Er zijn twee complementaire vaardigheden die erg nuttig zijn bij het afstemmen van zoekopdrachten. Een daarvan is het vermogen om uitvoeringsplannen te lezen en te interpreteren. De tweede is iets weten over hoe de query-optimizer werkt om SQL-tekst te vertalen naar een uitvoeringsplan. Door de twee dingen samen te voegen, kunnen we zien wanneer een verwachte optimalisatie niet is toegepast, wat resulteert in een uitvoeringsplan dat niet zo efficiënt is als het zou kunnen zijn. Het gebrek aan documentatie over welke optimalisaties SQL Server precies kan toepassen (en onder welke omstandigheden), betekent echter dat veel hiervan op ervaring neerkomt.
Een voorbeeld
De voorbeeldquery voor dit artikel is gebaseerd op een vraag van SQL Server MVP Fabiano Amorim een paar maanden geleden, op basis van een reëel probleem dat hij tegenkwam. Het onderstaande schema en de testquery is een vereenvoudiging van de werkelijke situatie, maar behoudt alle belangrijke functies.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Test 1 – 10.000 rijen, SQL Server 2005+
De specifieke tabelgegevens doen er voor deze tests niet echt toe. De volgende query's laden eenvoudig 10.000 rijen uit een getallentabel naar elk van de drie testtabellen:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Nadat de gegevens zijn geladen, is het uitvoeringsplan dat voor de testquery is gemaakt:
SELECT MAX(c1) FROM dbo.V1;
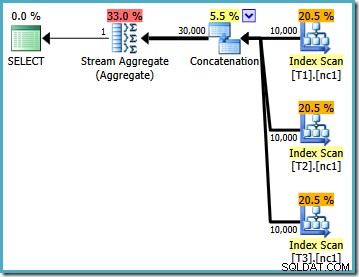
Dit uitvoeringsplan is een vrij directe implementatie van de logische SQL-query (nadat de view-referentie V1 is uitgebreid). De optimizer ziet de zoekopdracht na weergave-uitbreiding, bijna alsof de zoekopdracht volledig is uitgeschreven:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Als we de uitgebreide tekst vergelijken met het uitvoeringsplan, is de directheid van de implementatie van de query-optimizer duidelijk. Er is een Index Scan voor elke lezing van de basistabellen, een Concatenatie-operator om de UNION ALL te implementeren , en een Stream Aggregate voor de laatste MAX aggregaat.
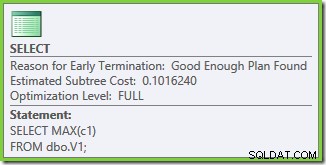
Uit de eigenschappen van het uitvoeringsplan blijkt dat op kosten gebaseerde optimalisatie is gestart (optimalisatieniveau is FULL ), maar dat het vroegtijdig stopte omdat er een ‘goed genoeg’ plan was gevonden. De geschatte kosten van het geselecteerde abonnement zijn 0,1016240 magische optimalisatie-eenheden.
Test 2 – 50.000 rijen, SQL Server 2008 en 2008 R2
Voer het volgende script uit om de testomgeving opnieuw in te stellen voor uitvoering met 50.000 rijen:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
Het uitvoeringsplan voor deze test is afhankelijk van de versie van SQL Server die u gebruikt. In SQL Server 2008 en 2008 R2 krijgen we het volgende plan:
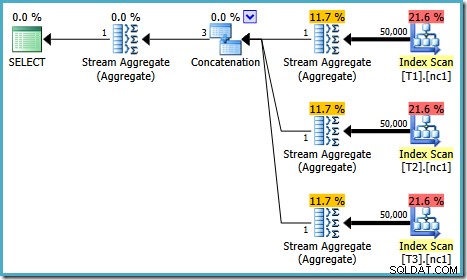
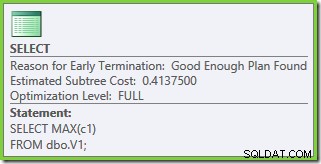
Uit de planeigenschappen blijkt dat op kosten gebaseerde optimalisatie om dezelfde reden als voorheen toch vroegtijdig eindigde. De geschatte kosten zijn hoger dan voorheen:0.41375 eenheden, maar dat wordt verwacht vanwege de hogere kardinaliteit van de basistabellen.
