Ik ben mijn huis aan het opruimen (te laat in de zomer om te proberen het door te geven als voorjaarsschoonmaak). Je weet wel, kasten opruimen, het speelgoed van de kinderen doorzoeken en de kelder ordenen. Het is een pijnlijk proces. Toen we 10 jaar geleden naar ons huis verhuisden, hadden we ZO veel ruimte. Nu heb ik het gevoel dat er overal spullen zijn, en het maakt het moeilijker om te vinden wat ik echt zoek en het duurt steeds langer om op te ruimen en te ordenen.
Klinkt dit als elke database die u beheert?
Veel klanten met wie ik heb gewerkt, hebben te maken met het opschonen van gegevens als een bijzaak. Op het moment van de implementatie wil iedereen alles bewaren. "We weten nooit wanneer we het nodig hebben." Na een jaar of twee realiseert iemand zich dat er veel extra dingen in de database staan, maar nu zijn mensen bang om er vanaf te komen. "We moeten contact opnemen met Legal om te zien of we het kunnen verwijderen." Maar niemand neemt contact op met Legal, of als iemand dat doet, gaat Legal terug naar de bedrijfseigenaren om te vragen wat ze moeten behouden, en dan komt het project tot stilstand. "We kunnen het niet eens worden over wat er kan worden verwijderd." Het project is vergeten, en dan, twee of vier jaar verder, is de database plotseling een terabyte, moeilijk te beheren, en mensen wijten alle prestatieproblemen aan de grootte van de database. Je hoort de woorden 'partitioneren' en 'database archiveren' rondslingeren, en soms mag je gewoon een heleboel gegevens verwijderen, wat zijn eigen problemen heeft.
In het ideale geval moet u vóór de implementatie of binnen de eerste zes tot twaalf maanden na de ingebruikname beslissen over uw zuiveringsstrategie. Maar aangezien we dat stadium voorbij zijn, laten we eens kijken naar de impact die deze extra gegevens kunnen hebben.
Testmethodologie
Om de toon te zetten, nam ik een kopie van de Credit-database en herstelde deze naar mijn SQL Server 2012-instantie. Ik liet de drie bestaande niet-geclusterde indexen vallen en voegde er twee van mezelf toe:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Vervolgens heb ik het aantal rijen in de tabel verhoogd tot 14,4 miljoen, door de originele set rijen meerdere keren opnieuw in te voegen en de datums enigszins aan te passen:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Ten slotte heb ik een testharnas opgezet om elk vier keer een reeks instructies tegen de database uit te voeren. De uitspraken staan hieronder:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Voor elke instructie die ik uitvoerde
DBCC DROPCLEANBUFFERS; GO
om de bufferpool te wissen. Uiteraard is dit niet iets om uit te voeren tegen een productieomgeving. Ik deed het hier om een consistent startpunt voor elke test te bieden.
Na elke uitvoering heb ik de tabel dbo.charge vergroot door de 14,4 miljoen rijen waarmee ik begon in te voegen, maar ik heb de charge_dt voor elke uitvoering met een jaar verhoogd. Bijvoorbeeld:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Na de toevoeging van 14,4 miljoen rijen, heb ik het testharnas opnieuw uitgevoerd. Ik herhaalde dit zes keer, waarbij ik in wezen zes "jaren" aan gegevens toevoeg. De tabel dbo.charge begon met gegevens uit 1999 en bevatte na herhaalde invoegingen gegevens tot en met 2005.
