In deel 5 van mijn serie over tabeluitdrukkingen heb ik de volgende oplossing gegeven voor het genereren van een reeks getallen met behulp van CTE's, een tabelwaardeconstructor en kruiskoppelingen:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Er zijn veel praktische toepassingen voor een dergelijke tool, waaronder het genereren van een reeks datum- en tijdwaarden, het maken van voorbeeldgegevens en meer. Sommige platforms erkennen de algemene behoefte en bieden een ingebouwde tool, zoals de functie Genereer_serie van PostgreSQL. Op het moment van schrijven biedt T-SQL niet zo'n ingebouwde tool, maar men kan altijd hopen en stemmen dat een dergelijke tool in de toekomst wordt toegevoegd.
In een reactie op mijn artikel zei Marcos Kirchner dat hij mijn oplossing testte met verschillende kardinaliteiten van de tabelwaarde-constructor en verschillende uitvoeringstijden kreeg voor de verschillende kardinaliteiten.
 Ik gebruikte mijn oplossing altijd met een basistabelwaarde-constructorkardinaliteit van 2, maar de opmerking van Marcos zette me aan het denken. Deze tool is zo handig dat we als gemeenschap onze krachten moeten bundelen om te proberen de snelste versie te maken die mogelijk is. Het testen van verschillende kardinaliteiten van de basistabel is slechts één dimensie om te proberen. Er kunnen er nog veel meer zijn. Ik zal de prestatietests presenteren die ik met mijn oplossing heb gedaan. Ik heb voornamelijk geëxperimenteerd met verschillende kardinaliteiten van de tabelwaardeconstructor, met seriële versus parallelle verwerking, en met rijmodus versus batchmodusverwerking. Het kan echter zijn dat een geheel andere oplossing zelfs sneller is dan mijn beste versie. Dus de uitdaging is aan! Ik noem alle jedi, padawan, tovenaar en leerling gelijk. Wat is de best presterende oplossing die je kunt bedenken? Heb jij het in je om de snelste oplossing tot nu toe te verslaan? Als dat zo is, deel die van jou dan als een opmerking bij dit artikel en voel je vrij om elke oplossing die door anderen is gepost te verbeteren.
Ik gebruikte mijn oplossing altijd met een basistabelwaarde-constructorkardinaliteit van 2, maar de opmerking van Marcos zette me aan het denken. Deze tool is zo handig dat we als gemeenschap onze krachten moeten bundelen om te proberen de snelste versie te maken die mogelijk is. Het testen van verschillende kardinaliteiten van de basistabel is slechts één dimensie om te proberen. Er kunnen er nog veel meer zijn. Ik zal de prestatietests presenteren die ik met mijn oplossing heb gedaan. Ik heb voornamelijk geëxperimenteerd met verschillende kardinaliteiten van de tabelwaardeconstructor, met seriële versus parallelle verwerking, en met rijmodus versus batchmodusverwerking. Het kan echter zijn dat een geheel andere oplossing zelfs sneller is dan mijn beste versie. Dus de uitdaging is aan! Ik noem alle jedi, padawan, tovenaar en leerling gelijk. Wat is de best presterende oplossing die je kunt bedenken? Heb jij het in je om de snelste oplossing tot nu toe te verslaan? Als dat zo is, deel die van jou dan als een opmerking bij dit artikel en voel je vrij om elke oplossing die door anderen is gepost te verbeteren.
Vereisten:
- Implementeer uw oplossing als een inline tabelwaardefunctie (iTVF) met de naam dbo.GetNumsYourName met parameters @low AS BIGINT en @high AS BIGINT. Zie als voorbeeld degene die ik aan het einde van dit artikel indien.
- U kunt indien nodig ondersteunende tabellen in de gebruikersdatabase maken.
- Je kunt indien nodig hints toevoegen.
- Zoals vermeld, zou de oplossing scheidingstekens van het BIGINT-type moeten ondersteunen, maar u kunt uitgaan van een maximale reekskardinaliteit van 4.294.967.296.
- Om de prestaties van uw oplossing te evalueren en deze met andere te vergelijken, test ik deze met een bereik van 1 tot 100.000.000, waarbij Resultaten negeren na uitvoering is ingeschakeld in SSMS.
Veel geluk voor ons allemaal! Moge de beste gemeenschap winnen.;)
Verschillende kardinaliteiten voor basistabelwaarde-constructor
Ik heb geëxperimenteerd met verschillende kardinaliteiten van de basis-CTE, beginnend met 2 en voortschrijdend in een logaritmische schaal, waarbij ik de vorige kardinaliteit in elke stap kwadrateerde:2, 4, 16 en 256.
