U heeft allemaal wel eens gehoord over schalen - uw architectuur moet schaalbaar zijn, u moet in staat zijn om op te schalen om aan de vraag te voldoen, enzovoort, enzovoort. Wat betekent het als we het hebben over databases? Hoe ziet de schaalvergroting er achter de schermen uit? Dit onderwerp is uitgebreid en er is geen manier om alle aspecten te behandelen. Deze serie van twee blogposts is een poging om u inzicht te geven in het onderwerp van databaseschaalbaarheid.
Waarom schalen we?
Laten we eerst eens kijken wat schaalbaarheid inhoudt. Kortom, we hebben het over het vermogen om een hogere belasting van uw databasesystemen aan te kunnen. Het kan een kwestie zijn van het omgaan met kortstondige pieken in de activiteit, het kan een kwestie zijn van het omgaan met een geleidelijk toenemende werkdruk in uw database-omgeving. Er kunnen tal van redenen zijn om schaalvergroting te overwegen. De meeste van hen hebben hun eigen uitdagingen. We kunnen wat tijd besteden aan het doornemen van voorbeelden van de situatie waarin we misschien willen uitschalen.
Verbruik van hulpbronnen Toename
Dit is de meest algemene - uw belasting is zodanig toegenomen dat uw bestaande bronnen er niet langer mee om kunnen gaan. Het kan van alles zijn. De CPU-belasting is toegenomen en uw databasecluster kan geen gegevens meer leveren met een redelijke en stabiele uitvoeringstijd voor query's. Het geheugengebruik is zodanig gegroeid dat de database niet langer CPU-gebonden is, maar I/O-gebonden is geworden, en als zodanig zijn de prestaties van de databaseknooppunten aanzienlijk verminderd. Netwerk kan net zo goed een bootle-neck zijn. U zult er misschien versteld van staan welke limieten met betrekking tot netwerken uw cloudinstanties hebben toegewezen. In feite kan dit de meest voorkomende limiet worden waarmee u te maken krijgt, aangezien het netwerk alles in de cloud is - niet alleen de gegevens die tussen de applicatie en de database worden verzonden, maar ook de opslag wordt via het netwerk aangesloten. Het kan ook schijfgebruik zijn - je hebt gewoon bijna geen schijfruimte meer of, gezien het feit dat we tegenwoordig behoorlijk grote schijven kunnen hebben, is de database groter geworden dan de "beheersbare" grootte. Onderhoud, zoals schemawijzigingen, wordt een uitdaging, de prestaties worden verminderd vanwege de gegevensomvang, het duurt eeuwen om back-ups te voltooien. Al die gevallen kunnen een geldige reden zijn voor opschaling.
Plotselinge toename van de werkdruk
Een ander voorbeeld waarbij schalen vereist is, is een plotselinge toename van de werkdruk. Om de een of andere reden (of het nu marketinginspanningen zijn, inhoud die viraal gaat, een noodsituatie of een vergelijkbare situatie) ervaart uw infrastructuur een aanzienlijke toename van de belasting van het databasecluster. CPU-belasting gaat over het dak, schijf-I/O vertraagt de query's enz. Vrijwel elke bron die we in de vorige sectie noemden, kan overbelast raken en problemen veroorzaken.
Geplande operatie
De derde reden die we willen benadrukken is de meer algemene - een soort geplande operatie. Het kan een geplande marketingactiviteit zijn waarvan u verwacht dat deze meer verkeer zal opleveren, Black Friday, load-tests of vrijwel alles dat u van tevoren weet.
Elk van deze redenen heeft zijn eigen kenmerken. Als je van tevoren kunt plannen, kun je het proces tot in detail voorbereiden, testen en uitvoeren wanneer je maar wilt. Je zult het waarschijnlijk graag doen in een periode van "weinig verkeer", zolang zoiets in je workloads bestaat (het hoeft niet te bestaan). Aan de andere kant zullen plotselinge pieken in de belasting, vooral als ze significant genoeg zijn om de productie te beïnvloeden, een onmiddellijke reactie afdwingen, hoe voorbereid u ook bent en hoe veilig het ook is - als uw services al worden beïnvloed, kunt u net zo goed gewoon ga ervoor in plaats van te wachten.
