Ik heb eerder geschreven over de voordelen van het gebruik van NOEXPAND hints, zelfs in Enterprise Edition. De details staan allemaal in het gelinkte artikel, maar om het kort samen te vatten:
- SQL Server zal alleen automatisch maken statistieken over een geïndexeerde weergave wanneer een
NOEXPANDtabelhint wordt gebruikt. Het weglaten van deze hint kan leiden tot waarschuwingen voor het uitvoeringsplan over ontbrekende statistieken die niet kunnen worden opgelost door handmatig statistieken te maken. - SQL Server zal alleen gebruiken automatisch of handmatig gemaakte weergavestatistieken in berekeningen voor kardinaliteitsschattingen wanneer de query rechtstreeks naar de weergave verwijst en een
NOEXPANDhint wordt gebruikt. Voor alle behalve de meest triviale weergavedefinities betekent dit dat de kwaliteit van kardinaliteitsschattingen waarschijnlijk lager is wanneer deze hint niet wordt gebruikt, wat vaak resulteert in minder optimale uitvoeringsplannen. - Het ontbreken van, of het niet kunnen gebruiken van, statistieken kan ertoe leiden dat het optimalisatieprogramma gokt op kardinaliteitsschattingen, zelfs als er basistabelstatistieken beschikbaar zijn. Dit kan gebeuren wanneer een deel van het zoekplan wordt vervangen door een geïndexeerde weergavereferentie door de automatische weergave-overeenkomstfunctie, maar er geen weergavestatistieken beschikbaar zijn, zoals hierboven beschreven.
Er is nog een gevolg van het niet gebruiken van de NOEXPAND hint, die ik een paar jaar geleden terloops noemde in mijn artikel, Optimizer-beperkingen met gefilterde indexen:
De NOEXPAND zelfs in Enterprise Edition zijn hints nodig om ervoor te zorgen dat de uniekheidsgarantie die wordt geboden door de weergave-indexen door de optimizer wordt gebruikt.
Dit artikel gaat dieper in op die verklaring en de implicaties ervan.
Demo instellen
Het volgende script maakt een eenvoudige tabel en geïndexeerde weergave:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Dat creëert een heaptabel met één kolom en een onbeperkte weergave van dezelfde tabel met een unieke geclusterde index. Dit is niet bedoeld als een realistische use-case voor een geïndexeerde weergave; maar het zal helpen om de belangrijkste punten te illustreren met een minimum aan afleiding. Het belangrijke punt is dat de basistabel hier helemaal geen indexen heeft (zelfs geen geclusterde index), maar de weergave wel, en die index is uniek.
De voorbeeldquery
Overweeg de volgende eenvoudige query tegen de basistabel:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Het uitvoeringsplan dat u voor deze query ziet, is afhankelijk van de editie van SQL Server die wordt gebruikt. Als dit geen Enterprise Edition (of equivalent) is, ziet u een plan als dit:

De SQL Server-queryoptimalisatie heeft ervoor gekozen om de basistabel te scannen en de opgegeven onderscheiding toe te passen met behulp van een Distinct Sort-operator. Deze planvorm wordt volledig verwacht, aangezien automatische geïndexeerde weergave-overeenkomst niet beschikbaar is buiten Enterprise Edition. Ik stop vanaf nu met het zeggen van "Enterprise Edition of gelijkwaardig", maar blijf alsjeblieft concluderen dat ik elke editie bedoel die automatische weergave-matching ondersteunt als ik zeg, "Enterprise Edition" vanaf nu.
De UITGEBREIDE VIEWS hint
Dit is een beetje terzijde, maar om hetzelfde abonnement op Enterprise Edition te krijgen, moeten we een EXPAND VIEWS gebruiken vraag hint:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Het lijkt misschien een beetje vreemd om deze hint te gebruiken als er geen weergavereferenties zijn in de query, maar zo werkt het. De EXPAND VIEWS hint specificeert effectief dat geïndexeerde weergave-overeenkomst moet worden uitgeschakeld tijdens het compileren en optimaliseren van de query. Voor alle duidelijkheid:zonder deze hint kan Enterprise Edition anders (delen van) de zoekopdracht koppelen aan een of meer geïndexeerde weergaven.
