 Dit artikel is het achtste deel in een serie over tabeluitdrukkingen. Tot dusverre heb ik een achtergrond gegeven voor tabeluitdrukkingen, waarbij ik zowel de logische als de optimalisatieaspecten van afgeleide tabellen, de logische aspecten van CTE's en enkele optimalisatieaspecten van CTE's behandelde. Deze maand ga ik verder met het behandelen van optimalisatieaspecten van CTE's, waarbij ik specifiek inga op hoe meerdere CTE-referenties worden behandeld.
Dit artikel is het achtste deel in een serie over tabeluitdrukkingen. Tot dusverre heb ik een achtergrond gegeven voor tabeluitdrukkingen, waarbij ik zowel de logische als de optimalisatieaspecten van afgeleide tabellen, de logische aspecten van CTE's en enkele optimalisatieaspecten van CTE's behandelde. Deze maand ga ik verder met het behandelen van optimalisatieaspecten van CTE's, waarbij ik specifiek inga op hoe meerdere CTE-referenties worden behandeld.
In mijn voorbeelden blijf ik de voorbeelddatabase TSQLV5 gebruiken. U vindt het script dat TSQLV5 maakt en vult hier, en het ER-diagram hier.
Meerdere referenties en niet-determinisme
Vorige maand heb ik uitgelegd en aangetoond dat CTE's worden verwijderd, terwijl tijdelijke tabellen en tabelvariabelen feitelijk gegevens behouden. Ik gaf aanbevelingen in termen van wanneer het zinvol is om CTE's te gebruiken versus wanneer het zinvol is om tijdelijke objecten te gebruiken vanuit het oogpunt van queryprestaties. Maar naast de prestaties van de oplossing is er nog een ander belangrijk aspect van CTE-optimalisatie, of fysieke verwerking, waarmee u rekening moet houden:hoe meerdere verwijzingen naar de CTE vanuit een externe query worden afgehandeld. Het is belangrijk om te beseffen dat als je een buitenste query hebt met meerdere verwijzingen naar dezelfde CTE, elk afzonderlijk wordt verwijderd. Als u niet-deterministische berekeningen hebt in de innerlijke query van de CTE, kunnen die berekeningen verschillende resultaten hebben in de verschillende verwijzingen.
Stel bijvoorbeeld dat u de functie SYSDATETIME aanroept in de innerlijke query van een CTE, waardoor een resultaatkolom wordt gemaakt met de naam dt. In het algemeen wordt een ingebouwde functie, ervan uitgaande dat de invoer niet verandert, eenmaal per query en verwijzing geëvalueerd, ongeacht het aantal betrokken rijen. Als u slechts één keer naar de CTE verwijst vanuit een buitenste query, maar meerdere keren met de dt-kolom interageert, wordt verondersteld dat alle verwijzingen dezelfde functie-evaluatie vertegenwoordigen en dezelfde waarden retourneren. Als u echter meerdere keren naar de CTE in de buitenste query verwijst, of het nu gaat om meerdere subquery's die verwijzen naar de CTE of om een koppeling tussen meerdere instanties van dezelfde CTE (bijvoorbeeld gealiasd als C1 en C2), de verwijzingen naar C1.dt en C2.dt vertegenwoordigt verschillende evaluaties van de onderliggende expressie en kan resulteren in verschillende waarden.
Bekijk de volgende drie batches om dit aan te tonen:
-- Batch 1
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
SELECT @i += 1 WHERE SYSDATETIME() = SYSDATETIME();
PRINT @i;
GO
-- Batch 2
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 FROM C WHERE dt = dt;
PRINT @i;
GO
-- Batch 3
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 WHERE (SELECT dt FROM C) = (SELECT dt FROM C);
PRINT @i;
GO Op basis van wat ik zojuist heb uitgelegd, kun je identificeren welke van de batches een oneindige lus hebben en welke op een gegeven moment zullen stoppen vanwege de twee comparands van het predikaat dat naar verschillende waarden evalueert?
