Hoewel ze gepaard gaan met veel beperkingen en enkele belangrijke kanttekeningen bij de implementatie, zijn geïndexeerde weergaven nog steeds een zeer krachtige SQL Server-functie wanneer ze correct worden gebruikt in de juiste omstandigheden. Een veelvoorkomend gebruik is om een vooraf geaggregeerde weergave van onderliggende gegevens te bieden, zodat gebruikers de resultaten rechtstreeks kunnen opvragen zonder de kosten van het verwerken van de onderliggende joins, filters en aggregaties telkens wanneer een query wordt uitgevoerd.
Hoewel nieuwe Enterprise Edition-functies zoals opslag in kolommen en verwerking in batchmodus de prestatiekenmerken van veel grote zoekopdrachten van dit type hebben getransformeerd, is er nog steeds geen snellere manier om een resultaat te verkrijgen dan alle onderliggende verwerking volledig te vermijden, hoe efficiënt die verwerking ook is zou kunnen zijn geworden.
Voordat geïndexeerde weergaven (en hun beperktere neven, berekende kolommen) aan het product werden toegevoegd, schreven databaseprofessionals soms complexe multi-triggercode om de resultaten van een belangrijke query in een echte tabel weer te geven. Dit soort arrangementen is notoir moeilijk in alle omstandigheden goed te krijgen, vooral wanneer gelijktijdige wijzigingen in de onderliggende gegevens frequent zijn.
De functie geïndexeerde weergaven maakt dit alles veel gemakkelijker, waar het verstandig en correct wordt toegepast. De database-engine zorgt voor alles wat nodig is om ervoor te zorgen dat gegevens die uit een geïndexeerde weergave worden gelezen, te allen tijde overeenkomen met de onderliggende query- en tabelgegevens.
Incrementeel onderhoud
SQL Server houdt geïndexeerde weergavegegevens gesynchroniseerd met de onderliggende query door de weergave-indexen automatisch bij te werken wanneer gegevens in de basistabellen worden gewijzigd. De kosten van deze onderhoudsactiviteit worden gedragen door het proces waarbij de basisgegevens worden gewijzigd. De extra bewerkingen die nodig zijn om de weergave-indexen te onderhouden, worden stil toegevoegd aan het uitvoeringsplan voor de oorspronkelijke bewerking voor invoegen, bijwerken, verwijderen of samenvoegen. Op de achtergrond zorgt SQL Server ook voor meer subtiele problemen met betrekking tot transactie-isolatie, bijvoorbeeld zorgen voor een correcte afhandeling van transacties die worden uitgevoerd onder snapshot of leescommitte snapshot-isolatie.
Het construeren van de extra uitvoeringsplanbewerkingen die nodig zijn om de weergave-indexen correct te onderhouden, is geen triviale zaak, zoals iedereen die heeft geprobeerd een "samenvattende tabel onderhouden door triggercode"-implementatie te implementeren, weet. De complexiteit van de taak is een van de redenen dat geïndexeerde weergaven zoveel beperkingen hebben. Door het ondersteunde oppervlak te beperken tot binnenverbindingen, projecties, selecties (filters) en de SUM- en COUNT_BIG-aggregaten, wordt de implementatiecomplexiteit aanzienlijk verminderd.
Geïndexeerde weergaven worden incrementeel onderhouden . Dit betekent dat de queryprocessor het netto-effect van de wijzigingen in de basistabel op de weergave bepaalt en alleen die wijzigingen toepast die nodig zijn om de weergave up-to-date te brengen. In eenvoudige gevallen kan het de benodigde delta's berekenen op basis van alleen de wijzigingen in de basistabel en de gegevens die momenteel in de weergave zijn opgeslagen. Waar de weergavedefinitie joins bevat, moet het geïndexeerde weergaveonderhoudsgedeelte van het uitvoeringsplan ook toegang hebben tot de samengevoegde tabellen, maar dit kan meestal efficiënt worden uitgevoerd, met de juiste basistabelindexen.
Om de implementatie verder te vereenvoudigen, gebruikt SQL Server altijd dezelfde basisplanvorm (als uitgangspunt) om onderhoudsbewerkingen voor geïndexeerde weergaven te implementeren. De normale faciliteiten die door de query-optimizer worden geboden, worden gebruikt om de standaardonderhoudsvorm waar nodig te vereenvoudigen en te optimaliseren. We gaan nu naar een voorbeeld om deze concepten samen te brengen.
