Zijn uw keuzes van SQL-servergegevenstypen en hun grootte van belang?
Het antwoord ligt in het resultaat dat je hebt gekregen. Is uw database in korte tijd ballonvaren? Zijn uw zoekopdrachten traag? Had je de verkeerde resultaten? Hoe zit het met runtime-fouten tijdens invoegingen en updates?
Het is niet zozeer een ontmoedigende taak als je weet wat je doet. Vandaag leert u de 5 slechtste keuzes die u met deze gegevenstypen kunt maken. Als ze een gewoonte van u zijn geworden, moeten we dit voor u en uw gebruikers oplossen.
Veel datatypes in SQL, veel verwarring
Toen ik voor het eerst hoorde over SQL Server-gegevenstypen, waren de keuzes overweldigend. Alle typen worden in mijn hoofd door elkaar gehaald, zoals deze woordwolk in figuur 1:

We kunnen het echter in categorieën indelen:
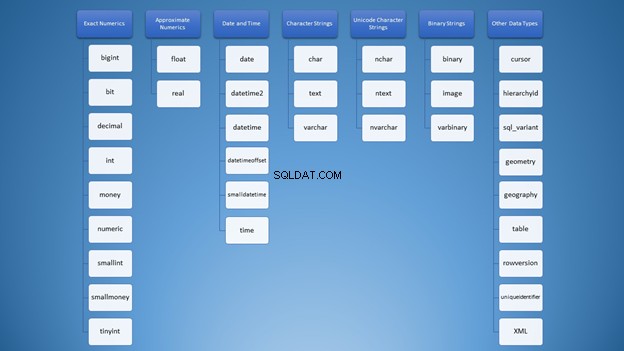
Toch heb je voor het gebruik van strings veel opties die kunnen leiden tot verkeerd gebruik. Eerst dacht ik dat varchar en nvarchar waren net hetzelfde. Bovendien zijn het beide typen tekenreeksen. Het gebruik van cijfers is niet anders. Als ontwikkelaars moeten we weten welk type we in verschillende situaties moeten gebruiken.
Maar je vraagt je misschien af, wat is het ergste dat kan gebeuren als ik de verkeerde keuze maak? Laat me je vertellen!
1. De verkeerde SQL-gegevenstypen kiezen
Dit item gebruikt tekenreeksen en gehele getallen om het punt te bewijzen.
Het verkeerde tekenreeks SQL-gegevenstype gebruiken
Laten we eerst teruggaan naar snaren. Er is zoiets dat Unicode- en niet-Unicode-strings wordt genoemd. Beide hebben verschillende opbergformaten. Je definieert dit vaak op kolommen en variabele declaraties.
De syntaxis is ofwel varchar (n)/char (n) of nvarchar (n)/nchar (n) waar n is de maat.
Merk op dat n is niet het aantal karakters maar het aantal bytes. Het is een veel voorkomende misvatting die optreedt omdat, in varchar , is het aantal tekens gelijk aan de grootte in bytes. Maar niet in nvarchar .
Laten we, om dit feit te bewijzen, 2 tabellen maken en er wat gegevens in plaatsen.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Laten we nu hun rijgroottes controleren met DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Figuur 3 laat zien dat het verschil tweeledig is. Bekijk het hieronder.
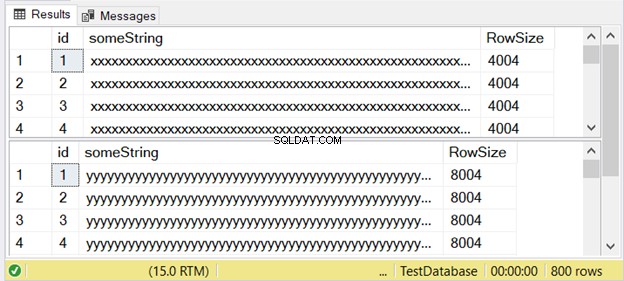
Let op de tweede resultaatset met een rijgrootte van 8004. Dit gebruikt de nvarchar data type. Het is ook bijna twee keer groter dan de rijgrootte van de eerste resultatenset. En dit gebruikt de varchar gegevenstype.
