Misschien denkt u dat databaseonderhoud niet uw zaak is. Maar als u uw modellen proactief ontwerpt, krijgt u databases die het leven gemakkelijker maken voor degenen die ze moeten onderhouden.
Een goed database-ontwerp vereist proactiviteit, een hoog aangeschreven kwaliteit in elke werkomgeving. Voor het geval u niet bekend bent met de term, is proactiviteit het vermogen om te anticiperen op problemen en oplossingen klaar te hebben wanneer zich problemen voordoen - of beter nog, plannen en handelen zodat problemen zich überhaupt niet voordoen.
Werkgevers begrijpen dat de proactiviteit van hun werknemers of aannemers gelijk staat aan kostenbesparingen. Dat is waarom ze het waarderen en waarom ze mensen aanmoedigen om het te oefenen.
In uw rol als datamodelleur is de beste manier om proactiviteit aan te tonen het ontwerpen van modellen die anticiperen op en voorkomen van problemen die routinematig databaseonderhoud teisteren. Of in ieder geval, dat vereenvoudigt de oplossing voor die problemen aanzienlijk.
Zelfs als u niet verantwoordelijk bent voor database-onderhoud, heeft modellering voor eenvoudig database-onderhoud veel voordelen. Het voorkomt bijvoorbeeld dat u op elk moment wordt gebeld om gegevensnoodgevallen op te lossen die kostbare tijd wegnemen die u zou kunnen besteden aan de ontwerp- of modelleringstaken die u zo leuk vindt!
Het leven gemakkelijker maken voor de IT-jongens
Bij het ontwerpen van onze databases moeten we verder denken dan het aanleveren van een DER en het genereren van updatescripts. Zodra een database in productie gaat, hebben onderhoudstechnici te maken met allerlei potentiële problemen, en een deel van onze taak als databasemodelleurs is om de kans dat die problemen optreden te minimaliseren.
Laten we beginnen met te kijken naar wat het betekent om een goed database-ontwerp te maken en hoe die activiteit zich verhoudt tot reguliere database-onderhoudstaken.
Wat is gegevensmodellering?
Datamodellering is de taak van het creëren van een abstracte, meestal grafische, representatie van een informatiearchief. Het doel van gegevensmodellering is om de attributen en de relaties tussen de entiteiten bloot te leggen waarvan de gegevens in de repository zijn opgeslagen.
Gegevensmodellen zijn gebouwd rond de behoeften van een zakelijk probleem. Regels en vereisten worden vooraf gedefinieerd door input van bedrijfsexperts, zodat ze kunnen worden opgenomen in het ontwerp van een nieuwe datarepository of kunnen worden aangepast in de iteratie van een bestaande.
Idealiter zijn datamodellen levende documenten die evolueren met veranderende zakelijke behoeften. Ze spelen een belangrijke rol bij het ondersteunen van zakelijke beslissingen en bij het plannen van systeemarchitectuur en -strategie. De datamodellen moeten synchroon worden gehouden met de databases die ze vertegenwoordigen, zodat ze nuttig zijn voor de onderhoudsroutines van die databases.
Algemene uitdagingen voor databaseonderhoud
Het onderhouden van een database vereist constante monitoring, al dan niet geautomatiseerd, om ervoor te zorgen dat deze zijn deugden niet verliest. Best practices voor databaseonderhoud zorgen ervoor dat databases altijd hun:
- Integriteit en kwaliteit van informatie
- Prestaties
- Beschikbaarheid
- Schaalbaarheid
- Aanpasbaarheid aan veranderingen
- Traceerbaarheid
- Beveiliging
Er zijn veel tips voor gegevensmodellering beschikbaar om u te helpen elke keer een goed databaseontwerp te maken. De hieronder besproken zijn specifiek gericht op het waarborgen of vergemakkelijken van het onderhoud van de bovengenoemde databasekwaliteiten.
Integriteit en informatiekwaliteit
Een fundamenteel doel van best practices voor databaseonderhoud is ervoor te zorgen dat de informatie in de database zijn integriteit behoudt. Dit is van cruciaal belang voor de gebruikers die hun vertrouwen in de informatie behouden.
Er zijn twee soorten integriteit:fysieke integriteit en logische integriteit .
