Databases die zakelijke toepassingen bedienen, moeten vaak tijdelijke gegevens ondersteunen. Stel bijvoorbeeld dat een contract met een leverancier slechts voor een beperkte tijd geldig is. Het kan geldig zijn vanaf een specifiek tijdstip, of het kan geldig zijn voor een specifiek tijdsinterval - van een begintijdstip tot een eindtijdspunt. Bovendien moet u vaak alle wijzigingen in een of meer tabellen controleren. Mogelijk moet u ook de status op een bepaald tijdstip of alle wijzigingen die in een bepaalde periode in een tabel zijn aangebracht, kunnen weergeven. Vanuit het perspectief van gegevensintegriteit moet u mogelijk veel extra tijdspecifieke beperkingen implementeren.
Introductie van tijdelijke gegevens
In een tabel met tijdelijke ondersteuning vertegenwoordigt de kop een predikaat met een ten minste eenmalige parameter die het interval vertegenwoordigt wanneer de rest van het predikaat geldig is, is het volledige predikaat daarom een predikaat met een tijdstempel. Rijen vertegenwoordigen tijdstempels, en de geldige tijdsperiode van de rij wordt meestal uitgedrukt met twee attributen:van en naar , of begin en einde .
Soorten tijdelijke tabellen
Het is je misschien opgevallen tijdens het inleidingsgedeelte dat er twee soorten tijdelijke problemen zijn. De eerste is de geldigheidstijd van de propositie - in welke periode de propositie die een rij met tijdstempel in een tabel voorstelt, eigenlijk waar was. Een contract met een leverancier was bijvoorbeeld alleen geldig van tijdstip 1 tot tijdstip 2. Dit soort geldigheidsduur is zinvol voor mensen, zinvol voor het bedrijf. De geldigheidsduur wordt ook wel sollicitatietijd . genoemd of menselijke tijd . We kunnen meerdere geldige perioden hebben voor dezelfde entiteit. Het bovengenoemde contract dat geldig was van tijdstip 1 tot tijdstip 2, kan bijvoorbeeld ook geldig zijn van tijdstip 7 tot tijdstip 9.
Het tweede tijdelijke probleem is de transactietijd . Een rij voor het hierboven genoemde contract werd ingevoegd op tijdstip 1 en was de enige versie van de waarheid die de database kende totdat iemand het veranderde, of zelfs tot het einde van de tijd. Wanneer de rij wordt bijgewerkt op tijdstip 2, stond de oorspronkelijke rij bekend als trouw aan de database van tijdstip 1 tot tijdstip 2. Een nieuwe rij voor dezelfde propositie wordt ingevoegd met de tijd geldig voor de database vanaf tijdstip 2 tot het einde van de tijd. De transactietijd is ook bekend als systeemtijd of databasetijd .
Natuurlijk kunt u ook tabellen met zowel applicatie- als systeemversies implementeren. Dergelijke tabellen worden bitemporaal . genoemd tabellen.
In SQL Server 2016 krijgt u out-of-the-box ondersteuning voor de systeemtijd met tijdelijke tabellen met systeemversies . Als u applicatietijd moet implementeren, moet u zelf een oplossing ontwikkelen.
Allen's Interval Operators
De theorie voor de temporele gegevens in een relationeel model begon meer dan dertig jaar geleden te evolueren. Ik zal een flink aantal bruikbare Booleaanse operatoren introduceren en een aantal operatoren die op intervallen werken en een interval teruggeven. Deze operatoren staan bekend als de operatoren van Allen, genoemd naar J.F. Allen, die een aantal van hen definieerde in een onderzoekspaper uit 1983 met tijdsintervallen. Ze worden allemaal nog steeds als geldig en nodig geaccepteerd. Een databasebeheersysteem kan u helpen bij het omgaan met aanvraagtijden door deze operators kant-en-klaar te implementeren.
