Opmerking:dit bericht is oorspronkelijk alleen gepubliceerd in ons eBook, High Performance Techniques for SQL Server, Volume 4. U kunt hier meer te weten komen over onze eBooks.
Ik krijg regelmatig de vraag:"Waar begin ik als het gaat om het afstemmen van een SQL Server-instantie?" Mijn eerste reactie is om hen te vragen naar de configuratie van hun instantie. Als bepaalde dingen niet goed zijn geconfigureerd, kan het verspilde moeite zijn om meteen naar langlopende of dure zoekopdrachten te kijken.
Ik heb geblogd over veelvoorkomende dingen die beheerders missen, waarbij ik veel van de instellingen deel die beheerders moeten wijzigen van een standaardinstallatie van SQL Server. Voor prestatiegerelateerde items zeg ik dat ze het volgende moeten controleren:
- Geheugeninstellingen
- Statistieken bijwerken
- Indexonderhoud
- MAXDOP en kostendrempel voor parallellisme
- praktische tips voor tempdb
- Optimaliseren voor ad-hocworkloads
Zodra ik voorbij de configuratie-items ben, vraag ik of ze de bestands- en wachtstatistieken hebben bekeken, evenals dure vragen. Meestal is het antwoord "nee" - met een uitleg dat ze niet zeker weten hoe ze die informatie kunnen vinden.
De gebruikelijke compliantie wanneer iemand zegt dat ze een SQL Server moeten afstemmen, is dat deze traag werkt. Wat betekent langzaam? Is het een bepaald rapport, een specifieke toepassing of alles? Is het net begonnen, of is het in de loop van de tijd erger geworden? Ik begin met het stellen van de gebruikelijke triagevragen over wat het geheugen, de CPU en het schijfgebruik wordt vergeleken met wanneer de dingen normaal zijn, is het probleem net begonnen en wat is er recentelijk veranderd. Tenzij de klant een baseline vastlegt, hebben ze geen statistieken om mee te vergelijken om te weten of de huidige statistieken abnormaal zijn.
Bijna elke SQL Server waaraan ik werk, host meer dan één gebruikersdatabase. Wanneer een klant meldt dat de SQL Server traag werkt, maken ze zich meestal zorgen over een specifieke toepassing die problemen veroorzaakt voor hun klanten. Een reflexmatige reactie is om je onmiddellijk op die specifieke database te concentreren, maar vaak kan een ander proces waardevolle bronnen verbruiken en wordt de database van de applicatie beïnvloed. Als u bijvoorbeeld een grote rapportagedatabase heeft en iemand een enorm rapport heeft gestart dat de schijf verzadigt, de CPU doet toenemen en de plancache leegmaakt, kunt u er zeker van zijn dat de andere gebruikersdatabases langzamer gaan werken terwijl dat rapport wordt gegenereerd.
Ik vind het altijd leuk om te beginnen met het bekijken van de bestandsstatistieken. Voor SQL Server 2005 en hoger kunt u de DMV sys.dm_io_virtual_file_stats opvragen om I/O-statistieken voor elk gegevens- en logbestand te krijgen. Deze DMV heeft de functie fn_virtualfilestats vervangen. Om de bestandsstatistieken vast te leggen, gebruik ik graag een script dat Paul Randal heeft samengesteld:het vastleggen van IO-latenties voor een bepaalde periode. Dit script legt een basislijn vast en legt 30 minuten later (tenzij u de duur wijzigt in de sectie WACHTFOR VERTRAGING) de statistieken vast en berekent de delta's ertussen. Het script van Paul doet ook wat rekenwerk om de lees- en schrijflatenties te bepalen, wat het voor ons veel gemakkelijker maakt om te lezen en te begrijpen.
Op mijn laptop heb ik een kopie van de AdventureWorks2014-database teruggezet op een USB-drive, zodat ik lagere schijfsnelheden zou hebben; Ik heb toen een proces gestart om er een belasting tegen te genereren. U kunt de resultaten hieronder zien, waarbij mijn schrijflatentie voor mijn gegevensbestand 240 ms is en de schrijflatentie voor mijn logbestand 46 ms is. Dergelijke hoge latenties zijn lastig.
