Toen ik een paar weken geleden in Chicago was voor een van onze Immersion Events, had een deelnemer een statistische vraag. Ik zal niet ingaan op alle details over het probleem, maar de deelnemer zei dat de statistieken zijn bijgewerkt met sp_updatestats . Dit is een methode om statistieken bij te werken die ik nooit heb aanbevolen; Ik heb altijd een combinatie aanbevolen van index-rebuilds en UPDATE STATISTICS statistieken up-to-date te houden. Als u niet bekend bent met sp_updatestats , het is een opdracht die voor de hele database wordt uitgevoerd om statistieken bij te werken. Maar zoals Kimberly de deelnemer opmerkte, sp_updatestats zal een statistiek bijwerken zolang er één rij is gewijzigd. Wauw. Ik opende meteen Books Online, en voor sp_updatestats je ziet dit:
Nu geef ik toe dat ik een aanname deed over wat "... updaten vereist op basis van de rowmodctr-informatie in de sys.sysindexes-catalogusweergave..." betekende. Ik ging ervan uit dat de update-beslissing dezelfde logica zou volgen als de optie Statistieken automatisch bijwerken, namelijk:
- De tabelgrootte is van 0 naar>0 rijen gegaan (test 1).
- Het aantal rijen in de tabel toen de statistieken werden verzameld was 500 of minder, en de colmodctr van de leidende kolom van het statistiekobject is sindsdien met meer dan 500 veranderd (test 2).
- De tabel had meer dan 500 rijen toen de statistieken werden verzameld, en de colmodctr van de leidende kolom van het statistiekobject is veranderd met meer dan 500 + 20% van het aantal rijen in de tabel toen de statistieken werden verzameld ( toets 3)).
Deze logica wordt niet gevolgd voor sp_updatestats . In feite is de logica zo ongelooflijk eenvoudig, het is eng:als een rij wordt gewijzigd, wordt de statistiek bijgewerkt. Een rij. EEN RIJ. Wat is mijn zorg? Ik maak me zorgen over de overhead van het bijwerken van statistieken voor een heleboel statistieken die niet echt hoeven te worden bijgewerkt. Laten we sp_updatestats eens nader bekijken .
We beginnen met een nieuwe kopie van de AdventureWorks2012-database die u kunt downloaden van Codeplex. Ik ga eerst de rijen in drie verschillende tabellen bijwerken:
USE [AdventureWorks2012];
GO
SET NOCOUNT ON;
GO
UPDATE [Production].[Product]
SET [Name] = 'Bike Chain'
WHERE [ProductID] = 952;
UPDATE [Person].[Person]
SET [LastName] = 'Cameron'
WHERE [LastName] = 'Diaz';
GO
INSERT INTO Sales.SalesReason
(Name, ReasonType, ModifiedDate)
VALUES('Stats', 'Test', GETDATE());
GO 10000
We hebben één rij aangepast in Production.Product , 211 rijen in Person.Person , en we hebben 10.000 rijen toegevoegd aan Sales.SalesReason . Als de sp_updatestats procedure volgde dezelfde logica voor updates als de optie Statistieken automatisch bijwerken, dan alleen Sales.SalesReason zou updaten omdat het 10 rijen had om te beginnen (terwijl de 211 rijen werden bijgewerkt in Person.Person ongeveer één procent van de tabel vertegenwoordigen). Als we echter ingaan op sp_updatestats , kunnen we zien dat de gebruikte logica anders is. Merk op dat ik alleen de verklaringen uit sp_updatestats haal die worden gebruikt om te bepalen welke statistieken worden bijgewerkt.
Een cursor doorloopt alle door de gebruiker gedefinieerde tabellen en interne tabellen in de database:
declare ms_crs_tnames cursor local fast_forward read_only for select name, object_id, schema_id, type from sys.objects o where o.type = 'U' or o.type = 'IT' open ms_crs_tnames fetch next from ms_crs_tnames into @table_name, @table_id, @sch_id, @table_type
Een andere cursor loopt door de statistieken voor elke tabel en sluit stapels en hypothetische indexen en statistieken uit. Merk op dat sys.sysindexes wordt gebruikt in sp_helpstats . Sysindexes is een SQL Server 2000-systeemtabel en zal naar verwachting worden verwijderd in een toekomstige versie van SQL Server. Dit is interessant, aangezien de andere methode om de bijgewerkte rijen te bepalen de sys.dm_db_stats_properties is DMF, dat alleen beschikbaar is in SQL 2008 R2 SP2 en SQL 2012 SP1.