Laat me eerst de notatie introduceren die ik zal gebruiken. Ik werk met twee intervallen, aangeduid met i1 en i2 . Het begintijdstip van het eerste interval is b1 , en het einde is e1 ; het begintijdstip van het tweede interval is b2 en het einde is e2 . De Booleaanse operatoren van Allen worden gedefinieerd in de volgende tabel.
[table id=2 /]
Naast Booleaanse operatoren zijn er de drie operatoren van Allen die intervallen als invoerparameters accepteren en een interval retourneren. Deze operatoren vormen eenvoudige intervalalgebra . Merk op dat deze operatoren dezelfde naam hebben als relationele operatoren die u waarschijnlijk al kent:Union, Intersect en Minus. Ze gedragen zich echter niet precies zoals hun relationele tegenhangers. In het algemeen, als een van de drie intervaloperatoren wordt gebruikt, als de bewerking zou resulteren in een lege set tijdpunten of in een set die niet door één interval kan worden beschreven, moet de operator NULL retourneren. Een vereniging van twee intervallen heeft alleen zin als de intervallen elkaar ontmoeten of overlappen. Een kruising heeft alleen zin als de intervallen elkaar overlappen. De operator Minus-interval heeft slechts in sommige gevallen zin. Bijvoorbeeld (3:10) Min (5:7) retourneert NULL omdat het resultaat niet door één interval kan worden beschreven. De volgende tabel vat de definitie van de operatoren van intervalalgebra samen.
[tabel id=3 /]
Overlappende queryprestaties ProbleemEen van de meest complexe operators om te implementeren zijn de overlappingen exploitant. Query's die overlappende intervallen moeten vinden, zijn niet eenvoudig te optimaliseren. Dergelijke zoekopdrachten komen echter vrij vaak voor in tijdelijke tabellen. In dit en de volgende twee artikelen laat ik u een aantal manieren zien om dergelijke zoekopdrachten te optimaliseren. Maar voordat ik de oplossingen introduceer, wil ik eerst het probleem introduceren.
Om het probleem uit te leggen heb ik wat gegevens nodig. De volgende code toont een voorbeeld van het maken van een tabel met geldigheidsintervallen uitgedrukt met de b en e kolommen, waarbij het begin en het einde van een interval worden weergegeven als gehele getallen. De tabel is gevuld met demogegevens uit de tabel WideWorldImporters.Sales.OrderLines. Houd er rekening mee dat er meerdere versies zijn van de WideWorldImporters database, dus u krijgt mogelijk iets andere resultaten. Ik heb het WideWorldImporters-Standard.bak-back-upbestand van https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 gebruikt om deze demodatabase op mijn SQL Server-instantie te herstellen .
De demogegevens maken
Ik heb een demotabel gemaakt dbo.Intervals in de tempd database met de volgende code.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Let ook op de indexen gemaakt. De twee indexen zijn optimaal voor zoekopdrachten aan het begin van een interval of aan het einde van een interval. U kunt het minimale begin en het maximale einde van alle intervallen controleren met de volgende code.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
U kunt in de resultaten zien dat het minimale begintijdstip 1 is en het maximale eindtijdstip 1155 is.
De context aan de gegevens geven
Het is je misschien opgevallen dat ik het begin en het einde vertegenwoordig tijdspunten als gehele getallen. Nu moet ik de intervallen wat tijdscontext geven. In dit geval vertegenwoordigt een enkel tijdstip een dag . De volgende code maakt een datum-opzoektabel en vult het. Let op:de startdatum is 1 juli 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Nu kunt u de tabel dbo.Intervals twee keer samenvoegen met de tabel dbo.DateNums, om de context te geven aan de gehele getallen die het begin en het einde van de intervallen vertegenwoordigen.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Introductie van het prestatieprobleem
Het probleem met tijdelijke query's is dat SQL Server bij het lezen van een tabel slechts één index kan gebruiken en met succes rijen kan verwijderen die niet in aanmerking komen voor het resultaat van slechts één kant, en vervolgens de rest van de gegevens scant. U moet bijvoorbeeld alle intervallen in de tabel vinden die een bepaald interval overlappen. Onthoud dat twee intervallen elkaar overlappen wanneer het begin van de eerste lager of gelijk is aan het einde van de tweede en het begin van de tweede lager of gelijk is aan het einde van de eerste, of wiskundig wanneer (b1 ≤ e2) EN (b2 ≤ e1).