Test 3 – 50.000 rijen, SQL Server 2005 en 2012
Dezelfde query uitgevoerd in 2005 of 2012 levert een ander uitvoeringsplan op:
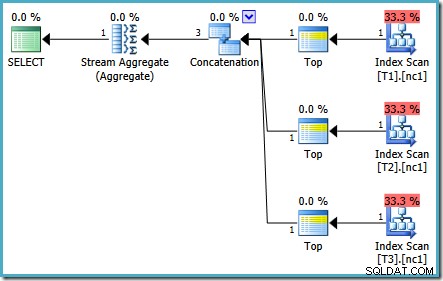
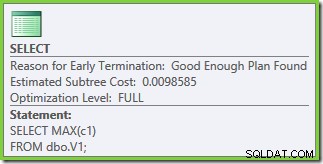
De optimalisatie eindigde weer vroeg, maar de geschatte abonnementskosten voor 50.000 rijen per basistabel zijn gedaald tot 0,0098585 (van 0.41375 op SQL Server 2008 en 2008 R2).
Uitleg
Zoals u wellicht weet, verdeelt de SQL Server-query-optimizer de optimalisatie-inspanningen in meerdere fasen, waarbij latere fasen meer optimalisatietechnieken toevoegen en meer tijd geven. De optimalisatiefasen zijn:
- Tviaal plan
- Op kosten gebaseerde optimalisatie
- Transactieverwerking (zoek 0)
- Snelplan (zoek 1)
- Snelplan met parallellisme ingeschakeld
- Volledige optimalisatie (zoekopdracht 2)
Geen van de tests die hier zijn uitgevoerd, komt in aanmerking voor een triviaal plan, omdat het aggregaat en de vakbonden meerdere implementatiemogelijkheden hebben, wat een op kosten gebaseerde beslissing vereist.
Transactieverwerking
De transactieverwerkingsfase (TP) vereist dat een query ten minste drie tabelverwijzingen bevat, anders slaat de op kosten gebaseerde optimalisatie deze fase over en gaat u direct door naar Snel plan. De TP-fase is gericht op de goedkope navigatiequery's die typisch zijn voor OLTP-workloads. Het probeert een beperkt aantal optimalisatietechnieken en is beperkt tot het vinden van plannen met geneste lus-joins (tenzij een hash-join nodig is om een geldig plan te genereren).
In sommige opzichten is het verrassend dat de testquery in aanmerking komt voor een fase gericht op het vinden van OLTP-plannen. Hoewel de query de vereiste drie tabelverwijzingen bevat, bevat deze geen joins. De vereiste van drie tabellen is slechts een heuristiek, dus ik zal er niet op ingaan.
Welke Optimizer-fasen zijn uitgevoerd?
Er zijn een aantal methoden, waarvan de gedocumenteerde is om de inhoud van sys.dm_exec_query_optimizer_info voor en na compilatie te vergelijken. Dit is prima, maar het registreert instantie-brede informatie, dus u moet oppassen dat de uwe de enige querycompilatie is die tussen snapshots plaatsvindt.
Een ongedocumenteerd (maar redelijk bekend) alternatief dat werkt op alle momenteel ondersteunde versies van SQL Server is het inschakelen van traceervlaggen 8675 en 3604 tijdens het compileren van de query.
Test 1
Deze test produceert traceringsvlag 8675-uitvoer vergelijkbaar met het volgende:

De geschatte kosten van 0,101624 na de TP-fase zijn laag genoeg zodat de optimizer niet op zoek gaat naar goedkopere plannen. Het eenvoudige plan waarmee we eindigen is redelijk gezien de relatief lage kardinaliteit van de basistabellen, ook al is het niet echt optimaal.
