Als SQL Server DBA's hebben we gehoord dat indexstructuren de prestaties van een bepaalde query (of reeks query's) drastisch kunnen verbeteren. Toch zijn er bepaalde details die veel DBA's over het hoofd zien, zoals de volgende:
- Indexstructuren kunnen gefragmenteerd raken, wat mogelijk kan leiden tot prestatieverlies.
- Zodra een indexstructuur voor een databasetabel is geïmplementeerd, werkt SQL Server deze bij wanneer er schrijfbewerkingen voor die tabel plaatsvinden. Dit gebeurt als de kolommen die voldoen aan de index worden beïnvloed.
- Er zijn metadata in SQL Server die kunnen worden gebruikt om te weten wanneer de statistieken voor een bepaalde indexstructuur voor de laatste keer (of ooit) zijn bijgewerkt. Onvoldoende of verouderde statistieken kunnen de prestaties van bepaalde zoekopdrachten beïnvloeden.
- Er zijn metadata in SQL Server die kunnen worden gebruikt om te weten hoeveel een indexstructuur is verbruikt door leesbewerkingen, of is bijgewerkt door schrijfbewerkingen door SQL Server zelf. Deze informatie kan nuttig zijn om te weten of er indexen zijn waarvan het schrijfvolume het leesvolume aanzienlijk overschrijdt. Het kan mogelijk een indexstructuur zijn die niet zo handig is om bij te houden.*
*Het is erg belangrijk om te onthouden dat de systeemweergave die deze specifieke metagegevens bevat, wordt gewist telkens wanneer de SQL Server-instantie opnieuw wordt gestart, dus het is geen informatie vanaf het begin.
Vanwege het belang van deze details heb ik een Stored Procedure gemaakt om informatie over indexstructuren in zijn/haar omgeving bij te houden, om zo proactief mogelijk te kunnen handelen.
Eerste overwegingen
- Zorg ervoor dat het account dat deze Opgeslagen Procedure uitvoert voldoende rechten heeft. U kunt waarschijnlijk beginnen met de sysadmin-versies en vervolgens zo gedetailleerd mogelijk gaan om ervoor te zorgen dat de gebruiker het minimum aan privileges heeft dat nodig is om de SP goed te laten werken.
- De database-objecten (databasetabel en opgeslagen procedure) worden gemaakt in de database die is geselecteerd op het moment dat het script wordt uitgevoerd, dus kies zorgvuldig.
- Het script is zo gemaakt dat het meerdere keren kan worden uitgevoerd zonder dat er een fout optreedt. Voor de Stored Procedure heb ik de CREATE OR ALTER PROCEDURE-instructie gebruikt, beschikbaar sinds SQL Server 2016 SP1.
- Voel je vrij om de naam van de gemaakte database-objecten te wijzigen als je een andere naamgevingsconventie wilt gebruiken.
- Als u ervoor kiest om gegevens die door de opgeslagen procedure zijn geretourneerd, te behouden, wordt de doeltabel eerst afgekapt, zodat alleen de meest recente resultatenset wordt opgeslagen. Je kunt de nodige aanpassingen doen als je wilt dat dit zich om wat voor reden dan ook anders gedraagt (om historische informatie te behouden misschien?).
Hoe de opgeslagen procedure gebruiken?
- Kopieer en plak de T-SQL-code (beschikbaar in dit artikel).
- De SP verwacht 2 parameters:
- @persistData:'Y' als de DBA de uitvoer in een doeltabel wil opslaan, en 'N' als de DBA de uitvoer alleen rechtstreeks wil zien.
- @db:'all' om de informatie voor alle databases (systeem en gebruiker) te krijgen, 'user' om gebruikersdatabases te targeten, 'system' om alleen systeemdatabases te targeten (exclusief tempdb), en tot slot de werkelijke naam van een bepaalde database.
Gepresenteerde velden en hun betekenis
- dbName: de naam van de database waarin het indexobject zich bevindt.
- schemaNaam: de naam van het schema waar het indexobject zich bevindt.
- tabelNaam: de naam van de tabel waarin het indexobject zich bevindt.
- indexName: de naam van de indexstructuur.
- typ: het type index (bijv. geclusterd, niet-geclusterd).
- allocation_unit_type: specificeert het type gegevens waarnaar wordt verwezen (bijvoorbeeld gegevens in de rij, lobgegevens).
- fragmentatie: de mate van fragmentatie (in %) die de indexstructuur momenteel heeft.
