Verantwoordelijk zijn voor de prestaties van SQL Server kan een ontmoedigende taak zijn. Er zijn veel gebieden die we moeten controleren en begrijpen. Er wordt ook van ons verwacht dat we op de hoogte kunnen blijven van al die statistieken en te allen tijde weten wat er op onze servers gebeurt. Ik vraag DBA's graag waar ze als eerste aan denken als ze de uitdrukking "SQL Server afstemmen" horen; de overweldigende reactie die ik krijg is "query tuning". Ik ben het ermee eens dat het afstemmen van zoekopdrachten erg belangrijk is en een nooit eindigende taak is waarmee we worden geconfronteerd, omdat de werkbelasting voortdurend verandert.
Er zijn echter veel andere aspecten waarmee u rekening moet houden bij het nadenken over de prestaties van SQL Server. Er zijn veel instellingen op instantie-, besturingssysteem- en databaseniveau die moeten worden aangepast vanuit de standaardinstellingen. Als consultant kan ik in veel verschillende bedrijfstakken werken en word ik blootgesteld aan allerlei prestatieproblemen. Wanneer ik met een nieuwe client werk, probeer ik altijd een gezondheidsaudit van de server uit te voeren om te weten waar ik mee te maken heb. Tijdens het uitvoeren van deze audits was een van de dingen die ik herhaaldelijk heb gevonden, buitensporige lees- en schrijflatenties op de schijven waar SQL Server-gegevens en logbestanden zich bevinden.
Lees-/schrijflatentie
Om uw schijflatenties in SQL Server te bekijken, kunt u snel en eenvoudig de DMV sys.dm_io_virtual_file_stats opvragen . Deze DMV accepteert twee parameters:database_id en file_id . Wat geweldig is, is dat je NULL kunt doorgeven as beide waarden en retourneert de latenties voor alle bestanden voor alle databases. De uitvoerkolommen omvatten:
- database_id
- file_id
- sample_ms
- aantal_of_reads
- num_of_bytes_read
- io_stall_read_ms
- aantal_of_writes
- aantal_of_bytes_geschreven
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
Zoals je kunt zien in de kolomlijst, is er echt nuttige informatie die deze DMV ophaalt, maar je hoeft alleen maar SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); uit te voeren. helpt niet veel, tenzij je je database_ids hebt onthouden en wat wiskunde in je hoofd kunt doen.
Wanneer ik de bestandsstatistieken opvraag, gebruik ik een query uit de blogpost van Paul Randal, "Hoe IO-subsysteemlatenties onderzoeken vanuit SQL Server." Dit script maakt de kolomnamen gemakkelijker leesbaar, inclusief het station waarop het bestand zich bevindt, de databasenaam en het pad naar het bestand.
Door deze DMV op te vragen, kunt u gemakkelijk zien waar de I/O-hotspots voor uw bestanden zijn. U kunt zien waar de hoogste schrijf- en leeslatenties zijn en welke databases de boosdoeners zijn. Als u dit weet, kunt u gaan kijken naar de afstemmingsmogelijkheden voor die specifieke databases. Dit kan indexafstemming omvatten, controleren of de bufferpool onder geheugendruk staat, mogelijk de database verplaatsen naar een sneller deel van het I/O-subsysteem, of mogelijk de database partitioneren en de bestandsgroepen over andere LUN's verspreiden.
Dus je voert de query uit en deze retourneert veel waarden in ms voor latentie - welke waarden zijn goed en welke slecht?
Welke waarden zijn goed of slecht?
Als je het SQLskills vraagt, zullen we je iets vertellen in de trant van:
- Uitstekend:<1ms
- Zeer goed:<5ms
- Goed:5 – 10 ms
- Slecht:10 – 20ms
- Slecht:20 – 100 ms
- Heel erg:100 – 500ms
- OMG!:> 500 ms
Als u een Bing-zoekopdracht uitvoert, vindt u artikelen van Microsoft met aanbevelingen die vergelijkbaar zijn met:
- Goed:<10 ms
- Ok:10 – 20 ms
- Slecht:20 – 50 ms
- Ernstig slecht:> 50 ms
Zoals je kunt zien, zijn er enkele kleine variaties in de cijfers, maar de consensus is dat alles boven de 20ms als lastig kan worden beschouwd. Dat gezegd hebbende, kan uw gemiddelde schrijflatentie 20 ms zijn en dat is 100% acceptabel voor uw organisatie en dat is oké. U moet de algemene I/O-latenties voor uw systeem kennen, zodat u weet wat normaal is als het misgaat.
Mijn lees-/schrijflatenties zijn slecht, wat moet ik doen?
