Als ze horen wat ik doe, hebben mensen de neiging me dezelfde vraag te stellen:Kun je een systeem ontwikkelen dat de resultaten van voetbalwedstrijden voorspelt? Of Olympische medailleresultaten? Persoonlijk heb ik niet veel vertrouwen in voorspellingen. Maar als we een grote hoeveelheid historische gegevens en relevante indicatoren zouden hebben, zouden we zeker een systeem kunnen ontwerpen om ons te helpen met nauwkeuriger aannames te komen. In dit artikel bekijken we een model dat de resultaten van wedstrijden en toernooien kan opslaan.
Dit model is voornamelijk gericht op Europese voetbal (voetbal) wedstrijden, statistieken en resultaten, maar het kan gemakkelijk worden aangepast om plaats te bieden aan vele andere sporten. Mijn belangrijkste motivatie voor dit artikel waren de twee grote voetbalevenementen van dit jaar:het UEFA Euro 2016-kampioenschap dat net plaatsvond, en de Olympische Zomerspelen 2016 die nu plaatsvinden.
Wat weten we voordat het toernooi begint?
Voordat het toernooi begint, weten we er bijna alles van, behalve het belangrijkste:wie gaat er winnen. Laten we kort aangeven wat we al weten:
- De datums waarop het toernooi begint en eindigt
- De locaties waar de wedstrijden plaatsvinden
- De exacte tijden waarop de wedstrijden beginnen
- Welke teams hebben zich gekwalificeerd voor het toernooi
- De spelers van elk van deze teams
- De eerdere prestaties van elke speler en hun huidige vorm
Welke wedstrijddetails willen we opslaan?
Toernooien bestaan uit meerdere wedstrijden. Voordat we wedstrijddetails opslaan, moeten we:
- Verbind elke wedstrijd met het toernooi
- Registreer de toernooifase waarin de wedstrijd werd gespeeld (bijv. groepsfase, halve finales)
We moeten ook details voor afzonderlijke wedstrijden opslaan, waaronder:
- De teams die bij de wedstrijd betrokken zijn
- Startopstellingen en wissels
- Wedstrijdevenementen (in het voetbal zijn dit:doelpunt, penalty, fout, gele kaart, enz.)
- Eindscore
- Acties van spelers tijdens de wedstrijd
We gebruiken deze gegevens om alle belangrijke wedstrijdgebeurtenissen vast te leggen. Het vergelijken van de prestaties van een speler voor en tijdens de wedstrijd zou tot bepaalde conclusies kunnen leiden. Misschien zouden we de uiteindelijke resultaten van hun prestaties niet kunnen voorspellen (d.w.z. een overwinning of een verlies), maar statistieken kunnen ons zeker helpen om met een zekere mate van betrouwbaarheid aannames te doen.
Introductie van het model
Het model is verdeeld in vier hoofdgebieden:
Tournament detailsMatch detailsEventsIndicators and Performance
De tabellen buiten deze gebieden zijn woordenboeken (sport , phase , position ), catalogi (sport_event , team , player ) en een enkele veel-op-veel-relatie (plays ).
We zullen eerst de niet-gecategoriseerde tabellen beschrijven en daarna elk gebied nader bekijken.
De niet-gecategoriseerde tabellen
Deze tabellen zijn belangrijk omdat tabellen uit alle vier de gebieden ze gebruiken als woordenboeken of catalogi.

De sport tabel geeft een overzicht van alle sporten die we in onze database zullen opslaan. We zullen hier waarschijnlijk maar één sport hebben, herenvoetbal, maar deze tabel geeft ons de flexibiliteit om gelijkaardige sporten toe te voegen (bijv. damesvoetbal) indien nodig.

In het sport_event tabel, slaan we de evenementen op die verband houden met onze sport(en). Een voorbeeld hiervan zijn de "Olympische Spelen van 2016".
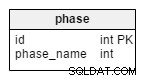
De phase table is een woordenboek dat alle mogelijke toernooifasen bevat. Het bevat waarden zoals “groepsfase” , “ronde van 16” , “kwartfinales” , “halve finale” , “finale” .
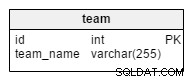
Het team tabel is, zoals je zou raden, een eenvoudige lijst van alle teams. Mogelijke waarden zijn “Kroatië” , “Polen” , “VS” enz. Als we de database gebruiken om informatie over club- of competitiecompetitie op te slaan, zouden we ook waarden hebben zoals "Barcelona" , "Real Madrid" , “Bayern” , "Manchester United" enz.
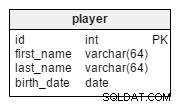
In de player tabel, slaan we records op voor alle spelers die tot de relevante teams behoren.
