Vorig jaar presenteerde ik een oplossing om uitleesbare secundaire bestanden van de Beschikbaarheidsgroep te simuleren zonder te investeren in Enterprise Edition. Niet om mensen ervan te weerhouden Enterprise Edition te kopen, aangezien er veel voordelen zijn buiten AG's, maar vooral voor degenen die geen enkele kans hebben om ooit Enterprise Edition te hebben:
- Leesbare secundaire artikelen met een beperkt budget
Ik probeer een meedogenloze pleitbezorger te zijn voor de Standard Edition-klant; het is bijna een lopende grap dat zeker - gezien het aantal functies dat het in elke nieuwe release krijgt - die editie als geheel op het pad van afschaffing staat. Tijdens privévergaderingen met Microsoft heb ik erop aangedrongen dat functies ook worden opgenomen in de Standard Edition, vooral met functies die veel voordeliger zijn voor kleine bedrijven dan die met een onbeperkt hardwarebudget.
Enterprise Edition-klanten profiteren van de beheers- en prestatievoordelen die worden geboden door tabelpartitionering, maar deze functie is niet beschikbaar in Standard Edition. Onlangs viel me het idee op dat er een manier is om op zijn minst een deel van de voordelen van partitionering in elke editie te bereiken, en dat er geen gepartitioneerde views nodig zijn. Dit wil niet zeggen dat gepartitioneerde weergaven geen haalbare optie zijn die het overwegen waard is; deze worden goed beschreven door anderen, waaronder Daniel Hutmacher (Gepartitioneerde weergaven over tabelpartitionering) en Kimberly Tripp (Gepartitioneerde tabellen v. Gepartitioneerde weergaven – waarom zijn ze er nog?). Mijn idee is net iets eenvoudiger te implementeren.
Je nieuwe held:gefilterde indexen
Nu, ik weet het, deze functie is voor sommigen een woord van vier letters; voordat u verder gaat, moet u tevreden zijn met gefilterde indexen, of op zijn minst op de hoogte zijn van hun beperkingen. Wat leesvoer om je een redelijk evenwicht te geven voordat ik je probeer te verkopen:
- Ik heb het over verschillende tekortkomingen in Hoe gefilterde indexen een krachtigere functie zouden kunnen zijn, en wijs op tal van Connect-items waarop u kunt stemmen;
- Paul White (@SQL_Kiwi) praat over afstemmingsproblemen in Optimizer-beperkingen met gefilterde indexen en ook in Een onverwacht neveneffect van het toevoegen van een gefilterde index; en,
- Jes Borland (@grrl_geek) vertelt ons wat je wel en niet kunt doen met gefilterde indexen.
Die allemaal lezen? En je bent er nog? Geweldig.
De TL;DR hiervan is dat je gefilterde indexen kunt gebruiken om al je "hot data" in een afzonderlijke fysieke structuur te houden, en zelfs op afzonderlijke onderliggende hardware (je hebt misschien een snelle SSD- of PCIe-schijf beschikbaar, maar het kan' niet de hele tafel vasthouden).
Een snel voorbeeld
Er zijn veel gevallen waarin een deel van de gegevens veel vaker wordt opgevraagd dan de rest - denk aan een winkel die bestellingen beheert, een bakkerij die de bezorging van bruidstaarten plant of een voetbalstadion dat aanwezigheids- en concessiegegevens meet. In deze gevallen hebben de meeste of alle dagelijkse zoekopdrachten betrekking op "actuele" gegevens.
Laten we het simpel houden; we zullen een database maken met een zeer smalle Orders-tabel:
CREATE DATABASE PoorManPartition; GO USE PoorManPartition; GO CREATE TABLE dbo.Orders ( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, ...other columns... );
Stel nu dat u genoeg ruimte op uw snelle opslag heeft om een maand aan gegevens te bewaren (met voldoende ruimte om rekening te houden met seizoensinvloeden en toekomstige groei). We kunnen een nieuwe bestandsgroep toevoegen en een gegevensbestand op de snelle schijf plaatsen.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData; GO ALTER DATABASE PoorManPartition ADD FILE ( Name = N'HotData', FileName = N'Z:\folder\HotData.mdf', Size = 100MB, FileGrowth = 25MB ) TO FILEGROUP HotData;
Laten we nu een gefilterde index maken op onze HotData-bestandsgroep, waar het filter alles vanaf begin november 2015 omvat en de algemene kolommen die betrokken zijn bij op tijd gebaseerde query's in de sleutel- of include-lijst staan:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151101'
AND OrderDate < '20151201'
ON HotData; We kunnen een paar rijen invoegen en het uitvoeringsplan controleren om er zeker van te zijn dat gedekte zoekopdrachten in feite de index kunnen gebruiken:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 3
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106'; Het resulterende uitvoeringsplan gebruikt inderdaad de gefilterde index (ook al komt het filterpredikaat in de query niet exact overeen met de indexdefinitie):
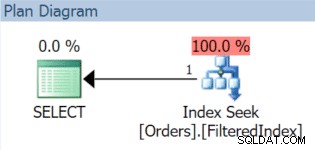
Nu, 1 december rolt rond, en het is tijd om onze november-gegevens uit te wisselen en te vervangen door december. We kunnen de gefilterde index gewoon opnieuw maken met een nieuw filterpredikaat en de DROP_EXISTING gebruiken optie:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151201'
AND OrderDate < '20160101'
WITH (DROP_EXISTING = ON)
ON HotData; Nu kunnen we nog een paar rijen toevoegen, de partitiestatistieken controleren en onze vorige query uitvoeren en een nieuwe om de gebruikte indexen te controleren:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 5
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151202'
AND OrderDate < '20151204'; In dit geval krijgen we een geclusterde indexscan met de november-query:
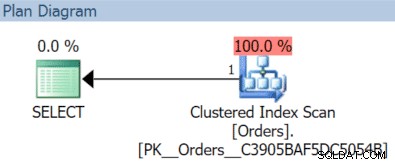
(Maar dat zou anders zijn als we een aparte, niet-gefilterde index hadden met OrderDate als sleutel.)