Als u merkt dat de lees- en schrijflatenties slecht zijn op uw server, zijn er verschillende plaatsen waar u naar problemen kunt zoeken. Dit is geen uitgebreide lijst, maar een leidraad voor waar te beginnen.
- Analyseer uw werklast. Is uw indexeringsstrategie correct? Het niet hebben van de juiste indexen zal ertoe leiden dat veel meer gegevens van de schijf worden gelezen. Scant in plaats van zoekt.
- Zijn uw statistieken up-to-date? Slechte statistieken kunnen leiden tot slechte keuzes voor uitvoeringsplannen.
- Heeft u problemen met het snuiven van parameters die slechte uitvoeringsplannen veroorzaken?
- Staat de bufferpool onder geheugendruk, bijvoorbeeld door een opgeblazen plancache?
- Netwerkproblemen? Functioneert uw SAN-fabric correct? Laat uw opslagtechnicus het pad en het netwerk valideren.
- Verplaats de hotspots naar verschillende opslagarrays. In sommige gevallen kan het een enkele database zijn of slechts enkele databases die alle problemen veroorzaken. Isoleren naar een andere set schijven of snellere high-end schijven zoals SSD's kan de beste logische oplossing zijn.
- Kun je de database partitioneren om lastige tabellen naar een andere schijf te verplaatsen om de belasting te spreiden?
Wachtstatistieken
Net als het monitoren van uw bestandsstatistieken, kan het monitoren van uw wachtstatistieken u veel vertellen over knelpunten in uw omgeving. We hebben het geluk dat we weer een geweldige DMV hebben (sys.dm_os_wait_stats ) die we kunnen opvragen die alle beschikbare wachtinformatie zal ophalen die is verzameld sinds de laatste herstart of sinds de laatste keer dat de wachttijden opnieuw werden ingesteld; er zijn ook wachttijden met betrekking tot schijfprestaties. Deze DMV zal belangrijke informatie retourneren, waaronder:
- wait_type
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
Het opvragen van deze DMV op mijn SQL Server 2014-machine leverde 771 wachttypen op. SQL Server wacht altijd ergens op, maar er zijn veel wachttijden waar we ons geen zorgen over moeten maken. Om deze reden gebruik ik een andere vraag van Paul Randal; zijn blogpost, "Wachtstatistieken, of vertel me alsjeblieft waar het pijn doet", heeft een uitstekend script dat een aantal wachttijden uitsluit waar we niet echt om geven. Paul somt ook veel van de veelvoorkomende problematische wachttijden op en biedt begeleiding voor de veelvoorkomende wachttijden.
Waarom zijn wachtstatistieken belangrijk?
Monitoring voor hoge wachttijden voor bepaalde evenementen zal u vertellen wanneer er problemen aan de hand zijn. Je hebt een basislijn nodig om te weten wat normaal is en wanneer dingen een drempel of pijnniveau overschrijden. Als u een erg hoge PAGEIOLATCH_XX . heeft dan weet u dat SQL Server moet wachten tot een gegevenspagina van schijf wordt gelezen. Dit kan schijf, geheugen, wijziging van de werkbelasting of een aantal andere problemen zijn.
Een recente klant met wie ik werkte, zag zeer ongewoon gedrag. Toen ik verbinding maakte met de databaseserver en de server onder een werkbelasting kon observeren, begon ik onmiddellijk met het controleren van bestandsstatistieken, wachtstatistieken, geheugengebruik, tempdb-gebruik, enz. Een ding dat meteen opviel was WRITELOG wachten is het meest voorkomend. Ik weet dat dit wachten te maken heeft met een log flush naar schijf en deed me denken aan Paul's serie over Trimming the Transaction Log Fat. Hoge WRITELOG wachttijden kunnen meestal worden geïdentificeerd door hoge schrijfvertragingen voor het transactielogboekbestand. Dus gebruikte ik mijn script voor bestandsstatistieken om de lees- en schrijflatenties op de schijf te bekijken. Ik kon toen een hoge schrijflatentie zien in het gegevensbestand, maar niet in mijn logbestand. Bij het bekijken van de WRITELOG het was een hoge wachttijd, maar de wachttijd in ms was extreem laag. Maar iets in de tweede post van Paul's serie zat nog steeds in mijn hoofd. Ik zou naar de automatische groei-instellingen voor de database moeten kijken om "Dood door duizend sneden" uit te sluiten. Toen ik naar de database-eigenschappen van de database keek, zag ik dat het gegevensbestand was ingesteld om automatisch te groeien met 1 MB en dat het transactielogboek was ingesteld om automatisch met 10% te groeien. Beide bestanden hadden bijna 0 ongebruikte ruimte. Ik deelde met de klant wat ik vond en hoe dit hun prestaties verwoestte. We hebben snel de juiste wijziging aangebracht en het testen ging vooruit, veel beter trouwens. Helaas is dit niet de enige keer dat ik dit exacte probleem ben tegengekomen. Een andere keer dat een database 66 GB groot was, groeide hij met 1 MB.
