In afwijking van mijn serie 'knee-jerk performance tuning', wil ik graag bespreken hoe indexfragmentatie u onder bepaalde omstandigheden kan besluipen.
Wat is indexfragmentatie?
De meeste mensen beschouwen 'indexfragmentatie' als het probleem waarbij de indexbladpagina's niet in orde zijn - de indexbladpagina met de volgende sleutelwaarde is niet degene die fysiek aangrenzend is in het gegevensbestand aan de indexbladpagina die momenteel wordt onderzocht . Dit wordt logische fragmentatie genoemd (en sommige mensen noemen het externe fragmentatie - een verwarrende term waar ik niet van houd).
Logische fragmentatie vindt plaats wanneer een indexbladpagina vol is en er ruimte nodig is, hetzij voor een invoeging, hetzij om een bestaand record langer te maken (door een kolom met variabele lengte bij te werken). In dat geval maakt de Storage Engine een nieuwe, lege pagina aan en verplaatst 50% van de rijen (meestal, maar niet altijd) van de volledige pagina naar de nieuwe pagina. Deze bewerking creëert ruimte op beide pagina's, waardoor het invoegen of bijwerken kan doorgaan, en wordt een paginasplitsing genoemd. Er zijn interessante pathologische gevallen met herhaalde paginasplitsingen van een enkele bewerking en paginasplitsingen die de indexniveaus trapsgewijs verhogen, maar deze vallen buiten het bestek van dit bericht.
Wanneer een pagina wordt gesplitst, veroorzaakt dit meestal logische fragmentatie, omdat het zeer onwaarschijnlijk is dat de nieuwe pagina die is toegewezen fysiek aansluit op de pagina die wordt gesplitst. Wanneer een index veel logische fragmentatie heeft, worden indexscans vertraagd omdat het fysiek lezen van de benodigde pagina's niet zo efficiënt kan worden gedaan (met behulp van 'readahead'-lezingen van meerdere pagina's) wanneer de bladpagina's niet op volgorde in het gegevensbestand worden opgeslagen .
Dat is de basisdefinitie van indexfragmentatie, maar er is een tweede soort indexfragmentatie waar de meeste mensen geen rekening mee houden:lage paginadichtheid (ook wel interne fragmentatie genoemd, nogmaals, een verwarrende term waar ik niet van houd).
Paginadichtheid is een maat voor hoeveel gegevens er op een indexbladpagina zijn opgeslagen. Wanneer een paginasplitsing plaatsvindt met de gebruikelijke 50/50-kast, blijft elke bladpagina (de gesplitste en de nieuwe) achter met een paginadichtheid van slechts 50%. Hoe lager de paginadichtheid, hoe meer lege ruimte er in de index is en hoe meer schijfruimte en bufferpoolgeheugen u als verspild kunt beschouwen. Ik heb een paar jaar geleden over dit probleem geblogd en je kunt het hier lezen.
Nu ik een basisdefinitie heb gegeven van de twee soorten indexfragmentatie, ga ik ze samen simpelweg 'fragmentatie' noemen.
Voor de rest van dit bericht wil ik drie gevallen bespreken waarin geclusterde indexen gefragmenteerd kunnen raken, zelfs als u bewerkingen vermijdt die duidelijk fragmentatie zouden veroorzaken (d.w.z. willekeurige invoegingen en het bijwerken van records zou langer zijn).
Fragmentatie van verwijderde items
"Hoe kan een verwijdering van een geclusterde indexbladpagina een paginasplitsing veroorzaken?" vraag je je misschien af. Onder normale omstandigheden niet (en ik zat er een paar minuten over na te denken om er zeker van te zijn dat er geen vreemd pathologisch geval was! Maar zie de sectie hieronder...) Verwijderingen kunnen er echter voor zorgen dat de paginadichtheid steeds lager wordt.
Stel je het geval voor waarbij de geclusterde index een bigint-identiteitssleutelwaarde heeft, zodat invoegingen altijd naar de rechterkant van de index gaan en nooit, maar dan ook nooit in een eerder deel van de index worden ingevoegd (tenzij iemand de identiteitswaarde opnieuw instelt - potentieel zeer problematisch!). Stel je nu voor dat de werkbelasting records uit de tabel verwijdert die niet langer nodig zijn, waarna de taak voor het opschonen van achtergronden de ruimte op de pagina terugwint en het vrije ruimte wordt.