Voorbeeld 1 – Enkele rij invoegen
Stel dat we de volgende eenvoudige tabel en geïndexeerde weergave hebben:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Nadat dat script is uitgevoerd, zien de gegevens in de voorbeeldtabel er als volgt uit:

En de geïndexeerde weergave bevat:

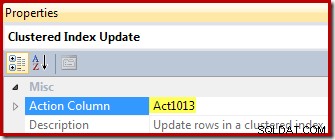
Het eenvoudigste voorbeeld van een onderhoudsplan met geïndexeerde weergave voor deze opstelling doet zich voor wanneer we een enkele rij aan de basistabel toevoegen:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Het uitvoeringsplan voor deze bijlage wordt hieronder weergegeven:
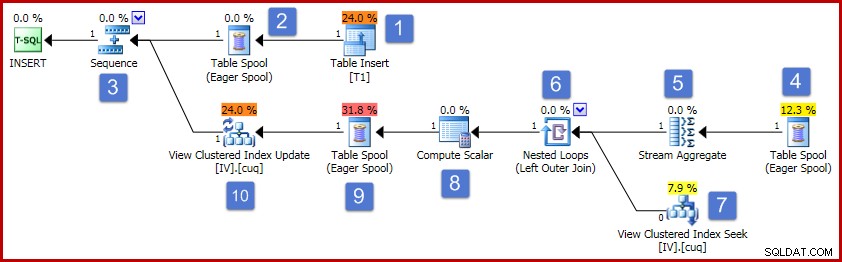
Volgens de nummers in het diagram gaat de werking van dit uitvoeringsplan als volgt:
- De operator Tabel invoegen voegt de nieuwe rij toe aan de basistabel. Dit is de enige planoperator die is gekoppeld aan de basistabelinvoeging; alle overige operators houden zich bezig met het onderhoud van de geïndexeerde weergave.
- De Eager Table Spool slaat de ingevoegde rijgegevens op in tijdelijke opslag.
- De reeksoperator zorgt ervoor dat de bovenste vertakking van het plan wordt voltooid voordat de volgende vertakking in de reeks wordt geactiveerd. In dit speciale geval (het invoegen van een enkele rij), zou het geldig zijn om de sequentie (en de spoelen op posities 2 en 4) te verwijderen, waarbij de stroomaggregaatinvoer rechtstreeks wordt aangesloten op de uitvoer van de tabelinvoeging. Deze mogelijke optimalisatie is niet geïmplementeerd, dus de volgorde en spoelen blijven bestaan.
- Deze Eager Table Spool is gekoppeld aan de spool op positie 2 (hij heeft een Primary Node ID eigenschap die deze link expliciet verschaft). De spoel herhaalt rijen (één rij in dit geval) van dezelfde tijdelijke opslag waarnaar door de primaire spoel is geschreven. Zoals hierboven vermeld, zijn de spoelen en posities 2 en 4 niet nodig en zijn ze eenvoudigweg aanwezig in de generieke sjabloon voor onderhoud van geïndexeerde weergaven.
- De Stream Aggregate berekent de som van de kolomgegevens Waarde in de ingevoegde set en telt het aantal aanwezige rijen per weergavesleutelgroep. De uitvoer is de incrementele gegevens die nodig zijn om de weergave gesynchroniseerd te houden met de basisgegevens. Let op:de Stream Aggregate heeft geen Group By-element omdat de query-optimizer weet dat er slechts één waarde wordt verwerkt. De optimizer past echter geen vergelijkbare logica toe om de aggregaten te vervangen door projecties (de som van een enkele waarde is alleen de waarde zelf, en de telling zal altijd één zijn voor een enkele rij-invoeging). Het berekenen van de som en tellingen voor een enkele rij gegevens is geen dure operatie, dus deze gemiste optimalisatie is niet veel om je zorgen over te maken.
- De join relateert elke berekende incrementele wijziging aan een bestaande sleutel in de geïndexeerde weergave. De join is een outer join omdat de nieuw ingevoegde gegevens mogelijk niet overeenkomen met bestaande gegevens in de weergave.
- Deze operator zoekt de rij die moet worden gewijzigd in de weergave.
