Bij het uitvoeren van een query probeert de SQL Server-optimizer het beste queryplan te vinden op basis van bestaande indexen en beschikbare nieuwste statistieken voor een redelijke tijd, natuurlijk, als dit plan niet al in de servercache is opgeslagen. Zo nee, dan wordt de query uitgevoerd volgens dit plan en wordt het plan opgeslagen in de servercache. Als het plan al is gemaakt voor deze query, wordt de query uitgevoerd volgens het bestaande plan.
We zijn geïnteresseerd in het volgende nummer:
Tijdens het samenstellen van een queryplan, bij het sorteren van mogelijke indexen, als de server de beste index niet vindt, wordt de ontbrekende index gemarkeerd in het queryplan en houdt de server statistieken bij over dergelijke indexen:hoe vaak zou de server deze index gebruiken en hoeveel deze zoekopdracht zou kosten.
In dit artikel gaan we deze ontbrekende indexen analyseren - hoe ermee om te gaan.
Laten we dit bij een bepaald voorbeeld bekijken. Maak een paar tabellen in onze database op een lokale en testserver:
[titel uitvouwen =”Code”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/uitbreiden]
De structuur is eenvoudig en bestaat uit twee tabellen. De eerste tabel heet orders met velden als een identifier, datum van verkoop en verkoper. De tweede is de bestelgegevens, waarbij sommige goederen worden gespecificeerd met prijs en hoeveelheid.
Bekijk een eenvoudige zoekopdracht en het bijbehorende plan:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
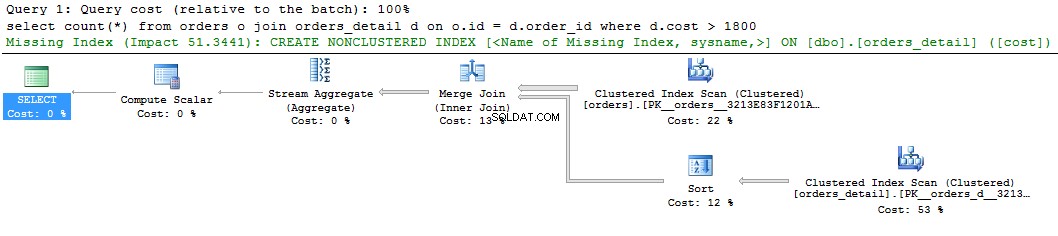
We zien een groene hint over de ontbrekende index op de grafische weergave van het queryplan. Als u er met de rechtermuisknop op klikt en "Ontbrekende indexdetails .." selecteert, verschijnt de tekst van de voorgestelde index. Het enige wat u hoeft te doen is de opmerkingen in de tekst te verwijderen en de index een naam te geven. Het script is klaar om uitgevoerd te worden.
We zullen niet de index bouwen die we hebben ontvangen op basis van de hint van SSMS. In plaats daarvan zullen we zien of deze index wordt aanbevolen door dynamische weergaven die zijn gekoppeld aan ontbrekende indexen. De weergaven zijn als volgt:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
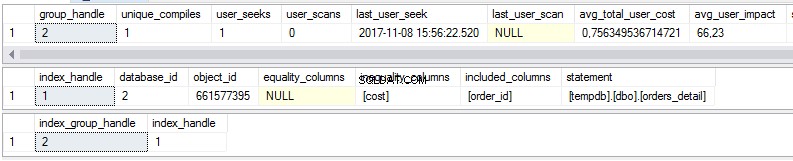
Zoals we kunnen zien, zijn er enkele statistieken over ontbrekende indexen in de eerste weergave:
- Hoe vaak zou een zoekopdracht worden uitgevoerd als de voorgestelde index bestond?
- Hoe vaak zou een scan worden uitgevoerd als de voorgestelde index bestond?
- Laatste datum en tijd waarop we de index hebben gebruikt
- De huidige werkelijke kosten van het zoekplan zonder de voorgestelde index.
De tweede weergave is de index:
- Database
- Object/tabel
- Gesorteerde kolommen
- Kolommen toegevoegd om de indexdekking te vergroten
De derde weergave is de combinatie van de eerste en tweede weergave.
Dienovereenkomstig is het niet moeilijk om een script te krijgen dat een script zou genereren om ontbrekende indexen van deze dynamische weergaven te maken. Het script is als volgt:
[uitbreiden title=”Code”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/uitbreiden]
Voor indexefficiëntie worden de ontbrekende indexen uitgevoerd. De perfecte oplossing is wanneer deze resultaatset niets retourneert. In ons voorbeeld retourneert de resultatenset ten minste één index:

Als er geen tijd is en je geen zin hebt om met de client-bugs om te gaan, heb ik de query uitgevoerd, de eerste kolom gekopieerd en op de server uitgevoerd. Hierna werkte alles goed.
Ik raad aan om bewust om te gaan met de informatie op deze indexen. Als het systeem bijvoorbeeld de volgende indexen aanbeveelt:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
En deze indexen worden gebruikt voor het zoeken, het is vrij duidelijk dat het logischer is om deze indexen te vervangen door een index die alle drie de voorgestelde dekt:
create index ix_1 on tbl1 (a,b) include (c,d)
Daarom beoordelen we de ontbrekende indexen voordat we ze implementeren op de productieserver. Hoewel…. Nogmaals, ik heb bijvoorbeeld de verloren indexen op de TFS-server geïmplementeerd, waardoor de algehele prestaties zijn verbeterd. Het kostte minimale tijd om deze optimalisatie uit te voeren. Toen ik echter overstapte van TFS 2015 naar TFS 2017, kreeg ik te maken met het probleem dat er geen update was vanwege deze nieuwe indexen. Desalniettemin zijn ze gemakkelijk te vinden door het masker
select * from sys.indexes where name like 'ix[_]2017%'
Handig hulpmiddel:
dbForge Index Manager – handige SSMS-invoegtoepassing voor het analyseren van de status van SQL-indexen en het oplossen van problemen met indexfragmentatie.