Je ziet de implicaties voor opslag en I/O. Afbeelding 4 toont de logische uitlezingen van de 2 zoekopdrachten.
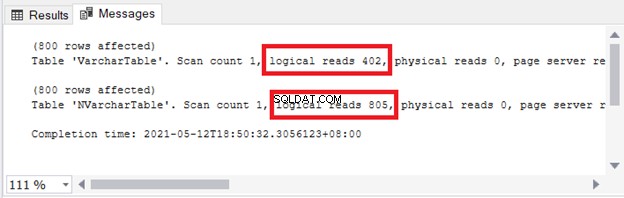
Zie je wel? Logische uitlezingen zijn ook tweeledig bij gebruik van nvarchar vergeleken met varchar .
U kunt ze dus niet zomaar door elkaar gebruiken. Als u meertalig moet opslaan tekens, gebruik nvarchar . Gebruik anders varchar .
Dit betekent dat als u nvarchar . gebruikt alleen voor enkelbyte-tekens (zoals Engels), is de opslaggrootte groter . Queryprestaties zijn ook trager met hogere logische uitlezingen.
In SQL Server 2019 (en hoger) kunt u het volledige bereik van Unicode-tekengegevens opslaan met varchar of char met een van de UTF-8 sorteeropties.
Het verkeerde numerieke gegevenstype SQL gebruiken
Hetzelfde concept is van toepassing op bigint vs. int – hun afmetingen kunnen dag en nacht betekenen. Zoals nvarchar en varchar , groot is dubbel zo groot als int (8 bytes voor bigint en 4 bytes voor int ).
Toch is er nog een ander probleem mogelijk. Als je hun maten niet erg vindt, kunnen er fouten optreden. Als u een int . gebruikt kolom en een getal groter dan 2.147.483.647 opslaat, zal een rekenkundige overloop optreden:
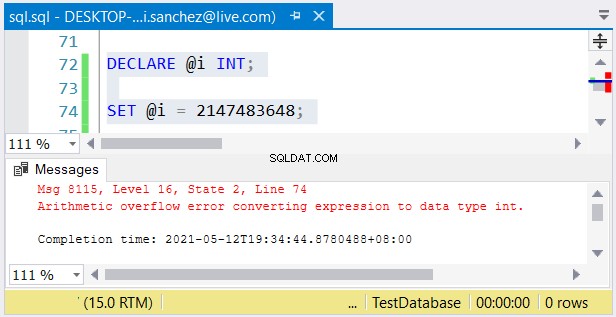
Bij het kiezen van typen gehele getallen, zorg ervoor dat de gegevens met de maximale waarde passen . U ontwerpt bijvoorbeeld een tabel met historische gegevens. U bent van plan gehele getallen te gebruiken als de primaire sleutelwaarde. Denk je dat het geen 2.147.483.647 rijen zal bereiken? Gebruik dan int in plaats van bigint als het type primaire sleutelkolom.
Het ergste dat kan gebeuren
Het kiezen van de verkeerde gegevenstypen kan de prestaties van de query beïnvloeden of runtime-fouten veroorzaken. Kies dus het gegevenstype dat geschikt is voor de gegevens.
2. Grote tabelrijen maken met Big Data Types voor SQL
Ons volgende item is gerelateerd aan het eerste, maar het zal het punt nog meer uitbreiden met voorbeelden. Het heeft ook iets te maken met pagina's en grote varchar of nvarchar kolommen.
Wat is er met pagina's en rijformaten?
Het concept van pagina's in SQL Server kan worden vergeleken met de pagina's van een spiraalvormig notitieboekje. Elke pagina in een notitieblok heeft dezelfde fysieke grootte. Je schrijft woorden en tekent er afbeeldingen op. Als een pagina niet genoeg is voor een reeks alinea's en afbeeldingen, gaat u verder op de volgende pagina. Soms scheur je ook een pagina en begin je opnieuw.
Evenzo worden tabelgegevens, indexitems en afbeeldingen in SQL Server in pagina's opgeslagen.
Een pagina heeft dezelfde grootte van 8 KB. Als een rij met gegevens erg groot is, past deze niet op de pagina van 8 KB. Een of meer kolommen worden op een andere pagina geschreven onder de toewijzingseenheid ROW_OVERFLOW_DATA. Het bevat een verwijzing naar de originele rij op de pagina onder de IN_ROW_DATA-toewijzingseenheid.
