Ik zie daar veel advies dat iets zegt in de trant van:"Verander je cursor in een op sets gebaseerde bewerking; dat zal het sneller maken." Hoewel dat vaak het geval kan zijn, is het niet altijd waar. Een use case die ik zie waarbij een cursor herhaaldelijk beter presteert dan de typische set-gebaseerde benadering, is de berekening van lopende totalen. Dit komt omdat de set-gebaseerde benadering meestal meer dan één keer naar een deel van de onderliggende gegevens moet kijken, wat een exponentieel slechte zaak kan zijn naarmate de gegevens groter worden; terwijl een cursor - hoe pijnlijk het ook klinkt - precies één keer door elke rij/waarde kan gaan.
Dit zijn onze basisopties in de meest voorkomende versies van SQL Server. In SQL Server 2012 zijn er echter verschillende verbeteringen aangebracht aan de vensterfuncties en de OVER-clausule, meestal als gevolg van verschillende geweldige suggesties die zijn ingediend door collega-MVP Itzik Ben-Gan (hier is een van zijn suggesties). Itzik heeft zelfs een nieuw MS-Press-boek dat al deze verbeteringen veel gedetailleerder behandelt, getiteld "Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions."
Dus natuurlijk was ik nieuwsgierig; zou de nieuwe vensterfunctionaliteit de cursor- en self-join-technieken overbodig maken? Zouden ze gemakkelijker te coderen zijn? Zouden ze in alle (laat staan alle) gevallen sneller zijn? Welke andere benaderingen zijn mogelijk geldig?
De installatie
Laten we een database opzetten om wat te testen:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO En vul dan een tabel met 10.000 rijen die we kunnen gebruiken om wat lopende totalen uit te voeren. Niets te ingewikkeld, alleen een samenvattende tabel met een rij voor elke datum en een getal dat aangeeft hoeveel snelheidsbekeuringen zijn uitgegeven. Ik heb al een paar jaar geen snelheidsbekeuring meer gehad, dus ik weet niet waarom dit mijn onbewuste keuze was voor een simplistisch datamodel, maar daar is het dan.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Verkorte resultaten:
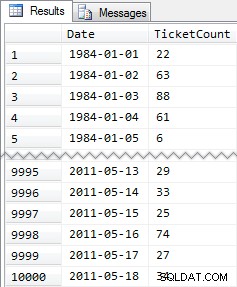
Dus nogmaals, 10.000 rijen met vrij eenvoudige gegevens - kleine INT-waarden en een reeks datums van 1984 tot mei 2011.
De benaderingen
Nu is mijn opdracht relatief eenvoudig en typerend voor veel toepassingen:retourneer een resultatenset met alle 10.000 datums, samen met het cumulatieve totaal van alle snelheidsbekeuringen tot en met die datum. De meeste mensen zouden eerst zoiets proberen (we noemen dit de "inner join " methode):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
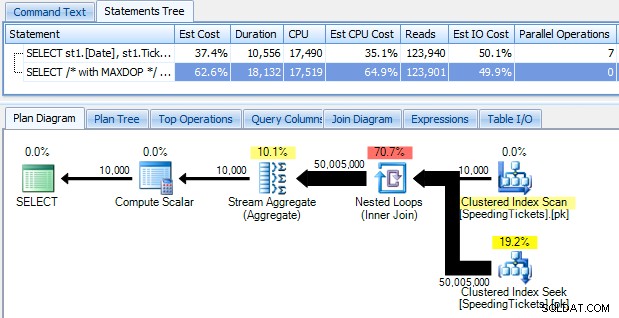
…en wees geschokt om te ontdekken dat het bijna 10 seconden duurt om te rennen. Laten we snel onderzoeken waarom door het grafische uitvoeringsplan te bekijken, met behulp van SQL Sentry Plan Explorer:

De grote dikke pijlen moeten een onmiddellijke indicatie geven van wat er aan de hand is:de geneste lus leest één rij voor de eerste aggregatie, twee rijen voor de tweede, drie rijen voor de derde, en zo verder door de hele set van 10.000 rijen. Dit betekent dat we ongeveer ((10000 * (10000 + 1)) / 2) rijen moeten zien die zijn verwerkt zodra de hele set is doorlopen, en dat lijkt overeen te komen met het aantal rijen dat in het plan wordt weergegeven.