Onthoud dat ik zei dat een aanroep van een ingebouwde niet-deterministische functie zoals SYSDATETIME eenmaal per query en referentie wordt geëvalueerd. Dit betekent dat je in Batch 1 twee verschillende evaluaties hebt en na voldoende herhalingen van de lus zullen ze resulteren in verschillende waarden. Probeer het. Hoeveel herhalingen heeft de code gerapporteerd?
Wat Batch 2 betreft, heeft de code twee verwijzingen naar de dt-kolom van dezelfde CTE-instantie, wat betekent dat beide dezelfde functie-evaluatie vertegenwoordigen en dezelfde waarde moeten vertegenwoordigen. Bijgevolg heeft batch 2 een oneindige lus. Voer het zo lang uit als u wilt, maar uiteindelijk moet u de uitvoering van de code stoppen.
Wat betreft Batch 3, de buitenste query heeft twee verschillende subquery's die interageren met de CTE C, die elk een ander exemplaar vertegenwoordigen dat afzonderlijk door een unnesting-proces gaat. De code wijst niet expliciet verschillende aliassen toe aan de verschillende instanties van de CTE omdat de twee subquery's in onafhankelijke bereiken verschijnen, maar om het gemakkelijker te begrijpen te maken, zou je kunnen denken aan de twee als het gebruik van verschillende aliassen zoals C1 in één subquery en C2 in de andere. Het is dus alsof de ene subquery interageert met C1.dt en de andere met C2.dt. De verschillende referenties vertegenwoordigen verschillende evaluaties van de onderliggende uitdrukking en kunnen dus resulteren in verschillende waarden. Probeer de code uit te voeren en kijk of deze op een gegeven moment stopt. Hoeveel iteraties duurde het voordat het stopte?
Het is interessant om te proberen de gevallen te identificeren waarin u een enkele of meerdere evaluaties van de onderliggende expressie in het uitvoeringsplan voor query's hebt. Figuur 1 toont de grafische uitvoeringsplannen voor de drie batches (klik om te vergroten).
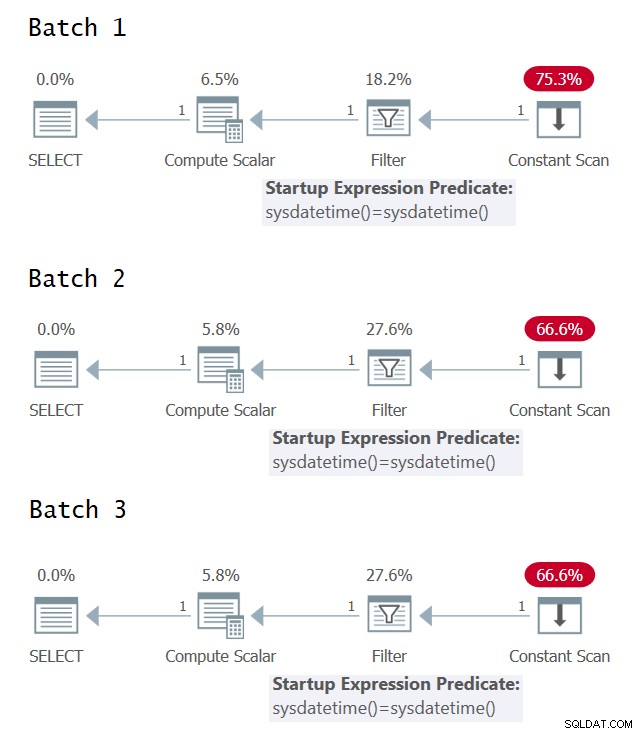 Figuur 1:Grafische uitvoeringsplannen voor Batch 1, Batch 2 en Batch 3
Figuur 1:Grafische uitvoeringsplannen voor Batch 1, Batch 2 en Batch 3
Helaas geen plezier van de grafische uitvoeringsplannen; ze lijken allemaal identiek, ook al hebben de drie batches semantisch geen identieke betekenis. Dankzij @CodeRecce en Forrest (@tsqladdict) zijn we er als community op andere manieren in geslaagd om dit tot op de bodem uit te zoeken.
