Als consultant die met SQL Server werkt, word ik vaak gevraagd om naar een server te kijken die prestatieproblemen lijkt te hebben. Bij het uitvoeren van triage op de server stel ik bepaalde vragen, zoals:wat is uw normale CPU-gebruik, wat zijn uw gemiddelde schijflatenties, wat is uw normale geheugengebruik, enzovoort. Het antwoord is meestal:"we weten het niet" of "we leggen die informatie niet regelmatig vast." Het ontbreken van een recente baseline maakt het erg moeilijk om te weten hoe abnormaal gedrag eruitziet. Als u niet weet wat normaal gedrag is, hoe weet u dan zeker of het beter of slechter gaat? Ik gebruik vaak de uitdrukkingen:"als je het niet meet, kun je het niet meten", en "als je het niet meet, kun je het niet beheren."
Vanuit het oogpunt van monitoring moeten organisaties minimaal controleren op mislukte taken zoals back-ups, indexonderhoud, DBCC CHECKDB en andere belangrijke taken. Het is eenvoudig om hiervoor storingsmeldingen in te stellen; u hebt echter ook een proces nodig om ervoor te zorgen dat de taken worden uitgevoerd zoals verwacht. Ik heb banen gezien die vastlopen en nooit worden voltooid. Een storingsmelding zou geen alarm activeren, omdat de taak nooit slaagt of mislukt.
Vanuit een prestatiebasislijn zijn er verschillende belangrijke statistieken die moeten worden vastgelegd. Ik heb een proces gemaakt dat ik met klanten gebruik en dat regelmatig belangrijke statistieken vastlegt en die waarden opslaat in een gebruikersdatabase. Mijn proces is eenvoudig:een speciale database met opgeslagen procedures die gemeenschappelijke scripts gebruiken die de resultatensets in tabellen invoegen. Ik heb SQL Agent-taken om de opgeslagen procedures met regelmatige tussenpozen uit te voeren en een opschoningsscript om gegevens ouder dan X dagen op te schonen. De statistieken die ik altijd vastleg zijn onder meer:
Levensverwachting van pagina :PLE is waarschijnlijk een van de beste manieren om te meten of uw systeem onder interne geheugendruk staat. De meeste systemen hebben PLE-waarden die fluctueren tijdens normale werkbelasting. Ik vind het leuk om deze waarden te trenden om te weten wat de minimale, gemiddelde en maximale waarden zijn. Ik probeer graag te begrijpen waardoor PLE op bepaalde momenten van de dag daalde om te zien of die processen kunnen worden afgestemd. Vaak doet iemand een tafelscan en spoelt de bufferpool door. Het kan helpen om die zoekopdrachten correct te indexeren. Zorg ervoor dat u de juiste PLE-teller in de gaten houdt - zie hier .
CPU-gebruik :Als u een basislijn voor CPU-gebruik heeft, weet u of uw systeem plotseling onder CPU-druk staat. Wanneer een gebruiker klaagt over prestatieproblemen, merken ze vaak dat de CPU er hoog uitziet. Als de CPU bijvoorbeeld rond de 80% schommelt, kunnen ze dat zorgwekkend vinden, maar als de CPU de afgelopen weken ook 80% was in dezelfde tijd toen er geen problemen werden gemeld, is de kans dat de CPU het probleem is erg klein. Trending CPU is niet alleen bedoeld om vast te leggen wanneer de CPU piekt en constant hoog blijft. Ik heb talloze verhalen over de tijd dat ik in een 'severity one'-conferentiebrug werd gebracht omdat er een probleem was met een aanvraag. Als DBA droeg ik de hoed van 'Default Blame Acceptor'. Toen het applicatieteam zei dat er een probleem was met de database, was het aan mij om te bewijzen dat dit niet het geval was, de databaseserver was schuldig totdat zijn onschuld bewezen was. Ik herinner me nog levendig een incident waarbij het applicatieteam er zeker van was dat de databaseserver problemen had omdat gebruikers geen verbinding konden maken. Ze hadden op internet gelezen dat SQL Server zou kunnen lijden aan uithongering van de threadpool als het verbindingen zou weigeren. Ik sprong op de server en begon te kijken naar bronnen en welke processen er op dat moment draaiden. Binnen een paar minuten meldde ik terug dat de server in kwestie zich erg verveelde. Op basis van onze baseline-statistieken was de CPU meestal 60% en was deze ongeveer 20% inactief, was de levensduur van de pagina merkbaar hoger dan normaal, en er was geen vergrendeling of blokkering, I/O zag er geweldig uit, geen fouten in logs, en de sessietellingen waren ongeveer 1/3 van hun normale telling. Ik maakte toen de opmerking:"Het lijkt erop dat gebruikers de databaseserver niet eens bereiken." Dat trok de aandacht van de netwerkmensen en ze realiseerden zich dat een wijziging die ze aanbrachten in de load balancer niet goed werkte en ze stelden vast dat meer dan 50% van de verbindingen verkeerd werd gerouteerd en de databaseserver niet bereikte. Als ik niet had geweten wat de basislijn was, had het veel langer geduurd voordat we de resolutie hadden bereikt.