Merk op dat het uitvoeren van de query zonder parallellisme (met behulp van de OPTION (MAXDOP 1) queryhint) de planvorm een beetje eenvoudiger maakt, maar helemaal niet helpt bij de uitvoeringstijd of I/O; zoals te zien is in het plan, verdubbelt de duur bijna en neemt het aantal leesacties slechts met een heel klein percentage af. In vergelijking met het vorige plan:
Er zijn tal van andere benaderingen die mensen hebben geprobeerd om efficiënte lopende totalen te krijgen. Een voorbeeld is de "subquery-methode " die gewoon een gecorreleerde subquery gebruikt op vrijwel dezelfde manier als de inner join-methode die hierboven is beschreven:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Deze twee plannen vergelijken:
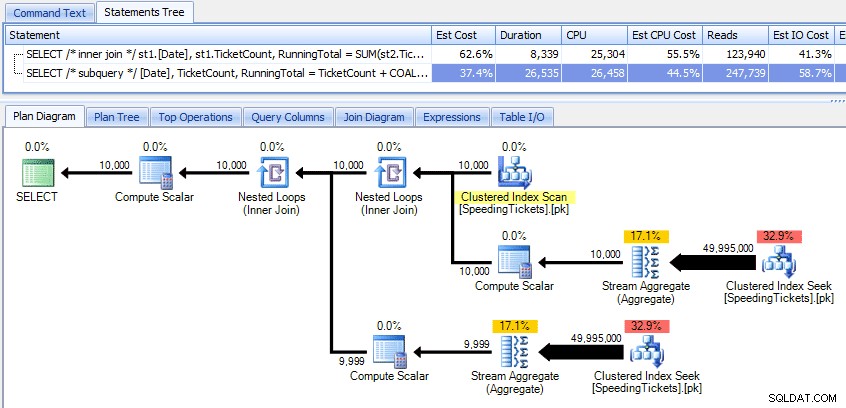
Dus hoewel de subquery-methode een efficiënter algemeen plan lijkt te hebben, is het erger waar het ertoe doet:duur en I/O. Wat hieraan bijdraagt, kunnen we zien door wat dieper in de plannen te graven. Door naar het tabblad Topbewerkingen te gaan, kunnen we zien dat in de inner join-methode de geclusterde indexzoekopdracht 10.000 keer wordt uitgevoerd en dat alle andere bewerkingen slechts een paar keer worden uitgevoerd. Verschillende bewerkingen worden echter 9.999 of 10.000 keer uitgevoerd in de subquery-methode:
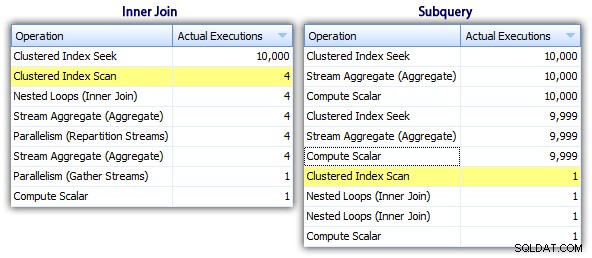
Dus de subquery-aanpak lijkt slechter te zijn, niet beter. De volgende methode die we zullen proberen, noem ik de "eigenzinnige update " methode. Dit is niet echt gegarandeerd om te werken, en ik zou het nooit aanbevelen voor productiecode, maar ik voeg het toe voor de volledigheid. In feite maakt de eigenzinnige update gebruik van het feit dat je tijdens een update toewijzing en wiskunde kunt omleiden, zodat dat de variabele achter de schermen toeneemt als elke rij wordt bijgewerkt.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Ik herhaal dat ik niet geloof dat deze aanpak veilig is voor productie, ongeacht de getuigenissen die je zult horen van mensen die aangeven dat het "nooit faalt". Tenzij gedrag gedocumenteerd en gegarandeerd is, probeer ik weg te blijven van aannames op basis van waargenomen gedrag. Je weet nooit wanneer een wijziging in het beslissingspad van de optimizer (gebaseerd op een wijziging in de statistieken, gegevenswijziging, servicepack, traceringsvlag, query-hint, wat dan ook) het plan drastisch zal veranderen en mogelijk tot een andere volgorde zal leiden. Als je deze niet-intuïtieve benadering echt leuk vindt, kun je jezelf