
Dit is ook geen goede fragmentatie
Vorige maand schreef ik over onverwachte geclusterde indexfragmentatie, dus deze keer wil ik enkele dingen bespreken die u kunt doen om indexfragmentatie te voorkomen. Ik neem aan dat je het vorige bericht hebt gelezen en bekend bent met de termen die ik daar heb gedefinieerd, en in de rest van dit artikel, als ik 'fragmentatie' zeg, verwijs ik naar zowel de logische fragmentatie als de problemen met een lage paginadichtheid.
Kies een goede clustersleutel
De duurste gegevensstructuur om op te werken om fragmentatie te verwijderen, is de geclusterde index van een tabel, omdat dit de grootste structuur is omdat deze alle tabelgegevens bevat. Vanuit het perspectief van fragmentatie is het logisch om een clustersleutel te kiezen die overeenkomt met het invoegpatroon van de tabel, zodat er geen mogelijkheid is dat een invoeging plaatsvindt op een pagina waar geen ruimte is, waardoor een pagina wordt gesplitst en fragmentatie wordt geïntroduceerd.
Wat de beste clustersleutel voor een bepaalde tabel is, is een kwestie van veel discussie, maar over het algemeen zult u niet fout gaan als uw clustersleutel de volgende eenvoudige eigenschappen heeft:
- Smal (d.w.z. zo min mogelijk kolommen)
- Statisch (d.w.z. u werkt het nooit bij)
- Uniek
- Alsmaar toenemend
Het is de steeds groter wordende eigenschap die het belangrijkst is voor het voorkomen van fragmentatie, omdat het willekeurige invoegingen vermijdt die pagina-splitsingen kunnen veroorzaken op reeds volle pagina's. Voorbeelden van zo'n sleutelkeuze zijn int identiteit en bigint identiteit kolommen, of zelfs een sequentiële GUID van de NEWSEQUENTIALID() functie.
Met dit type sleutels hebben nieuwe rijen een sleutelwaarde die gegarandeerd hoger is dan alle andere in de tabel, en dus bevindt het invoegpunt van de nieuwe rij zich aan het einde van de meest rechtse pagina in de geclusterde indexstructuur. Uiteindelijk zullen de nieuwe rijen die pagina vullen en een andere pagina zal worden toegevoegd aan de rechterkant van de index, maar zonder dat er schadelijke pagina's worden gesplitst.
Nu, als je een geclusterde indexsleutel hebt die niet steeds groter wordt, kan het een zeer complexe en onsmakelijke procedure zijn om deze te veranderen in een steeds groter wordende sleutel, dus maak je geen zorgen - in plaats daarvan kun je een vulfactor gebruiken zoals ik bespreek hieronder.
Trouwens, voor een veel dieper inzicht in het kiezen van een clustersleutel en alle gevolgen ervan, bekijk de blogcategorie van Kimberly's Clustering Key (lees van onder naar boven).
Indexsleutelkolommen niet bijwerken
Telkens wanneer een belangrijke kolom wordt bijgewerkt, is het niet alleen een eenvoudige interne update, hoewel veel plaatsen online en in boeken zeggen dat dit het geval is (ze hebben het mis). Een sleutelkolom kan niet op zijn plaats worden bijgewerkt, omdat de nieuwe sleutelwaarde dan zou betekenen dat de rij in de verkeerde sleutelvolgorde voor de index staat. In plaats daarvan wordt een sleutelkolomupdate vertaald in een volledige rij verwijderen plus een volledige rij invoegen met de nieuwe sleutelwaarde. Als de pagina waar de nieuwe rij wordt ingevoegd niet genoeg ruimte heeft, wordt de pagina gesplitst, waardoor fragmentatie ontstaat.
Het vermijden van sleutelkolomupdates zou gemakkelijk moeten zijn voor de geclusterde index, omdat het een slecht ontwerp is dat vraagt om het bijwerken van de clustersleutel van een tabelrij. Voor niet-geclusterde indexen is het echter onvermijdelijk als updates van de tabel kolommen bevatten waarop een niet-geclusterde index staat. Voor die gevallen moet u een opvulfactor gebruiken.
Kolommen met variabele lengte niet bijwerken
Deze is makkelijker gezegd dan gedaan. Als je kolommen met variabele lengte moet gebruiken en het is mogelijk dat ze worden bijgewerkt, dan is het mogelijk dat ze groter worden en dus meer ruimte nodig hebben voor de bijgewerkte rij, wat leidt tot een paginasplitsing als de pagina al vol is.