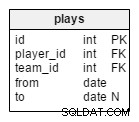
De plays tafel is onze enige veel-op-veel relatie, en het brengt spelers en teams met elkaar in verband. Een speler kan tegelijkertijd tot meer dan één team behoren (bijvoorbeeld het nationale team en een club), maar tijdens een toernooi spelen ze uiteraard maar voor één team.
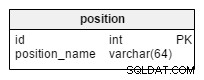
Ten slotte hebben we de position tafel. Dit eenvoudige woordenboek slaat een lijst op van alle vereiste posities. In het voetbal zijn dit onder meer keeper, centrale verdediger, spits, enz.
Toernooidetails
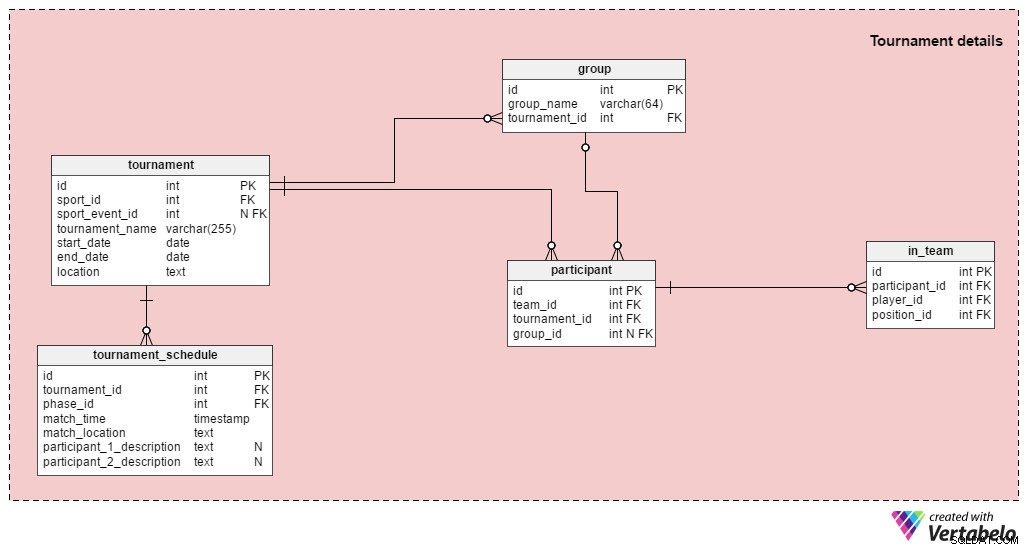
Opmerking: Als u alleen de resultaten van enkele wedstrijden wilt opslaan, hoeft u deze sectie niet te gebruiken.
Een toernooi bestaat uit meer dan één wedstrijd; zowel UEFA Euro 2016 als de voetbalevenementen op de Olympische Zomerspelen 2016 zijn toernooien. Zoals we al eerder zeiden, kunnen we een enkele wedstrijd in onze database opslaan, maar we kunnen ook wedstrijden relateren aan hun relevante toernooien. De tafels in de sectie Toernooi zijn:
tournament– Dit bevat alle basistoernooigegevens:de sport, startdatum, einddatum, enz. We moeten ook de toernooinaam opslaan en een beschrijving van waar het plaatsvindt. Desport_event_idattribuut is optioneel omdat een toernooi niet gekoppeld hoeft te zijn aan een groter evenement (zoals de Olympische Spelen).group– Dit geeft een overzicht van alle groepen in dat toernooi. UEFA Euro 2016 had zes groepen, A tot F.participant– Dit zijn de teams die in het toernooi spelen; elke deelnemer kan aan een groep worden toegewezen. De meeste toernooien beginnen met een groepsfase en gaan dan door naar een knock-outfase (bijv. UEFA Euro, UEFA World Cup, Olympisch voetbal). Sommige toernooien hebben alleen een groepsfase (bijvoorbeeld nationale competities), terwijl andere alleen een knock-outfase hebben (bijvoorbeeld nationale bekers).in_team– Deze tabel biedt een veel-op-veel-relatie waarin informatie wordt opgeslagen over de spelers die voor dat toernooi zijn geregistreerd en hun verwachte posities.tournament_schedule– Naar mijn mening is dit de meest interessante tabel in deze sectie. De lijst van alle gespeelde wedstrijden tijdens dit toernooi wordt hier opgeslagen. Detournament_idattribuut geeft aan tot welk toernooi elke wedstrijd behoort, en dephase_idattribuut definieert de fase waarin de wedstrijd zal plaatsvinden. We slaan ook de wedstrijdlocatie op en het tijdstip waarop deze begint. Beide deelnemers worden beschreven met tekstvelden. Wanneer de groepsfase is afgelopen, weten we alle matchups voor de eliminatieronde. Aan het begin van UEFA Euro 2016 wisten we bijvoorbeeld dat de winnaar van Groep E (1E) zou spelen tegen de nummer twee van Groep D (2D). Nadat alle drie de ronden in de groepsfase waren gespeeld, was dit paar Italië vs. Spanje.