Op basis hiervan kun je tijdens het databaseontwerp niet zomaar heel veel kolommen in een tabel passen. Er zullen gevolgen zijn voor I/O. Bovendien, als u veel query's uitvoert op deze row-overflow-gegevens, is de uitvoeringstijd langzamer . Dit kan een nachtmerrie zijn.
Er ontstaat een probleem wanneer u alle kolommen met verschillende afmetingen maximaal gebruikt. Vervolgens gaan de gegevens naar de volgende pagina onder ROW_OVERFLOW_DATA. update de kolommen met kleinere gegevens, en het moet op die pagina worden verwijderd. De nieuwe kleinere gegevensrij wordt samen met de andere kolommen op de pagina onder IN_ROW_DATA geschreven. Stel je de I/O voor die hier bij betrokken zijn.
Voorbeeld grote rij
Laten we eerst onze gegevens voorbereiden. We zullen gegevenstypes met tekenreeksen met grote afmetingen gebruiken.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
De rijgrootte verkrijgen
Laten we op basis van de gegenereerde gegevens hun rijgroottes inspecteren op basis van DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
De eerste 300 records passen op de IN_ROW_DATA-pagina's omdat elke rij minder dan 8060 bytes of 8 KB heeft. Maar de laatste 100 rijen zijn te groot. Bekijk de resultatenset in figuur 6.
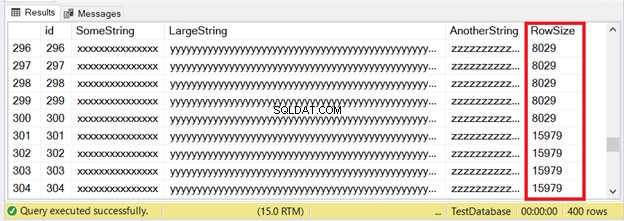
Je ziet een deel van de eerste 300 rijen. De volgende 100 overschrijden de paginagroottelimiet. Hoe weten we dat de laatste 100 rijen zich in de ROW_OVERFLOW_DATA-toewijzingseenheid bevinden?
De ROW_OVERFLOW_DATA inspecteren
We gebruiken sys.dm_db_index_physical_stats . Het geeft pagina-informatie terug over tabel- en indexitems.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
De resultatenset staat in figuur 7.

Daar is het. Afbeelding 7 toont 100 rijen onder ROW_OVERFLOW_DATA. Dit komt overeen met afbeelding 6 wanneer er grote rijen bestaan, beginnend met rijen 301 tot en met 400.
De volgende vraag is hoeveel logische reads we krijgen als we deze 100 rijen opvragen. Laten we het proberen.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

We zien 102 logische reads en 100 lob logische reads van LargeTable . Laat deze cijfers voor nu - we zullen ze later vergelijken.
Laten we nu eens kijken wat er gebeurt als we de 100 rijen bijwerken met kleinere gegevens.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Deze update-instructie gebruikte dezelfde logische reads en lob logische reads als in figuur 8. Hieruit weten we dat er iets groters gebeurde vanwege de lob logische reads van 100 pagina's.
Maar laten we het voor de zekerheid controleren met sys.dm_db_index_physical_stats zoals we eerder deden. Afbeelding 9 toont het resultaat:

Weg! Pagina's en rijen van ROW_OVERFLOW_DATA werden nul na het bijwerken van 100 rijen met kleinere gegevens. Nu weten we dat de gegevensverplaatsing van ROW_OVERFLOW_DATA naar IN_ROW_DATA plaatsvindt wanneer grote rijen worden verkleind. Stel je voor dat dit veel gebeurt voor duizenden of zelfs miljoenen records. Gek, nietwaar?
In figuur 8 zagen we 100 lob logische uitlezingen. Zie nu Afbeelding 10 na het opnieuw uitvoeren van de query:

Het werd nul!