Met automatische weergave-matching ingeschakeld
Zonder een EXPAND VIEWS hint, het compileren van dezelfde zoekopdracht op Developer Edition (bijvoorbeeld) levert een ander plan op:
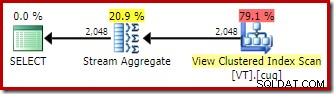
De toepassing van geïndexeerde weergave-matching betekent dat het uitvoeringsplan een scan van de weergaveclusterindex bevat in plaats van een basistabelscan.
Hetzelfde plan wordt in dit geval geproduceerd als de query rechtstreeks verwijst naar de weergave (in plaats van naar de basistabel):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; In alle edities wordt de weergaveverwijzing uitgebreid voordat de query-optimalisatie begint. In Enterprise-equivalente edities kan de uitgebreide vorm later worden aangepast aan de weergave. Dit is een belangrijk concept om te begrijpen wanneer u nadenkt over hoe de query-compiler en -optimizer geïndexeerde weergaven in SQL Server gebruiken.
Het stroomaggregaat
Het meest interessante verschil tussen de twee plannen die we tot nu toe hebben gezien, is het stroomaggregaat in het op de weergave afgestemde plan. Als je kijkt naar de geschatte kosten van de operators Table Scan en View Scan, dan zie je dat ze precies hetzelfde zijn. De optimizer heeft niet besloten om de geïndexeerde weergave te gebruiken omdat het de toegang tot de gegevens goedkoper maakte. In plaats daarvan maakt het scannen van de weergave-index de DISTINCT vereiste om te worden geïmplementeerd als een stroomaggregaat, in plaats van een hashaggregaat of onderscheidende sortering (zoals in het eerste plan).
Een Stream Aggregate vereist invoer geordend op de groeperingskolom(men). In dit geval is het onderscheiden gelijk aan groeperen op de enkele kolom, en de unieke geclusterde index van de weergave biedt de nodige bestelgarantie. Het kostenmodel van de optimizer identificeert de Stream Aggregate als een goedkopere optie dan een Distinct Sort of Hash Aggregate voor deze zoekopdracht. Dit is de basis voor de optimizer die ervoor kiest om toegang te krijgen tot de geïndexeerde weergave wanneer automatische weergave-overeenkomst beschikbaar is.
Met al dat gezegd en begrepen, is de Stream Aggregate nog steeds onverwacht:gezien de uniciteitsgarantie die wordt geboden door de weergave-index, is het helemaal niet nodig om deze groeperingsbewerking uit te voeren. De unieke geclusterde index zorgt er al voor dat de kolom geen duplicaten bevat.
Dit is in een notendop het probleem. Wanneer automatische weergave-matching wordt gebruikt, herkent de optimizer de bestelgarantie die wordt geboden door de weergave-index, maar niet de uniciteitsgarantie.
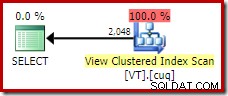
Een NOEXPAND-hint gebruiken
Om het ideale uitvoeringsplan voor deze query te krijgen, moeten we rechtstreeks naar de weergave verwijzen en een NOEXPAND gebruiken tafel hint:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Dit geeft ons het plan dat een ervaren database-persoon zou verwachten; een die correct herkent dat de afzonderlijke bewerking overbodig is en kan worden verwijderd:
Een tweede voorbeeld
Als u geen gebruik maakt van de uniciteitsgarantie die wordt geboden door een weergave-index, kan dit andere effecten hebben op het uiteindelijke uitvoeringsplan. Overweeg nu een self-join van de geïndexeerde weergave (nogmaals, alleen om een concept te illustreren - dit is niet bedoeld als een realistische vraag):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Bij gebruik van Developer Edition heeft het gekozen uitvoeringsplan helemaal geen toegang tot de geïndexeerde weergave en bevat het een hash-join (soms een indicatie dat er een bruikbare index ontbreekt):
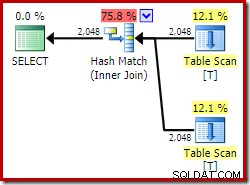
Laten we nu precies dezelfde zoekopdracht proberen, maar met een NOEXPAND hint bij elke weergavereferentie:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Het uitvoeringsplan bevat nu twee geïndexeerde weergave-toegangen en een samenvoeg-join:
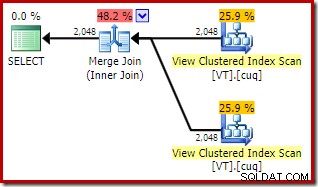
Dit nieuwe plan heeft veel lagere geschatte kosten dan het hash-joinplan, dus waarom heeft de optimizer deze optie niet eerder gekozen? We kunnen zien waarom door een hint voor samenvoegen toe te voegen aan de oorspronkelijke zoekopdracht:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Dit geeft een gelijkaardig uitziende plan dat ervoor kiest om toegang te krijgen tot de weergave, hoewel NOEXPAND was niet gespecificeerd:
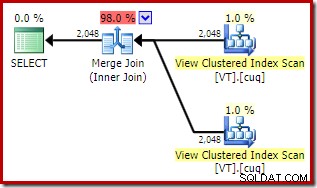
De totale geschatte kosten van dit plan zijn hoger dan bij beide voorgaande voorbeelden. De Merge Join in dit plan vertegenwoordigt ook een groter deel van de totale geschatte kosten dan voorheen (98% versus 48,2%).