Overeenkomstdetails
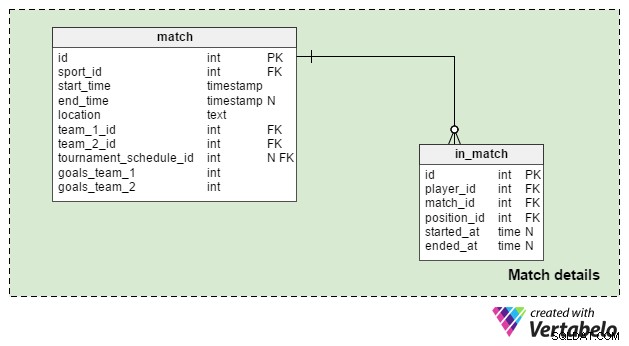
De Match details gebied wordt gebruikt om gegevens voor enkele wedstrijden op te slaan. We gebruiken twee tabellen:
match– Dit bevat alle details over een enkele wedstrijd; deze wedstrijd kan gerelateerd zijn aan een toernooi, maar het kan ook een enkele wedstrijd zijn. Dus detournament_schedule_idattribuut is optioneel en we slaan desport_id. op ,start_timeenlocationattributen hier weer. Als de wedstrijd deel uitmaakt van een toernooi, dantournament_schedule_idkrijgt een waarde toegewezen. Deteam_1_identeam_2_idattributen zijn verwijzingen naar de teams die bij de wedstrijd betrokken zijn. Degoals_team_1engoals_team_2attributen bevatten het resultaat van de wedstrijd. Ze zijn verplicht en zouden "0" moeten hebben als de standaardwaarde voor beide.in_match– Deze tabel is een lijst van alle spelers die voor die wedstrijd zijn ingeschreven; spelers die niet deelnemen hebben een NULL in destarted_atattribuut, terwijl spelers die als wissels binnenkwamen,started_at. hebben> 0 . Als een speler is vervangen, krijgt deze eenended_atattribuut dat overeenkomt met destarted_atattribuut van de speler die ze heeft vervangen. Als de speler de hele wedstrijd binnen is gebleven, wordt hunended_atattribuut zal dezelfde waarde hebben als deend_timeattribuut.
Wedstrijdevenementen
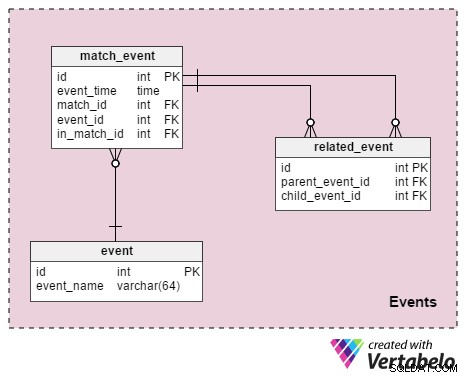
Dit gedeelte is bedoeld om alle details of gebeurtenissen op te slaan die tijdens het spel hebben plaatsgevonden. En de tabellen zijn:
event– Dit is een woordenboek met alle gebeurtenissen die we willen opslaan. In het voetbal zijn dit waarden als 'fout begaan' , "fout geleden" , “gele kaart” , “rode kaart” , “vrije trap” , “straf” , “doel” , “buitenspel” , “vervanging” , "speler verwijderd uit wedstrijd" .match_event– Dit verbindt gebeurtenissen met de wedstrijd. We slaan deevent_time. op evenals spelersinformatie met betrekking tot dat evenement (in_match_id).related_event– Dit is wat evenementinformatie bij elkaar brengt. Laten we ter verduidelijking eens kijken naar een voorbeeld waarin speler A een overtreding begaat tegen speler B. We voegen een record in hetmatch_eventtabel die aangeeft dat speler A een fout heeft begaan en een andere die aangeeft dat speler B een fout heeft gemaakt. We voegen ook een record toe aan hetrelated_eventtafel, waar de 'begaan fout' de ouder zal zijn en de 'geleden fout' het kind. We registreren ook de resultaten van de overtreding:een gele kaart, een vrije trap of een strafschop, en misschien een doelpunt.