Resultaten
De resultaten van de executies zijn hier te zien:
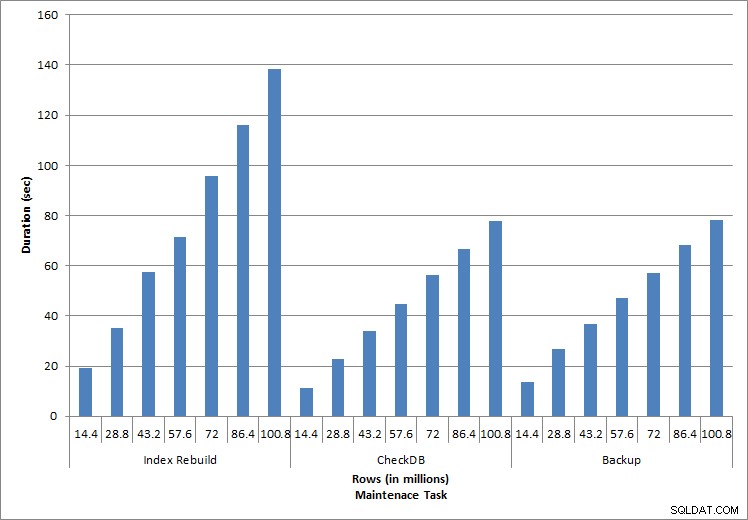
Duur van onderhoudstaken
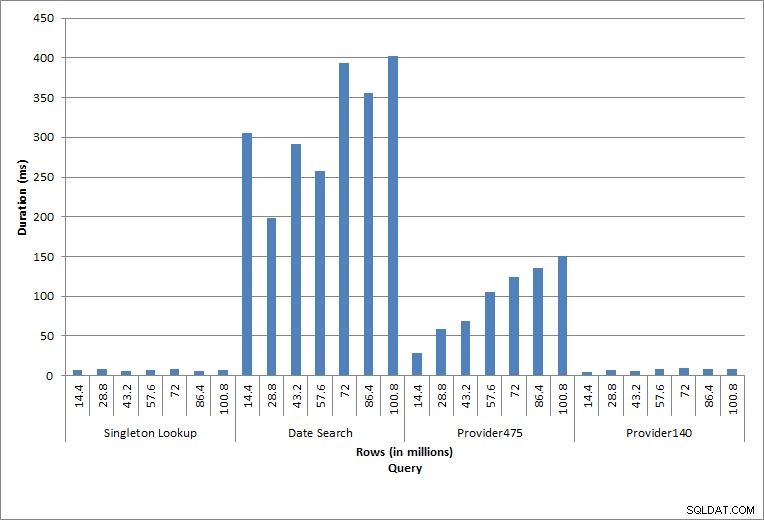
Duur van zoekopdrachten
De individuele uitgevoerde instructies weerspiegelen typische database-activiteit. Het opnieuw opbouwen van indexen, integriteitscontroles en back-ups maken deel uit van het reguliere database-onderhoud. De zoekopdrachten in de kostentabel vertegenwoordigen een singleton-zoekopdracht en drie variaties van bereikscans die specifiek zijn voor de gegevens in de tabel.
Index herbouwt, CHECKDB en back-ups
Zoals verwacht voor de onderhoudstaken, namen de duur en IO-waarden toe naarmate er meer rijen aan de database werden toegevoegd. De databasegrootte nam met een factor 10 toe, en hoewel de duur niet in hetzelfde tempo toenam, werd een consistente toename waargenomen. Elke onderhoudstaak nam aanvankelijk minder dan 20 seconden in beslag, maar naarmate er meer rijen werden toegevoegd, nam de duur van de taken toe tot bijna 1 minuut en 20 seconden voor 100 miljoen rijen (en tot meer dan 2 minuten voor het opnieuw opbouwen van de index). Dit weerspiegelt de extra tijd die SQL Server nodig heeft om de taak te voltooien vanwege aanvullende gegevens.
Eenmalig opzoeken
De zoekopdracht tegen dbo.charge voor een specifieke charge_no leverde altijd één rij op – en zou één rij hebben opgeleverd, ongeacht de gebruikte waarde, aangezien charge_no een unieke identiteit is. Er is minimale variatie voor deze zoekopdracht. Omdat er voortdurend rijen aan de tabel worden toegevoegd, kan de index met één of twee niveaus in diepte toenemen (meer naarmate de tabel breder wordt), waardoor er een paar IO's worden toegevoegd, maar dit is een singleton-zoekopdracht met heel weinig IO's.
Bereikscans
De zoekopdracht voor een datumbereik (charge_dt) is na elke invoeging gewijzigd om de gegevens van het meest recente jaar voor juli te doorzoeken (bijv. '2005-07-01' tot '2005-07-01' voor de laatste reeks tests), maar werd geretourneerd iets meer dan 1,2 miljoen rijen per keer. In een realistisch scenario verwachten we niet dat hetzelfde aantal rijen wordt geretourneerd voor dezelfde maand, jaar na jaar, en evenmin verwachten we dat hetzelfde aantal rijen wordt geretourneerd voor elke maand in een jaar. Maar het aantal rijen kan tussen de maanden binnen hetzelfde bereik blijven, met lichte stijgingen in de loop van de tijd. Er bestaan fluctuaties in de duur van deze query, maar een beoordeling van de IO-gegevens die zijn vastgelegd uit sys.dm_io_virtual_file_stats toont consistentie in het aantal leesbewerkingen.