Zoals @CodeRecce ontdekte, bevatten de XML-plannen het antwoord. Hier zijn de relevante delen van de XML voor de drie batches:
−− Batch 1
…
…
−− Batch 2
…
…
−− Batch 3
…
…
In het XML-plan voor Batch 1 kunt u duidelijk zien dat het filterpredikaat de resultaten vergelijkt van twee afzonderlijke directe aanroepen van de intrinsieke SYSDATETIME-functie.
In het XML-plan voor Batch 2 vergelijkt het filterpredikaat de constante expressie ConstExpr1002 die één aanroep van de SYSDATETIME-functie vertegenwoordigt met zichzelf.
In het XML-plan voor Batch 3 vergelijkt het filterpredikaat twee verschillende constante-expressies, ConstExpr1005 en ConstExpr1006 genaamd, die elk een afzonderlijke aanroep van de functie SYSDATETIME vertegenwoordigen.
Als een andere optie stelde Forrest (@tsqladdict) voor om traceringsvlag 8605 te gebruiken, die de initiële queryboomrepresentatie toont die is gemaakt door SQL Server, na het inschakelen van traceervlag 3604 die ervoor zorgt dat de uitvoer van TF 8605 naar de SSMS-client wordt gestuurd. Gebruik de volgende code om beide traceervlaggen in te schakelen:
DBCC TRACEON(3604); -- direct output to client GO DBCC TRACEON(8605); -- show initial query tree GO
Vervolgens voert u de code uit waarvoor u de queryboom wilt ophalen. Hier zijn de relevante delen van de uitvoer die ik heb gekregen van TF 8605 voor de drie batches:
−− Batch 1
*** Omgezette boom:***
LogOp_Project COL:Uitdr1000
LogOp_Select
LogOp_ConstTableGet (1) [leeg]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsieke sysdatetime
ScaOp_Intrinsieke sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Uitdr1000
ScaOp_Rekenkunde x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Niet in eigendom,Waarde=1)
−− Batch 2
*** Omgezette boom:***
LogOp_Project COL:Uitdr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [leeg]
AncOp_PrjList
AncOp_PrjEl COL:Uitdr1000
ScaOp_Intrinsieke sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Uitdr1000
ScaOp_Identifier COL:Uitdr1000
AncOp_PrjList
AncOp_PrjEl COL:Uitdr1001
ScaOp_Rekenkunde x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Niet in eigendom,Waarde=1)
−− Batch 3
*** Omgezette boom:***
LogOp_Project COL:Uitdr1004
LogOp_Select
LogOp_ConstTableGet (1) [leeg]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Uitdr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [leeg]
AncOp_PrjList
AncOp_PrjEl COL:Uitdr1000
ScaOp_Intrinsieke sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Uitdr1001
ScaOp_Identifier COL:Uitdr1000
ScaOp_Subquery COL:Uitdr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [leeg]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsieke sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Uitdr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Rekenkunde x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Niet in eigendom,Waarde=1)
In batch 1 ziet u een vergelijking tussen de resultaten van twee afzonderlijke evaluaties van de intrinsieke functie SYSDATETIME.
In Batch 2 zie je één evaluatie van de functie die resulteert in een kolom met de naam Expr1000, en vervolgens een vergelijking tussen deze kolom en zichzelf.
In Batch 3 ziet u twee afzonderlijke evaluaties van de functie. Eén in kolom genaamd Expr1000 (later geprojecteerd door de subquerykolom genaamd Expr1001). Een andere in kolom genaamd Expr1002 (later geprojecteerd door de subquerykolom genaamd Expr1003). Je hebt dan een vergelijking tussen Expr1001 en Expr1003.
Dus met een beetje meer graven dan wat het grafische uitvoeringsplan blootlegt, kun je erachter komen wanneer een onderliggende expressie slechts één keer wordt geëvalueerd in plaats van meerdere keren. Nu u de verschillende gevallen begrijpt, kunt u uw oplossingen ontwikkelen op basis van het gewenste gedrag dat u zoekt.