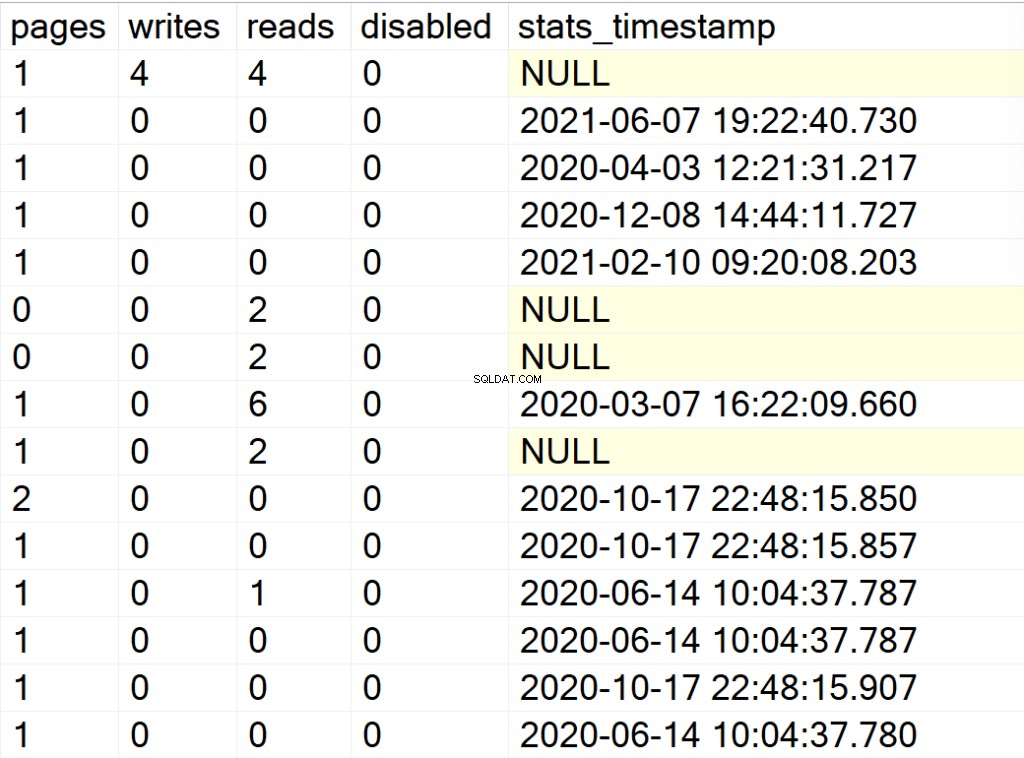
- pagina's: het aantal pagina's van 8 KB dat de indexstructuur vormt.
- schrijft: het aantal schrijfbewerkingen dat de indexstructuur heeft ondergaan sinds de SQL Server-instantie voor het laatst opnieuw is opgestart.
- leest: het aantal leesbewerkingen dat de indexstructuur heeft ondergaan sinds de SQL Server-instantie voor het laatst opnieuw is opgestart.
- uitgeschakeld: 1 als de indexstructuur momenteel is uitgeschakeld of 0 als de structuur is ingeschakeld.
- stats_timestamp: de tijdstempelwaarde van wanneer de statistieken voor de specifieke indexstructuur voor het laatst zijn bijgewerkt (NULL indien nooit).
- data_collection_timestamp: alleen zichtbaar als 'Y' wordt doorgegeven aan de parameter @persistData en wordt gebruikt om te weten wanneer de SP is uitgevoerd en de informatie met succes is opgeslagen in de tabel DBA_Indexes.
Uitvoeringstests
Ik zal een paar uitvoeringen van de opgeslagen procedure demonstreren, zodat u een idee krijgt van wat u ervan kunt verwachten:
*Je kunt de volledige T-SQL-code van het script in de staart van dit artikel vinden, dus zorg ervoor dat je het uitvoert voordat je verdergaat met de volgende sectie.
*De resultatenset zal te breed zijn om mooi in 1 screenshot te passen, dus ik zal alle benodigde screenshots delen om de volledige informatie te presenteren.