Typen database-schaling
Er zijn twee hoofdtypen schalen:verticaal en horizontaal. Beide hebben voor- en nadelen, beide zijn nuttig in verschillende situaties. Laten we ze eens bekijken en gebruiksscenario's voor beide scenario's bespreken.
Verticale schaal
Deze schalingsmethode is waarschijnlijk de oudste:als je hardware niet krachtig genoeg is om de werklast aan te kunnen, voer deze dan uit. We hebben het hier gewoon over het toevoegen van bronnen aan bestaande knooppunten met de bedoeling ze capabel genoeg te maken om de gegeven taken uit te voeren. Dit heeft enkele gevolgen die we graag willen bespreken.
Voordelen van verticaal schalen
Het belangrijkste is dat alles hetzelfde blijft. Je had drie knooppunten in een databasecluster, je hebt nog steeds drie knooppunten, alleen capabeler. Het is niet nodig om uw omgeving opnieuw te ontwerpen, te wijzigen hoe de toepassing toegang moet krijgen tot de database - alles blijft precies hetzelfde omdat er qua configuratie niets is veranderd.
Een ander belangrijk voordeel van verticaal schalen is dat het erg snel kan zijn, vooral in cloudomgevingen. Het hele proces is eigenlijk om het bestaande knooppunt te stoppen, de hardware te wijzigen en het knooppunt opnieuw te starten. Voor klassieke, on-prem setups, zonder enige virtualisatie, kan dit lastig zijn - je hebt misschien geen snellere CPU's beschikbaar om te wisselen, het upgraden van schijven naar groter of sneller kan ook tijdrovend zijn, maar voor cloudomgevingen, openbaar of privé, dit kan net zo eenvoudig zijn als het uitvoeren van drie opdrachten:stop instance, upgrade instance naar groter formaat, start instance. Virtuele IP's en opnieuw koppelbare volumes maken het gemakkelijk om gegevens tussen instanties te verplaatsen.
Nadelen van verticaal schalen
Het belangrijkste nadeel van verticaal schalen is dat het zijn beperkingen heeft. Als u de grootste beschikbare instantie gebruikt, met de snelste schijfvolumes, kunt u niet veel anders doen. Het is ook niet zo eenvoudig om de prestaties van uw databasecluster aanzienlijk te verhogen. Het hangt meestal af van de initiële instantiegrootte, maar als u al behoorlijk performante knooppunten gebruikt, kunt u mogelijk geen 10x scale-out bereiken met verticaal schalen. Knooppunten die 10x sneller zouden zijn, bestaan misschien gewoon niet.
Horizontaal schalen
Horizontaal schalen is een ander beest. In plaats van omhoog te gaan met de instantiegrootte, blijven we op hetzelfde niveau, maar breiden we horizontaal uit door meer knooppunten toe te voegen. Nogmaals, er zijn voor- en nadelen van deze methode.
Voordelen van horizontaal schalen
Het belangrijkste voordeel van horizontaal schalen is dat, in theorie, de lucht de limiet is. Er is geen kunstmatige harde limiet voor scale-out, hoewel er wel limieten zijn, voornamelijk omdat communicatie binnen een cluster steeds groter wordt en meer overhead met elk nieuw knooppunt dat aan het cluster wordt toegevoegd.
Een ander belangrijk voordeel is dat u het cluster kunt opschalen zonder downtime. Als u hardware wilt upgraden, moet u de instantie stoppen, upgraden en opnieuw beginnen. Als u meer knooppunten aan het cluster wilt toevoegen, hoeft u alleen maar die knooppunten in te richten, de software te installeren die u nodig hebt, inclusief de database, en deze lid te laten worden van het cluster. Optioneel (afhankelijk of het cluster interne methoden heeft om nieuwe knooppunten met de gegevens in te richten) moet u mogelijk zelf gegevens inrichten. Meestal is het echter een geautomatiseerd proces.
