
Het is die dinsdag van de maand – je weet wel, die ene waarop het blogger block-feest, bekend als T-SQL Tuesday, plaatsvindt. Deze maand wordt het gehost door Russ Thomas (@SQLJudo), en het onderwerp is, "Calling All Tuners and Gear Heads." Ik ga hier een prestatiegerelateerd probleem behandelen, hoewel mijn excuses dat het misschien niet volledig in overeenstemming is met de richtlijnen die Russ in zijn uitnodiging heeft uiteengezet (ik ga geen hints, traceervlaggen of planhandleidingen gebruiken) .
Bij SQLBits vorige week gaf ik een presentatie over triggers, en mijn goede vriend en mede-MVP Erland Sommarskog was toevallig aanwezig. Op een gegeven moment stelde ik voor dat je, voordat je een nieuwe trigger op een tafel maakt, moet controleren of er al triggers bestaan, en overwegen om de logica te combineren in plaats van een extra trigger toe te voegen. Mijn redenen waren voornamelijk voor de onderhoudbaarheid van de code, maar ook voor de prestaties. Erland vroeg of ik ooit had getest of er extra overhead was als meerdere triggers voor dezelfde actie werden geactiveerd, en ik moest toegeven dat, nee, ik had niets uitgebreids gedaan. Dus dat ga ik nu doen.
In AdventureWorks2014 heb ik een eenvoudige set tabellen gemaakt die in feite sys.all_objects vertegenwoordigen (~ 2.700 rijen) en sys.all_columns (~ 9.500 rijen). Ik wilde het effect meten op de werklast van verschillende benaderingen voor het bijwerken van beide tabellen - in wezen heb je gebruikers die de kolommentabel bijwerken en je gebruikt een trigger om een andere kolom in dezelfde tabel en een paar kolommen in de objectentabel bij te werken.
- T1:basislijn :Stel dat u alle gegevenstoegang kunt regelen via een opgeslagen procedure; in dit geval kunnen de updates voor beide tabellen direct worden uitgevoerd, zonder dat er triggers nodig zijn. (Dit is niet praktisch in de echte wereld, omdat je directe toegang tot de tabellen niet op betrouwbare wijze kunt verbieden.)
- T2:enkele trigger tegen andere tafel :Stel dat u de update-instructie voor de betreffende tabel kunt beheren en andere kolommen kunt toevoegen, maar de updates voor de secundaire tabel moeten worden geïmplementeerd met een trigger. We werken alle drie de kolommen bij met één verklaring.
- T3:enkele trigger voor beide tafels :In dit geval hebben we een trigger met twee instructies, een die de andere kolom in de betreffende tabel bijwerkt en een die alle drie de kolommen in de secundaire tabel bijwerkt.
- T4:enkele trigger voor beide tafels :Net als T3, maar deze keer hebben we een trigger met vier instructies, een die de andere kolom in de betreffende tabel bijwerkt en een instructie voor elke kolom die is bijgewerkt in de secundaire tabel. Dit kan de manier zijn waarop het wordt afgehandeld als de vereisten in de loop van de tijd worden toegevoegd en een afzonderlijke verklaring als veiliger wordt beschouwd in termen van regressietesten.
- T5:twee triggers :Eén trigger werkt alleen de betreffende tabel bij; de andere gebruikt een enkele instructie om de drie kolommen in de secundaire tabel bij te werken. Dit kan de manier zijn waarop het wordt gedaan als de andere triggers niet worden opgemerkt of als het wijzigen ervan verboden is.
- T6:vier triggers :Eén trigger werkt alleen de betreffende tabel bij; de andere drie werken elke kolom in de secundaire tabel bij. Nogmaals, dit kan de manier zijn waarop het wordt gedaan als je niet weet dat de andere triggers bestaan, of als je bang bent om de andere triggers aan te raken vanwege regressieproblemen.
Dit zijn de brongegevens waarmee we te maken hebben:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Nu gaan we voor elk van de 6 tests onze updates 1000 keer uitvoeren en de tijdsduur meten
T1:basislijn