- De Compute Scalar heeft twee belangrijke verantwoordelijkheden. Ten eerste bepaalt het of elke incrementele wijziging een bestaande rij in de weergave beïnvloedt, of dat er een nieuwe rij moet worden gemaakt. Het doet dit door te controleren of de buitenste voeg een nul heeft geproduceerd vanaf de zichtzijde van de voeg. Onze voorbeeldinvoeging is voor groep 3, die momenteel niet bestaat in de weergave, dus er wordt een nieuwe rij gemaakt. De tweede functie van de Compute Scalar is het berekenen van nieuwe waarden voor de weergavekolommen. Als er een nieuwe rij aan de weergave moet worden toegevoegd, is dit eenvoudigweg het resultaat van de incrementele som van het stroomaggregaat. Als een bestaande rij in de weergave moet worden bijgewerkt, is de nieuwe waarde de bestaande waarde in de weergaverij plus de incrementele som van het stroomaggregaat.
- Deze enthousiaste tafelspoel is bedoeld voor Halloween-bescherming. Het is vereist voor correctheid wanneer een invoegbewerking een tabel beïnvloedt waarnaar ook wordt verwezen aan de gegevenstoegangszijde van de query. Het is technisch niet vereist als de onderhoudsbewerking met één rij resulteert in een update van een bestaande weergaverij, maar het blijft toch in het plan.
- De laatste operator in het plan is gelabeld als een Update-operator, maar deze voert een invoeging of een update uit voor elke rij die hij ontvangt, afhankelijk van de waarde van de kolom 'actiecode' die is toegevoegd door de Compute Scalar op knooppunt 8 Meer in het algemeen kan deze update-operator invoegen, bijwerken en verwijderen.
Er is nogal wat detail, dus om samen te vatten:
- De gegevens van de geaggregeerde groepen worden gewijzigd door de unieke geclusterde sleutel van de weergave. Het berekent het netto-effect van de wijzigingen in de basistabel op elke kolom per toets.
- De outer join verbindt de incrementele wijzigingen per toets met bestaande rijen in de weergave.
- De compute scalaire berekent of een nieuwe rij moet worden toegevoegd aan de weergave, of een bestaande rij moet worden bijgewerkt. Het berekent de laatste kolomwaarden voor de bewerking voor het invoegen of bijwerken van weergave.
- De view update-operator voegt een nieuwe rij in of werkt een bestaande bij zoals aangegeven in de actiecode.
Voorbeeld 2 – Invoegen met meerdere rijen
Geloof het of niet, het hierboven besproken uitvoeringsplan voor het invoegen van een basistabel met één rij was onderhevig aan een aantal vereenvoudigingen. Hoewel enkele mogelijke verdere optimalisaties werden gemist (zoals opgemerkt), slaagde de query-optimizer er toch in om enkele bewerkingen uit de algemene onderhoudssjabloon voor geïndexeerde weergaven te verwijderen en de complexiteit van andere te verminderen.
Verschillende van deze optimalisaties waren toegestaan omdat we slechts één rij invoegden, maar andere waren ingeschakeld omdat de optimizer kon zien dat de letterlijke waarden werden toegevoegd aan de basistabel. De optimizer zou bijvoorbeeld kunnen zien dat de ingevoegde groepswaarde het predikaat in de WHERE-component van de weergave zou doorgeven.
Als we nu twee rijen invoegen, met de waarden "verborgen" in lokale variabelen, krijgen we een iets complexer plan:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
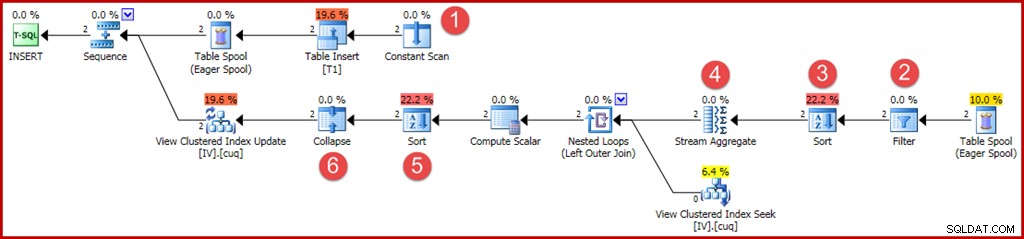
De nieuwe of gewijzigde operators worden zoals voorheen geannoteerd:
- De Constant Scan levert de in te voegen waarden. Voorheen zorgde een optimalisatie voor invoegingen met één rij ervoor dat deze operator kon worden weggelaten.