Fysieke integriteit
Het handhaven van de fysieke integriteit van een database wordt gedaan door de informatie te beschermen tegen externe factoren zoals hardware- of stroomstoringen. De meest gebruikelijke en algemeen aanvaarde aanpak is door middel van een adequate back-upstrategie waarmee een database binnen een redelijke tijd kan worden hersteld als deze door een ramp wordt vernietigd.
Voor DBA's en serverbeheerders die databaseopslag beheren, is het handig om te weten of databases kunnen worden opgedeeld in secties met verschillende updatefrequenties. Hierdoor kunnen ze het opslaggebruik en de back-upplannen optimaliseren.
Gegevensmodellen kunnen die verdeling weerspiegelen door gebieden met verschillende gegevens "temperatuur" te identificeren en door entiteiten in die gebieden te groeperen. “Temperatuur” verwijst naar de frequentie waarmee tabellen nieuwe informatie ontvangen. Tabellen die zeer vaak worden bijgewerkt, zijn de "hottest"; degenen die nooit of zelden worden bijgewerkt, zijn de "koudste".

Gegevensmodel van een e-commercesysteem dat onderscheid maakt tussen warme, warme en koude gegevens.
Een DBA of systeembeheerder kan deze logische groepering gebruiken om de databasebestanden te partitioneren en voor elke partitie verschillende back-upplannen te maken.
Logische integriteit
Het handhaven van de logische integriteit van een database is essentieel voor de betrouwbaarheid en bruikbaarheid van de informatie die het levert. Als een database logische integriteit ontbeert, zullen de applicaties die er gebruik van maken vroeg of laat inconsistenties in de data aan het licht brengen. Geconfronteerd met deze inconsistenties, wantrouwen gebruikers de informatie en gaan ze op zoek naar betrouwbaardere gegevensbronnen.
Van de databaseonderhoudstaken is het handhaven van de logische integriteit van de informatie een uitbreiding van de databasemodelleringstaak, alleen dat deze begint nadat de database in productie is genomen en gedurende de hele levensduur wordt voortgezet. Het meest cruciale onderdeel van dit onderhoudsgebied is het aanpassen aan veranderingen.
Wijzigingsbeheer
Veranderingen in bedrijfsregels of vereisten vormen een constante bedreiging voor de logische integriteit van databases. U bent misschien blij met het datamodel dat u hebt gebouwd, wetende dat het perfect is aangepast aan het bedrijf, dat het met de juiste informatie op elke vraag reageert en dat het eventuele afwijkingen bij het invoegen, bijwerken of verwijderen weglaat. Geniet van dit moment van voldoening, want het is van korte duur!
Onderhoud van een database houdt in dat er dagelijks wijzigingen in het model moeten worden aangebracht. Het dwingt je om nieuwe objecten toe te voegen of bestaande te wijzigen, de kardinaliteit van de relaties aan te passen, primaire sleutels te herdefiniëren, gegevenstypen te wijzigen en andere dingen te doen die ons modelbouwers doen huiveren.
Veranderingen gebeuren de hele tijd. Het kan zijn dat een vereiste vanaf het begin verkeerd is uitgelegd, dat er nieuwe vereisten zijn opgedoken of dat u onbedoeld een fout in uw model heeft geïntroduceerd (we zijn tenslotte maar mensen die gegevensmodelleren).
Uw modellen moeten eenvoudig aan te passen zijn wanneer er behoefte aan wijzigingen is. Het is van cruciaal belang om een databaseontwerptool voor modellering te gebruiken waarmee u uw modellen kunt versieren, scripts kunt genereren om een database van de ene versie naar de andere te migreren en elke ontwerpbeslissing goed kunt documenteren.
Zonder deze tools creëert elke wijziging die u aanbrengt in uw ontwerp integriteitsrisico's die op de meest ongelegen momenten aan het licht komen. Vertabelo geeft je al deze functionaliteit en zorgt voor het bijhouden van de versiegeschiedenis van een model zonder dat je er zelfs maar over hoeft na te denken.
Het automatische versiebeheer dat in Vertabelo is ingebouwd, is een enorme hulp bij het onderhouden van wijzigingen in een gegevensmodel.
Wijzigingsbeheer en versiebeheer zijn ook cruciale factoren bij het inbedden van gegevensmodelleringsactiviteiten in de levenscyclus van softwareontwikkeling.