Er zijn een paar dingen die u in dit geval kunt doen om fragmentatie te voorkomen:
- Gebruik een vulfactor
- Gebruik in plaats daarvan een kolom met een vaste lengte, als de overhead van alle extra opvulbytes minder een probleem is dan fragmentatie of het gebruik van een opvulfactor
- Gebruik een tijdelijke aanduiding om ruimte voor de kolom te 'reserveren' - dit is een truc die u kunt gebruiken als de toepassing een nieuwe rij invoert en vervolgens terugkomt om enkele details in te vullen, waardoor kolomuitbreiding met variabele lengte ontstaat li>
- Voer een verwijdering plus invoegen uit in plaats van een update
Gebruik een vulfactor
Zoals u kunt zien, zijn veel van de manieren om fragmentatie te voorkomen onverteerbaar omdat ze toepassings- of schemawijzigingen met zich meebrengen, en daarom is het gebruik van een opvulfactor een gemakkelijke manier om fragmentatie te verminderen.
Een indexvulfactor is een instelling voor de index die aangeeft hoeveel lege ruimte er op elke pagina op leaf-niveau moet worden achtergelaten wanneer de index wordt gemaakt, opnieuw opgebouwd of gereorganiseerd. Het idee is dat er voldoende vrije ruimte op de pagina is om willekeurige invoegingen of rijgroei toe te staan (van een versietag die wordt toegevoegd of kolommen met variabele lengte bijgewerkt) zonder dat de pagina vol raakt en een pagina moet worden opgesplitst. Uiteindelijk zal de pagina echter vol raken, en daarom moet de vrije ruimte periodiek worden vernieuwd door de index opnieuw op te bouwen of te reorganiseren (in het algemeen indexonderhoud genoemd). De truc is om de juiste vulfactor te vinden, samen met de juiste periodiciteit van indexonderhoud.
U kunt hier meer lezen over het instellen van een vulfactor in MSDN. Trap niet in de valkuil om de vulfactor voor de hele instantie in te stellen (met sp_configure), want dat betekent dat alle indexen opnieuw worden opgebouwd of gereorganiseerd met die vulfactorwaarde, zelfs die indexen die geen fragmentatieproblemen hebben. Je wilt niet dat je grote geclusterde indexen, met mooie steeds groter wordende toetsen, allemaal 30% van hun bladruimte verspild hebben aan het voorbereiden van willekeurige invoegingen die nooit zullen gebeuren. Het is veel beter om erachter te komen welke indexen daadwerkelijk worden beïnvloed door fragmentatie en alleen daarvoor een vulfactor in te stellen.
Er is geen juist antwoord of magische formule die ik je hiervoor kan geven. De algemeen aanvaarde praktijk is om een vulfactor van 70 in te voeren (wat betekent dat er 30% vrije ruimte overblijft) voor die indexen waar fragmentatie een probleem is, te controleren hoe snel fragmentatie optreedt en vervolgens ofwel de vulfactor ofwel de onderhoudsfrequentie van de index te wijzigen (of beide).
Ja, dit betekent dat u met opzet ruimte in de indexen verspilt om fragmentatie te voorkomen, maar dat is een goede afweging, gezien hoe duur paginasplitsingen zijn en hoe schadelijk fragmentatie kan zijn voor de prestaties. En ja, ondanks wat sommigen misschien zeggen, is dit nog steeds belangrijk, zelfs als je SSD's gebruikt.
Samenvatting
Er zijn een aantal eenvoudige dingen die u kunt doen om fragmentatie te voorkomen, maar zodra u in niet-geclusterde indexen komt, of snapshot-isolatie of leesbare secondaries gebruikt, steekt fragmentatie de kop op en moet u proberen dit te voorkomen.
Schrik niet en denk niet dat je een vulfactor van 70 moet instellen voor al je instanties - je moet ze zorgvuldig kiezen en instellen, zoals ik hierboven heb beschreven.
En vergeet SQL Sentry Fragmentation Manager niet, die u kunt gebruiken (als een add-on voor Performance Advisor) om erachter te komen waar fragmentatieproblemen zich bevinden en deze vervolgens aan te pakken. Op het tabblad Indexen kunt u bijvoorbeeld eenvoudig uw indexen sorteren op de hoogste fragmentatie eerst (en, als u wilt, een filter toepassen op de kolom voor het tellen van rijen, om uw kleinere tabellen te negeren):
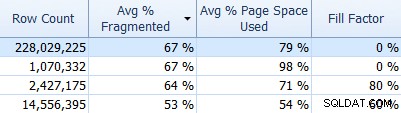
En kijk dan of die indexen de standaard opvulfactor (0%) gebruiken, of misschien een niet-standaard opvulfactor, die misschien niet goed past bij uw gegevens en DML-patronen. Ik laat je raden welke in de bovenstaande schermafbeelding ik het meest zou willen onderzoeken. Het implementeren van meer geschikte indexvulfactoren is de eenvoudigste manier om eventuele problemen aan te pakken.