Uw gegevens vastleggen
Veel dataprofessionals hebben processen gecreëerd om regelmatig bestands- en wachtstatistieken vast te leggen voor analyse. Aangezien de wachtstatistieken cumulatief zijn, wilt u ze vastleggen en de delta's vergelijken tussen verschillende tijdstippen van de dag of voor en na het uitvoeren van bepaalde processen. Dit is niet al te ingewikkeld en er zijn talloze blogposts beschikbaar waarin mensen vertellen hoe ze dit hebben bereikt. Het belangrijkste is om deze gegevens te meten, zodat u ze kunt controleren. Hoe weet u vandaag dat het beter of slechter gaat op uw databaseserver, tenzij u de gegevens van gisteren kent?
Hoe kan SQL Sentry helpen?
Ik ben blij dat je het vraagt! SQL Sentry Performance Advisor brengt latentie en wachttijden centraal op het dashboard. Eventuele afwijkingen zijn gemakkelijk te herkennen; u kunt overschakelen naar de historische modus en de vorige trend bekijken en die ook vergelijken met eerdere perioden. Dit kan van onschatbare waarde blijken te zijn bij het analyseren van die "wat is er gebeurd?" momenten. Iedereen heeft die oproep gekregen:"Gisteren rond 15:00 uur leek het systeem gewoon te bevriezen, kunt u ons vertellen wat er is gebeurd?" Natuurlijk, laat me Profiler tevoorschijn halen en teruggaan in de tijd. Als u een monitoringtool zoals Performance Advisor heeft, heeft u die historische informatie binnen handbereik.
Naast de grafieken en grafieken op het dashboard, hebt u de mogelijkheid om ingebouwde waarschuwingen te gebruiken voor omstandigheden zoals hoge schijfwachttijden, hoge VLF-tellingen, hoge CPU, lage levensverwachting van pagina's en nog veel meer. Je hebt ook de mogelijkheid om je eigen aangepaste voorwaarden te creëren, en je kunt leren van de voorbeelden op de SQL Sentry-site of via de Condition Exchange (Aaron Bertrand heeft hierover geblogd). Ik heb de waarschuwende kant hiervan aangestipt in mijn laatste artikel over SQL Server Agent Alerts.
Op het tabblad Schijfruimte van Performance Advisor is het heel gemakkelijk om zaken als autogrowth-instellingen en hoge VLF-tellingen te zien. U zou het moeten weten, maar voor het geval u dat niet doet, is autogrowth met 1 MB of 10% niet de beste instelling. Als u deze waarden ziet (Performance Advisor markeert ze voor u), kunt u snel notities maken en de tijd plannen om de juiste aanpassingen te maken. Ik vind het geweldig hoe het ook Total VLF's weergeeft; te veel VLF's kunnen zeer problematisch zijn. Lees Kimberly's post "Transaction Log VLF's - too much or too few?" als je dat nog niet hebt gedaan.
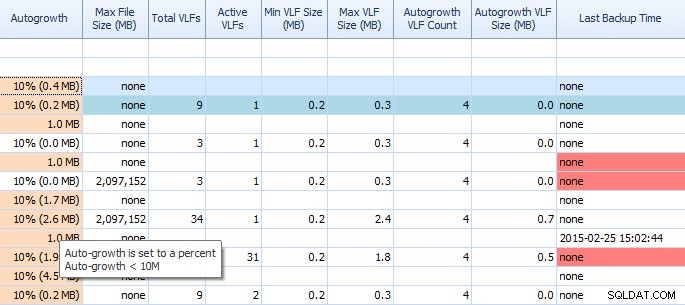 Gedeeltelijk raster op het tabblad Schijfruimte van Performance Advisor
Gedeeltelijk raster op het tabblad Schijfruimte van Performance Advisor
Een andere manier waarop Performance Advisor kan helpen, is via de gepatenteerde Disk Activity-module. Hier kun je zien dat tempdb op F:een aanzienlijke schrijflatentie ervaart; u kunt dit zien aan de dikke rode lijnen onder de schijfafbeeldingen. Het is je misschien ook opgevallen dat F:de enige stationsletter is waarvan de schijf rood is weergegeven; dit is een visuele aanwijzing dat de schijf een verkeerd uitgelijnde partitie heeft, wat kan bijdragen aan I/O-problemen.