Bij afwezigheid van willekeurige invoegingen (onmogelijk in ons scenario, tenzij iemand de identiteit opnieuw invult of een sleutelwaarde opgeeft die moet worden gebruikt na het inschakelen van SET IDENTITY INSERT voor de tabel), zullen geen nieuwe records ooit de ruimte gebruiken die is vrijgemaakt van de verwijderde records. Dit betekent dat de gemiddelde paginadichtheid van de eerdere delen van de geclusterde index gestaag zal afnemen, wat leidt tot een toenemende hoeveelheid verspilde schijfruimte en bufferpoolgeheugen, zoals ik eerder heb beschreven.
Verwijderingen kunnen fragmentatie veroorzaken, zolang u paginadichtheid als onderdeel van 'fragmentatie' beschouwt.
Fragmentatie van momentopname-isolatie
SQL Server 2005 heeft twee nieuwe isolatieniveaus geïntroduceerd:snapshot-isolatie en read-committed snapshot-isolatie. Deze twee hebben een iets andere semantiek, maar laten in feite query's toe om een point-in-time weergave van een database te zien, en voor lock-collision-free selects. Dat is een enorme vereenvoudiging, maar het is genoeg voor mijn doeleinden.
Om deze isolatieniveaus te vergemakkelijken, implementeerde het ontwikkelteam bij Microsoft dat ik leidde een mechanisme genaamd versiebeheer. De manier waarop versiebeheer werkt, is dat wanneer een record verandert, de pre-change-versie van het record wordt gekopieerd naar de versieopslag in tempdb, en de gewijzigde opgenomen versie krijgt een 14-byte versietag toegevoegd aan het einde ervan. De tag bevat een verwijzing naar de vorige versie van het record, plus een tijdstempel dat kan worden gebruikt om te bepalen wat de juiste versie van een record is voor een bepaalde query om te lezen. Nogmaals, enorm vereenvoudigd, maar het is alleen de toevoeging van de 14-bytes waarin we geïnteresseerd zijn.
Dus wanneer een record verandert wanneer een van deze isolatieniveaus van kracht is, kan het met 14 bytes worden uitgebreid als er nog geen versietag voor het record is. Wat als er niet genoeg ruimte is voor de extra 14 bytes op de indexbladpagina? Dat klopt, er zal een paginasplitsing plaatsvinden, waardoor fragmentatie ontstaat.
Big deal, zou je denken, omdat het record toch verandert, dus als het toch van formaat zou veranderen, zou er waarschijnlijk een paginasplitsing zijn opgetreden. Nee - die logica geldt alleen als de recordwijziging de grootte van een kolom met variabele lengte zou vergroten. Er wordt een versietag toegevoegd, zelfs als een kolom met een vaste lengte wordt bijgewerkt!
Dat klopt - wanneer versiebeheer in het spel is, kunnen updates van kolommen met een vaste lengte ervoor zorgen dat een record wordt uitgebreid, wat mogelijk kan leiden tot paginasplitsing en fragmentatie. Wat nog interessanter is, is dat een verwijdering ook de 14-byte-tag zal toevoegen, dus een verwijdering in een geclusterde index kan een paginasplitsing veroorzaken wanneer versiebeheer in gebruik is!
Het komt erop neer dat het inschakelen van beide vormen van snapshot-isolatie ertoe kan leiden dat fragmentatie plotseling optreedt in geclusterde indexen waar voorheen geen mogelijkheid tot fragmentatie was.
Fragmentatie van leesbare secundairen
Het laatste geval dat ik wil bespreken, is het gebruik van leesbare secundairen, onderdeel van de beschikbaarheidsgroepfunctie die is toegevoegd in SQL Server 2012.
Wanneer u een leesbare secundaire inschakelt, worden alle query's die u uitvoert op de secundaire replica geconverteerd naar het gebruik van snapshot-isolatie onder de dekmantel. Dit voorkomt dat de query's het constant opnieuw afspelen van logrecords van de primaire replica blokkeren, omdat de herstelcode vergrendelingen krijgt terwijl het verder gaat.
Om dit te doen, moeten er 14-byte versietags op records op de secundaire replica staan. Er is een probleem, omdat alle replica's identiek moeten zijn, zodat de log-replay werkt. Nou, niet helemaal. De inhoud van de versie-tag is niet relevant omdat ze alleen worden gebruikt op de instantie die ze heeft gemaakt. Maar de secundaire replica kan geen versietags toevoegen, waardoor records langer worden, omdat dat de fysieke lay-out van records op een pagina zou veranderen en het opnieuw afspelen van logboeken zou verbreken. Als de versietags er al waren, zou het de ruimte kunnen gebruiken zonder iets te breken.
