De algemene strategie die de SQL Server-database-engine gebruikt om een geïndexeerde weergave gesynchroniseerd te houden met de basistabellen - die ik in mijn laatste bericht in meer detail heb beschreven - is het uitvoeren van incrementeel onderhoud van de weergave wanneer een gegevensveranderende bewerking plaatsvindt tegen een van de tabellen waarnaar in de weergave wordt verwezen. In grote lijnen is het idee om:
- Verzamel informatie over de wijzigingen in de basistabel
- Pas de projecties, filters en joins toe die in de weergave zijn gedefinieerd
- Aggregeer de wijzigingen per geclusterde sleutel voor geïndexeerde weergave
- Bepaal of elke wijziging moet resulteren in een invoeging, update of verwijdering tegen de weergave
- Bereken de waarden die u in de weergave wilt wijzigen, toevoegen of verwijderen
- Pas de weergavewijzigingen toe
Of, nog beknopter (zij het met het risico van grove vereenvoudiging):
- Bereken de incrementele weergave-effecten van de oorspronkelijke gegevenswijzigingen;
- Pas die wijzigingen toe op de weergave
Dit is meestal een veel efficiëntere strategie dan het opnieuw opbouwen van de hele weergave na elke onderliggende gegevenswijziging (de veilige maar langzame optie), maar het vertrouwt erop dat de incrementele updatelogica correct is voor elke denkbare gegevenswijziging, tegen elke mogelijke geïndexeerde weergavedefinitie.
Zoals de titel al doet vermoeden, gaat dit artikel over een interessant geval waarin de logica van incrementele updates faalt, wat resulteert in een corrupte geïndexeerde weergave die niet langer overeenkomt met de onderliggende gegevens. Voordat we bij de bug zelf komen, moeten we snel scalaire en vectoraggregaten bekijken.
Scalaire en vectoraggregaten
Voor het geval u de term niet kent, er zijn twee soorten aggregaat. Een aggregaat dat is gekoppeld aan een GROUP BY-clausule (zelfs als de groep op lijst leeg is) staat bekend als een vectoraggregaat . Een aggregaat zonder een GROUP BY-clausule staat bekend als een scalair aggregaat .
Terwijl een vectoraggregaat gegarandeerd een enkele uitvoerrij produceert voor elke groep die aanwezig is in de dataset, zijn scalaire aggregaten een beetje anders. Scalaire aggregaten altijd produceer een enkele uitvoerrij, zelfs als de invoerset leeg is.
Voorbeeld van vectoraggregatie
Het volgende AdventureWorks-voorbeeld berekent twee vectoraggregaten (een som en een telling) op een lege invoerset:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Deze zoekopdrachten produceren de volgende uitvoer (geen rijen):

Het resultaat is hetzelfde als we de GROUP BY-component vervangen door een lege set (vereist SQL Server 2008 of later):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Ook de uitvoeringsplannen zijn in beide gevallen identiek. Dit is het uitvoeringsplan voor de telquery:
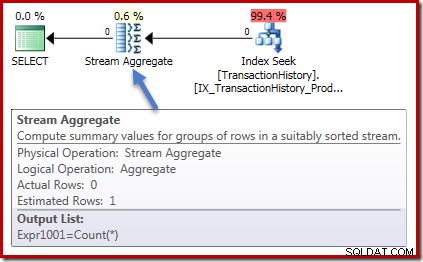
Nul rijen invoer naar het stroomaggregaat en nul rijen uit. Het uitvoeringsplan voor de som ziet er als volgt uit:

Nogmaals, nul rijen in het aggregaat en nul rijen eruit. Allemaal goede simpele dingen tot nu toe.