Voordat u begint te experimenteren met verschillende basiskardinaliteiten, kan het handig zijn om een formule te hebben die, gezien de basiskardinaliteit en maximale bereikkardinaliteit, u zou vertellen hoeveel niveaus van CTE's u nodig hebt. Als voorbereidende stap is het gemakkelijker om eerst een formule te bedenken die, gegeven de basiskardinaliteit en het aantal niveaus van CTE's, berekent wat de maximale resulterende bereikkardinaliteit is. Hier is zo'n formule uitgedrukt in T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Met de bovenstaande voorbeeldinvoerwaarden levert deze uitdrukking een maximale bereikkardinaliteit op van 4.294.967.296.
Vervolgens omvat de inverse formule voor het berekenen van het aantal benodigde CTE-niveaus het nesten van twee logfuncties, zoals:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Met de bovenstaande voorbeeldinvoerwaarden levert deze uitdrukking 5 op. Merk op dat dit getal een aanvulling is op de basis-CTE die de tabelwaardeconstructor heeft, die ik L0 (voor niveau 0) heb genoemd in mijn oplossing.
Vraag me niet hoe ik aan deze formules ben gekomen. Het verhaal waar ik me aan vasthoud, is dat Gandalf ze in mijn dromen in Elfen tegen me uitsprak.
Laten we doorgaan met prestatietesten. Zorg ervoor dat u Resultaten negeren na uitvoering inschakelt in het dialoogvenster SSMS-queryopties onder Raster, Resultaten. Gebruik de volgende code om een test uit te voeren met een basis-CTE-kardinaliteit van 2 (vereist 5 extra CTE-niveaus):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ik heb het plan weergegeven in figuur 1 voor deze uitvoering.
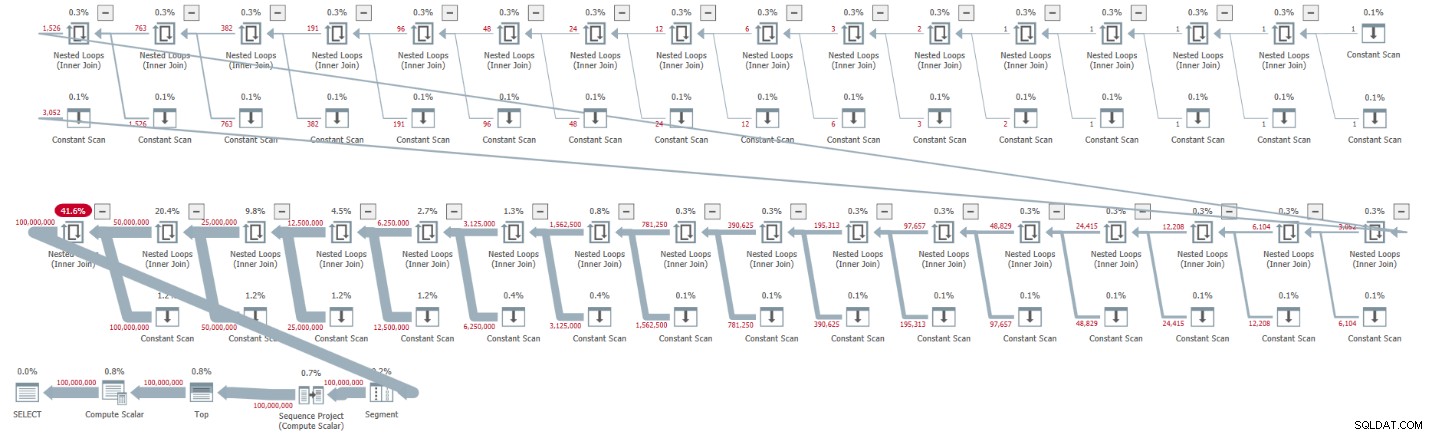 Figuur 1:Plan voor basis CTE-kardinaliteit van 2
Figuur 1:Plan voor basis CTE-kardinaliteit van 2
Het plan is serieel en alle operators in het plan gebruiken standaard verwerking in rijmodus. Als u standaard een parallel abonnement krijgt, bijvoorbeeld wanneer u de oplossing in een iTVF inkapselt en een groot bereik gebruikt, forceer dan nu een serieel abonnement met een MAXDOP 1-hint.
Kijk hoe het uitpakken van de CTE's resulteerde in 32 instanties van de Constant Scan-operator, die elk een tabel met twee rijen vertegenwoordigen.
Ik heb de volgende prestatiestatistieken voor deze uitvoering:
CPU time = 30188 ms, elapsed time = 32844 ms.
Gebruik de volgende code om de oplossing te testen met een basis CTE-kardinaliteit van 4, waarvoor volgens onze formule vier CTE-niveaus nodig zijn:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ik heb het plan weergegeven in figuur 2 voor deze uitvoering.