Dus dat is precies wat er gebeurt. De Storage Engine zorgt ervoor dat alle benodigde versie-tags voor de secundaire replica al aanwezig zijn door ze toe te voegen aan de primaire replica!
Zodra een leesbare secundaire replica van een database is gemaakt, zorgt elke update van een record in de primaire replica ervoor dat aan het record een lege tag van 14 bytes wordt toegevoegd, zodat de 14 bytes correct worden verantwoord in alle logboekrecords . De tag wordt nergens voor gebruikt (tenzij snapshot-isolatie is ingeschakeld op de primaire replica zelf), maar het feit dat deze is gemaakt, zorgt ervoor dat de record wordt uitgevouwen en als de pagina al vol is, dan...
Ja, het inschakelen van een leesbare secundaire heeft hetzelfde effect op de primaire replica als wanneer u snapshot-isolatie erop heeft ingeschakeld:fragmentatie.
Samenvatting
Denk niet dat, omdat u het gebruik van GUID's als clustersleutels en het bijwerken van kolommen met variabele lengte in uw tabellen vermijdt, uw geclusterde indexen immuun zijn voor fragmentatie. Zoals ik hierboven heb beschreven, zijn er andere werklast en omgevingsfactoren die fragmentatieproblemen in uw geclusterde indexen kunnen veroorzaken, waar u rekening mee moet houden.
Schrik nu niet en denk dat u geen records moet verwijderen, geen snapshot-isolatie moet gebruiken en geen leesbare secondaries moet gebruiken. Je moet je er alleen van bewust zijn dat ze allemaal fragmentatie kunnen veroorzaken en weten hoe je deze kunt detecteren, verwijderen en verminderen.
SQL Sentry heeft een coole tool, Fragmentation Manager, die u kunt gebruiken als een add-on voor Performance Advisor om erachter te komen waar fragmentatieproblemen zich bevinden en deze vervolgens aan te pakken. U zult misschien verbaasd zijn over de fragmentatie die u aantreft wanneer u controleert! Als een snel voorbeeld kan ik hier visueel zien - tot op het individuele partitieniveau - hoeveel fragmentatie er bestaat, hoe snel het zo is gekomen, eventuele bestaande patronen en de daadwerkelijke impact die het heeft op verspild geheugen in het systeem:
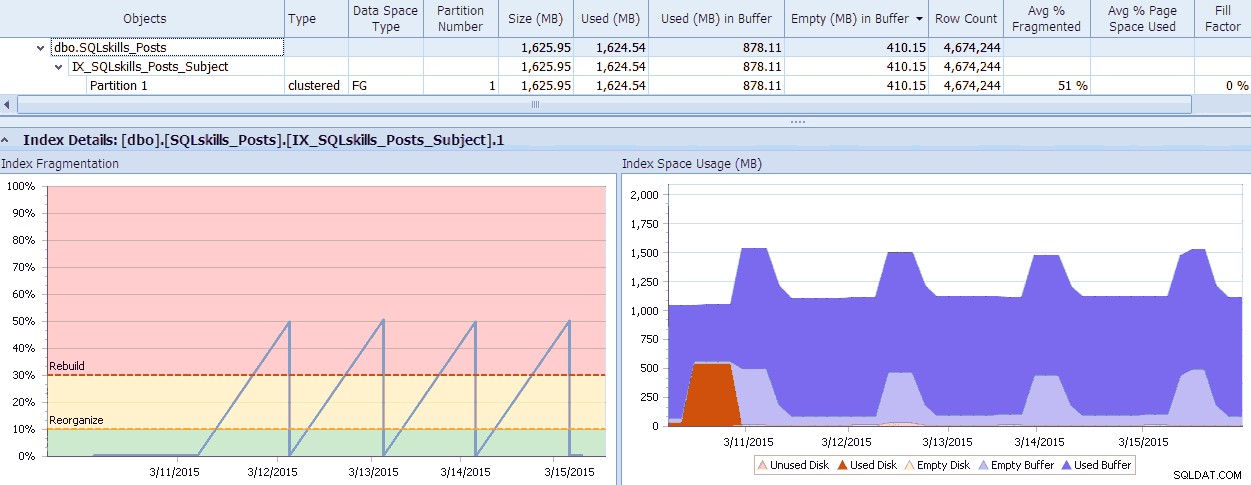 SQL Sentry Fragmentation Manager-gegevens (klik om te vergroten)
SQL Sentry Fragmentation Manager-gegevens (klik om te vergroten)
In mijn volgende bericht zal ik meer bespreken over fragmentatie en hoe je het kunt verminderen om het minder problematisch te maken.