Scalaire aggregaten
Kijk nu wat er gebeurt als we de GROUP BY-clausule volledig uit de query's verwijderen:
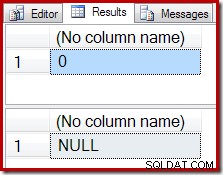
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
In plaats van een leeg resultaat, produceert het COUNT-aggregaat een nul, en de SUM retourneert een NULL:
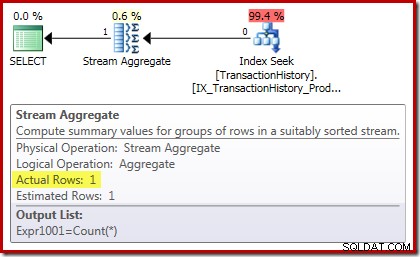
Het uitvoeringsplan voor tellingen bevestigt dat rijen met nul invoer een enkele uitvoerrij produceren van het stroomaggregaat:
Het plan voor de uitvoering van de som is nog interessanter:
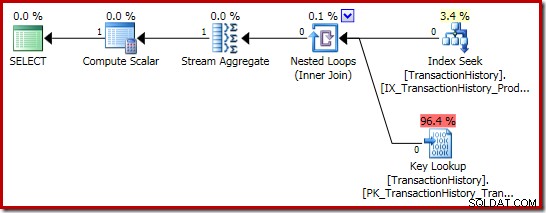
De Stream Aggregate-eigenschappen laten zien dat er een telling-aggregaat wordt berekend naast het bedrag waar we om hebben gevraagd:
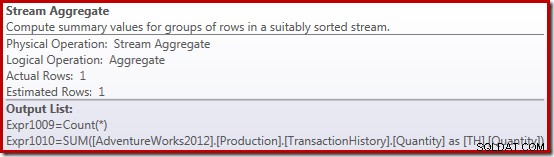
De nieuwe Compute Scalar-operator wordt gebruikt om NULL te retourneren als het aantal rijen dat door de Stream Aggregate is ontvangen nul is, anders wordt de som van de aangetroffen gegevens geretourneerd:
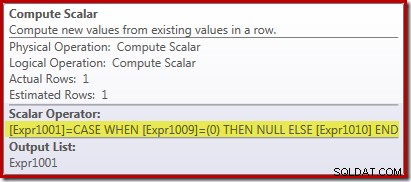
Dit lijkt misschien allemaal een beetje vreemd, maar zo werkt het:
- Een vectoraggregaat van nul rijen retourneert nul rijen;
- Een scalair aggregaat produceert altijd precies één rij uitvoer, zelfs voor een lege invoer;
- De scalaire telling van nul rijen is nul; en
- De scalaire som van nul rijen is NULL (niet nul).
Het belangrijke punt voor onze huidige doeleinden is dat scalaire aggregaten altijd een enkele rij output produceren, zelfs als dit betekent dat er een uit het niets moet worden gecreëerd. Ook is de scalaire som van nul rijen NULL, niet nul.
Deze gedragingen zijn trouwens allemaal "juist". De dingen zijn zoals ze zijn, omdat de SQL-standaard oorspronkelijk het gedrag van scalaire aggregaten niet definieerde, maar het aan de implementatie overliet. SQL Server behoudt zijn oorspronkelijke implementatie om redenen van achterwaartse compatibiliteit. Vectoraggregaten hebben altijd goed gedefinieerde gedragingen gehad.
Geïndexeerde weergaven en vectoraggregatie
Overweeg nu een eenvoudige geïndexeerde weergave met een aantal (vector)aggregaten:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); De volgende query's tonen de inhoud van de basistabel, het resultaat van het opvragen van de geïndexeerde weergave en het resultaat van het uitvoeren van de weergavequery op de tabel die aan de weergave ten grondslag ligt:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
De resultaten zijn:
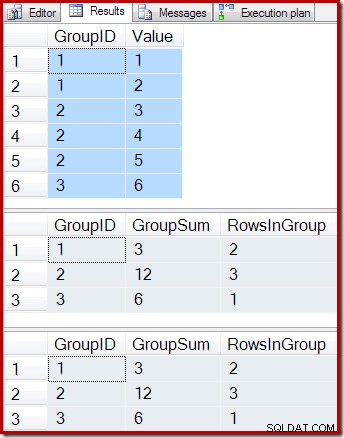
Zoals verwacht, retourneren de geïndexeerde weergave en onderliggende query exact dezelfde resultaten. De resultaten blijven gesynchroniseerd na alle mogelijke wijzigingen in de basistabel T1. Om onszelf eraan te herinneren hoe dit allemaal werkt, overweeg dan het eenvoudige geval van het toevoegen van een enkele nieuwe rij aan de basistabel:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Het uitvoeringsplan voor deze bijlage bevat alle logica die nodig is om de geïndexeerde weergave gesynchroniseerd te houden:
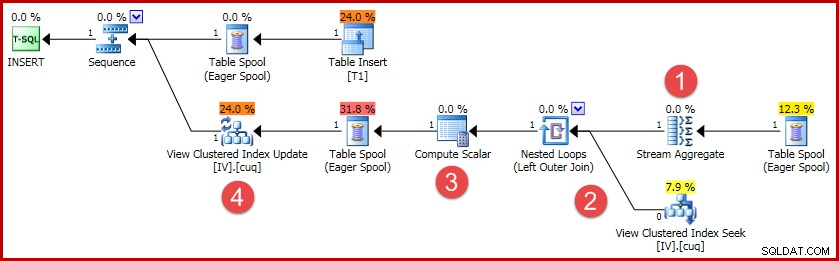
De belangrijkste activiteiten in het plan zijn:
- De Stream Aggregate berekent de wijzigingen per geïndexeerde weergavesleutel
- De buitenste verbinding met de weergave koppelt de wijzigingssamenvatting aan de rij van de doelweergave, indien aanwezig
- De Compute Scalar beslist of elke wijziging moet worden ingevoegd, bijgewerkt of verwijderd ten opzichte van de weergave, en berekent de benodigde waarden.
- De weergave-update-operator voert elke wijziging fysiek uit in de geclusterde weergave-index.
Er zijn enkele planverschillen voor verschillende wijzigingsbewerkingen ten opzichte van de basistabel (bijv. updates en verwijderingen), maar het algemene idee achter het gesynchroniseerd houden van de weergave blijft hetzelfde:aggregeer de wijzigingen per weergavesleutel, zoek de weergaverij als deze bestaat en voer vervolgens uit een combinatie van invoeg-, update- en verwijderbewerkingen op de weergave-index indien nodig.
Welke wijzigingen u in dit voorbeeld ook aanbrengt in de basistabel, de geïndexeerde weergave blijft correct gesynchroniseerd - de bovenstaande NOEXPAND- en EXPAND VIEWS-query's retourneren altijd dezelfde resultatenset. Zo zouden dingen altijd moeten werken.
Geïndexeerde weergaven en scalaire aggregatie
Probeer nu dit voorbeeld, waarbij de geïndexeerde weergave scalaire aggregatie gebruikt (geen GROUP BY-clausule in de weergave):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Dit is een volkomen legale geïndexeerde weergave; er worden geen fouten aangetroffen bij het maken ervan. Er is echter één aanwijzing dat we misschien iets vreemds doen:als het tijd is om de weergave te materialiseren door de vereiste unieke geclusterde index te maken, is er geen voor de hand liggende kolom om als sleutel te kiezen. Normaal gesproken zouden we de groeperingskolommen natuurlijk uit de GROUP BY-clausule van de weergave kiezen.
Het bovenstaande script kiest willekeurig de NumRows-kolom. Die keuze is niet belangrijk. Voel je vrij om de unieke geclusterde index te maken, hoe je maar wilt. De weergave bevat altijd precies één rij vanwege de scalaire aggregaten, dus er is geen kans op een unieke sleutelschending. In die zin is de keuze van de view-indexsleutel overbodig, maar niettemin vereist.
Door de testquery's uit het vorige voorbeeld opnieuw te gebruiken, kunnen we zien dat de geïndexeerde weergave correct werkt:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
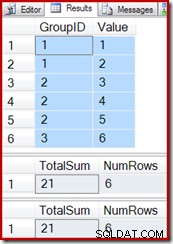
Het invoegen van een nieuwe rij in de basistabel (zoals we deden met de geïndexeerde weergave van vectoraggregatie) blijft ook correct werken:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Het uitvoeringsplan is vergelijkbaar, maar niet helemaal identiek:
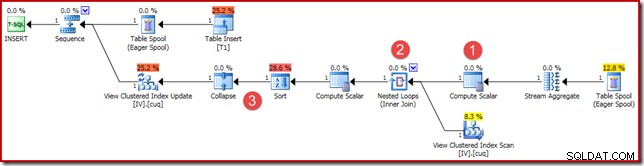
De belangrijkste verschillen zijn:
- Deze nieuwe Compute Scalar is er om dezelfde redenen als toen we eerder vector- en scalaire aggregatieresultaten vergeleken:het zorgt ervoor dat een NULL-som wordt geretourneerd (in plaats van nul) als de aggregatie werkt op een lege set. Dit is het vereiste gedrag voor een scalaire som van geen rijen.
