Uitvoeringsplannen bieden een rijke bron van informatie die ons kan helpen bij het identificeren van manieren om de prestaties van belangrijke query's te verbeteren. Mensen zoeken vaak naar zaken als grote scans en zoekopdrachten om mogelijke optimalisaties van het gegevenstoegangspad te identificeren. Deze problemen kunnen vaak snel worden opgelost door een nieuwe index te maken of een bestaande uit te breiden met meer kolommen.
We kunnen plannen na uitvoering ook gebruiken om het werkelijke aantal rijen met het verwachte aantal rijen tussen planoperators te vergelijken. Waar blijkt dat deze significant afwijken, kunnen we proberen betere statistische informatie aan de optimizer te leveren door bestaande statistieken bij te werken, nieuwe statistische objecten te maken, statistieken over berekende kolommen te gebruiken of misschien door een complexe query op te splitsen in minder complexe componenten onderdelen.
Daarnaast kunnen we ook kijken naar dure operaties in het plan, met name geheugenverslindende zoals sorteren en hashen. Sorteren kan soms worden vermeden door wijzigingen in de indexering. In andere gevallen moeten we de query mogelijk herstructureren met behulp van syntaxis die de voorkeur geeft aan een plan dat een bepaalde gewenste volgorde behoudt.
Soms zijn de prestaties nog steeds niet goed genoeg, zelfs nadat al deze technieken voor het afstemmen van de prestaties zijn toegepast. Een mogelijke volgende stap is om een beetje meer na te denken over het plan als geheel . Dit betekent een stap terug doen en proberen de algemene strategie te begrijpen die door de query-optimizer is gekozen, om te zien of we een algoritmische verbetering kunnen identificeren.
In dit artikel wordt dit laatste type analyse onderzocht, aan de hand van een eenvoudig voorbeeldprobleem van het vinden van unieke kolomwaarden in een redelijk grote dataset. Zoals vaak het geval is bij analoge problemen uit de echte wereld, zal de betreffende kolom relatief weinig unieke waarden hebben in vergelijking met het aantal rijen in de tabel. Deze analyse bestaat uit twee delen:het maken van de voorbeeldgegevens en het schrijven van de query met afzonderlijke waarden zelf.
De voorbeeldgegevens maken
Om het eenvoudigst mogelijke voorbeeld te geven, heeft onze testtabel slechts een enkele kolom met een geclusterde index (deze kolom bevat dubbele waarden, zodat de index niet uniek kan worden verklaard):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Om enkele getallen uit de lucht te halen, kiezen we ervoor om tien miljoen rijen te laden in totaal, met een gelijkmatige verdeling over duizend verschillende waarden . Een veelgebruikte techniek om dergelijke gegevens te genereren, is om een aantal systeemtabellen te kruisen en de ROW_NUMBER toe te passen. functie. We zullen ook de modulo-operator gebruiken om de gegenereerde getallen te beperken tot de gewenste afzonderlijke waarden:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Het geschatte uitvoeringsplan voor die zoekopdracht is als volgt (klik op de afbeelding om deze indien nodig te vergroten):

Dit duurt ongeveer 30 seconden om de voorbeeldgegevens op mijn laptop te maken. Dat is zeker niet enorm veel tijd, maar het is toch interessant om na te denken over wat we zouden kunnen doen om dit proces efficiënter te maken…
Plananalyse
We beginnen met te begrijpen waar elke operatie in het plan voor dient.
Het gedeelte van het uitvoeringsplan rechts van de segmentoperator heeft betrekking op het vervaardigen van rijen door systeemtabellen aan elkaar te koppelen:

De Segment-operator is er voor het geval de vensterfunctie een PARTITION BY . had clausule. Dat is hier niet het geval, maar het staat toch in het queryplan. De operator Sequence Project genereert de rijnummers en de Top beperkt de planuitvoer tot tien miljoen rijen:

De Compute Scalar definieert de uitdrukking die de modulo-functie toepast en voegt er een toe aan het resultaat:

We kunnen zien hoe de expressielabels Sequence Project en Compute Scalar zich verhouden met behulp van het tabblad Expressies van Plan Explorer:

Dit geeft ons een vollediger gevoel voor de stroom van dit plan:het Sequence Project nummert de rijen en labelt de uitdrukking Expr1050; de Compute Scalar labelt het resultaat van de modulo en plus-een berekening als Expr1052 . Let ook op de impliciete conversie in de Compute Scalar-expressie. De doeltabelkolom is van het type integer, terwijl de ROW_NUMBER functie produceert een bigint, dus een versmallende conversie is noodzakelijk.
De volgende operator in het plan is een Sort. Volgens de kostenramingen van de query-optimizer is dit naar verwachting de duurste operatie (88,1% geschat ):