Refactoring
Wanneer u wijzigingen aanbrengt in een database die in gebruik is, moet u er 100% zeker van zijn dat er geen informatie verloren gaat en dat de integriteit ervan niet wordt aangetast als gevolg van de wijzigingen. Om dit te doen, kunt u refactoring-technieken gebruiken. Ze worden normaal gesproken toegepast wanneer u een ontwerp wilt verbeteren zonder de semantiek ervan aan te tasten, maar ze kunnen ook worden gebruikt om ontwerpfouten te corrigeren of een model aan te passen aan nieuwe vereisten.
Er zijn een groot aantal refactoringtechnieken. Ze worden meestal gebruikt om oude databases nieuw leven in te blazen, en er zijn procedures uit het handboek die ervoor zorgen dat de wijzigingen de bestaande informatie niet schaden. Er zijn hele boeken over geschreven; Ik raad je aan ze te lezen.
Maar om samen te vatten, we kunnen refactoring-technieken in de volgende categorieën indelen:
- Gegevenskwaliteit: Wijzigingen aanbrengen die zorgen voor consistentie en coherentie van de gegevens. Voorbeelden zijn het toevoegen van een opzoektabel en het migreren naar gegevens die in een andere tabel worden herhaald en het toevoegen van een beperking aan een kolom.
- Structureel: Wijzigingen aanbrengen in tabelstructuren die de semantiek van het model niet veranderen. Voorbeelden zijn het combineren van twee kolommen tot één, het toevoegen van een vervangende sleutel en het splitsen van een kolom in twee.
- Referentiële integriteit: Wijzigingen toepassen om ervoor te zorgen dat een rij waarnaar wordt verwezen bestaat in een gerelateerde tabel of dat een rij zonder referenties kan worden verwijderd. Voorbeelden zijn het toevoegen van een externe-sleutelbeperking aan een kolom en het toevoegen van een niet-nullwaardebeperking aan een tabel.
- Bouwkundig: Aanbrengen van wijzigingen gericht op het verbeteren van de interactie van applicaties met de database. Voorbeelden zijn het maken van een index, het alleen-lezen van een tabel en het inkapselen van een of meer tabellen in een weergave.
Technieken die de semantiek van het model wijzigen, evenals technieken die het datamodel op geen enkele manier veranderen, worden niet beschouwd als refactoringtechnieken. Deze omvatten het invoegen van rijen in een tabel, het toevoegen van een nieuwe kolom, het maken van een nieuwe tabel of weergave en het bijwerken van de gegevens in een tabel.
Informatiekwaliteit handhaven
De informatiekwaliteit in een database is de mate waarin de gegevens voldoen aan de verwachtingen van de organisatie voor nauwkeurigheid, validiteit, volledigheid en consistentie. Het handhaven van de gegevenskwaliteit gedurende de hele levenscyclus van een database is van vitaal belang voor de gebruikers ervan om juiste en geïnformeerde beslissingen te nemen met behulp van de gegevens erin.
Uw verantwoordelijkheid als datamodelleur is ervoor te zorgen dat uw modellen hun informatiekwaliteit op het hoogst mogelijke niveau houden. Om dit te doen:
- Het ontwerp moet ten minste de 3e normaalvorm volgen, zodat er geen anomalieën bij het invoegen, bijwerken of verwijderen optreden. Deze overweging geldt vooral voor databases voor transactioneel gebruik, waar regelmatig gegevens worden toegevoegd, bijgewerkt en verwijderd. Het is niet strikt van toepassing in databases voor analytisch gebruik (d.w.z. datawarehouses), aangezien het bijwerken en verwijderen van gegevens zelden of nooit wordt uitgevoerd.
- De gegevenstypen van elk veld in elke tabel moeten geschikt zijn voor het attribuut dat ze vertegenwoordigen in het logische model. Dit gaat verder dan het correct definiëren of een veld een numeriek, datum- of alfanumeriek gegevenstype is. Het is ook belangrijk om het bereik en de precisie van de waarden die door elk veld worden ondersteund, correct te definiëren. Een voorbeeld:een attribuut van het type Datum geïmplementeerd in een database als een Datum/Tijd-veld kan problemen veroorzaken in query's, aangezien een waarde die is opgeslagen met een ander tijdsdeel dan nul buiten het bereik kan vallen van een query die een datumbereik gebruikt.