Nadelen van horizontaal schalen
Het grootste probleem waarmee u te maken heeft, is dat het toevoegen van steeds meer knooppunten het moeilijk maakt om de hele omgeving te beheren. Je moet kunnen zien welke nodes beschikbaar zijn, zo'n lijst moet worden onderhouden en bijgewerkt met elke nieuwe node die wordt gemaakt. Mogelijk hebt u externe oplossingen nodig, zoals directoryservice (Consul of Etcd) om de knooppunten en hun status bij te houden. Dit verhoogt uiteraard de complexiteit van de hele omgeving.
Een ander potentieel probleem is dat het uitschaalproces tijd kost. Het toevoegen van nieuwe nodes en het voorzien van software en vooral data kost tijd. Hoeveel, hangt af van de hardware (voornamelijk I/O en netwerkdoorvoer) en de grootte van de gegevens. Voor grote opstellingen kan dit een aanzienlijke hoeveelheid tijd zijn en dit kan een blokkade zijn voor situaties waarin de opschaling onmiddellijk moet gebeuren. Het is mogelijk niet acceptabel om uren te wachten om nieuwe knooppunten toe te voegen als het databasecluster zodanig wordt beïnvloed dat bewerkingen niet correct worden uitgevoerd.
Vereisten voor schalen
Gegevensreplicatie
Voordat er een poging tot schalen kan worden gedaan, moet uw omgeving aan een aantal vereisten voldoen. Om te beginnen moet uw toepassing kunnen profiteren van meer dan één knooppunt. Als het slechts één knooppunt kan gebruiken, zijn uw opties vrijwel beperkt tot verticaal schalen. Je kunt de grootte van zo'n node vergroten of wat hardwarebronnen toevoegen aan de bare-metalserver en deze performanter maken, maar dat is het beste wat je kunt doen:je wordt altijd beperkt door de beschikbaarheid van meer performante hardware en uiteindelijk zul je merken dat jezelf zonder een optie om verder op te schalen.
Aan de andere kant, als u over de middelen beschikt om meerdere databaseknooppunten door uw toepassing te gebruiken, kunt u profiteren van horizontale schaling. Laten we hier stoppen en bespreken wat je nodig hebt om meerdere nodes daadwerkelijk optimaal te benutten.
Om te beginnen, de mogelijkheid om lees- en schrijfbewerkingen te splitsen. Traditioneel maakt de applicatie verbinding met slechts één knooppunt. Dat knooppunt wordt gebruikt om alle schrijf- en leesbewerkingen af te handelen die door de toepassing worden uitgevoerd.

Het toevoegen van een tweede knooppunt aan het cluster, vanuit het oogpunt van schaling, verandert niets . U moet er rekening mee houden dat, als één knooppunt uitvalt, het andere het verkeer moet afhandelen, dus op geen enkel moment mag de som van de belasting over beide knooppunten te hoog zijn voor één enkel knooppunt.

Met drie beschikbare knooppunten kunt u twee knooppunten volledig gebruiken. Dit stelt ons in staat om een deel van het leesverkeer uit te schalen:als één knooppunt 100% capaciteit heeft (en we zouden liever maximaal 70% draaien), dan vertegenwoordigen twee knooppunten 200%. Drie knooppunten:300%. Als één knooppunt niet werkt en we de resterende knooppunten bijna tot het uiterste drijven, kunnen we zeggen dat we in staat zijn om met 170 - 180% van een enkele knooppuntcapaciteit te werken als het cluster verslechterd is. Dat geeft ons een mooie belasting van 60% op elk knooppunt als alle drie de knooppunten beschikbaar zijn.