Vensterfuncties met niet-deterministische volgorde
Er is nog een andere klasse berekeningen die u in de problemen kunnen brengen wanneer ze worden gebruikt in oplossingen met meerdere verwijzingen naar dezelfde CTE. Dat zijn vensterfuncties die afhankelijk zijn van niet-deterministische ordening. Neem de ROW_NUMBER vensterfunctie als voorbeeld. Bij gebruik met gedeeltelijke bestelling (sorteren op elementen die de rij niet uniek identificeren), elke evaluatie van de onderliggende query kan resulteren in een andere toewijzing van de rijnummers, zelfs als de onderliggende gegevens niet zijn gewijzigd. Houd er bij meerdere CTE-referenties rekening mee dat elk afzonderlijk wordt verwijderd en dat u verschillende resultatensets kunt krijgen. Afhankelijk van wat de buitenste query doet met elke verwijzing, b.v. met welke kolommen van elke referentie het interageert en hoe, de optimizer kan beslissen om toegang te krijgen tot de gegevens voor elk van de instanties met behulp van verschillende indexen met verschillende bestelvereisten.
Beschouw de volgende code als voorbeeld:
USE TSQLV5;
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Kan deze query ooit een niet-lege resultatenset retourneren? Misschien is je eerste reactie dat het niet kan. Maar denk eens goed na over wat ik zojuist heb uitgelegd en je zult je realiseren dat het, althans in theorie, mogelijk is vanwege de twee afzonderlijke CTE-ontsluitingsprocessen die hier zullen plaatsvinden - een van C1 en een andere van C2. Het is echter één ding om te theoretiseren dat er iets kan gebeuren, en iets anders om het aan te tonen. Toen ik deze code bijvoorbeeld uitvoerde zonder nieuwe indexen te maken, kreeg ik steeds een lege resultatenset:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Ik heb het plan weergegeven in Afbeelding 23 voor deze zoekopdracht.
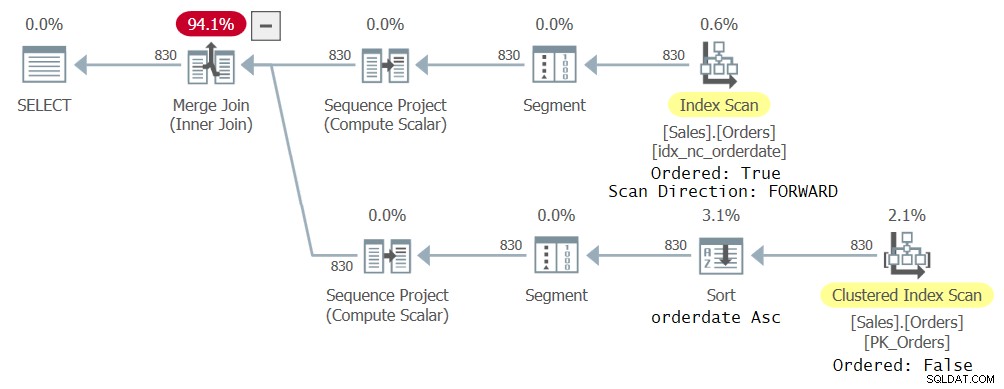 Figuur 2:Eerste plan voor zoekopdracht met twee CTE-referenties
Figuur 2:Eerste plan voor zoekopdracht met twee CTE-referenties
Wat hier interessant is om op te merken, is dat de optimizer ervoor heeft gekozen om verschillende indexen te gebruiken om de verschillende CTE-referenties te verwerken, omdat hij dat als optimaal beschouwde. Elke verwijzing in de buitenste query heeft immers betrekking op een andere subset van de CTE-kolommen. Eén referentie resulteerde in een geordende voorwaartse scan van de index idx_nc_orderedate, en de andere in een ongeordende scan van de geclusterde index gevolgd door een sorteerbewerking op orderdatum oplopend. Hoewel de index idx_nc_orderedate expliciet alleen in de orderdate-kolom als sleutel wordt gedefinieerd, wordt deze in de praktijk gedefinieerd op (orderdate, orderid) als zijn sleutels, aangezien orderid de geclusterde indexsleutel is en wordt opgenomen als de laatste sleutel in alle niet-geclusterde indexen. Dus een geordende scan van de index zendt eigenlijk de rijen uit die zijn geordend op orderdatum, orderid. Wat betreft de ongeordende scan van de geclusterde index, op het niveau van de opslagengine, worden de gegevens gescand in de volgorde van de indexsleutel (gebaseerd op orderid) om tegemoet te komen aan minimale consistentieverwachtingen van het standaard isolatieniveau dat is vastgelegd. De sorteeroperator neemt daarom de gegevens op die zijn geordend op orderid, sorteert de rijen op orderdatum en geeft in de praktijk de rijen uit die zijn geordend op orderdatum, orderid.