Schijf-I/O :Het vastleggen van schijfstatistieken is erg belangrijk. De DMV sys.dm_io_virtual_file_stats is cumulatief sinds de laatste herstart van de server. Door uw I/O-latenties over een tijdsinterval vast te leggen, krijgt u een basislijn van wat normaal is gedurende die tijd. Als u op de cumulatieve waarde vertrouwt, kunt u vertekende gegevens krijgen van activiteiten na kantooruren of lange perioden waarin het systeem niet actief was. Paul besprak dat hier .
Databasebestandsgroottes :Als u een inventaris van uw databases heeft, inclusief bestandsgrootte, gebruikte grootte, vrije ruimte en meer, kunt u de databasegroei voorspellen. Vaak wordt mij gevraagd om te voorspellen hoeveel opslagruimte er het komende jaar nodig is voor een databaseserver. Zonder de wekelijkse of maandelijkse groeitrend te kennen, kan ik op geen enkele manier intelligent een cijfer bedenken. Zodra ik deze waarden begin te volgen, kan ik dit op de juiste manier trenden. Naast trending kon ik ook vinden wanneer er onverwachte databasegroei was. Wanneer ik onverwachte groei zie en onderzoek, merk ik meestal dat iemand een tabel dupliceerde om wat testen uit te voeren (ja, in productie!) Of een ander eenmalig proces deed. Door dit soort gegevens te volgen en te kunnen reageren wanneer zich afwijkingen voordoen, kunt u laten zien dat u proactief bent en over uw systemen waakt.
Wachtstatistieken :Het bewaken van wachtstatistieken kan u helpen de oorzaak van bepaalde prestatieproblemen te achterhalen. Veel nieuwe DBA's maken zich zorgen wanneer ze voor het eerst onderzoek gaan doen naar wachtstatistieken en zich niet realiseren dat er altijd wachttijden zijn, en dat is precies de manier waarop het planningssysteem van SQL Server werkt. Er zijn ook veel wachttijden die als goedaardig of meestal ongevaarlijk kunnen worden beschouwd. Paul Randal sluit deze meestal ongevaarlijke wachttijden uit in zijn populaire script voor wachtstatistieken. Paul heeft ook een uitgebreide bibliotheek gebouwd met de verschillende wachttypen en latch-klassen met beschrijvingen en andere informatie over het oplossen van problemen met wachttijden en vergrendelingen.
Ik heb mijn gegevensverzamelingsproces gedocumenteerd en je kunt de code vinden op mijn blog . Afhankelijk van de situatie en het soort problemen dat een klant kan hebben, wil ik misschien ook aanvullende statistieken vastleggen. Glenn Berry blogde over een proces dat hij samenstelde dat het gemiddelde aantal taken, het gemiddelde aantal uitvoerbare taken, het gemiddelde aantal in behandeling zijnde I/O's, het CPU-gebruik van het SQL Server-proces en de gemiddelde levensduur van de pagina voor alle NUMA-knooppunten vastlegt. Een snelle zoekopdracht op internet zal verschillende andere gegevensverzamelingsprocessen opleveren die mensen hebben gedeeld, zelfs het SQL Server Tiger Team heeft een proces dat gebruikmaakt van T-SQL en PowerShell.
Het gebruik van een aangepaste database en het bouwen van uw eigen gegevensverzamelingspakket is een geldige oplossing voor het vastleggen van een baseline, maar de meesten van ons zijn niet bezig met het bouwen van volledige SQL Server-bewakingsoplossingen. Er is nog veel meer dat nuttig zou kunnen zijn om vast te leggen, zaken als langlopende queries, topquery's en opgeslagen procedures op basis van geheugen, I/O en CPU, deadlocks, indexfragmentatie, transacties per seconde en nog veel meer. Daarvoor raad ik klanten altijd aan een monitoringtool van derden aan te schaffen. Deze leveranciers zijn gespecialiseerd in het op de hoogte blijven van de nieuwste trends en functies van SQL Server, zodat u uw tijd kunt besteden aan het zo stabiel en snel mogelijk maken van SQL Server.