De reden hiervoor kan worden bekeken door te kijken naar de eigenschappen van de merge join. In de NOEXPAND plan, het was een één-op-veel merge join. In het bovenstaande plan is het een veel-op-veel merge-join. Het kostenmodel van de optimizer kent hogere kosten toe aan veel-op-veel merge-joins omdat er een tempdb-werktabel nodig is om eventuele duplicaten af te handelen.
Conclusies
De garanties die een unieke index biedt, kunnen een krachtige optimalisatietool zijn, dus het is jammer dat automatische indexmatching er momenteel niet van kan profiteren. De potentiële voordelen gaan verder dan het elimineren van onnodige aggregaties of het inschakelen van een één-op-veel merge-join, zoals te zien is in de voorgaande eenvoudige voorbeelden. Over het algemeen kan het moeilijk zijn om te ontdekken dat een uitvoeringsplan suboptimaal is omdat de optimizer niet heeft kunnen profiteren van een uniciteitsgarantie.
Deze optimalisatiebeperking is niet alleen van toepassing op de unieke geclusterde index die een weergave moet hebben om te worden gerealiseerd. In meer complexe scenario's kunnen er ook aanvullende niet-geclusterde indexen in de weergave aanwezig zijn; misschien om kruistabelrelaties weer te geven die moeilijk af te dwingen of anderszins te vertegenwoordigen zijn. Als deze niet-geclusterde indexen als uniek zijn gedefinieerd, zal de optimizer deze garanties ook over het hoofd zien, als automatische indexaanpassing wordt gebruikt.
Als we dit toevoegen aan de beperkingen rond het maken en gebruiken van statistische informatie, lijkt het erop dat het vertrouwen op automatische weergave van weergaven kan leiden tot inferieure uitvoeringsplannen. De veiligste optie is waarschijnlijk om expliciet naar geïndexeerde views te verwijzen en een NOEXPAND . te gebruiken hint elke keer - in ieder geval totdat deze problemen in het product zijn opgelost.
Verzachtende factoren
Ik moet benadrukken dat het probleem dat in dit artikel wordt beschreven alleen van toepassing is op de uniciteitsgarantie die wordt geboden door een unieke weergave-index. Als de optimizer de vereiste uniciteitsinformatie op een andere manier kan krijgen , is de kans groot dat optimalisatieproblemen worden vermeden.
Er kan bijvoorbeeld een geschikte unieke index zijn in een basistabel waarnaar door de weergave wordt verwezen. Of, in het geval van een weergave die aggregatie bevat, kan de optimizer al een bruikbare uniciteitsgarantie afleiden uit de GROUP BY van de weergave. clausule. De gebruikelijke praktijk om een geclusterde weergave-index aan de groeperingssleutels toe te voegen, voegt in dat geval geen extra uniciteitsinformatie toe.
Desalniettemin zijn er momenten waarop dit "unieke overzicht" kan betekenen dat u uitvoeringsplannen van betere kwaliteit krijgt door een expliciete weergavereferentie en NOEXPAND te gebruiken. hints, zelfs in Enterprise Edition.