een beetje beter voelen door de vraagoptie FORCE ORDER te gebruiken (en dit zal proberen een geordende scan van de PK te gebruiken, aangezien dat de enige geschikte index is op de tabelvariabele):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Voor wat meer vertrouwen tegen iets hogere I/O-kosten, kun je de originele tafel weer in het spel brengen en ervoor zorgen dat de PK op de basistafel wordt gebruikt:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Persoonlijk denk ik niet dat het zo veel meer gegarandeerd is, omdat het SET-gedeelte van de bewerking mogelijk de optimizer kan beïnvloeden, onafhankelijk van de rest van de query. Nogmaals, ik beveel deze aanpak niet aan, ik neem alleen de vergelijking op voor de volledigheid. Hier is het plan van deze vraag:
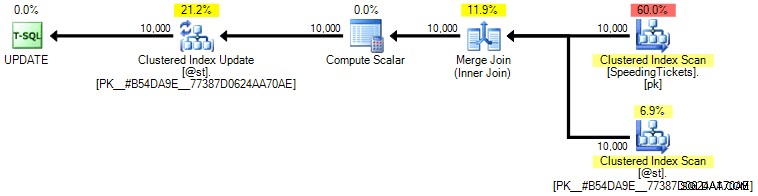
Op basis van het aantal uitvoeringen dat we zien op het tabblad Topbewerkingen (ik zal u de schermafbeelding besparen; het is 1 voor elke bewerking), is het duidelijk dat zelfs als we een samenvoeging uitvoeren om ons beter te voelen over bestellen, de eigenzinnige update maakt het mogelijk de lopende totalen te berekenen in een enkele doorgang van de gegevens. In vergelijking met de vorige zoekopdrachten is het veel efficiënter, ook al dumpt het eerst gegevens in een tabelvariabele en wordt het opgedeeld in meerdere bewerkingen:

Dit brengt ons bij een "recursieve CTE " methode. Deze methode gebruikt de datumwaarde en gaat ervan uit dat er geen gaten zijn. Omdat we deze gegevens hierboven hebben ingevuld, weten we dat het een volledig aaneengesloten reeks is, maar in veel scenario's kun je dat niet maken Dus hoewel ik het voor de volledigheid heb opgenomen, zal deze benadering niet altijd geldig zijn. In ieder geval gebruikt dit een recursieve CTE met de eerste (bekende) datum in de tabel als anker, en de recursieve gedeelte bepaald door één dag toe te voegen (toevoegen van de MAXRECURSION-optie omdat we precies weten hoeveel rijen we hebben):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Deze query werkt ongeveer net zo efficiënt als de eigenzinnige update-methode. We kunnen het vergelijken met de subquery- en inner join-methoden:

Net als de eigenzinnige updatemethode, zou ik deze CTE-aanpak in productie niet aanbevelen, tenzij je absoluut kunt garanderen dat je sleutelkolom geen gaten heeft. Als er hiaten in uw gegevens zijn, kunt u iets soortgelijks maken met ROW_NUMBER(), maar het zal niet efficiënter zijn dan de methode voor zelf-join hierboven.