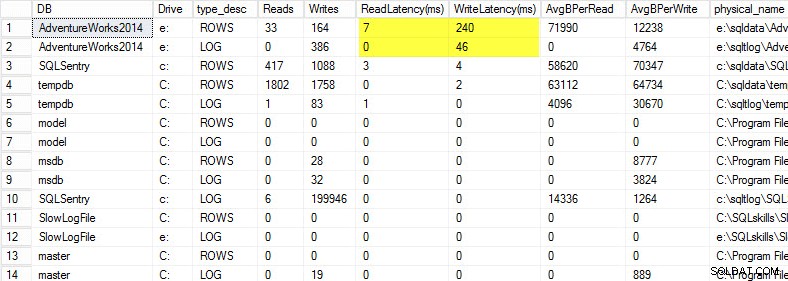
Alles boven de 20 ms moet als slecht worden beschouwd, zoals ik in een vorige post deelde:het bewaken van de lees-/schrijflatentie. Mijn leeslatentie is redelijk, maar de AdventureWorks2014-database lijdt aan trage schrijfacties. In dit geval zou ik onderzoeken wat de schrijfacties genereert en de prestaties van mijn I/O-subsysteem onderzoeken. Als dit buitengewoon hoge leeslatenties waren geweest, zou ik beginnen met het onderzoeken van de prestaties van query's (waarom doet het zoveel leesbewerkingen, bijvoorbeeld van ontbrekende indexen), evenals de algehele prestaties van het I/O-subsysteem.
Het is belangrijk om de algehele prestaties van uw I/O-subsysteem te kennen, en de beste manier om erachter te komen waartoe het in staat is, is door het te benchmarken. Glenn Berry vertelt hierover in zijn artikel over het analyseren van I/O-prestaties voor SQL Server. Glenn legt latentie, IOPS en doorvoer uit en pronkt met CrystalDiskMark, een gratis tool die u kunt gebruiken om uw opslag te baseren.
Nadat ik heb ontdekt hoe de bestandsstatistieken presteren, kijk ik graag naar wachtstatistieken met behulp van de DMV sys.dm_os_wait_stats, die informatie retourneert over alle wachttijden die zijn opgetreden. Hiervoor wend ik me tot een ander script dat Paul Randal levert in zijn vastlegging van wachtstatistieken voor een blogpost over een bepaalde periode. Het script van Paul doet weer wat rekenwerk voor ons, maar belangrijker nog, het sluit veel van de goedaardige wachttijden uit waar we normaal gesproken niet om geven. Dit script heeft ook een WACHTVERTRAGING en is ingesteld op 30 minuten. Wachtstatistieken lezen kan wat lastiger zijn:u kunt wachttijden hebben die hoog lijken op basis van percentage, maar de gemiddelde wachttijd is zo laag dat u zich er geen zorgen over hoeft te maken.
Ik startte hetzelfde laadproces en legde mijn wachtstatistieken vast, die ik hieronder heb weergegeven. Voor verklaringen voor veel van deze soorten wachten kun je een andere blogpost van Paul lezen, statistieken over wachten, of vertel me alsjeblieft waar het pijn doet, plus enkele van zijn berichten op deze blog.
