
De T-SQL dinsdag van deze maand wordt gehost door Mike Donnelly (@SQLMD), en hij vat het onderwerp als volgt samen:
Het onderwerp van deze maand is ongecompliceerd, maar zeer open. Je moet iets nieuws leren en dan een blogpost schrijven waarin je het uitlegt.Nou, vanaf het moment dat Mike het onderwerp aankondigde, was ik niet echt van plan om iets nieuws te leren, en toen het weekend naderde en ik wist dat maandag me zou aanvallen met juryplicht, dacht ik dat ik dit moest gaan zitten maand uit.
Toen leerde Martin Smith me iets dat ik ofwel nooit wist, of lang geleden wist, maar ben vergeten (soms weet je niet wat je niet weet, en soms herinner je je niet wat je nooit wist en wat je niet kunt onthouden). Ik herinnerde me dat het veranderen van een kolom van NOT NULL naar NULL moeten een bewerking met alleen metadata zijn, waarbij het schrijven naar elke pagina wordt uitgesteld totdat die pagina om andere redenen is bijgewerkt, aangezien de NULL bitmap zou niet echt hoeven te bestaan totdat ten minste één rij NULL . zou kunnen worden .
In diezelfde post herinnerde @ypercube me ook aan dit relevante citaat van Books Online (typfout en zo):
Het wijzigen van een kolom van NOT NULL naar NULL wordt niet ondersteund als een online bewerking wanneer de gewijzigde kolom verwijzingen is door niet-geclusterde indexen."Geen online bewerking" kan worden geïnterpreteerd als "geen bewerking met alleen metagegevens" - wat betekent dat het in feite een bewerking van gegevensomvang is (hoe groter uw index, hoe langer het duurt).
Ik wilde dit bewijzen met een vrij eenvoudig (maar langdurig) experiment tegen een specifieke doelkolom om te converteren van NOT NULL naar NULL . Ik zou 3 tabellen maken, allemaal met een geclusterde primaire sleutel, maar elk met een andere niet-geclusterde index. De ene zou de doelkolom hebben als een sleutelkolom, de tweede als een INCLUDE kolom, en de derde zou helemaal niet verwijzen naar de doelkolom.
Dit zijn mijn tabellen en hoe ik ze heb ingevuld:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Elke tabel had 100.000 rijen, de geclusterde indexen hadden 310 pagina's en de niet-geclusterde indexen hadden ofwel 272 pagina's (test1 en test2 ) of 174 pagina's (test3 ). (Deze waarden zijn eenvoudig te verkrijgen via sys.dm_db_index_physical_stats .)
Vervolgens had ik een eenvoudige manier nodig om bewerkingen vast te leggen die op paginaniveau waren vastgelegd - ik koos voor sys.fn_dblog() , hoewel ik dieper had kunnen graven en direct naar pagina's had kunnen kijken. Ik heb niet de moeite genomen om met LSN-waarden te knoeien om door te geven aan de functie, aangezien ik dit niet in productie draaide en niet veel om de prestaties gaf, dus na de tests heb ik de resultaten van de functie gewoon gedumpt, met uitzondering van alle gegevens die werd gelogd voorafgaand aan de ALTER TABLE operaties.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Nu kon ik mijn tests uitvoeren, die een stuk eenvoudiger waren dan de installatie.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Nu kon ik de bewerkingen bekijken die in elk geval waren geregistreerd:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; De resultaten lijken te suggereren dat elke bladpagina van de niet-geclusterde index wordt aangeraakt voor de gevallen waarin de doelkolom op enigerlei wijze in de index werd genoemd, maar dergelijke bewerkingen vinden niet plaats in het geval dat de doelkolom in geen enkele niet-geclusterde index:
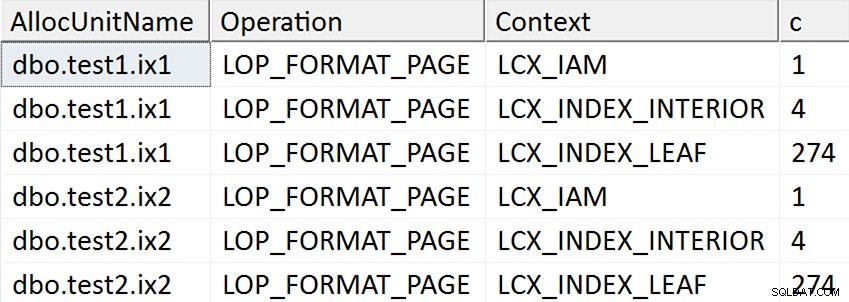
In de eerste twee gevallen worden zelfs nieuwe pagina's toegewezen (je kunt dat valideren met DBCC IND , zoals Spörri deed in zijn antwoord), dus de bewerking kan online plaatsvinden, maar dat betekent niet dat het snel is (omdat het nog steeds een kopie van al die gegevens moet wegschrijven en de NULL moet maken bitmapwijziging als onderdeel van het schrijven van elke nieuwe pagina en log al die activiteiten in).
Ik denk dat de meeste mensen zouden vermoeden dat het veranderen van een kolom van NOT NULL naar NULL zou in alle scenario's alleen metadata zijn, maar ik heb hier laten zien dat dit niet waar is als naar de kolom wordt verwezen door een niet-geclusterde index (en soortgelijke dingen gebeuren, of het nu een sleutel is of INCLUDE kolom). Misschien kan deze operatie ook worden afgedwongen om ONLINE te zijn in Azure SQL Database vandaag, of zal het mogelijk zijn in de volgende grote versie? Dit zorgt er niet noodzakelijkerwijs voor dat de daadwerkelijke fysieke operaties sneller gebeuren, maar het zal blokkering als resultaat voorkomen.
Ik heb dat scenario niet getest (en de analyse of het echt online is, is sowieso moeilijker in Azure), en ik heb het ook niet op een hoop getest. Iets waar ik in een volgende post op terug kan komen. Wees in de tussentijd voorzichtig met eventuele aannames die u maakt over bewerkingen met alleen metadata.