En dan hebben we de "cursor " benadering:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; ...wat veel meer code is, maar in tegenstelling tot wat de populaire mening suggereert, keert het binnen 1 seconde terug. We kunnen zien waarom uit sommige van de bovenstaande details van het plan:de meeste andere benaderingen lezen uiteindelijk dezelfde gegevens steeds opnieuw, terwijl de cursorbenadering elke rij één keer leest en het lopende totaal in een variabele houdt in plaats van de som te berekenen over en opnieuw. We kunnen dit zien door te kijken naar de uitspraken die zijn vastgelegd door een echt plan te genereren in Plan Explorer:
We kunnen zien dat er meer dan 20.000 uitspraken zijn verzameld, maar als we sorteren op geschatte of werkelijke rijen, aflopend, ontdekken we dat er slechts twee bewerkingen zijn die meer dan één rij verwerken. Dat staat ver af van een paar van de bovenstaande methoden die exponentiële uitlezingen veroorzaken doordat dezelfde vorige rijen steeds opnieuw worden gelezen voor elke nieuwe rij.
Laten we nu eens kijken naar de nieuwe vensterverbeteringen in SQL Server 2012. In het bijzonder kunnen we nu SUM OVER() berekenen en een reeks rijen specificeren ten opzichte van de huidige rij. Dus bijvoorbeeld:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Deze twee zoekopdrachten geven toevallig hetzelfde antwoord, met correcte lopende totalen. Maar werken ze precies hetzelfde? De plannen suggereren van niet. De versie met ROWS heeft een extra operator, een project met 10.000 rijen:
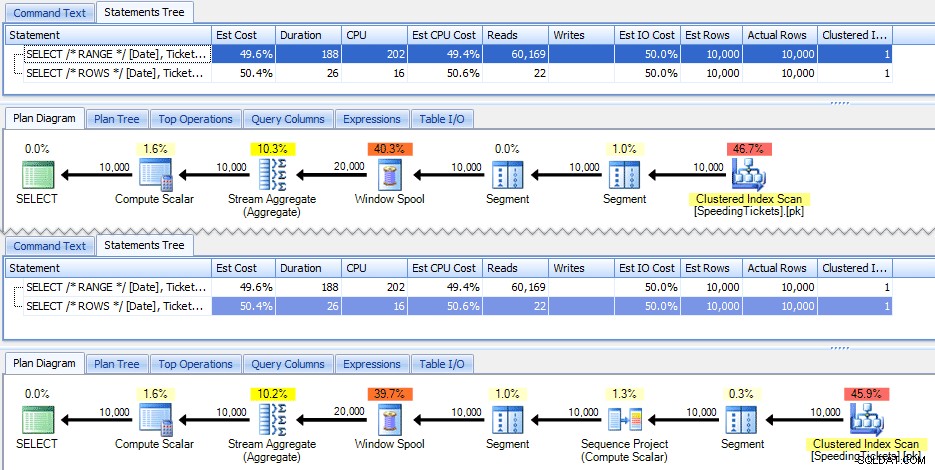
En dat is ongeveer de omvang van het verschil in het grafische plan. Maar als je wat beter kijkt naar de werkelijke runtime-statistieken, zie je kleine verschillen in duur en CPU, en een enorm verschil in uitlezingen. Waarom is dit? Welnu, dit komt omdat RANGE een spool op de schijf gebruikt, terwijl ROWS een spool in het geheugen gebruikt. Bij kleine sets is het verschil waarschijnlijk te verwaarlozen, maar de kosten van de spoel op de schijf kunnen zeker duidelijker worden naarmate de sets groter worden. Ik wil het einde niet verklappen, maar je zou kunnen vermoeden dat een van deze oplossingen beter zal presteren dan de andere in een meer grondige test.
Even terzijde, de volgende versie van de query levert dezelfde resultaten op, maar werkt als de langzamere RANGE-versie hierboven:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Dus terwijl je met de nieuwe vensterfuncties speelt, moet je kleine weetjes als deze in gedachten houden:de verkorte versie van een query, of degene die je toevallig als eerste hebt geschreven, is niet noodzakelijk degene die je wilt om naar productie te duwen.