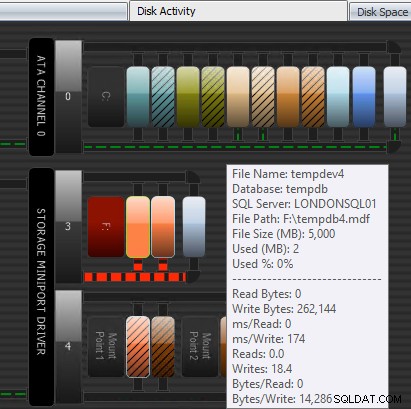 Performance Advisor Disk Activity-module
Performance Advisor Disk Activity-module
En u kunt deze informatie in de onderstaande rasters met elkaar in verband brengen – problemen worden ook daar gemarkeerd in de rasters, en bekijk de ms/Write kolom:
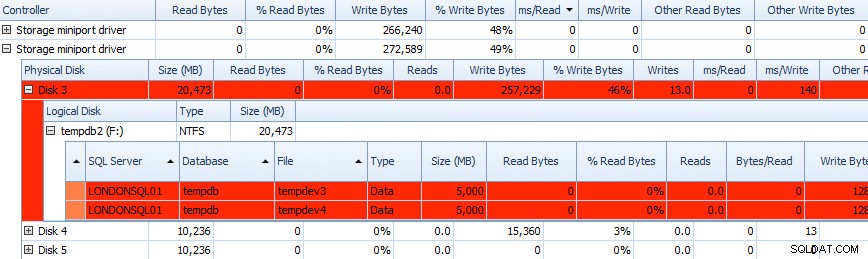 Gedeeltelijk raster van gegevens over schijfactiviteit van Performance Advisor
Gedeeltelijk raster van gegevens over schijfactiviteit van Performance Advisor
U kunt deze informatie ook met terugwerkende kracht inzien; als iemand gistermiddag of afgelopen dinsdag klaagt over een waargenomen schijfknelpunt, kun je gewoon teruggaan met de datumkiezers in de werkbalk en de gemiddelde doorvoer en latentie voor elk bereik bekijken. Zie de Gebruikershandleiding voor meer informatie over de module Schijfactiviteit.
Performance Advisor heeft ook veel ingebouwde rapporten onder de categorieën Performance, Blocking, Top SQL, Disk/File Space en Deadlocks. In de onderstaande afbeelding ziet u hoe u bij de rapporten Schijf/Bestandsruimte komt. Het is erg waardevol om de rapporten slechts een paar muisklikken verwijderd te hebben om er meteen in te kunnen graven en te zien wat er op uw server gebeurt (of was).
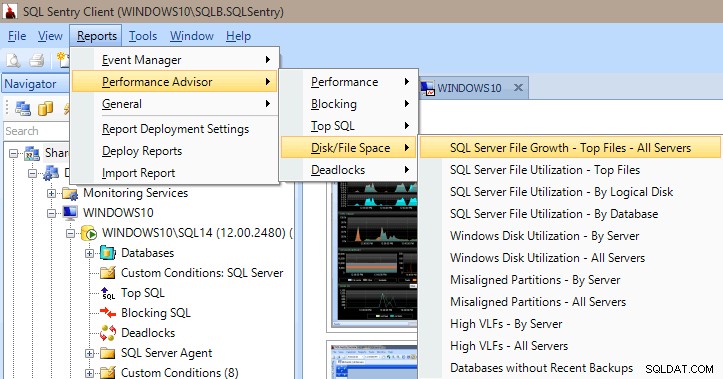 Performance Advisor-rapporten
Performance Advisor-rapporten
Samenvatting
De belangrijke conclusie van dit bericht is om uw prestatiestatistieken te kennen. Een veelgehoorde uitspraak onder dataprofessionals is dat schijf onze #1 bottleneck is. Als u de bestandsstatistieken van uw server kent, helpt dit om de pijnpunten op uw server te begrijpen. In combinatie met bestandsstatistieken zijn uw wachtstatistieken ook een geweldige plek om te kijken. Veel mensen, waaronder ikzelf, beginnen daar. Het hebben van een tool als SQL Sentry Performance Advisor kan je enorm helpen bij het oplossen van problemen en het vinden van prestatieproblemen voordat ze te problematisch worden; Als u echter niet over zo'n tool beschikt, moet u vertrouwd raken met sys.dm_os_wait_stats en sys.dm_io_virtual_file_stats zal u goed van pas komen om te beginnen met het afstemmen van uw server.