set @index_names = cursor local fast_forward read_only for select name, indid, rowmodctr from sys.sysindexes where id = @table_id and indid > 0 and indexproperty(id, name, 'ishypothetical') = 0 order by indid
Na een beetje voorbereiding en extra logica komen we bij een IF verklaring waaruit blijkt dat sp_updatestats filtert statistieken uit die geen rijen hebben bijgewerkt... om te bevestigen dat zelfs als er maar één rij is gewijzigd, de statistiek wordt bijgewerkt. Er is ook een cheque voor @is_ver_current , die wordt bepaald door een ingebouwde, interne functie.
if ((@ind_rowmodctr <> 0) or ((@is_ver_current is not null) and (@is_ver_current = 0)))
Nog een paar controles met betrekking tot bemonstering en compatibiliteitsniveau, en dan de UPDATE statement wordt uitgevoerd voor de statistiek. Voordat we sp_updatestats daadwerkelijk uitvoeren, kunnen we sys.sysindexes query opvragen om te zien welke statistieken worden bijgewerkt:
SELECT [o].[name], [si].[indid], [si].[name], [si].[rowmodctr], [si].[rowcnt], [o].[type] FROM [sys].[objects] [o] JOIN [sys].[sysindexes] [si] ON [o].[object_id] = [si].[id] WHERE ([o].[type] = 'U' OR [o].[type] = 'IT') AND [si].[indid] > 0 AND [si].[rowmodctr] <> 0 ORDER BY [o].[type] DESC, [o].[name];
Naast de drie tabellen die we hebben aangepast, is er nog een andere statistiek voor een gebruikerstabel (dbo.DatabaseLog ) en drie interne statistieken die worden bijgewerkt:
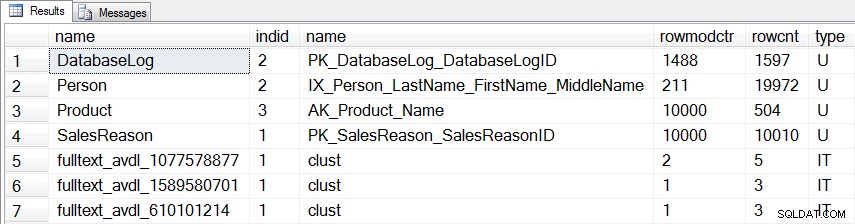
Statistieken die worden bijgewerkt
Als we sp_updatestats . uitvoeren voor de AdventureWorks-database geeft de uitvoer een lijst van alle tabellen en de bijgewerkte statistiek(en). De onderstaande uitvoer is aangepast om alleen bijgewerkte statistieken weer te geven:
Updaten van [sys].[fulltext_avdl_1589580701]
[clust] is bijgewerkt...
1 index(en)/statistiek(en) zijn bijgewerkt, 0 vereiste geen update.
…
Updaten van [dbo].[DatabaseLog]
[PK_DatabaseLog_DatabaseLogID] is bijgewerkt...
1 index(en)/statistiek(en) zijn bijgewerkt, 0 hoefde niet te worden bijgewerkt.
…
Updaten van [sys].[fulltext_avdl_1077578877]
[clust] is bijgewerkt...
1 index(en)/statistiek(en) zijn bijgewerkt, 0 vereiste geen update.
…
Updaten van [Person].[Person]
[PK_Person_BusinessEntityID], update is niet nodig...
[IX_Person_LastName_FirstName_MiddleName] is bijgewerkt...
[AK_Person_rowguid], update is niet nodig...
1 index(en)/statistiek(en) zijn bijgewerkt, 2 hadden geen update nodig.
…
Updaten van [Sales].[SalesReason]
[PK_SalesReason_SalesReasonID] is bijgewerkt...
1 index(en)/statistiek(en) zijn bijgewerkt, 0 hoefde niet te worden bijgewerkt.
…
Updaten van [Productie].[Product]
[PK_Product_ProductID], update is niet nodig...
[AK_Product_ProductNumber], update is niet nodig...