 Figuur 2:Plan voor basis CTE-kardinaliteit van 4
Figuur 2:Plan voor basis CTE-kardinaliteit van 4
Het uitpakken van de CTE's resulteerde in 16 Constant Scan-operators, die elk een tabel van 4 rijen vertegenwoordigen.
Ik heb de volgende prestatiestatistieken voor deze uitvoering:
CPU time = 23781 ms, elapsed time = 25435 ms.
Dit is een behoorlijke verbetering van 22,5 procent ten opzichte van de vorige oplossing.
Bij het onderzoeken van de wachttijdstatistieken die zijn gerapporteerd voor de zoekopdracht, is het dominante wachttype SOS_SCHEDULER_YIELD. Inderdaad, het aantal wachttijden daalde merkwaardig genoeg met 22,8 procent in vergelijking met de eerste oplossing (aantal wachttijden 15.280 versus 19.800).
Gebruik de volgende code om de oplossing te testen met een basis CTE-kardinaliteit van 16, waarvoor volgens onze formule drie CTE-niveaus nodig zijn:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ik heb het plan weergegeven in figuur 3 voor deze uitvoering.
 Figuur 3:Plan voor basis CTE-kardinaliteit van 16
Figuur 3:Plan voor basis CTE-kardinaliteit van 16
Dit keer resulteerde het uitpakken van de CTE's in 8 Constant Scan-operators, die elk een tabel met 16 rijen vertegenwoordigen.
Ik heb de volgende prestatiestatistieken voor deze uitvoering:
CPU time = 22968 ms, elapsed time = 24409 ms.
Deze oplossing verkort de verstreken tijd nog verder, zij het met slechts een paar procent extra, wat neerkomt op een reductie van 25,7 procent in vergelijking met de eerste oplossing. Nogmaals, het aantal wachttijden van het wachttype SOS_SCHEDULER_YIELD blijft dalen (12.938).
Vooruitgang in onze logaritmische schaal, de volgende test omvat een basis CTE-kardinaliteit van 256. Het is lang en lelijk, maar probeer het eens:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ik heb het plan weergegeven in figuur 4 voor deze uitvoering.
 Figuur 4:Plan voor basis CTE-kardinaliteit van 256
Figuur 4:Plan voor basis CTE-kardinaliteit van 256
Dit keer resulteerde het uitpakken van de CTE's in slechts vier Constant Scan-operators, elk met 256 rijen.
Ik heb de volgende prestatienummers voor deze uitvoering:
CPU time = 23516 ms, elapsed time = 25529 ms.
Deze keer lijkt het alsof de prestaties een beetje zijn verslechterd in vergelijking met de vorige oplossing met een basis CTE-kardinaliteit van 16. Inderdaad, het aantal wachttijden van het wachttype SOS_SCHEDULER_YIELD nam een beetje toe tot 13.176. Het lijkt er dus op dat we ons gouden getal 16 hebben gevonden!
Parallelle versus seriële abonnementen
Ik heb geëxperimenteerd met het forceren van een parallel plan met behulp van de hint ENABLE_PARALLEL_PLAN_PREFERENCE, maar het ging ten koste van de prestaties. Toen ik de oplossing implementeerde als een iTVF, kreeg ik standaard een parallel plan op mijn machine voor grote reeksen, en moest ik een serieel plan forceren met een MAXDOP 1-hint om optimale prestaties te krijgen.
Batchverwerking
De belangrijkste bron die in de plannen voor mijn oplossingen wordt gebruikt, is de CPU. Aangezien batchverwerking draait om het verbeteren van de CPU-efficiëntie, vooral als het gaat om grote aantallen rijen, is het de moeite waard om deze optie te proberen. De belangrijkste activiteit hier die kan profiteren van batchverwerking, is de berekening van het rijnummer. Ik heb mijn oplossingen getest in de SQL Server 2019 Enterprise-editie. SQL Server koos standaard voor verwerking in rijmodus voor alle eerder weergegeven oplossingen. Blijkbaar voldeed deze oplossing niet aan de heuristieken die nodig zijn om de batchmodus in rowstore in te schakelen. Er zijn een aantal manieren om SQL Server hier batchverwerking te laten gebruiken.
Optie 1 is om een tabel met een columnstore-index in de oplossing te betrekken. U kunt dit bereiken door een dummytabel te maken met een columnstore-index en een dummy left join te introduceren in de buitenste query tussen onze Nums CTE en die tabel. Hier is de definitie van de dummytabel:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Herzie vervolgens de buitenste query tegen Nums om FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0 te gebruiken. Hier is een voorbeeld met een basis-CTE-kardinaliteit van 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Ik heb het plan weergegeven in figuur 5 voor deze uitvoering.