En ik zal het niet nog een keer laten zien, maar met de december-query krijgen we dezelfde gefilterde indexzoekopdracht als voorheen.
U kunt ook meerdere indexen bijhouden, één voor de huidige maand, één voor de vorige maand, enzovoort, en u kunt ze gewoon afzonderlijk beheren (op 1 december laat u de index gewoon van oktober vallen en laat u bijvoorbeeld die van november met rust) . U kunt ook meerdere indexen bijhouden van kortere of langere tijdsperioden (huidige en vorige week, huidig en vorig kwartaal), enz. De oplossing is behoorlijk flexibel.
Vanwege de beperkingen van gefilterde indexen, zal ik niet proberen dit als een perfecte oplossing te pushen, noch als een volledige vervanging voor tabelpartitionering of gepartitioneerde weergaven. Het uitschakelen van een partitie is bijvoorbeeld een metadatabewerking, terwijl u een index opnieuw maakt met DROP_EXISTING kan veel logboekregistratie hebben (en aangezien u niet op Enterprise Edition zit, kan het niet online worden uitgevoerd). U zult misschien ook merken dat gepartitioneerde weergaven meer uw snelheid zijn - er is meer werk aan het onderhouden van afzonderlijke fysieke tabellen en de beperkingen die de gepartitioneerde weergave mogelijk maken, maar de uitbetaling in termen van queryprestaties kan in sommige gevallen beter zijn.
Automatisering
Het opnieuw maken van de index kan vrij eenvoudig worden geautomatiseerd, met behulp van een eenvoudige taak die één keer per maand zoiets doet (of wat uw "hot" venstergrootte ook is):
DECLARE @sql NVARCHAR(MAX), @dt DATE = DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql = N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate >= ''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING = ON) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
U kunt ook maanden van tevoren meerdere indexen maken, net zoals toekomstige partities van tevoren maken - de toekomstige indexen nemen immers geen ruimte in beslag totdat er gegevens zijn die relevant zijn voor hun predikaten. En je kunt gewoon de indexen laten vallen die de oudere gegevens segmenteerden die je nu koud wilt laten worden.
Achteraf
Nadat ik dit artikel had voltooid, kwam ik natuurlijk nog een van Kimberly Tripp's berichten tegen, die je moet lezen voordat je verder gaat met iets waar ik hier voor pleit (en die ik had gelezen voordat ik begon):
- Hoe zit het met gefilterde indexen in plaats van partitionering?
Om meerdere redenen is Kimberly veel meer voorstander van gepartitioneerde weergaven om iets te implementeren dat lijkt op partitionering in Standard Edition; voor bepaalde scenario's intrigeert het gebruik van gefilterde indexen me echter nog steeds genoeg om door te gaan met mijn experimenten. Een van de gebieden waar gefilterde indexen nuttig kunnen zijn, is wanneer uw "hot" gegevens meerdere criteria hebben - niet alleen gesegmenteerd op datum, maar ook op andere kenmerken (misschien wilt u snelle query's op alle bestellingen van deze maand die voor een specifiek niveau zijn van de klant of boven een bepaald bedrag in dollars).
Volgende…
In een toekomstig bericht zal ik met dit concept spelen op een duurder systeem, met wat real-world volume en werklast. Ik wil prestatieverschillen ontdekken tussen deze oplossing, een niet-gefilterde dekkingsindex, een gepartitioneerde weergave en een gepartitioneerde tabel. Binnen een VM op een laptop met alleen beschikbare SSD's zou waarschijnlijk geen realistische of eerlijke tests op schaal opleveren.