- Er is nu een expliciete filteroperator vereist om te controleren of de groepen die in de basistabel zijn ingevoegd, overeenkomen met de WHERE-component in de weergave. Toevallig zullen beide nieuwe rijen de test doorstaan, maar de optimizer kan de waarden in de variabelen niet zien om dit van tevoren te weten. Bovendien zou het niet veilig zijn om een plan dat dit filter heeft overgeslagen in de cache te cachen, omdat een toekomstig hergebruik van het plan andere waarden in de variabelen zou kunnen hebben.
- Er is nu een sortering vereist om ervoor te zorgen dat de rijen in groepsvolgorde bij het stroomaggregaat aankomen. De sortering is eerder verwijderd omdat het zinloos is om één rij te sorteren.
- De Stream Aggregate heeft nu een eigenschap "groeperen op" die overeenkomt met de unieke geclusterde sleutel van de weergave.
- Deze sortering is vereist om rijen te presenteren in de volgorde van de weergavesleutel en de actiecode, wat vereist is voor een correcte werking van de operator Samenvouwen. Sort is een volledig blokkerende operator, dus er is geen Eager Table Spool meer nodig voor Halloween-bescherming.
- De nieuwe operator Samenvouwen combineert een aangrenzend invoegen en verwijderen op dezelfde sleutelwaarde in een enkele update-bewerking. Deze operator is eigenlijk niet vereist in dit geval omdat er geen verwijderactiecodes kunnen worden gegenereerd (alleen invoegingen en updates). Dit lijkt een vergissing te zijn, of misschien iets dat om veiligheidsredenen is achtergelaten. De automatisch gegenereerde delen van een updatequeryplan kunnen extreem complex worden, dus het is moeilijk zeker te weten.
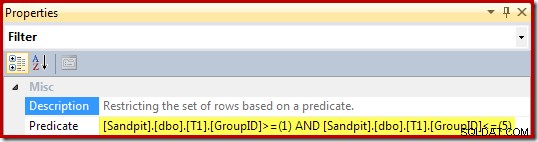
De eigenschappen van het filter (afgeleid van de WHERE-component van de view) zijn:
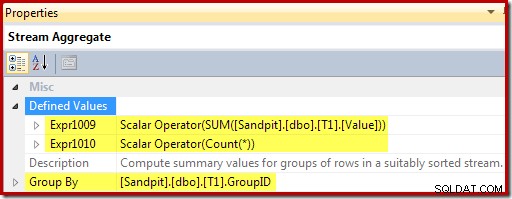
De Stream Aggregate groepeert op de weergavesleutel en berekent de som en tellingen per groep:
De Compute Scalar identificeert de actie die moet worden ondernomen per rij (in dit geval invoegen of bijwerken) en berekent de waarde die moet worden ingevoegd of bijgewerkt in de weergave:
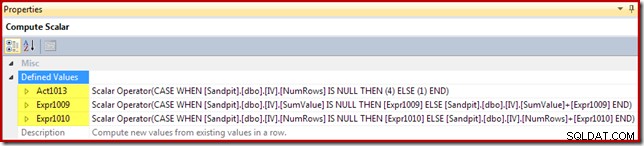
De actiecode krijgt een expressielabel van [Act1xxx]. Geldige waarden zijn 1 voor een update, 3 voor een verwijdering en 4 voor een invoeging. Deze actie-expressie resulteert in een insert (code 4) als er geen overeenkomende rij is gevonden in de weergave (d.w.z. de outer join retourneerde een null voor de NumRows-kolom). Als er een overeenkomende rij is gevonden, is de actiecode 1 (update).
Houd er rekening mee dat NumRows de naam is die wordt gegeven aan de vereiste kolom COUNT_BIG(*) in de weergave. In een plan dat zou kunnen leiden tot verwijderingen uit de weergave, zou de Compute Scalar detecteren wanneer deze waarde nul zou worden (geen rijen voor de huidige groep) en een actiecode voor verwijderen genereren (3).
De overige expressies behouden de som- en tellingsaggregaten in de weergave. Merk echter op dat de uitdrukkingslabels [Uitdr1009] en [Uitdr1010] niet nieuw zijn; ze verwijzen naar de labels die zijn gemaakt door de Stream Aggregate. De logica is eenvoudig:als er geen overeenkomende rij is gevonden, is de nieuwe waarde die moet worden ingevoegd gewoon de waarde die bij het totaal is berekend. Als er een overeenkomende rij in de weergave is gevonden, is de bijgewerkte waarde de huidige waarde in de rij plus de toename berekend door het totaal.