Oplossingen zoals SQL Sentry (voor SQL Server) en DB Sentry (voor Azure SQL Database) legt al deze metrische gegevens voor u vast, zodat u eenvoudig verschillende basislijnen kunt maken. U kunt een normale basislijn, maandeinde, kwartaaleinde en meer hebben. U kunt dan de basislijn toepassen en visueel zien hoe de dingen anders zijn. Wat nog belangrijker is, u kunt een willekeurig aantal waarschuwingen configureren voor verschillende omstandigheden en een melding ontvangen wanneer de metrische gegevens uw drempels overschrijden.
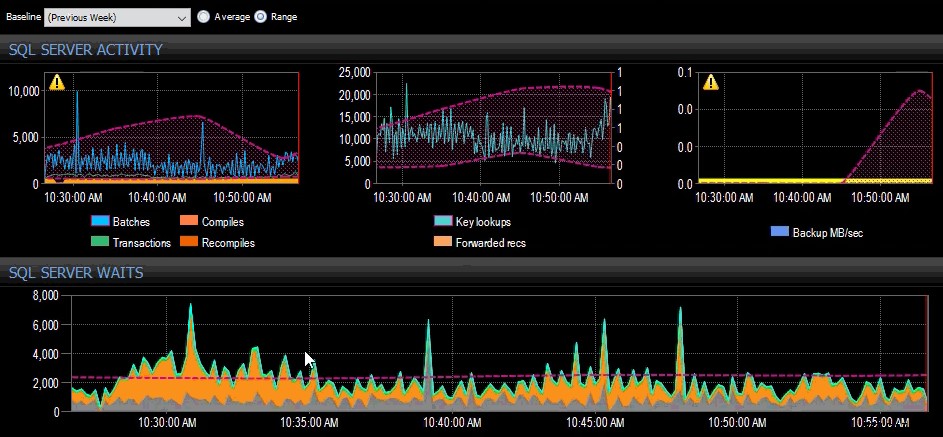 De basislijn van vorige week toegepast op verschillende SQL Server-statistieken op het SQL Sentry-dashboard.
De basislijn van vorige week toegepast op verschillende SQL Server-statistieken op het SQL Sentry-dashboard.
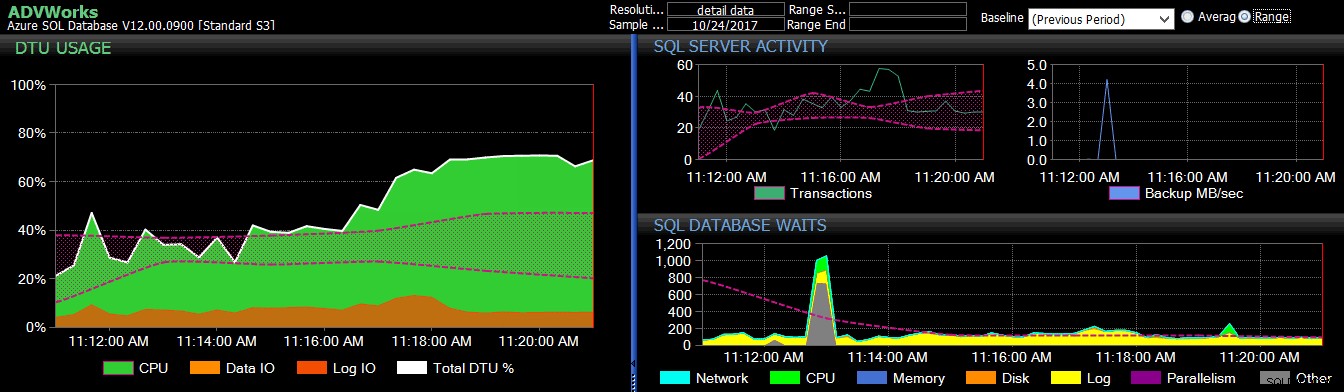 De basislijn van de vorige periode is toegepast op verschillende Azure SQL Database-metrische gegevens op het DB Sentry-dashboard.
De basislijn van de vorige periode is toegepast op verschillende Azure SQL Database-metrische gegevens op het DB Sentry-dashboard.
Voor meer informatie over baselines in SentryOne, zie deze berichten op hun teamblog, of deze video van 2 minuten op dinsdag . Geïnteresseerd in het downloaden van een proefversie? Ze hebben je daar ook gedekt .