- De eerder geziene Outer Join is vervangen door een Inner Join. Er zal altijd precies één rij in de geïndexeerde weergave zijn (vanwege de scalaire aggregatie) dus er is geen sprake van een outer join om te testen of een weergaverij overeenkomt of niet. De ene rij in de weergave vertegenwoordigt altijd de volledige set gegevens. Deze Inner Join heeft geen predikaat, dus technisch gezien is het een cross join (naar een tabel met een gegarandeerde enkele rij).
- De operators Sorteren en Samenvouwen zijn aanwezig om technische redenen die in mijn vorige artikel over onderhoud van geïndexeerde weergaven worden behandeld. Ze hebben geen invloed op de juiste werking van het onderhoud van de geïndexeerde weergave hier.
In feite kunnen in dit voorbeeld veel verschillende soorten gegevensveranderende bewerkingen met succes worden uitgevoerd tegen de basistabel T1; de effecten worden correct weergegeven in de geïndexeerde weergave. De volgende wijzigingsbewerkingen ten opzichte van de basistabel kunnen allemaal worden uitgevoerd terwijl de geïndexeerde weergave correct blijft:
- Bestaande rijen verwijderen
- Bestaande rijen bijwerken
- Nieuwe rijen invoegen
Dit lijkt misschien een uitgebreide lijst, maar dat is het niet.
De bug onthuld
Het probleem is nogal subtiel en houdt (zoals je zou verwachten) verband met het verschillende gedrag van vector- en scalaire aggregaten. De belangrijkste punten zijn dat een scalair aggregaat altijd een uitvoerrij zal produceren, zelfs als het geen rijen op zijn invoer ontvangt, en de scalaire som van een lege set NULL is, niet nul.
Om een probleem te veroorzaken, hoeven we alleen maar rijen in de basistabel in te voegen of te verwijderen.
Die verklaring is niet zo gek als het op het eerste gezicht lijkt.
Het punt is dat een invoeg- of verwijderquery die geen basistabelrijen beïnvloedt, de weergave toch zal bijwerken, omdat de scalaire stroomaggregaat in het geïndexeerde weergaveonderhoudsgedeelte van het queryplan een uitvoerrij zal produceren, zelfs als deze zonder invoer wordt gepresenteerd. De Compute Scalar die de Stream Aggregate volgt, genereert ook een NULL-som wanneer het aantal rijen nul is.
Het volgende script demonstreert de bug in actie:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
De uitvoer van dat script wordt hieronder getoond:
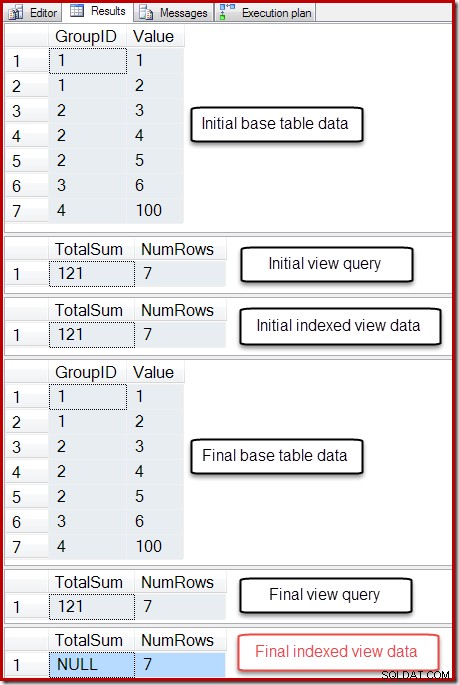
De uiteindelijke status van de kolom Totale som van de geïndexeerde weergave komt niet overeen met de onderliggende weergavequery of de basistabelgegevens. De NULL-som heeft de weergave beschadigd, wat kan worden bevestigd door DBCC CHECKTABLE uit te voeren (op de geïndexeerde weergave).