Het is misschien niet meteen duidelijk waarom dit plan sorteert, aangezien er geen expliciete volgorde vereist is in de zoekopdracht. De sortering wordt aan het plan toegevoegd om ervoor te zorgen dat rijen in geclusterde indexvolgorde bij de operator Clustered Index Insert aankomen. Dit bevordert sequentiële schrijfacties, vermijdt paginasplitsing en is een van de vereisten voor minimaal gelogde INSERT operaties.
Dit zijn allemaal potentieel goede dingen, maar de Sort zelf is nogal duur. Inderdaad, het controleren van het uitvoeringsplan na de uitvoering ("actuele") onthult dat de Sort ook onvoldoende geheugen had op het moment van uitvoering en moest overlopen naar fysieke tempdb schijf:

De sorteerfout vindt plaats ondanks dat het geschatte aantal rijen precies goed is, en ondanks het feit dat de query al het geheugen heeft gekregen waar het om vroeg (zoals te zien is in de planeigenschappen voor de hoofdmap INSERT knooppunt):

Gemorste sortering wordt ook aangegeven door de aanwezigheid van IO_COMPLETION wacht op het tabblad Wachtstatistieken van Plan Explorer PRO:

Let ten slotte voor dit gedeelte over plananalyse op de DML Request Sort eigenschap van de operator Clustered Index Insert is ingesteld op true:

Deze vlag geeft aan dat de optimizer de substructuur onder de Insert nodig heeft om rijen in de indexsleutel gesorteerde volgorde aan te bieden (vandaar de noodzaak van de problematische sorteeroperator).
De sortering vermijden
Nu we weten waarom de Sortering verschijnt, kunnen we testen om te zien wat er gebeurt als we het verwijderen. Er zijn manieren waarop we de query kunnen herschrijven om de optimizer voor de gek te houden door te denken dat er minder rijen zouden worden ingevoegd (dus sorteren zou niet de moeite waard zijn), maar een snelle manier om de sortering direct te vermijden (alleen voor experimentele doeleinden) is om een niet-gedocumenteerde traceringsvlag te gebruiken 8795. Dit stelt de DML Request Sort . in eigenschap op false, zodat rijen niet langer nodig zijn om in geclusterde sleutelvolgorde bij de geclusterde index te komen:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Het nieuwe queryplan na uitvoering is als volgt (klik op de afbeelding om te vergroten):

De sorteeroperator is verdwenen, maar de nieuwe zoekopdracht duurt meer dan 50 seconden (vergeleken met 30 seconden voordat). Hier zijn een aantal redenen voor. Ten eerste verliezen we elke mogelijkheid van minimaal gelogde invoegingen omdat deze gesorteerde gegevens vereisen (DML Request Sort =true). Ten tweede zal een groot aantal "slechte" paginasplitsingen optreden tijdens het invoegen. Als dat contra-intuïtief lijkt, onthoud dan dat hoewel de ROW_NUMBER functienummers rijen opeenvolgend, het effect van de modulo-operator is om een herhalende reeks getallen 1…1000 te presenteren aan de geclusterde index-insert.
Hetzelfde fundamentele probleem doet zich voor als we T-SQL-trucs gebruiken om het verwachte aantal rijen te verlagen om de sortering te vermijden in plaats van de niet-ondersteunde traceringsvlag te gebruiken.
De soort II vermijden
Als we naar het plan als geheel kijken, lijkt het duidelijk dat we rijen willen genereren op een manier die een expliciete sortering vermijdt, maar die nog steeds de voordelen plukt van minimale logboekregistratie en het vermijden van slechte paginasplitsing. Simpel gezegd:we willen een plan dat rijen in geclusterde sleutelvolgorde presenteert, maar zonder te sorteren.
Gewapend met dit nieuwe inzicht kunnen we onze vraag op een andere manier uiten. De volgende query genereert elk getal van 1 tot 1000 en cross-joins die zijn ingesteld met 10.000 rijen om de vereiste mate van duplicatie te produceren. Het idee is om een invoegset te genereren met 10.000 rijen genummerd '1', vervolgens 10.000 genummerd '2' ... enzovoort.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Helaas produceert de optimizer nog steeds een plan met een sortering:

Er valt hier niet veel te zeggen in de verdediging van de optimizer, dit is slechts een dwaas plan. Het heeft ervoor gekozen om 10.000 rijen te genereren en die vervolgens te kruisen met getallen van 1 tot 1000. Hierdoor kan de natuurlijke volgorde van de getallen niet worden behouden, dus de sortering kan niet worden vermeden.
De sortering vermijden – Eindelijk!
De strategie die de optimizer heeft gemist, is om de getallen 1…1000 eerst te nemen , en voeg elk nummer samen met 10.000 rijen (maak 10.000 kopieën van elk nummer in volgorde). Het verwachte plan zou een sortering vermijden door gebruik te maken van een geneste loops cross join die de volgorde behoudt van de rijen op de buitenste ingang.
We kunnen dit resultaat bereiken door de optimizer te dwingen toegang te krijgen tot de afgeleide tabellen in de volgorde die is gespecificeerd in de query, met behulp van de FORCE ORDER vraag hint:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Eindelijk krijgen we het plan dat we zochten:
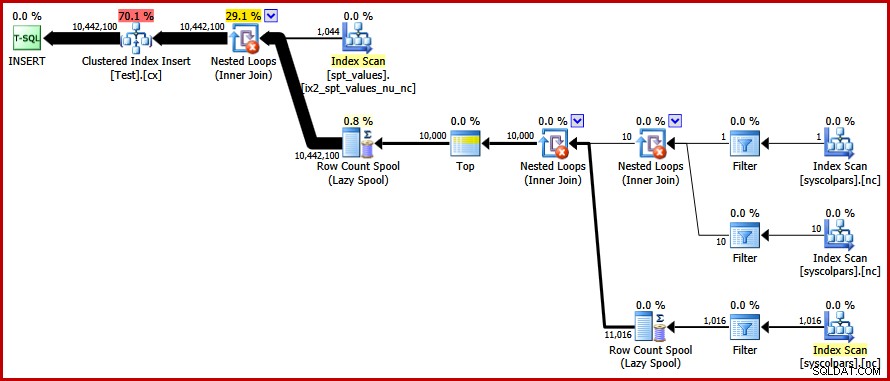
Dit plan vermijdt een expliciete sortering, terwijl toch "slechte" paginasplitsingen worden vermeden en minimaal gelogde invoegingen in de geclusterde index mogelijk zijn (ervan uitgaande dat de database de FULL niet gebruikt herstelmodel). Het laadt alle tien miljoen rijen in ongeveer 9 seconden op mijn laptop (met een enkele 7200 rpm SATA-spinschijf). Dit vertegenwoordigt een duidelijke efficiëntiewinst over de 30-50 seconden verstreken tijd vóór het herschrijven.
De verschillende waarden vinden
Nu we de voorbeeldgegevens hebben gemaakt, kunnen we onze aandacht richten op het schrijven van een query om de afzonderlijke waarden in de tabel te vinden. Een natuurlijke manier om deze vereiste in T-SQL uit te drukken is als volgt:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Het uitvoeringsplan is heel eenvoudig, zoals je zou verwachten:

Dit duurt ongeveer 2900 ms om op mijn computer te draaien, en vereist 43.406 logische leest:

De MAXDOP (1) verwijderen vraaghint genereert een parallel plan:

Dit is voltooid in ongeveer 1500 ms (maar met 8764 ms CPU-tijd verbruikt), en 43.804 logische leest:

Dezelfde plannen en hetzelfde resultaat als we GROUP BY . gebruiken in plaats van DISTINCT .
Een beter algoritme
De hierboven getoonde queryplannen lezen alle waarden uit de basistabel en verwerken deze via een Stream Aggregate. Als we de taak als geheel beschouwen, lijkt het inefficiënt om alle 10 miljoen rijen te scannen als we weten dat er relatief weinig verschillende waarden zijn.
Een betere strategie zou kunnen zijn om de enige laagste waarde in de tabel te vinden, dan de volgende hoogste te vinden, enzovoort, totdat we geen waarden meer hebben. Cruciaal is dat deze benadering zich leent voor singleton-zoeken in de index in plaats van elke rij te scannen.
We kunnen dit idee implementeren in een enkele query met behulp van een recursieve CTE, waarbij het ankergedeelte de laagste vindt onderscheidende waarde, dan vindt het recursieve deel de volgende onderscheidende waarde enzovoort. Een eerste poging om deze vraag te schrijven is:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Helaas compileert die syntaxis niet:

Ok, dus geaggregeerde functies zijn niet toegestaan. In plaats van MIN . te gebruiken , kunnen we dezelfde logica schrijven met TOP (1) met een ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Nog steeds geen vreugde.
Het blijkt dat we deze beperkingen kunnen omzeilen door het recursieve deel te herschrijven om de kandidaat-rijen in de vereiste volgorde te nummeren, en vervolgens te filteren op de rij met het nummer 'één'. Dit lijkt misschien een beetje omslachtig, maar de logica is precies hetzelfde:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Deze zoekopdracht doet compileren, en produceert het volgende post-uitvoeringsplan:

Let op de operator Top in het recursieve deel van het uitvoeringsplan (gemarkeerd). We kunnen geen T-SQL TOP schrijven in het recursieve deel van een recursieve algemene tabeluitdrukking, maar dat betekent niet dat de optimizer er geen kan gebruiken! De optimizer introduceert de Top op basis van redenering over het aantal rijen dat moet worden gecontroleerd om de rij met het nummer '1' te vinden.
De prestaties van dit (niet-parallelle) plan zijn veel beter dan de Stream Aggregate-aanpak. Het is voltooid in ongeveer 50 ms , met 3007 logische leest ten opzichte van de brontabel (en 6001 rijen gelezen uit de spoolwerktabel), vergeleken met de vorige beste van 1500ms (8764 ms CPU-tijd bij DOP 8) en 43.804 logische leest:


Conclusie
Het is niet altijd mogelijk om doorbraken in queryprestaties te bereiken door alleen afzonderlijke queryplanelementen te overwegen. Soms moeten we de strategie achter het hele uitvoeringsplan analyseren en dan lateraal denken om een efficiënter algoritme en een efficiëntere implementatie te vinden.