De volgende zoekopdracht zocht naar alle intervallen die het interval overlappen (10, 30). Merk op dat de tweede voorwaarde (b2 e1) wordt omgedraaid naar (e1 ≥ b2) voor eenvoudiger lezen (het begin en het einde van intervallen uit de tabel staan altijd aan de linkerkant van de voorwaarde). Het opgegeven of het gezochte interval staat aan het begin van de tijdlijn voor alle intervallen in de tabel.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
De query gebruikte 36 logische reads. Als u het uitvoeringsplan controleert, kunt u zien dat de query de index seek heeft gebruikt in de idx_b-index met het seek-predikaat [tempdb].[dbo].[Intervals].b <=Scalar Operator((30)) en vervolgens scant de rijen en selecteer de resulterende rijen met behulp van het resterende predikaat [tempdb].[dbo].[Intervals].[e]>=(10). Omdat het gezochte interval zich aan het begin van de tijdlijn bevindt, heeft het zoekpredikaat met succes de meerderheid van de rijen geëlimineerd; slechts enkele intervallen in de tabel hebben het beginpunt lager of gelijk aan 30.
U zou een even efficiënte zoekopdracht krijgen als het gezochte interval aan het einde van de tijdlijn zou zijn, alleen dat SQL Server de idx_e-index zou gebruiken voor zoeken. Wat gebeurt er echter als het gezochte interval zich in het midden van de tijdlijn bevindt, zoals de volgende zoekopdracht laat zien?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Deze keer gebruikte de query 111 logische reads. Met een grotere tabel zou het verschil met de eerste query nog groter zijn. Als u het uitvoeringsplan controleert, kunt u erachter komen dat SQL Server de idx_e-index heeft gebruikt met de [tempdb].[dbo].[Intervals].e>=Scalar Operator((570)) seek-predikaat en [tempdb].[ dbo].[Intervallen].[b]<=(590) restpredikaat. Het zoekpredikaat sluit ongeveer de helft van de rijen van de ene kant uit, terwijl de helft van de rijen van de andere kant wordt gescand en de resulterende rijen worden geëxtraheerd met het resterende predikaat.
Verbeterde T-SQL-oplossing
Er is een oplossing die die index zou gebruiken voor het verwijderen van de rijen aan beide zijden van het gezochte interval door een enkele index te gebruiken. De volgende afbeelding toont deze logica.
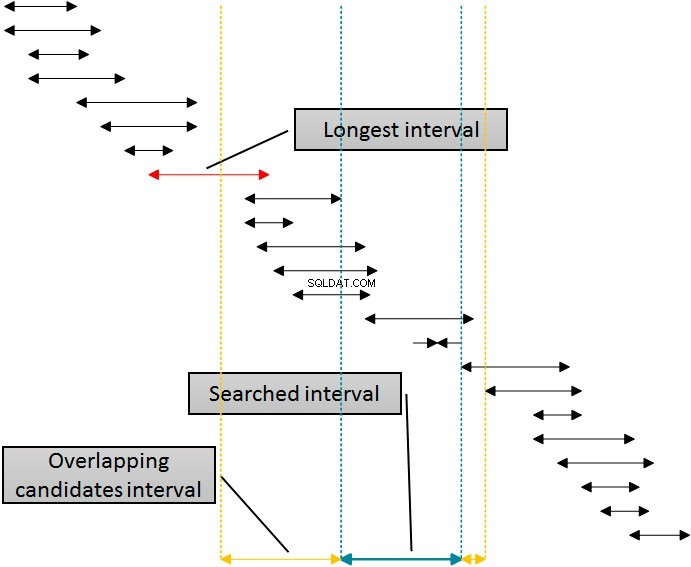
De intervallen in de afbeelding zijn gesorteerd op de ondergrens, wat het gebruik van de idx_b-index door SQL Server weergeeft. Het elimineren van intervallen aan de rechterkant van het gegeven (doorzochte) interval is eenvoudig:elimineer gewoon alle intervallen waarvan het begin minstens één eenheid groter (meer naar rechts) van het einde van het gegeven interval is. U kunt deze grens zien in de figuur aangegeven met de meest rechtse stippellijn. Het elimineren van links is echter complexer. Om dezelfde index te gebruiken, de idx_b index voor het verwijderen van links, moet ik het begin van de intervallen in de tabel in de WHERE-component van de query gebruiken. Ik moet naar de linkerkant gaan, weg van het begin van het gegeven (gezochte) interval, ten minste voor de lengte van het langste interval in de tabel, dat is gemarkeerd met een toelichting in de afbeelding. De intervallen die beginnen voor de linker gele lijn mogen het gegeven (blauwe) interval niet overlappen.