- De dimensies en feiten die de structuur van een datawarehouse bepalen, moeten aansluiten bij de behoeften van het bedrijf. Bij het ontwerpen van een datawarehouse moeten de afmetingen en feiten van het model vanaf het begin correct worden gedefinieerd. Wijzigingen aanbrengen zodra de database operationeel is, brengt zeer hoge onderhoudskosten met zich mee.
Groei beheren
Een andere grote uitdaging bij het onderhouden van een database is te voorkomen dat de groei onverwacht de limiet van de opslagcapaciteit bereikt. Om u te helpen bij het beheer van opslagruimte, kunt u hetzelfde principe toepassen dat wordt gebruikt in back-upprocedures:groepeer de tabellen in uw model op basis van de snelheid waarmee ze groeien.
Meestal is een opdeling in twee gebieden voldoende. Plaats de tabellen met frequente rij-toevoegingen in het ene gebied, de tabellen waaraan rijen zelden worden ingevoegd in een ander gebied. Door het model op deze manier te segmenteren, kunnen opslagbeheerders de databasebestanden partitioneren volgens de groeisnelheid van elk gebied. Ze kunnen de partities verdelen over verschillende opslagmedia met verschillende capaciteiten of groeimogelijkheden.
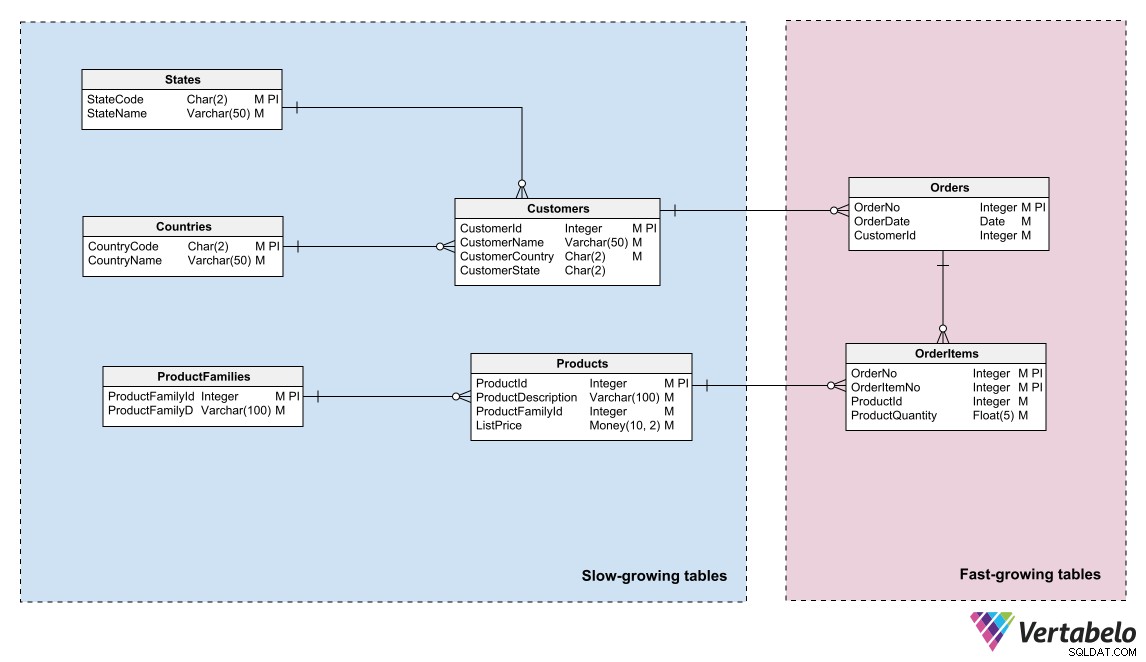
Een groepering van tabellen op basis van hun groeisnelheid helpt bij het bepalen van de opslagvereisten en het beheren van de groei.
Logboekregistratie
We maken een gegevensmodel in de verwachting dat het de informatie levert zoals het is op het moment van de query. We hebben echter de neiging om de noodzaak van een database om alles te onthouden wat er in het verleden is gebeurd over het hoofd te zien, tenzij gebruikers dit specifiek nodig hebben.