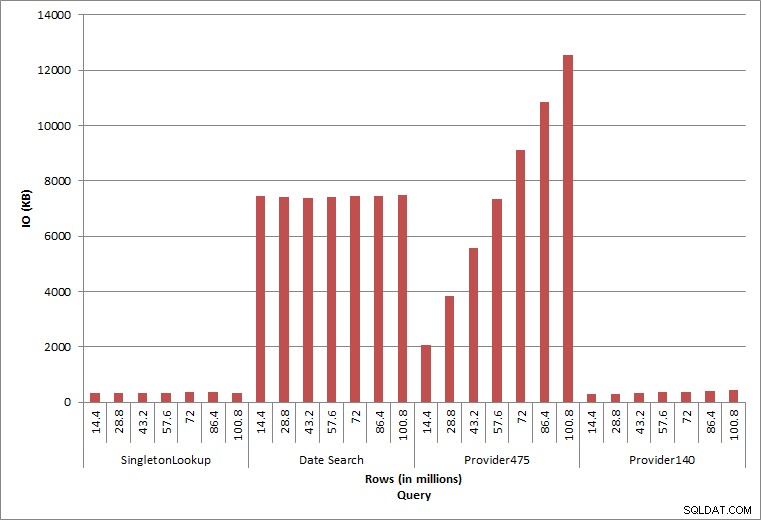
Query IO
De laatste twee query's, voor twee verschillende provider_no-waarden, tonen het ware effect van het bewaren van gegevens. In de eerste dbo.charge-tabel had provider_no 475 meer dan 126.000 rijen en provider_no 140 meer dan 1700 rijen. Voor elke 14,4 miljoen rijen die werden toegevoegd, werd ongeveer hetzelfde aantal rijen voor elke provider_no toegevoegd. In een productieomgeving is dit type gegevensdistributie niet ongebruikelijk, en query's voor deze gegevens kunnen in de eerste jaren van de oplossing goed presteren, maar kunnen na verloop van tijd verslechteren naarmate er meer rijen worden toegevoegd. De duur van de query neemt met een factor vijf toe (van 31 ms tot 153 ms) tussen de initiële en uiteindelijke uitvoering voor provider_no 475. Hoewel deze impact misschien niet significant lijkt, moet u rekening houden met de parallelle toename van IO (hierboven). Als dit een query is die met een hoge frequentie wordt uitgevoerd en/of als er vergelijkbare query's zijn die met een regelmatige frequentie worden uitgevoerd, kan de extra belasting oplopen en het algehele resourcegebruik beïnvloeden. Denk verder na over de impact wanneer u werkt met tabellen die miljarden rijen hebben en worden gebruikt in query's met complexe joins, en de impact op uw reguliere - en uiterst kritieke - onderhoudstaken. Houd tot slot rekening met de hersteltijd. Uw noodherstelplan moet gebaseerd zijn op hersteltijden, en naarmate de database groter wordt, duurt het langer voordat de database in zijn geheel is hersteld. Als u uw herstel niet regelmatig test en timet, kan het herstellen van een ramp langer duren dan u dacht.
Samenvatting
De hier getoonde voorbeelden zijn eenvoudige illustraties van wat er kan gebeuren als er geen data-archiveringsstrategie wordt bepaald tijdens de database-implementatie, en er zijn veel andere scenario's om te verkennen en te testen. Oude gegevens die zelden of nooit worden geopend, hebben meer invloed dan alleen de ruimte op de schijf. Het kan van invloed zijn op de queryprestaties en de duur van onderhoudstaken. Als DBA die meerdere databases op een instance beheert, kan één database met historische gegevens de prestatie- en onderhoudstaken van andere databases beïnvloeden. Verder, als rapporten worden uitgevoerd op basis van historische gegevens, kan dit grote schade aanrichten in de toch al drukke OLTP-omgeving.
Vanaf het begin is het van cruciaal belang dat de levensduur van gegevens in een database wordt bepaald en dat er een actieplan wordt opgesteld. Voor sommige oplossingen is het vereist om alle gegevens voor altijd te bewaren. Gebruik in dit geval strategieën om de databasegrootte beheersbaar te houden, bijvoorbeeld:archiveer de gegevens regelmatig in een aparte tabel of aparte database. In het geval dat gegevens niet jarenlang hoeven te worden bewaard, implementeert u een opschoonstrategie die gegevens op regelmatige basis verwijdert. Op deze manier gooi je het speelgoed weg waar niet meer mee gespeeld wordt, kleding die niet meer past en willekeurige rommel die je gewoon niet elke drie maanden gebruikt...in plaats van eens in de 10 jaar.