Nogmaals, in theorie is er geen garantie dat de twee referenties altijd dezelfde resultatenset vertegenwoordigen, zelfs als de onderliggende gegevens niet veranderen. Een eenvoudige manier om dit aan te tonen is door twee verschillende optimale indexen voor de twee referenties te rangschikken, maar de ene de gegevens te laten ordenen op orderdatum ASC, orderid ASC, en de andere de gegevens te ordenen op orderdatum DESC, orderid ASC (of precies het tegenovergestelde). We hebben de voormalige index al. Hier is de code om de laatste te maken:
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
Voer de code een tweede keer uit na het maken van de index:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Ik kreeg de volgende uitvoer bij het uitvoeren van deze code na het maken van de nieuwe index:
orderid shipcountry orderid ----------- --------------- ----------- 10251 France 10250 10250 Brazil 10251 10261 Brazil 10260 10260 Germany 10261 10271 USA 10270 ... 11070 Germany 11073 11077 USA 11074 11076 France 11075 11075 Switzerland 11076 11074 Denmark 11077 (546 rows affected)
Oeps.
Bekijk het queryplan voor deze uitvoering zoals weergegeven in Afbeelding 3:
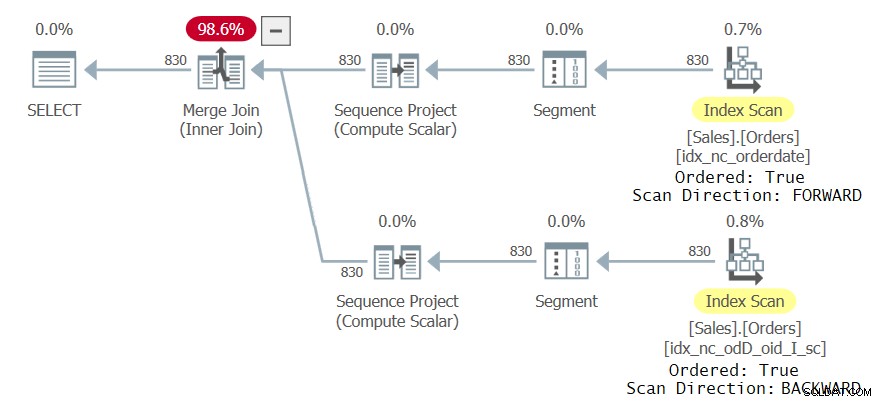 Figuur 3:Tweede plan voor zoekopdracht met twee CTE-referenties
Figuur 3:Tweede plan voor zoekopdracht met twee CTE-referenties
Merk op dat de bovenste tak van het plan de index idx_nc_orderdate op een geordende voorwaartse manier scant, waardoor de Sequence Project-operator die de rijnummers berekent, de gegevens in de praktijk op volgorde van orderdatum ASC, orderid ASC, opneemt. De onderste tak van het plan scant de nieuwe index idx_nc_odD_oid_I_sc op een geordende achterwaartse manier, waardoor de Sequence Project-operator de gegevens in de praktijk op volgorde van orderdatum ASC, orderid DESC, opneemt. Dit resulteert in een andere rangschikking van rijnummers voor de twee CTE-referenties wanneer er meer dan één exemplaar van dezelfde orderdatumwaarde is. Bijgevolg genereert de zoekopdracht een niet-lege resultatenset.