Een onderdeel van het onderhouden van een database is weten hoe, wanneer, waarom en door wie een bepaald stuk gegevens is gewijzigd. Dit kan bijvoorbeeld zijn om erachter te komen wanneer een productprijs is gewijzigd of om wijzigingen in het medisch dossier van een patiënt in een ziekenhuis te bekijken. Logboekregistratie kan zelfs worden gebruikt om gebruikers- of toepassingsfouten te corrigeren, aangezien u hiermee de staat van informatie kunt terugdraaien naar een punt in het verleden zonder dat u ingewikkelde back-upherstelprocedures hoeft te gebruiken.
Nogmaals, zelfs als gebruikers het niet expliciet nodig hebben, is de noodzaak van proactieve logboekregistratie een zeer waardevol middel om databaseonderhoud te vergemakkelijken en aan te tonen dat u in staat bent te anticiperen op problemen. Met loggegevens kan onmiddellijk worden gereageerd wanneer iemand historische informatie moet bekijken.
Er zijn verschillende strategieën voor een databasemodel om logboekregistratie te ondersteunen, die allemaal de complexiteit van het model vergroten. Eén benadering wordt in-place logging genoemd, waarbij kolommen aan elke tabel worden toegevoegd om versie-informatie vast te leggen. Dit is een eenvoudige optie waarvoor geen afzonderlijke schema's of logboekspecifieke tabellen hoeven te worden gemaakt. Het heeft echter wel invloed op het modelontwerp omdat de oorspronkelijke primaire sleutels van de tabellen niet langer geldig zijn als primaire sleutels - hun waarden worden herhaald in rijen die verschillende versies van dezelfde gegevens vertegenwoordigen.
Een andere optie om loggegevens bij te houden is het gebruik van schaduwtabellen. Schaduwtabellen zijn replica's van de modeltabellen met de toevoeging van kolommen om logtrailgegevens vast te leggen. Deze strategie vereist geen wijziging van de tabellen in het oorspronkelijke model, maar u moet eraan denken om de bijbehorende schaduwtabellen bij te werken wanneer u uw gegevensmodel wijzigt.
Nog een andere strategie is om een subschema van generieke tabellen te gebruiken waarin elke toevoeging, verwijdering of wijziging aan een andere tabel wordt vastgelegd.
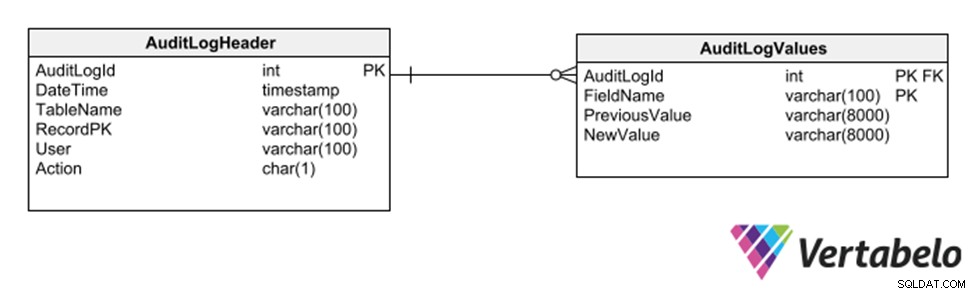
Algemene tabellen om een controlespoor van een database bij te houden.
Deze strategie heeft als voordeel dat er geen aanpassingen aan het model nodig zijn voor het vastleggen van een audit trail. Omdat het echter generieke kolommen van het type varchar gebruikt, beperkt het de soorten gegevens die in het logspoor kunnen worden vastgelegd.
Prestatieonderhoud en het maken van indexen
Vrijwel elke database presteert goed wanneer deze net in gebruik wordt genomen en de tabellen slechts een paar rijen bevatten. Maar zodra toepassingen het beginnen te vullen met gegevens, kunnen de prestaties zeer snel achteruitgaan als er geen voorzorgsmaatregelen worden genomen bij het ontwerpen van het model. Wanneer dit gebeurt, doen DBA's en systeembeheerders een beroep op u om prestatieproblemen op te lossen.
De automatische creatie/suggestie van indexen op productiedatabases is een handig hulpmiddel om prestatieproblemen "in het heetst van de strijd" op te lossen. Database-engines kunnen database-activiteiten analyseren om te zien welke bewerkingen het langst duren en waar mogelijkheden zijn om te versnellen door indexen te maken.