Test 2
Met 50.000 rijen in elke basistabel onthult de traceringsvlag verschillende informatie:

Deze keer zijn de geschatte kosten na de TP-fase 0,428735 (meer rijen =hogere kosten). Dit is voldoende om de optimizer in de Quick Plan-fase te stimuleren. Met meer optimalisatietechnieken beschikbaar, vindt deze fase een plan met een kostprijs van 0.41375 . Dit is geen enorme verbetering ten opzichte van het test 1-plan, maar het is lager dan de standaardkostendrempel voor parallellisme, en niet genoeg om volledige optimalisatie in te voeren, dus de optimalisatie eindigt opnieuw vroeg.
Test 3
Voor de uitvoering van SQL Server 2005 en 2012, is de uitvoer van de traceervlag:

Er zijn kleine verschillen in het aantal taken dat tussen versies wordt uitgevoerd, maar het belangrijkste verschil is dat op SQL Server 2005 en 2012 de fase Snel plan een plan vindt dat slechts 0,0098543 kost. eenheden. Dit is het plan dat Top-operators bevat in plaats van de drie stroomaggregaten onder de samenvoegingsoperator die wordt gezien in de SQL Server 2008- en 2008 R2-plannen.
Bugs en ongedocumenteerde oplossingen
SQL Server 2008 en 2008 R2 bevatten een regressiebug (vergeleken met 2005) die is opgelost onder traceringsvlag 4199, maar voor zover ik weet niet gedocumenteerd. Er is documentatie voor TF 4199 die fixes vermeldt die beschikbaar zijn gemaakt onder afzonderlijke traceringsvlaggen voordat ze onder 4199 vielen, maar zoals dat Knowledge Base-artikel zegt:
Deze ene traceervlag kan worden gebruikt om alle correcties in te schakelen die eerder zijn gemaakt voor de queryprocessor onder vele traceervlaggen. Bovendien zullen alle toekomstige reparaties van de queryprocessor worden beheerd met behulp van deze traceringsvlag.
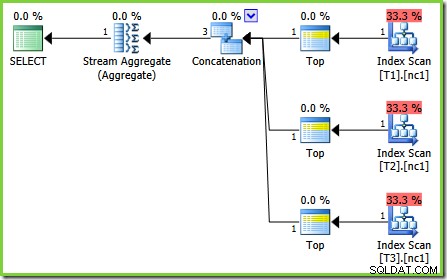
De bug in dit geval is een van die 'toekomstige fixes voor queryprocessors'. Een bepaalde optimalisatieregel, ScalarGbAggToTop , wordt niet toegepast op de nieuwe aggregaten die te zien zijn in het test 2-plan. Met traceringsvlag 4199 ingeschakeld op geschikte builds van SQL Server 2008 en 2008 R2, is de bug opgelost en wordt het optimale plan van test 3 verkregen:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Conclusie
Als je eenmaal weet dat de optimizer een scalaire MIN . kan transformeren of MAX aggregeren tot een TOP (1) op een geordende stream lijkt het in test 2 getoonde plan vreemd. De scalaire aggregaten boven een indexscan (die orde kan bieden als daarom wordt gevraagd) vallen op als een gemiste optimalisatie die normaal gesproken zou worden toegepast.
Dit is het punt dat ik in de inleiding maakte:als je eenmaal een idee hebt van het soort dingen dat de optimizer kan doen, kan het je helpen gevallen te herkennen waarin er iets mis is gegaan.
Het antwoord zal niet altijd zijn om traceringsvlag 4199 in te schakelen, omdat u mogelijk problemen tegenkomt die nog niet zijn opgelost. U wilt misschien ook niet dat de andere QP-correcties die onder de traceringsvlag vallen, in een bepaald geval van toepassing zijn - optimalisatiecorrecties maken de zaken niet altijd beter. Als ze dat wel deden, zou het niet nodig zijn om te beschermen tegen ongelukkige planregressies met deze vlag.
De oplossing in andere gevallen kan zijn om de SQL-query te formuleren met een andere syntaxis, om de query op te splitsen in meer optimalisatievriendelijke brokken, of iets heel anders. Wat het antwoord ook blijkt te zijn, het loont nog steeds om wat te weten over de internals van optimalisatieprogramma's, zodat je kunt herkennen dat er in de eerste plaats een probleem was :)