/* Toon alle indexinformatie voor alle systeem- en gebruikersdatabases */
EXEC GetIndexData @persistData = 'N',@db = 'all'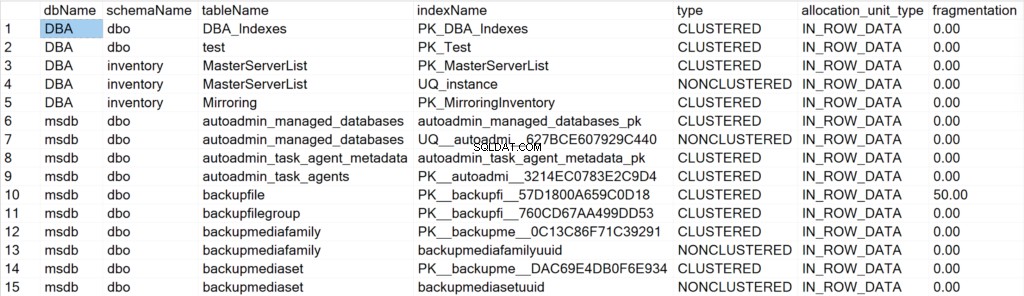
/* Toon alle indexinformatie voor alle systeemdatabases */
EXEC GetIndexData @persistData = 'N',@db = 'system'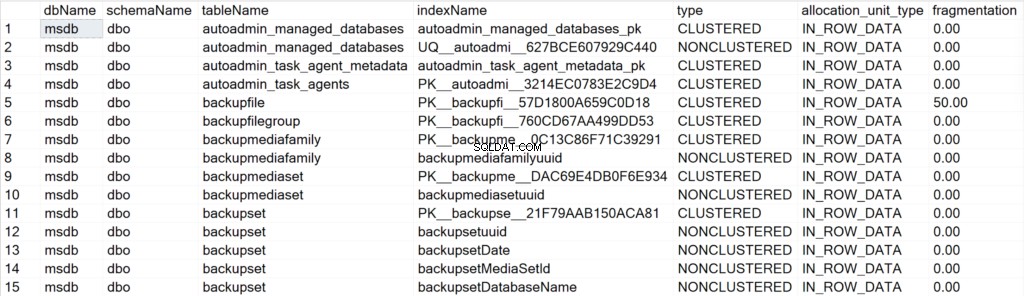
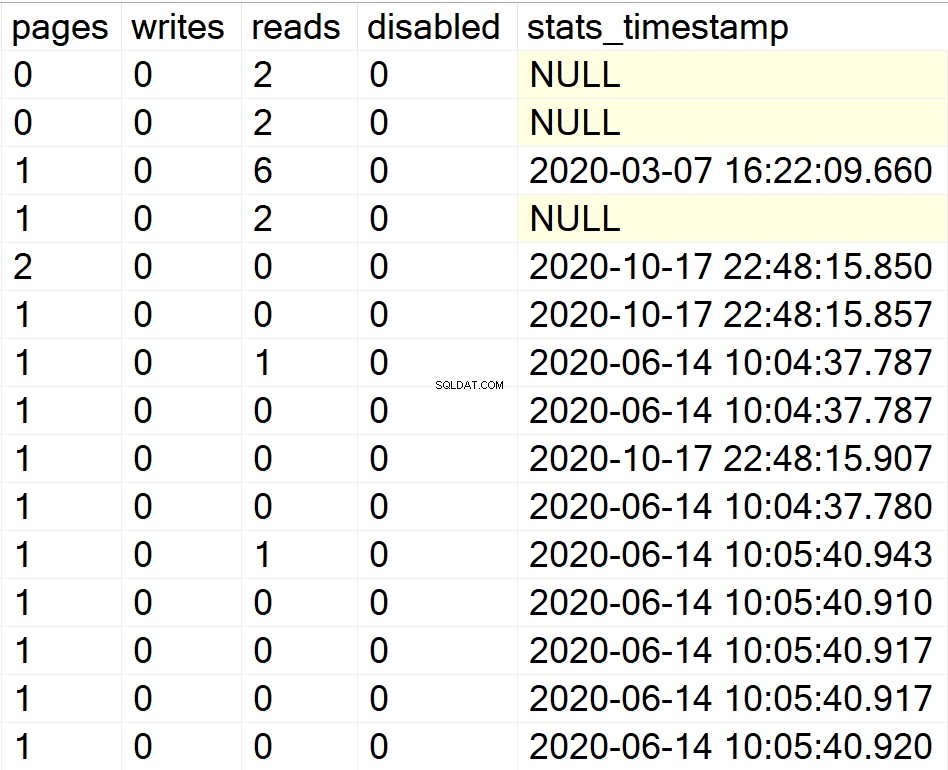
/* Toon alle indexinformatie voor alle gebruikersdatabases */
EXEC GetIndexData @persistData = 'N',@db = 'user'
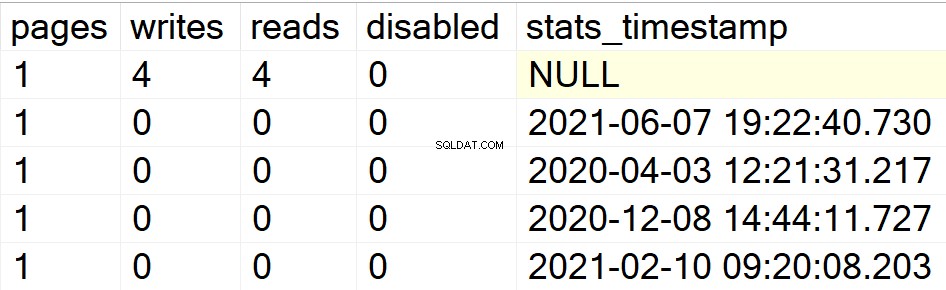
/* Toon alle indexinformatie voor specifieke gebruikersdatabases */
In mijn vorige voorbeelden verscheen alleen de database-DBA als mijn enige gebruikersdatabase met indexen erin. Laat me daarom een indexstructuur maken in een andere database die ik in dezelfde instantie heb liggen, zodat je kunt zien of de SP zijn ding doet of niet.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Alle voorbeelden die tot nu toe zijn getoond, demonstreren de uitvoer die u krijgt als u gegevens niet wilt behouden, voor de verschillende combinaties van opties voor de @db-parameter. De uitvoer is leeg wanneer u een optie opgeeft die niet geldig is of als de doeldatabase niet bestaat. Maar hoe zit het als de DBA gegevens in een databasetabel wil bewaren? Laten we het uitzoeken.