Het ergste dat kan gebeuren
Trage queryprestaties zijn het bijproduct van de row-overflow-gegevens. Overweeg om de grote kolom(men) naar een andere tabel te verplaatsen om dit te vermijden. Of, indien van toepassing, verklein de grootte van de varchar of nvarchar kolom.
3. Blindelings gebruik maken van impliciete conversie
SQL staat ons niet toe om gegevens te gebruiken zonder het type te specificeren. Maar het is vergevingsgezind als we een verkeerde keuze maken. Het probeert de waarde om te zetten naar het type dat het verwacht, maar met een boete. Dit kan gebeuren in een WHERE-clausule of JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Het Kaartnummer kolom is geen numeriek type. Het is nvarchar . De eerste SELECT zal dus een impliciete conversie veroorzaken. Beide zullen echter prima werken en dezelfde resultatenset produceren.
Laten we het uitvoeringsplan in figuur 11 eens bekijken.
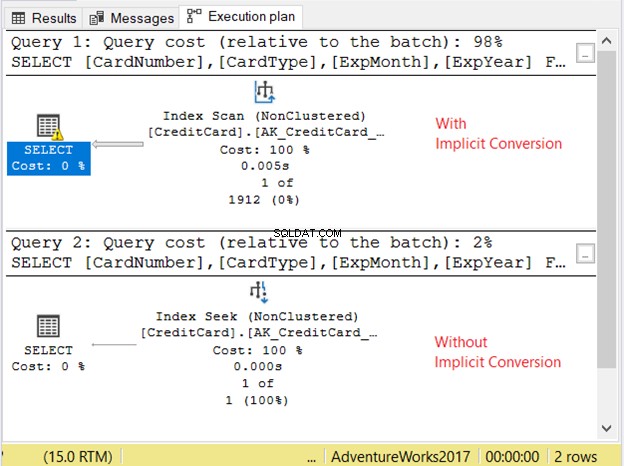
De 2 zoekopdrachten liepen erg snel. In Afbeelding 11 is het nul seconden. Maar kijk naar de 2 plannen. Degene met impliciete conversie had een indexscan. Er is ook een waarschuwingspictogram en een dikke pijl die naar de SELECT-operator wijst. Het vertelt ons dat het slecht is.
Maar daar houdt het niet op. Als u met uw muis over de SELECT-operator beweegt, ziet u iets anders:

Het waarschuwingspictogram in de SELECT-operator gaat over de impliciete conversie. Maar hoe groot is de impact? Laten we de logische waarden controleren.
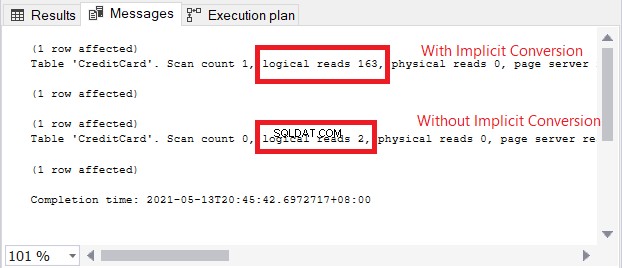
De vergelijking van logische waarden in figuur 13 is als hemel en aarde. Bij het opvragen van creditcardgegevens veroorzaakte impliciete conversie meer dan honderdvoudige logische uitlezingen. Heel slecht!
Het ergste dat kan gebeuren
Als een impliciete conversie hoge logische leesbewerkingen en een slecht plan veroorzaakte, verwacht dan trage queryprestaties bij grote resultaatsets. Om dit te voorkomen, gebruikt u het exacte gegevenstype in de WHERE-component en JOINs bij het matchen van de kolommen die u vergelijkt.
4. Geschatte cijfers gebruiken en afronden
Bekijk figuur 2 nog eens. Gegevenstypen van SQL-servers die behoren tot benaderende getallen zijn float en echt . Kolommen en variabelen die ervan zijn gemaakt, slaan een nauwkeurige benadering van een numerieke waarde op. Als u van plan bent deze getallen naar boven of naar beneden af te ronden, kunt u voor een grote verrassing komen te staan. Ik heb hier een artikel waarin dit in detail wordt besproken. Kijk hoe 1 + 1 resulteert in 3 en hoe je om kunt gaan met afrondingsgetallen.