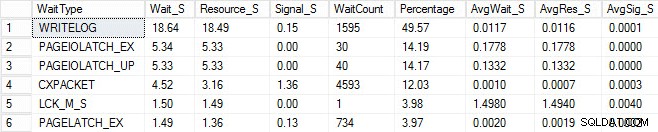
In deze gekunstelde uitvoer kunnen de PAGEIOLATCH-wachttijden wijzen op een knelpunt met mijn I/O-subsysteem, maar het kan ook een geheugenprobleem zijn, tabelscans zoeken in plaats daarvan, of een groot aantal andere problemen. In mijn geval weten we dat het een schijfprobleem is, aangezien ik de database op een USB-stick opsla. De LCK_M_S wachttijd is erg hoog, maar er is slechts één instantie van de wachttijd. Mijn WRITELOG is ook hoger dan ik zou willen zien, maar het is begrijpelijk gezien de latentieproblemen met de USB-stick. Dit laat ook zien dat CXPACKET wacht, en het zou gemakkelijk zijn om een reflexmatige reactie te hebben en te denken dat je een parallellisme/MAXDOP-probleem hebt, maar de AvgWait_S-teller is erg laag. Wees voorzichtig bij het gebruik van wachttijden voor het oplossen van problemen. Laat het een gids zijn om u dingen te vertellen die niet het probleem zijn en om u een richting te geven waar u naar problemen kunt zoeken. Een goede probleemoplossing is het correleren van gedrag uit meerdere gebieden om het probleem te verkleinen.
Nadat ik het bestand heb bekeken en de statistieken heb gewacht, begin ik me te verdiepen in de dure vragen op basis van de problemen die ik heb gevonden. Hiervoor wend ik me tot Glenn Berry's Diagnostic Information Queries. Deze reeksen query's zijn de scripts die veel consultants gebruiken. Glenn en de community leveren voortdurend updates om ze zo informatief en robuust mogelijk te maken. Een van mijn favoriete zoekopdrachten zijn de topquery's in de cache op basis van het aantal uitvoeringen. Ik ben dol op het vinden van query's of opgeslagen procedures met een hoog aantal uitvoeringen in combinatie met een hoog totaal_logisch_lezen. Als die zoekopdrachten afstemmingsmogelijkheden bieden, kun je snel een groot verschil maken voor de server. Ook inbegrepen in de scripts zijn SP's met de hoogste cache op basis van totale logische leesbewerkingen en SP's in de hoogste cache op basis van totale fysieke leesbewerkingen. Beide zijn goed voor het zoeken naar hoge reads met een hoog aantal uitvoeringen, zodat u het aantal I/O's kunt verminderen.
Naast de scripts van Glenn, gebruik ik graag sp_whoisactive van Adam Machanic om te zien wat er momenteel draait.
Er komt veel meer kijken bij het afstemmen van prestaties dan alleen naar bestands- en wachtstatistieken en dure zoekopdrachten kijken, maar daar begin ik graag mee. Het is een manier om snel een omgeving te triageren om te bepalen wat het probleem veroorzaakt. Er is geen volledig onfeilbare manier om af te stemmen:wat elke productie-DBA nodig heeft, is een checklist met dingen die moeten worden verwijderd en een echt goede verzameling scripts om door te lopen om de gezondheid van het systeem te analyseren. Het hebben van een basislijn is de sleutel tot het snel uitsluiten van normaal versus abnormaal gedrag. Mijn goede vriend Erin Stellato heeft een volledige cursus over Pluralsight, genaamd SQL Server:Benchmarking and Baselining, als je hulp nodig hebt bij het opzetten en vastleggen van je baseline.