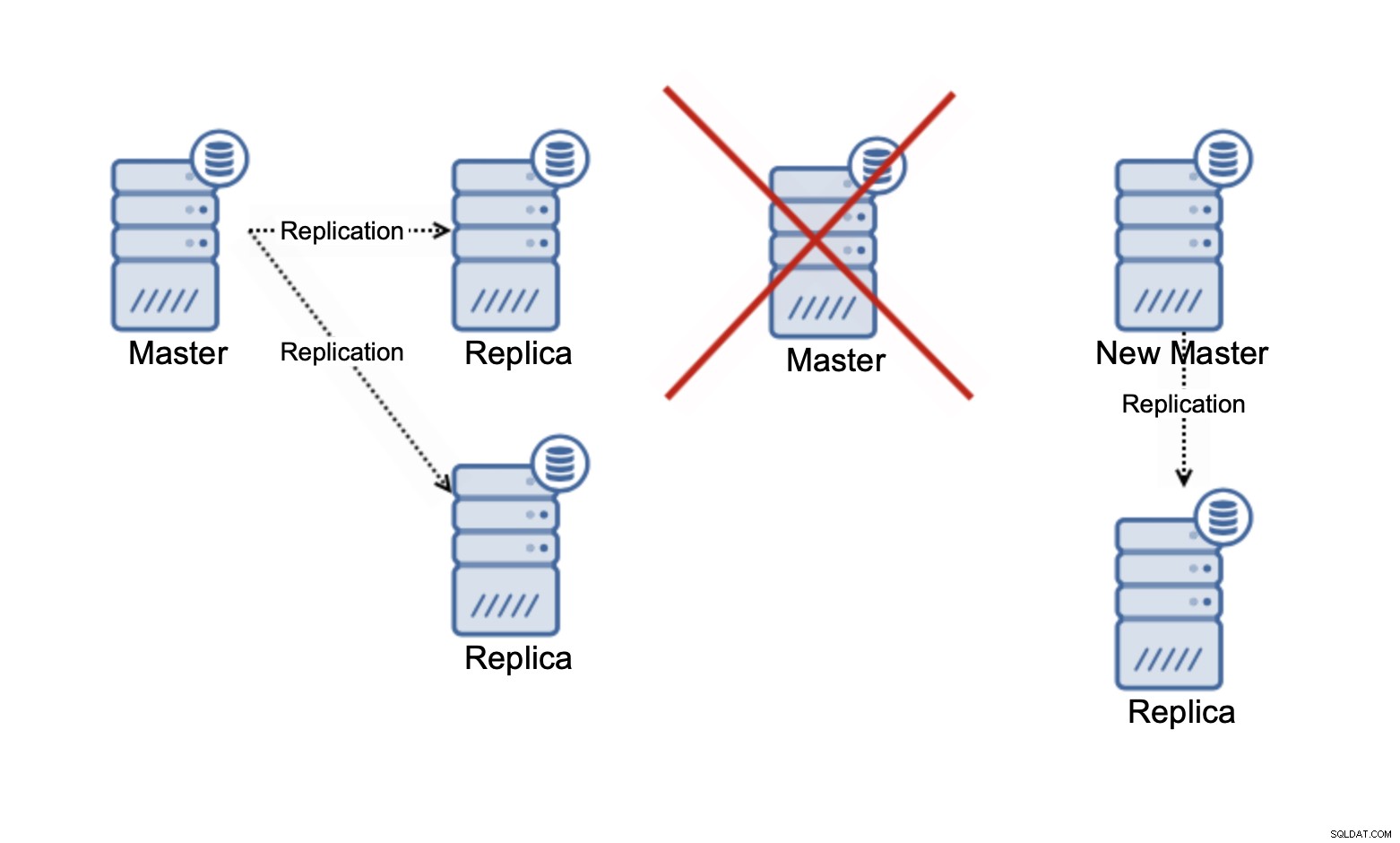
Houd er rekening mee dat we het op dit moment alleen hebben over het schalen van leesbewerkingen . Op geen enkel moment kan replicatie uw schrijfcapaciteit verbeteren. Bij asynchrone replicatie heb je maar één schrijver (master), en voor de synchrone replicatie, zoals Galera, waarbij de dataset wordt gedeeld door alle knooppunten, moet elke schrijfactie op één knooppunt worden uitgevoerd op de resterende knooppunten van de TROS.
In een Galera-cluster met drie knooppunten, als u één rij schrijft, schrijft u in feite drie rijen, één voor elk knooppunt. Het toevoegen van meer nodes of replica's zal geen verschil maken. In plaats van dezelfde rij op drie knooppunten te schrijven, schrijft u deze op vijf. Dit is de reden waarom het splitsen van uw schrijfbewerkingen in een multi-mastercluster, waar de dataset wordt gedeeld over alle knooppunten (er zijn multi-masterclusters waar gegevens worden geshard, bijvoorbeeld MySQL NDB-cluster - hier is het verhaal over schrijfschaalbaarheid totaal anders), heeft niet zo veel zin. Het voegt overhead toe aan het omgaan met potentiële schrijfconflicten over alle knooppunten, terwijl het niet echt iets verandert met betrekking tot de totale schrijfcapaciteit.