Het ergste dat kan gebeuren
Een drijver afronden of echt kan gekke resultaten opleveren. Als u exacte waarden wilt na afronding, gebruik dan decimaal of numeriek in plaats daarvan.
5. Stringgegevenstypen met een vaste grootte instellen op NULL
Laten we onze aandacht richten op gegevenstypen met een vaste grootte, zoals char en nchar . Afgezien van de opgevulde spaties, heeft het instellen ervan op NULL nog steeds een opslaggrootte die gelijk is aan de grootte van de char kolom. Dus, een char . instellen (500) kolom naar NULL zal een grootte hebben van 500, niet nul of 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
In de bovenstaande code zijn de gegevens maximaal op basis van de grootte van char en varchar kolommen. Als u hun rijgrootte controleert met DATALENGTH, wordt ook de som van de groottes van elke kolom weergegeven. Laten we nu de kolommen op NULL zetten.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Vervolgens zoeken we de rijen op met DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Wat denkt u dat de gegevensgroottes van elke kolom zullen zijn? Bekijk figuur 14.
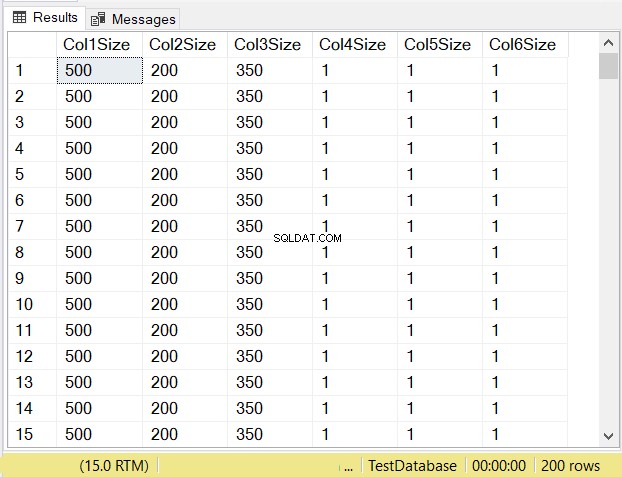
Kijk naar de kolomgroottes van de eerste 3 kolommen. Vergelijk ze vervolgens met de bovenstaande code toen de tabel werd gemaakt. De gegevensgrootte van de NULL-kolommen is gelijk aan de grootte van de kolom. Ondertussen is de varchar kolommen wanneer NULL een gegevensgrootte van 1 hebben.
Het ergste dat kan gebeuren
Tijdens het ontwerpen van tabellen, nullable char kolommen, indien ingesteld op NULL, hebben nog steeds dezelfde opslaggrootte. Ze verbruiken ook dezelfde pagina's en RAM. Als u niet de hele kolom met tekens vult, overweeg dan om varchar . te gebruiken in plaats daarvan.
Wat nu?
Dus, zijn uw keuzes in SQL-servergegevenstypen en hun grootte van belang? De punten die hier worden gepresenteerd, zouden voldoende moeten zijn om een punt te maken. Dus, wat kun je nu doen?
- Maak tijd vrij om de database die u ondersteunt door te nemen. Begin met de makkelijkste als je er meerdere op je bord hebt. En ja, maak tijd, vind de tijd niet. In ons vak is het bijna onmogelijk om tijd te vinden.
- Bekijk de tabellen, opgeslagen procedures en alles wat met gegevenstypen te maken heeft. Let op de positieve impact bij het identificeren van problemen. Je zult het nodig hebben als je baas vraagt waarom je hieraan moet werken.
- Plan om elk van de probleemgebieden aan te vallen. Volg de methoden of het beleid van uw bedrijf om de problemen aan te pakken.
- Als de problemen voorbij zijn, vier je feest.
Klinkt eenvoudig, maar we weten allemaal dat het dat niet is. We weten ook dat er een positieve kant is aan het einde van de reis. Daarom heten ze problemen – omdat er een oplossing is. Dus, vrolijk je op.
Heb je nog iets toe te voegen over dit onderwerp? Laat het ons weten in het gedeelte Opmerkingen. En als dit bericht je op een goed idee heeft gebracht, deel het dan op je favoriete sociale-mediaplatforms.