Beter nog, koop een ultramoderne tool zoals SQL Sentry Performance Advisor die niet alleen historische informatie verzamelt en opslaat voor profilering en trending, en gemakkelijke toegang geeft tot alle hierboven genoemde details en meer, maar het geeft ook de mogelijkheid om activiteit te vergelijken met ingebouwde of door de gebruiker gedefinieerde baselines, indexen efficiënt te onderhouden zonder een vinger uit te steken, en reacties te alarmeren of te automatiseren op basis van een zeer robuuste architectuur voor aangepaste voorwaarden. De volgende schermafbeelding toont de historische weergave van het Performance Advisor-dashboard, met schijfwachttijden in oranje, database-I/O rechtsonder en basislijnen die de huidige en vorige periode in elke grafiek vergelijken (klik om te vergroten):
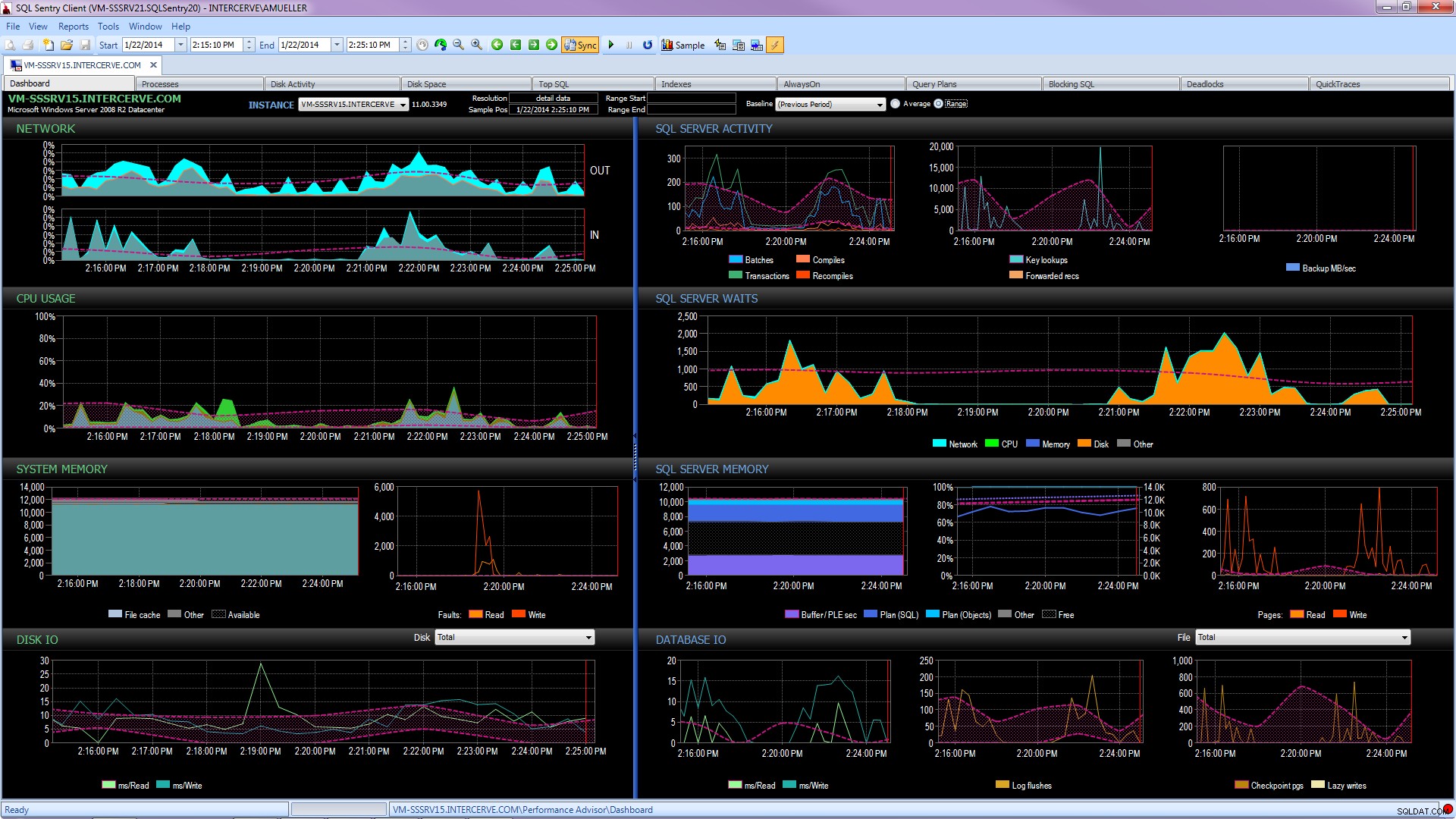
Tools voor kwaliteitsbewaking zijn niet gratis, maar ze bieden een heleboel functionaliteit en ondersteuning waarmee u zich kunt concentreren op de prestatieproblemen op uw servers, in plaats van u te concentreren op vragen, taken en waarschuwingen die mogelijk zodat u zich kunt concentreren op uw prestatieproblemen, maar alleen als u ze goed hebt opgelost. Het is vaak waardevol om het wiel niet opnieuw uit te vinden.