Het "Do not Repeat Yourself"-principe suggereert dat je herhaling moet verminderen. Deze week kwam ik een geval tegen waarbij DRY uit het raam zou moeten worden gegooid. Er zijn ook andere gevallen (bijvoorbeeld scalaire functies), maar deze was interessant met Bitwise-logica.
Laten we ons de volgende tabel voorstellen:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); De "WheelFlag"-bits vertegenwoordigen de volgende opties:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Dus mogelijke combinaties zijn:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Laten we argumenten opzij zetten, althans voorlopig, of dit in de eerste plaats in een enkele TINYINT moet worden verpakt, of als afzonderlijke kolommen moet worden opgeslagen, of een EAV-model moet gebruiken... het ontwerp bepalen is een aparte kwestie. Dit gaat over werken met wat je hebt.
Laten we, om de voorbeelden nuttig te maken, deze tabel vullen met een heleboel willekeurige gegevens. (En we gaan er voor de eenvoud van uit dat deze tabel alleen bestellingen bevat die nog niet zijn verzonden.) Dit voegt 50.000 rijen in met ongeveer gelijke verdeling tussen de zes optiecombinaties:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Als we naar de uitsplitsing kijken, kunnen we deze verdeling zien. Houd er rekening mee dat uw resultaten enigszins kunnen verschillen van de mijne, afhankelijk van de objecten in uw systeem:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Resultaten:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Laten we zeggen dat het dinsdag is en dat we net een zending 18" wielen hebben ontvangen, die voorheen niet op voorraad waren. Dit betekent dat we aan alle bestellingen kunnen voldoen die 18" wielen nodig hebben - zowel die met verbeterde banden (6), en degenen die dat niet deden (2). Dus we *kunnen* een query schrijven als de volgende:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); In het echte leven kun je dat natuurlijk niet echt doen; wat als er later meer opties worden toegevoegd, zoals wielsloten, levenslange wielgarantie of meerdere bandenopties? U wilt niet voor elke mogelijke combinatie een reeks IN()-waarden moeten schrijven. In plaats daarvan kunnen we een BITWISE AND-bewerking schrijven om alle rijen te vinden waar de 2e bit is ingesteld, zoals:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Dit levert me dezelfde resultaten op als de IN()-query, maar als ik ze vergelijk met SQL Sentry Plan Explorer, zijn de prestaties heel anders:

Het is gemakkelijk te zien waarom. De eerste gebruikt een index-zoekopdracht om de rijen te isoleren die aan de zoekopdracht voldoen, met een filter in de WheelFlag-kolom:
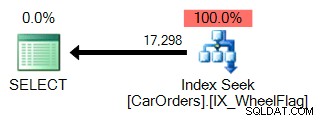

De tweede gebruikt een scan, gekoppeld aan een impliciete conversie, en vreselijk onnauwkeurige statistieken. Allemaal dankzij de BITWISE AND-operator:
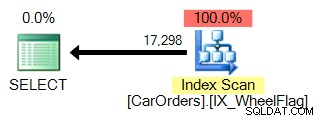


Dus wat betekent dit? In de kern vertelt dit ons dat de bewerking BITWISE EN niet sargable is .
Maar alle hoop is niet verloren.
Als we het DRY-principe even negeren, kunnen we een iets efficiëntere query schrijven door een beetje overbodig te zijn om te profiteren van de index in de WheelFlag-kolom. Ervan uitgaande dat we op zoek zijn naar een WheelFlag-optie boven 0 (helemaal geen upgrade), kunnen we de query op deze manier herschrijven, waarbij we SQL Server vertellen dat de WheelFlag-waarde minstens dezelfde waarde moet hebben als vlag (waardoor 0 en 1 worden geëlimineerd). ), en vervolgens de aanvullende informatie toe te voegen dat het ook die vlag moet bevatten (waardoor 5 wordt geëlimineerd).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
Het>=-gedeelte van deze clausule wordt duidelijk gedekt door het BITWISE-gedeelte, dus hier schenden we DRY. Maar omdat deze clausule die we hebben toegevoegd sargable is, levert het degraderen van de BITWISE AND-bewerking naar een secundaire zoekvoorwaarde nog steeds hetzelfde resultaat en levert de algemene zoekopdracht betere prestaties op. We zien een vergelijkbare indexzoektocht als de hardgecodeerde versie van de bovenstaande query, en hoewel de schattingen nog verder weg zijn (iets dat als een afzonderlijk probleem kan worden aangepakt), zijn de leeswaarden nog steeds lager dan met de BITWISE EN-bewerking alleen:

We kunnen ook zien dat er een filter wordt gebruikt tegen de index, wat we niet zagen bij het gebruik van de BITWISE EN-bewerking alleen:

Conclusie
Wees niet bang om jezelf te herhalen. Er zijn momenten waarop deze informatie de optimizer kan helpen; ook al is het misschien niet helemaal intuïtief om *toe te voegen* criteria om de prestaties te verbeteren, het is belangrijk om te begrijpen wanneer aanvullende clausules helpen de gegevens te verkleinen voor het eindresultaat in plaats van het voor de optimizer "gemakkelijk" te maken om de exacte rijen te vinden op zichzelf.