Aangezien ik al weet dat de lengte van het langste interval 20 is, kan ik op een vrij eenvoudige manier een uitgebreide query schrijven.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Met deze query worden dezelfde rijen opgehaald als de vorige met slechts 20 logische leesbewerkingen. Als u het uitvoeringsplan controleert, kunt u zien dat de idx_b is gebruikt, met het seek-predikaat Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Scalar Operator((550)) , End:[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), die met succes rijen elimineerde aan beide zijden van de tijdlijn, en vervolgens het resterende predikaat [tempdb].[dbo]. [Intervals].[e]>=(570) AND [tempdb].[dbo].[Intervals].[e]<=(610) werd gebruikt om rijen te selecteren uit een zeer beperkte gedeeltelijke scan.
Natuurlijk kan het cijfer worden omgedraaid om de gevallen te dekken waarin de idx_e-index nuttiger zou zijn. Met deze index is de eliminatie van links eenvoudig - elimineer alle intervallen die ten minste één eenheid eindigen voor het begin van het gegeven interval. Deze keer is de eliminatie van rechts ingewikkelder - het einde van de intervallen in de tabel kan niet meer naar rechts zijn dan het einde van het gegeven interval plus de maximale lengte van alle intervallen in de tabel.
Houd er rekening mee dat deze prestatie het gevolg is van de specifieke gegevens in de tabel. De maximale lengte van een interval is 20. Op deze manier kan SQL Server zeer efficiënt intervallen van beide kanten elimineren. Als er echter maar één lang interval in de tabel zou zijn, zou de code veel minder efficiënt worden, omdat SQL Server niet in staat zou zijn om veel rijen van één kant, links of rechts, te elimineren, afhankelijk van welke index het zou gebruiken . Hoe dan ook, in het echte leven varieert de intervallengte niet vaak, dus deze optimalisatietechniek kan erg handig zijn, vooral omdat het eenvoudig is.
Conclusie
Houd er rekening mee dat dit slechts één mogelijke oplossing is. In het artikel Interval Queries in SQL Server van Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-interval-query's). Ik hou echter echt van de verbeterde T-SQL oplossing die ik in dit artikel heb gepresenteerd. De oplossing is heel eenvoudig; het enige dat u hoeft te doen, is twee predikaten toevoegen aan de WHERE-component van uw overlappende query's. Dit is echter niet het einde van de mogelijkheden. Blijf op de hoogte, in de volgende twee artikelen zal ik u meer oplossingen laten zien, zodat u een rijke reeks mogelijkheden in uw optimalisatietoolbox zult hebben.
Handig hulpmiddel:
dbForge Query Builder voor SQL Server – stelt gebruikers in staat om snel en eenvoudig complexe SQL-query's te bouwen via een intuïtieve visuele interface zonder handmatig code schrijven.