Dit is het scenario waarin we het geluk hebben om triggers te vermijden (wederom, niet erg realistisch). In dit geval meten we de uitlezingen en duur van deze batch. Ik plaats /*real*/ in de querytekst, zodat ik eenvoudig de statistieken voor alleen deze verklaringen kan trekken, en niet alle verklaringen van binnen de triggers, omdat uiteindelijk de statistieken oprollen naar de verklaringen die de triggers oproepen. Houd er ook rekening mee dat de daadwerkelijke updates die ik aan het maken ben niet echt logisch zijn, dus negeer dat ik de sortering instel op de naam van de server / instantie en de principal_id van het object naar de session_id . van de huidige sessie .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:enkele trigger
Hiervoor hebben we de volgende eenvoudige trigger nodig, die alleen dbo.src . bijwerkt :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Dan hoeft onze batch alleen de twee kolommen in de primaire tabel bij te werken:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:enkele trigger tegen beide tafels
Voor deze test ziet onze trigger er als volgt uit:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO En nu hoeft de batch die we testen alleen de originele kolom in de primaire tabel bij te werken; de andere wordt afgehandeld door de trigger:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:enkele trigger tegen beide tafels
Dit is net als T3, maar nu heeft de trigger vier statements:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO De testbatch is ongewijzigd:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:Twee triggers
Hier hebben we één trigger om de primaire tabel bij te werken en één trigger om de secundaire tabel bij te werken:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO De testbatch is weer erg basic:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:vier triggers
Deze keer hebben we een trigger voor elke kolom die wordt beïnvloed; één in de primaire tabel en drie in de secundaire tabellen.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO En de testbatch:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
De impact van de werkdruk meten
Ten slotte schreef ik een eenvoudige query tegen sys.dm_exec_query_stats meetwaarden en duur voor elke test meten:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Resultaten
Ik heb de tests 10 keer uitgevoerd, de resultaten verzameld en alles gemiddeld. Hier is hoe het kapot ging:
| Test/Batch | Gemiddelde duur (microseconden) | Totaal aantal gelezen (8K pagina's) |
|---|---|---|
| T1 :UPDATE /*real*/ dbo.tr1 … | 22.608 | 205.134 |
| T2 :UPDATE /*real*/ dbo.tr2 … | 32.749 | 11.331.628 |
| T3 :UPDATE /*real*/ dbo.tr3 … | 72.899 | 22.838.308 |
| T4 :UPDATE /*real*/ dbo.tr4 … | 78,372 | 44.463.275 |
| T5 :UPDATE /*real*/ dbo.tr5 … | 88,563 | 41.514.778 |
| T6 :UPDATE /*real*/ dbo.tr6 … | 127.079 | 100.330.753 |
En hier is een grafische weergave van de duur:
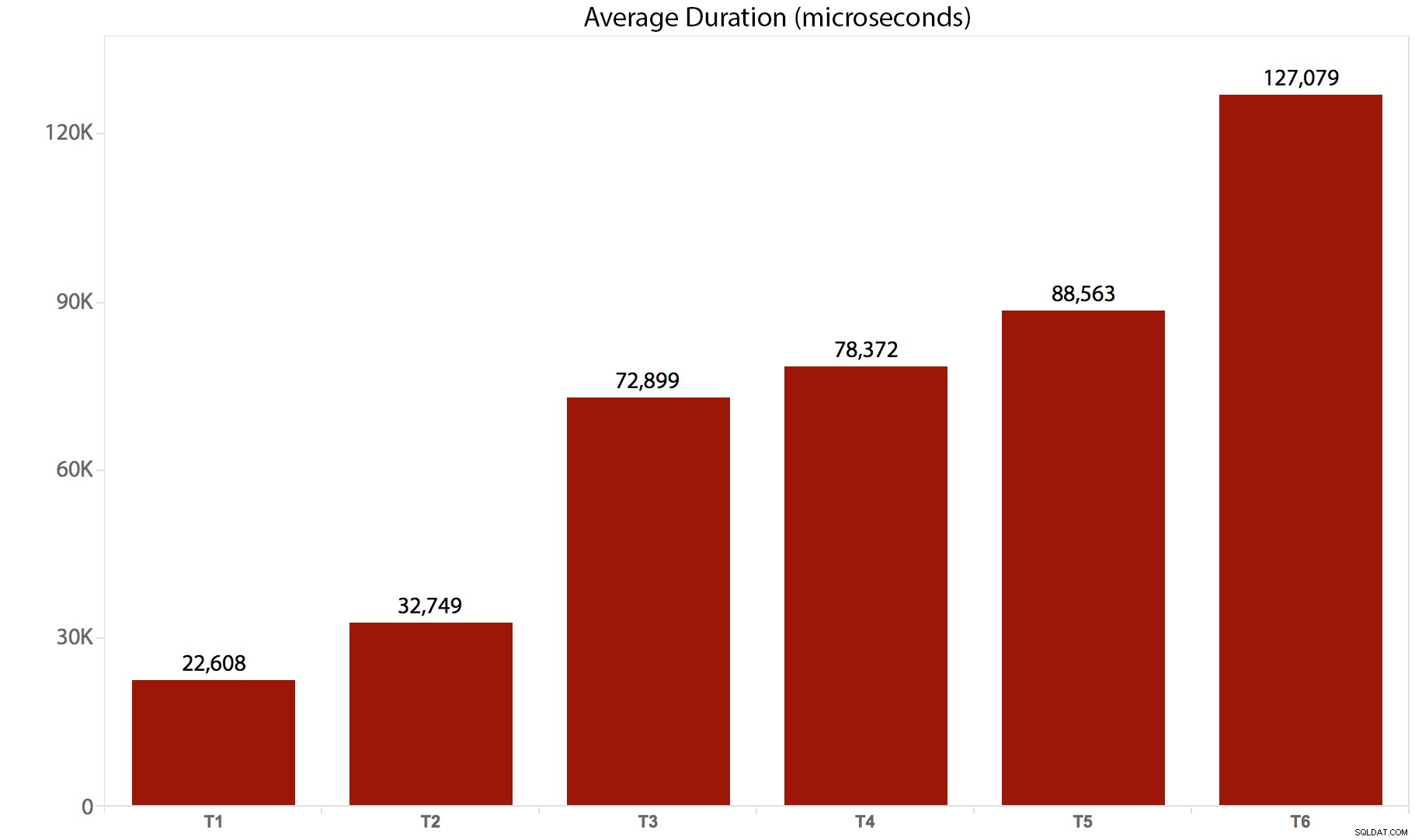
Conclusie
Het is duidelijk dat er in dit geval een aanzienlijke overhead is voor elke trigger die wordt aangeroepen - al deze batches hadden uiteindelijk invloed op hetzelfde aantal rijen, maar in sommige gevallen werden dezelfde rijen meerdere keren aangeraakt. Ik zal waarschijnlijk verdere vervolgtesten uitvoeren om het verschil te meten wanneer dezelfde rij nooit meer dan één keer wordt aangeraakt - een ingewikkelder schema misschien, waarbij elke keer 5 of 10 andere tabellen moeten worden aangeraakt, en deze verschillende uitspraken kunnen worden in een enkele trigger of in meerdere. Ik vermoed dat de overheadverschillen meer worden veroorzaakt door zaken als gelijktijdigheid en het aantal getroffen rijen dan door de overhead van de trigger zelf, maar we zullen zien.
Zelf de demo proberen? Download het script hier.