[AK_Product_Name] is bijgewerkt...
[ AK_Product_rowguid], update is niet nodig...
[_WA_Sys_00000013_75A278F5], update is niet nodig...
[_WA_Sys_00000014_75A278F5], update is niet nodig...
[_WA_Sys_0000000D_75A278F5], update is niet nodig...
[_WA_Sys_0000000C_75A278F5], update is niet nodig...
1 index(en)/statistiek(en) zijn bijgewerkt, 7 hadden geen update nodig.
…
Statistieken voor alle tabellen zijn bijgewerkt.
De laatste regel van de uitvoer is een beetje misleidend - statistieken voor alle tabellen zijn niet bijgewerkt, alleen de statistieken die één of meer rijen hebben gewijzigd, zijn bijgewerkt. En nogmaals, het nadeel daarvan is dat er misschien middelen zijn gebruikt die dat niet hoefden te zijn. Als een statistiek slechts één rij heeft gewijzigd, moet deze dan worden bijgewerkt? Nee. Als er 10.000 rijen zijn bijgewerkt, moet deze dan worden bijgewerkt? Nou, dat hangt ervan af. Als de tabel maar 5.000 rijen heeft, dan absoluut; als de tabel 1 miljoen rijen heeft, nee, want slechts één procent van de tabel is gewijzigd.
Het voordeel hier is dat als je sp_updatestats . gebruikt om uw statistieken bij te werken, verspilt u hoogstwaarschijnlijk bronnen, waaronder CPU, I/O en tempdb. Verder kost het tijd om elke statistiek bij te werken, en als je een strak onderhoudsvenster hebt, heb je waarschijnlijk andere onderhoudstaken die in die tijd kunnen worden uitgevoerd, in plaats van onnodige updates. Ten slotte biedt u waarschijnlijk geen prestatievoordelen door statistieken bij te werken als er zo weinig rijen zijn gewijzigd. De distributiewijziging is waarschijnlijk onbeduidend als slechts een klein percentage rijen is gewijzigd, dus het histogram en de dichtheidswaarden veranderen uiteindelijk niet zo veel. Houd er bovendien rekening mee dat het bijwerken van statistieken de queryplannen die deze statistieken gebruiken ongeldig maakt. Wanneer die query's worden uitgevoerd, worden plannen opnieuw gegenereerd en zal het plan waarschijnlijk precies hetzelfde zijn als voorheen, omdat er geen significante verandering in het histogram was. Er zijn kosten verbonden aan het opnieuw samenstellen van queryplannen - het is niet altijd gemakkelijk te meten, maar het mag niet worden genegeerd.
Een betere methode om statistieken te beheren - omdat u statistieken moet beheren - is om een geplande taak te implementeren die wordt bijgewerkt op basis van de percentages rijen die zijn gewijzigd. U kunt de bovengenoemde query gebruiken die sys.sysindexes . ondervraagt , of u kunt de onderstaande query gebruiken die gebruikmaakt van de nieuwe DMF die is toegevoegd in SQL Server 2008 R2 SP2 en SQL Server 2012 SP1:
SELECT [sch].[name] + '.' + [so].[name] AS [TableName] , [ss].[name] AS [Statistic], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications] FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp WHERE [so].[type] = 'U' AND [sp].[modification_counter] > 0 ORDER BY [sp].[last_updated] DESC;
Realiseer je dat verschillende tabellen verschillende drempels kunnen hebben en dat je de bovenstaande query voor je databases moet aanpassen. Voor sommige tabellen kan het oké zijn om te wachten tot 15% of 20% van de rijen is gewijzigd. Maar voor anderen moet u mogelijk bijwerken met 10% of zelfs 5%, afhankelijk van de werkelijke waarden en hun scheeftrekking. Er is geen zilveren kogel. Hoezeer we ook van absolute waarden houden, ze bestaan zelden in SQL Server en statistieken vormen daarop geen uitzondering. U wilt Statistieken voor automatisch bijwerken nog steeds ingeschakeld laten - het is een beveiliging die in werking treedt als u iets mist, net als Auto Growth voor uw databasebestanden. Maar u kunt het beste uw gegevens kennen en een methode implementeren waarmee u statistieken kunt bijwerken op basis van het percentage gewijzigde rijen.