*Ik ga de SP maar voor één geval uitvoeren omdat de rest van de opties voor de @db-parameter hierboven vrijwel zijn weergegeven en het resultaat hetzelfde is, maar bleef bestaan in een databasetabel.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
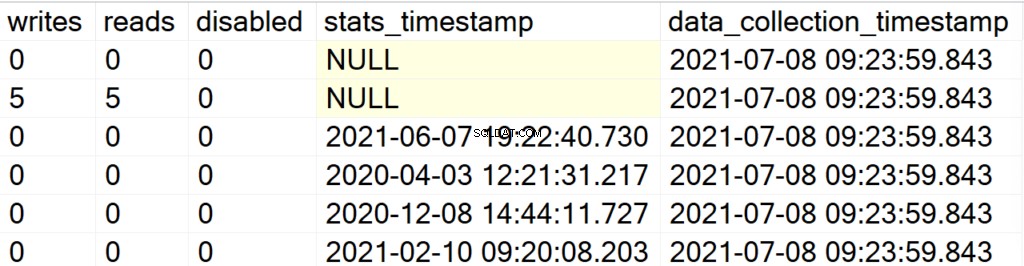
Nu, nadat u de Opgeslagen procedure hebt uitgevoerd, krijgt u geen uitvoer. Om de resultatenset op te vragen, moet u een SELECT-instructie uitgeven tegen de DBA_Indexes-tabel. De belangrijkste attractie hier is dat u de verkregen resultatenset kunt opvragen voor na-analyse, en de toevoeging van het data_collection_timestamp-veld dat u laat weten hoe recent/oud de gegevens die u bekijkt, zijn.
Sidequery's
Om de DBA meer waarde te bieden, heb ik een paar vragen opgesteld die u kunnen helpen om nuttige informatie te verkrijgen uit de gegevens die in de tabel staan vermeld.
*Query om over het algemeen zeer gefragmenteerde indexen te vinden.
*Kies het aantal % dat u passend vindt.
*De 1500 pagina's zijn gebaseerd op een artikel dat ik heb gelezen, op aanbeveling van Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Query om uitgeschakelde indexen in uw omgeving te vinden.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Query om indexen te vinden (meestal niet-geclusterd) die niet zo vaak door query's worden gebruikt, in ieder geval niet sinds de laatste keer dat de SQL Server-instantie opnieuw is opgestart.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Query om statistieken te vinden die ofwel nooit zijn bijgewerkt of oud zijn.
*U bepaalt wat oud is in uw omgeving, dus zorg ervoor dat u het aantal dagen dienovereenkomstig aanpast.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Hier is de volledige code van de opgeslagen procedure:
*Aan het begin van het script ziet u de standaardwaarde die de Opgeslagen Procedure aanneemt als er geen waarde wordt doorgegeven voor elke parameter.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOConclusie
- U kunt deze SP in elke SQL Server-instantie onder uw ondersteuning implementeren en een waarschuwingsmechanisme implementeren voor uw hele stapel ondersteunde instanties.
- Als u een agenttaak implementeert die deze informatie relatief vaak opvraagt, kunt u aan de top van het spel blijven om voor de indexstructuren binnen uw ondersteunde omgeving(en) te zorgen.
- Zorg ervoor dat u dit mechanisme goed test in een sandbox-omgeving en, wanneer u een productie-implementatie plant, zorg ervoor dat u perioden van lage activiteit kiest.
Problemen met indexfragmentatie kunnen lastig en stressvol zijn. Om ze te vinden en op te lossen, kunt u verschillende tools gebruiken, zoals dbForge Index Manager die u hier kunt downloaden.