Indicatoren en prestaties
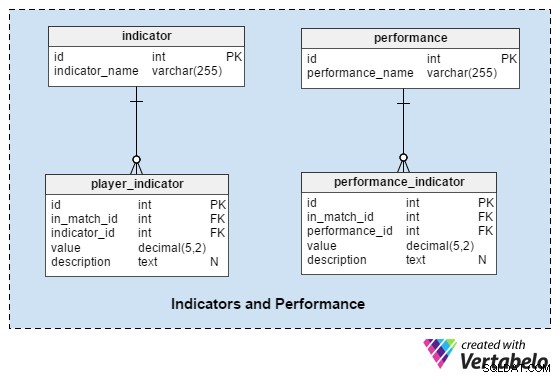
Dit gedeelte zou ons moeten helpen bij het analyseren van spelers en teams voor en na de wedstrijd.
De indicator table is een woordenboek met een vooraf gedefinieerde set indicatoren voor elke speler voor elke wedstrijd. Deze indicatoren moeten de huidige vorm van de speler beschrijven. Deze lijst kan waarden bevatten zoals:“aantal doelpunten in de laatste 10 wedstrijden” , 'gemiddelde afgelegde afstand in de laatste 10 wedstrijden' , "aantal saves voor GK in de laatste 10 wedstrijden" .
De performance woordenboek lijkt erg op indicator , maar we gebruiken het om alleen waarden op te slaan die gerelateerd zijn aan de enkele overeenkomst:“afgelegde afstand” , “nauwkeurige passes” , enz.
De player_indicator en performance_indicator tabellen delen een bijna identieke structuur:
in_match_id– verwijst naar de speler die deelneemt aan een bepaalde wedstrijdindicator_id/performance_id– verwijst naar deindicatorof ”prestatiewoordenboekenvalue– slaat de waarde voor die indicator op (bijv. een speler heeft een afstand van 10,72 km afgelegd)description– bevat een aanvullende beschrijving, indien nodig
Wat gebeurde er tijdens de wedstrijd?
Met al deze gegevens ingevoerd, kunnen we gemakkelijk wedstrijddetails, evenementen en statistieken krijgen voor elke wedstrijd in onze database.
Deze eenvoudige zoekopdracht levert basisgegevens op voor een aanstaande wedstrijd:
SELECT team_1.`team_name`, team_2.`team_name`, `match`.`start_time`, `match`.`location` FROM `match`, `team` AS team_1, `team` AS team_2 WHERE `match`.`team_1_id` = team_1.`id` AND `match`.`team_2_id` = team_2.`id`
Om een lijst te krijgen van alle in-play-evenementen tijdens een bepaalde wedstrijd, gebruiken we de onderstaande zoekopdracht:
SELECT `event`.`event_name`, `match_event`.`event_time`, `player`.`first_name`, `player`.`last_name` FROM `match`, `match_event`, `event`, `in_match`, `player` WHERE `match_event`.`match_id` = `match`.`id` AND `event`.`id` = `match_event`.`event_id` AND `in_match`.`id` = `match_event`.`in_match_id` AND `player`.`id` = `in_match`.`player_id` AND `match`.`id` = @match ORDER BY `match_event`.`event_time` ASC
Er zijn talloze aanvullende vragen die ik kan bedenken; het is gemakkelijk om een analyse te doen als je de gegevens hebt. Als je een groot aantal indicatoren en prestatiegegevens van spelers hebt gemeten en opgeslagen, kun je deze parameters mogelijk relateren aan een eindresultaat. Persoonlijk geloof ik niet in dergelijke voorspellingen; er is de geluksfactor tijdens wedstrijden, plus tal van andere factoren die je pas weet als het spel begint. Maar als je een grote dataset en veel parameters hebt, neemt je kans om nauwkeurigere voorspellingen te doen toe.
Met het model dat in dit artikel wordt gepresenteerd, kunnen we wedstrijden, wedstrijddetails en een geschiedenis van de prestaties van elke speler opslaan. We kunnen ook vormindicatoren instellen voor elke speler vóór de wedstrijd. Door voldoende details op te slaan, zouden we meer parameters moeten hebben waarop we onze aannames kunnen baseren. Ik zeg niet dat we het resultaat van het spel kunnen voorspellen, maar we kunnen er wel plezier mee hebben.
We zouden dit model ook gemakkelijk kunnen aanpassen om gegevens voor andere sporten op te slaan. Deze veranderingen mogen niet te ingewikkeld zijn. Een sport_id toevoegen toeschrijven aan de woordenboeken zou het lukken. Toch denk ik dat het verstandig zou zijn om voor elke andere sport een nieuwe instantie te hebben.