Loadbalancing en lezen/schrijven split
De mogelijkheid om leesbewerkingen te splitsen van schrijfbewerkingen is een must als u uw leesbewerkingen wilt schalen in asynchrone replicatieconfiguraties. U moet schrijfverkeer naar één knooppunt kunnen sturen en vervolgens de leesbewerkingen naar alle knooppunten in de replicatietopologie sturen. Zoals we eerder vermeldden, is deze functionaliteit ook heel handig in de multi-masterclusters, omdat het ons in staat stelt om de schrijfconflicten te verwijderen die kunnen optreden als u probeert de schrijfbewerkingen over meerdere knooppunten in het cluster te verdelen. Hoe kunnen we de lees/schrijf-splitsing uitvoeren? Er zijn verschillende methoden die u kunt gebruiken om dit te doen. Laten we even in dit onderwerp duiken.
Toepassingsniveau R/W-splitsing
Het meest eenvoudige scenario, ook het minst frequente:uw applicatie kan worden geconfigureerd welke knooppunten schrijfbewerkingen moeten ontvangen en welke knooppunten leesbewerkingen moeten ontvangen. Deze functionaliteit kan op een aantal manieren worden geconfigureerd, de meest eenvoudige is de hardgecodeerde lijst van de knooppunten, maar het kan ook iets zijn in de trant van dynamische knooppuntinventaris die wordt bijgewerkt door achtergrondthreads. Het grootste probleem met deze aanpak is dat de hele logica als onderdeel van de applicatie moet worden geschreven. Met een hardgecodeerde lijst met knooppunten zou in het eenvoudigste scenario wijzigingen in de toepassingscode nodig zijn voor elke wijziging in de replicatietopologie. Aan de andere kant zouden meer geavanceerde oplossingen, zoals het implementeren van een servicedetectie, op de lange termijn complexer zijn om te onderhouden.
R/W gesplitste connector
Een andere optie zou zijn om een connector te gebruiken om een lees/schrijf-splitsing uit te voeren. Ze hebben niet allemaal deze optie, maar sommige wel. Een voorbeeld is php-mysqlnd of Connector/J. Hoe het in de applicatie is geïntegreerd, kan verschillen op basis van de connector zelf. In sommige gevallen moet de configuratie in de applicatie worden gedaan, in sommige gevallen moet dit in een apart configuratiebestand voor de connector. Het voordeel van deze aanpak is dat zelfs als je je applicatie moet uitbreiden, de meeste nieuwe code klaar is voor gebruik en wordt onderhouden door externe bronnen. Het maakt het gemakkelijker om met dergelijke instellingen om te gaan en u hoeft minder code te schrijven (indien aanwezig).
R/W-splitsing in loadbalancer
Eindelijk een van de beste oplossingen:loadbalancers. Het idee is simpel:geef uw gegevens door aan een loadbalancer die onderscheid kan maken tussen lezen en schrijven en deze naar een juiste locatie sturen. Dit is een grote verbetering vanuit het oogpunt van bruikbaarheid, omdat we databasedetectie en queryrouting kunnen scheiden van de toepassing. Het enige dat de applicatie hoeft te doen, is het databaseverkeer naar een enkel eindpunt te sturen dat bestaat uit een hostnaam en een poort. De rest gebeurt op de achtergrond. Loadbalancers werken eraan om de query's naar een backend-databaseknooppunten te routeren. Loadbalancers kunnen ook replicatietopologie ontdekken of u kunt een goede service-inventarisatie implementeren met behulp van etcd of consul en deze bijwerken via uw infrastructuurorkestratietools zoals Ansible.
Hiermee is het eerste deel van deze blog afgesloten. In de tweede bespreken we de uitdagingen waarmee we worden geconfronteerd bij het schalen van de databaselaag. We zullen ook enkele manieren bespreken waarop we onze databaseclusters kunnen uitbreiden.