 Figuur 5:Plan met batchverwerking
Figuur 5:Plan met batchverwerking
Let op het gebruik van de batch-modus Window Aggregate-operator om de rijnummers te berekenen. Merk ook op dat het plan geen betrekking heeft op de dummy-tafel. De optimizer heeft het geoptimaliseerd.
Het voordeel van optie 1 is dat het werkt in alle SQL Server-edities en relevant is in SQL Server 2016 of later, aangezien de batchmodus Window Aggregate-operator werd geïntroduceerd in SQL Server 2016. Het nadeel is de noodzaak om de dummy-tabel te maken en op te nemen het in de oplossing.
Optie 2 om batchverwerking voor onze oplossing te krijgen, op voorwaarde dat u SQL Server 2019 Enterprise-editie gebruikt, is om de ongedocumenteerde zelfverklarende hint OVERRIDE_BATCH_MODE_HEURISTICS te gebruiken (details in het artikel van Dmitry Pilugin), zoals:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Het voordeel van optie 2 is dat u geen dummy-tabel hoeft te maken en deze bij uw oplossing hoeft te betrekken. De nadelen zijn dat je de Enterprise-editie moet gebruiken, minimaal SQL Server 2019 moet gebruiken waar de batchmodus op rowstore werd geïntroduceerd, en de oplossing omvat het gebruik van een ongedocumenteerde hint. Om deze redenen geef ik de voorkeur aan optie 1.
Dit zijn de prestatienummers die ik heb gekregen voor de verschillende basis-CTE-kardinaliteiten:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
Afbeelding 6 toont een prestatievergelijking tussen de verschillende oplossingen:
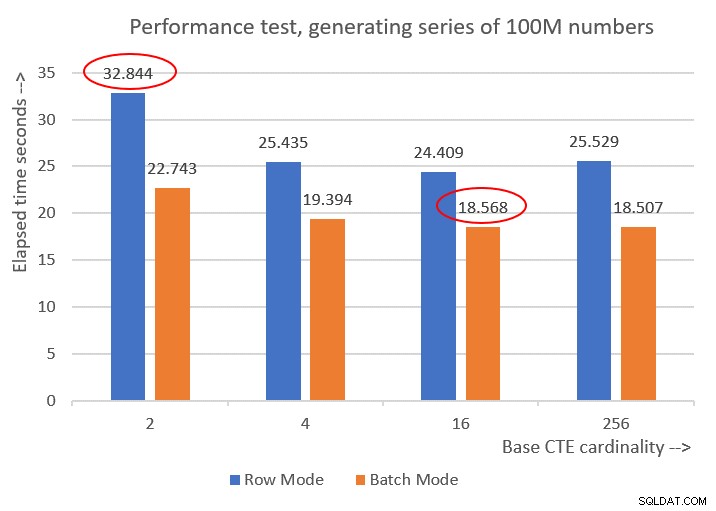 Figuur 6:Prestatievergelijking
Figuur 6:Prestatievergelijking
Je kunt een behoorlijke prestatieverbetering van 20-30 procent waarnemen ten opzichte van de tegenhangers in de rijmodus.
Vreemd genoeg deed de verwerking in batchmodus de oplossing met een basis-CTE-kardinaliteit van 256 het beste. Het is echter maar een klein beetje sneller dan de oplossing met een basis CTE-kardinaliteit van 16. Het verschil is zo klein, en de laatste heeft een duidelijk voordeel in termen van beknoptheid van de code, dat ik bij 16 zou blijven.
Dus mijn afstemmingsinspanningen resulteerden in een verbetering van 43,5 procent ten opzichte van de oorspronkelijke oplossing met de basiskardinaliteit van 2 met behulp van rijmodusverwerking.
De uitdaging is begonnen!
Ik dien twee oplossingen in als mijn bijdrage van de gemeenschap aan deze uitdaging. Als u SQL Server 2016 of later gebruikt en een tabel in de gebruikersdatabase kunt maken, maakt u de volgende dummytabel:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
En gebruik de volgende iTVF-definitie:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Gebruik de volgende code om het te testen (zorg ervoor dat de resultaten na uitvoering weggooien is aangevinkt):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Deze code eindigt in 18 seconden op mijn machine.
Als u om welke reden dan ook niet kunt voldoen aan de vereisten van de batchverwerkingsoplossing, dien ik de volgende functiedefinitie in als mijn tweede oplossing:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Gebruik de volgende code om het te testen:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Deze code is binnen 24 seconden klaar op mijn machine.
Jouw beurt!