Het is echter veel beter om proactief te zijn en te anticiperen op de situatie door indexen te definiëren als onderdeel van het datamodel. Dit vermindert de onderhoudsinspanningen voor het verbeteren van de databaseprestaties aanzienlijk. Als u niet bekend bent met de voordelen van database-indexen, raad ik u aan alles over indexen te lezen, te beginnen bij de basis.
Er zijn praktische regels die voldoende houvast bieden voor het maken van de belangrijkste indexen voor efficiënte zoekopdrachten. De eerste is het genereren van indexen voor de primaire sleutel van elke tabel. Vrijwel elk RDBMS genereert automatisch een index voor elke primaire sleutel, zodat u deze regel kunt vergeten.
Een andere regel is het genereren van indexen voor alternatieve sleutels van een tabel, met name in tabellen waarvoor een surrogaatsleutel is gemaakt. Als een tabel een natuurlijke sleutel heeft die niet als primaire sleutel wordt gebruikt, zullen query's om die tabel met anderen samen te voegen dit hoogstwaarschijnlijk doen met de natuurlijke sleutel, niet met de surrogaat. Die zoekopdrachten werken niet goed, tenzij u een index maakt op de natuurlijke sleutel.
De volgende vuistregel voor indexen is om ze te genereren voor alle velden die refererende sleutels zijn. Deze velden zijn uitstekende kandidaten voor het maken van joins met andere tabellen. Als ze zijn opgenomen in indexen, worden ze gebruikt door queryparsers om de uitvoering te versnellen en de databaseprestaties te verbeteren.
Ten slotte is het een goed idee om tijdens prestatietests een profileringstool op een staging- of QA-database te gebruiken om kansen voor het maken van indexen te detecteren die niet voor de hand liggend zijn. Het opnemen van de indexen die worden voorgesteld door de profileringstools in het gegevensmodel is uiterst nuttig bij het bereiken en behouden van de prestaties van de database zodra deze in productie is.
Beveiliging
In uw rol als datamodelleur kunt u de databasebeveiliging helpen handhaven door een solide en veilige basis te bieden voor het opslaan van gegevens voor gebruikersauthenticatie. Houd er rekening mee dat deze informatie zeer gevoelig is en niet mag worden blootgesteld aan cyberaanvallen.
Voor uw ontwerp om het onderhoud van databasebeveiliging te vereenvoudigen, volgt u de best practices voor het opslaan van authenticatiegegevens, waarvan de belangrijkste is om geen wachtwoorden in de database op te slaan, zelfs niet in gecodeerde vorm. Door alleen de hash op te slaan in plaats van het wachtwoord voor elke gebruiker, kan een toepassing een gebruikerslogin verifiëren zonder enig risico op blootstelling aan wachtwoorden.
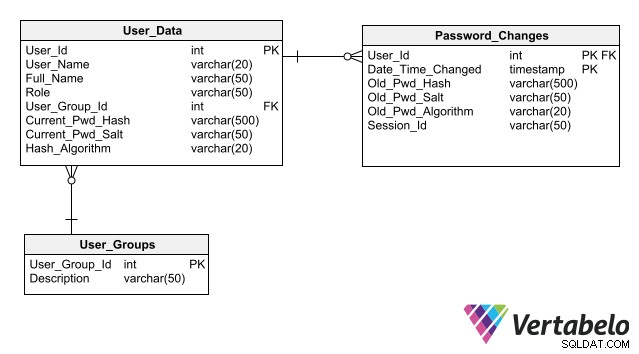
Een compleet schema voor gebruikersauthenticatie met kolommen voor het opslaan van wachtwoordhashes.
Visie voor de toekomst
Maak dus uw modellen voor eenvoudig database-onderhoud met goede database-ontwerpen door rekening te houden met de bovenstaande tips. Met meer onderhoudbare datamodellen ziet uw werk er beter uit en krijgt u waardering van DBA's, onderhoudstechnici en systeembeheerders.
U investeert ook in gemoedsrust. Door eenvoudig te onderhouden databases te maken, kunt u uw werkuren besteden aan het ontwerpen van nieuwe gegevensmodellen, in plaats van rond te lopen met het patchen van databases die niet op tijd de juiste informatie leveren.