Als je dergelijke bugs wilt vermijden, is een voor de hand liggende optie om het resultaat van de innerlijke query te behouden in een tijdelijk object zoals een tijdelijke tabel of tabelvariabele. Als u echter een situatie heeft waarin u liever vasthoudt aan het gebruik van CTE's, is een eenvoudige oplossing om de totale volgorde in de vensterfunctie te gebruiken door een tiebreaker toe te voegen. Met andere woorden, zorg ervoor dat u bestelt op een combinatie van uitdrukkingen die een rij uniek identificeert. In ons geval kun je eenvoudig orderid expliciet toevoegen als een tiebreaker, zoals:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; U krijgt zoals verwacht een lege resultatenset:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Zonder verdere indexen toe te voegen, krijgt u het plan weergegeven in Afbeelding 4:
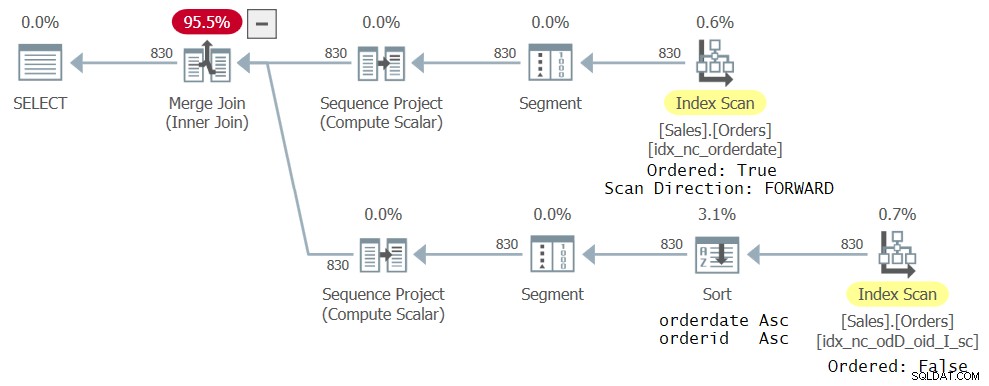 Figuur 4:Derde plan voor zoekopdracht met twee CTE-referenties
Figuur 4:Derde plan voor zoekopdracht met twee CTE-referenties
De bovenste tak van het plan is hetzelfde als voor het vorige plan dat wordt getoond in figuur 3. De onderste tak is echter een beetje anders. De nieuwe index die eerder is gemaakt, is niet echt ideaal voor de nieuwe query in die zin dat deze niet de gegevens heeft die zijn geordend zoals de ROW_NUMBER-functie nodig heeft (besteldatum, bestel-ID). Het is nog steeds de smalste dekkingsindex die de optimizer kon vinden voor zijn respectievelijke CTE-referentie, dus het is geselecteerd; het is echter gescand op een Ordered:False-manier. Een expliciete sorteeroperator sorteert de gegevens vervolgens op orderdatum, orderid zoals de ROW_NUMBER berekening nodig heeft. Natuurlijk kunt u de indexdefinitie wijzigen om zowel orderdatum als orderid dezelfde richting te laten gebruiken en op deze manier wordt de expliciete sortering uit het plan geëlimineerd. Het belangrijkste punt is echter dat je door gebruik te maken van Total Ordering, voorkomt dat je in de problemen komt door deze specifieke bug.
Als je klaar bent, voer je de volgende code uit om op te schonen:
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;
Conclusie
Het is belangrijk om te begrijpen dat meerdere verwijzingen naar dezelfde CTE vanuit een buitenste zoekopdracht resulteren in afzonderlijke evaluaties van de innerlijke zoekopdracht van de CTE. Wees vooral voorzichtig met niet-deterministische berekeningen, aangezien de verschillende evaluaties tot verschillende waarden kunnen leiden.
Wanneer u vensterfuncties zoals ROW_NUMBER en aggregaties met een frame gebruikt, moet u ervoor zorgen dat u de totale volgorde gebruikt om te voorkomen dat u verschillende resultaten krijgt voor dezelfde rij in de verschillende CTE-referenties.