De werkelijke tests
Om eerlijke tests uit te voeren, heb ik voor elke benadering een opgeslagen procedure gemaakt en de resultaten gemeten door verklaringen vast te leggen op een server waar ik al toezicht hield met SQL Sentry (als u onze tool niet gebruikt, kunt u SQL:BatchCompleted-gebeurtenissen verzamelen op een vergelijkbare manier met SQL Server Profiler).
Met "eerlijke tests" bedoel ik dat de eigenzinnige updatemethode bijvoorbeeld een daadwerkelijke update van statische gegevens vereist, wat betekent dat het onderliggende schema moet worden gewijzigd of een tijdelijke tabel / tabelvariabele moet worden gebruikt. Dus ik heb de opgeslagen procedures zo gestructureerd dat ze elk hun eigen tabelvariabele maken en de resultaten daar opslaan, of de onbewerkte gegevens daar opslaan en vervolgens het resultaat bijwerken. Het andere probleem dat ik wilde elimineren, was het terugsturen van de gegevens naar de client - dus de procedures hebben elk een debug-parameter die aangeeft of er geen resultaten moeten worden geretourneerd (de standaard), top/bottom 5 of allemaal. In de prestatietests heb ik het ingesteld om geen resultaten te retourneren, maar ik heb ze natuurlijk allemaal gevalideerd om er zeker van te zijn dat ze de juiste resultaten gaven.
De opgeslagen procedures zijn allemaal op deze manier gemodelleerd (ik heb een script toegevoegd dat de database en de opgeslagen procedures maakt, dus ik voeg hier voor de beknoptheid een sjabloon toe):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO En ik belde ze als volgt in een batch:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Ik realiseerde me al snel dat sommige van deze aanroepen niet in Top SQL verschenen omdat de standaarddrempel 5 seconden is. Ik heb dat als volgt gewijzigd in 100 milliseconden (iets wat je nooit wilt doen op een productiesysteem!)
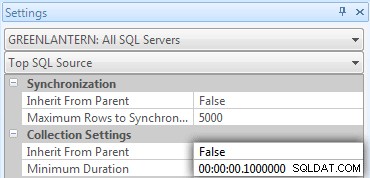
Ik herhaal:dit gedrag is niet toegestaan voor productiesystemen!
Ik ontdekte nog steeds dat een van de bovenstaande commando's niet werd opgevangen door de Top SQL-drempel; het was de Windowed_Rows-versie. Dus ik heb alleen het volgende aan die batch toegevoegd:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
En nu kreeg ik alle 7 rijen terug in Top SQL. Hier zijn ze gerangschikt op aflopend CPU-gebruik:
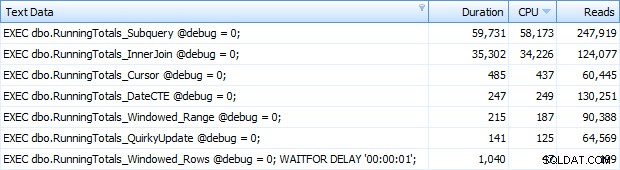
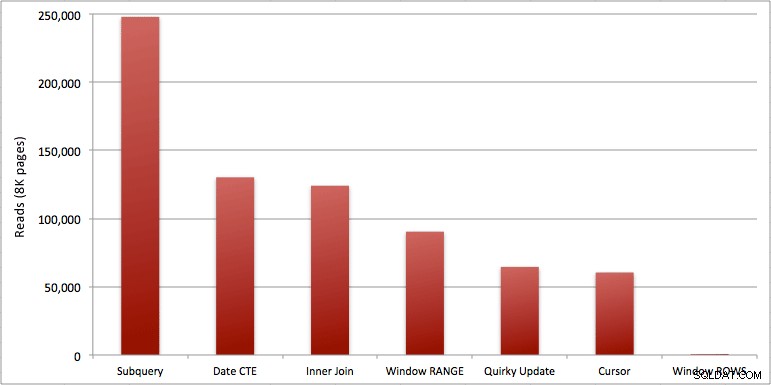
Je kunt de extra seconde zien die ik heb toegevoegd aan de batch Windowed_Rows; het werd niet opgevangen door de Top SQL-drempel omdat het in slechts 40 milliseconden voltooid was! Dit is duidelijk onze beste presteerder en als we SQL Server 2012 beschikbaar hebben, zou dit de methode moeten zijn die we gebruiken. De cursor is ook niet half slecht, gezien de prestaties of andere problemen met de resterende oplossingen. Het uitzetten van de duur in een grafiek is vrij zinloos - twee hoogtepunten en vijf niet te onderscheiden dieptepunten. Maar als I/O je bottleneck is, vind je de visualisatie van reads misschien interessant:
Conclusie
Uit deze resultaten kunnen we een paar conclusies trekken:
- Gevensterde aggregaten in SQL Server 2012 maken prestatieproblemen met lopende totalenberekeningen (en vele andere volgende rij(en)/vorige rij(en) problemen) alarmerend efficiënter. Toen ik het lage aantal reads zag, dacht ik zeker dat er een of andere fout was, dat ik moet zijn vergeten om daadwerkelijk enig werk uit te voeren. Maar nee, u krijgt hetzelfde aantal reads als uw opgeslagen procedure gewoon een gewone SELECT uit de SpeedingTickets-tabel uitvoert. (Voel je vrij om dit zelf te testen met STATISTICS IO.)
- De problemen die ik eerder aanhaalde over RANGE vs. ROWS leveren enigszins verschillende looptijden op (duurverschil van ongeveer 6x - vergeet niet de tweede te negeren die ik heb toegevoegd met WAITFOR), maar de leesverschillen zijn astronomisch vanwege de spool op de schijf. Als uw aggregaat met vensters kan worden opgelost met RIJEN, vermijd dan RANGE, maar u moet testen dat beide hetzelfde resultaat geven (of in ieder geval dat RIJEN het juiste antwoord geeft). Houd er ook rekening mee dat als u een vergelijkbare zoekopdracht gebruikt en u geen RANGE of ROWS opgeeft, het plan werkt alsof u RANGE had opgegeven).
- De subquery- en inner join-methoden zijn relatief slecht. 35 seconden tot een minuut om deze lopende totalen te genereren? En dit was op een enkele, magere tafel zonder de resultaten naar de klant terug te sturen. Deze vergelijkingen kunnen worden gebruikt om mensen te laten zien waarom een puur set-gebaseerde oplossing niet altijd het beste antwoord is.
- Van de snellere benaderingen, ervan uitgaande dat u nog niet klaar bent voor SQL Server 2012, en ervan uitgaande dat u zowel de eigenzinnige updatemethode (niet-ondersteund) als de CTE-datummethode negeert (kan geen aaneengesloten reeks garanderen), presteert alleen de cursor aanvaardbaar. Het heeft de hoogste duur van de "snellere" oplossingen, maar het minste aantal reads.
Ik hoop dat deze tests helpen om een beter beeld te krijgen van de vensterverbeteringen die Microsoft heeft toegevoegd aan SQL Server 2012. Gelieve Itzik te bedanken als u hem online of persoonlijk tegenkomt, aangezien hij de drijvende kracht achter deze veranderingen was. Bovendien hoop ik dat dit sommige mensen helpt te beseffen dat een cursor misschien niet altijd de slechte en gevreesde oplossing is die vaak wordt afgebeeld.
(Als een addendum heb ik de CLR-functie van Pavel Pawlowski getest en de prestatiekenmerken waren bijna identiek aan de SQL Server 2012-oplossing met behulp van ROWS. Reads waren identiek, CPU was 78 versus 47, en de totale duur was 73 in plaats van 40. Dus als u in de nabije toekomst niet naar SQL Server 2012 overstapt, kunt u de oplossing van Pavel aan uw tests toevoegen.)
Bijlagen:RunningTotals_Demo.sql.zip (2kb)