Het uitvoeringsplan dat verantwoordelijk is voor de corruptie wordt hieronder weergegeven:
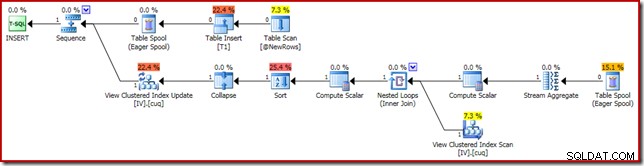
Inzoomen toont de invoer met nul rijen naar de stroomaggregaat en de uitvoer met één rij:
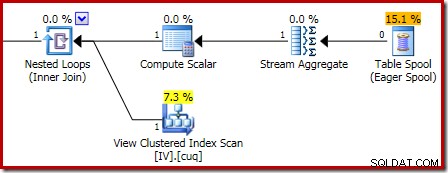
Als je het bovenstaande corruptiescript wilt proberen met een delete in plaats van een insert, is hier een voorbeeld:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
De verwijdering heeft geen invloed op de rijen van de basistabel, maar verandert de somkolom van de geïndexeerde weergave nog steeds in NULL.
De bug generaliseren
U kunt waarschijnlijk een willekeurig aantal invoegen en verwijderen van basistabelquery's bedenken die geen rijen beïnvloeden en deze geïndexeerde weergavecorruptie veroorzaken. Hetzelfde fundamentele probleem is echter van toepassing op een bredere klasse van problemen dan alleen invoegingen en verwijderingen die geen invloed hebben op basistabelrijen.
Het is bijvoorbeeld mogelijk om dezelfde corruptie te produceren met een insert dat doet rijen toevoegen aan de basistabel. Het essentiële ingrediënt is dat geen toegevoegde rijen in aanmerking komen voor de weergave . Dit resulteert in een lege invoer naar de Stream Aggregate en de corruptieveroorzakende NULL-rijuitvoer van de volgende Compute Scalar.
Een manier om dit te bereiken is door een WHERE-component in de weergave op te nemen die enkele van de basistabelrijen verwerpt:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Gezien de nieuwe beperking op groeps-ID's die in de weergave zijn opgenomen, zal de volgende invoeging rijen toevoegen aan de basistabel, maar de geïndexeerde weergave nog steeds een NULL-som maken:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; De uitvoer toont de inmiddels bekende indexcorruptie:
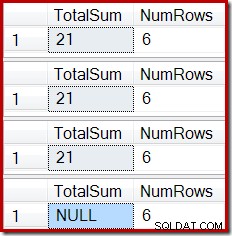
Een soortgelijk effect kan worden bereikt met een weergave die een of meer binnenverbindingen bevat. Zolang rijen die aan de basistabel zijn toegevoegd, worden afgewezen (bijvoorbeeld door niet mee te doen), ontvangt de Stream Aggregate geen rijen, genereert de Compute Scalar een NULL-som en raakt de geïndexeerde weergave waarschijnlijk beschadigd.
Laatste gedachten
Dit probleem doet zich niet voor bij update-query's (tenminste voor zover ik weet), maar dit lijkt meer per ongeluk te zijn dan ontwerp - het problematische Stream Aggregate is nog steeds aanwezig in potentieel kwetsbare updateplannen, maar de Compute Scalar die genereert de NULL-som wordt niet toegevoegd (of misschien weg geoptimaliseerd). Laat het me weten als het je lukt om de bug te reproduceren met een update-query.
Totdat deze bug is gecorrigeerd (of, misschien worden scalaire aggregaten niet toegestaan in geïndexeerde weergaven), moet u zeer voorzichtig zijn met het gebruik van aggregaten in een geïndexeerde weergave zonder een GROUP BY-clausule.
Dit artikel werd naar aanleiding van een Connect-item ingediend door Vladimir Moldovanenko, die zo vriendelijk was om een opmerking achter te laten op een oude blogpost van mij (die een andere geïndexeerde beschadiging van de weergave betreft, veroorzaakt door de MERGE-verklaring). Vladimir gebruikte om gegronde redenen scalaire aggregaten in een geïndexeerde weergave, dus oordeel niet te snel over deze bug als een randgeval dat u nooit zult tegenkomen in een productieomgeving! Mijn dank aan Vladimir voor het attenderen op zijn Connect-item.