Ten slotte toont de view update-operator (weergegeven als een geclusterde indexupdate in SSMS) de actiekolomreferentie ([Act1013] gedefinieerd door de Compute Scalar):
Voorbeeld 3 – Update met meerdere rijen
Tot nu toe hebben we alleen gekeken naar inzetstukken voor de basistafel. De uitvoeringsplannen voor een verwijdering lijken erg op elkaar, met slechts een paar kleine verschillen in de gedetailleerde berekeningen. Dit volgende voorbeeld gaat daarom verder om het onderhoudsplan voor een update van de basistabel te bekijken:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Zoals eerder gebruikt deze query variabelen om letterlijke waarden te verbergen voor de optimizer, waardoor sommige vereenvoudigingen niet kunnen worden toegepast. Het is ook voorzichtig om twee afzonderlijke groepen bij te werken, waardoor optimalisaties worden voorkomen die kunnen worden toegepast wanneer de optimizer weet dat slechts een enkele groep (een enkele rij van de geïndexeerde weergave) wordt beïnvloed. Het geannoteerde uitvoeringsplan voor de updatequery staat hieronder:
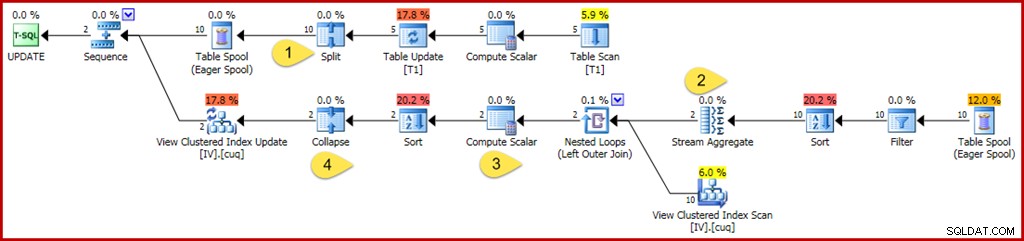
De wijzigingen en aandachtspunten zijn:
- De nieuwe operator Splitsen verandert elke update van de basistabelrij in een afzonderlijke verwijder- en invoegbewerking. Elke updaterij is opgesplitst in twee afzonderlijke rijen, waardoor het aantal rijen na dit punt in het plan wordt verdubbeld. Splitsen maakt deel uit van het patroon split-sort-collapse dat nodig is om te beschermen tegen onjuiste tijdelijke unieke sleutelovertredingsfouten.
- Het stroomaggregaat is aangepast om rekening te houden met inkomende rijen die een verwijdering of een invoeging kunnen specificeren (vanwege de splitsing en bepaald door een actiecodekolom in de rij). Een invoegrij draagt de oorspronkelijke waarde bij in somaggregaten; het teken is omgekeerd voor actierijen verwijderen. Op dezelfde manier telt het aggregaat voor het aantal rijen hier ingevoegde rijen als +1 en verwijder rijen als -1.
- De Compute Scalar-logica is ook aangepast om aan te geven dat het netto-effect van de wijzigingen per groep een eventuele invoeg-, update- of verwijderactie tegen de gerealiseerde weergave kan vereisen. Het is niet mogelijk dat deze specifieke update-query ertoe leidt dat een rij wordt ingevoegd of verwijderd tegen deze weergave, maar de logica die nodig is om dit af te leiden, gaat de huidige redeneermogelijkheden van de optimizer te boven. Een iets andere updatequery of weergavedefinitie kan inderdaad resulteren in een combinatie van invoeg-, verwijder- en updateweergaveacties.
- De operator Samenvouwen wordt alleen gemarkeerd vanwege zijn rol in het hierboven genoemde patroon van splitsen, sorteren en samenvouwen. Merk op dat het alleen deletes en inserts op dezelfde sleutel samenvouwt; ongeëvenaarde verwijderingen en invoegingen na de Collapse zijn perfect mogelijk (en vrij gebruikelijk).
Zoals eerder zijn de eigenschappen van de key-operator om naar te kijken om inzicht te krijgen in het onderhoudswerk van de geïndexeerde weergave, de Filter, Stream Aggregate, Outer Join en Compute Scalar.
Voorbeeld 4 – Update met meerdere rijen met joins
Om het overzicht van onderhoudsuitvoeringsplannen voor geïndexeerde weergaven te voltooien, hebben we een nieuwe voorbeeldweergave nodig die verschillende tabellen samenvoegt en een projectie bevat in de geselecteerde lijst:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Om de juistheid te garanderen, is een van de vereisten voor geïndexeerde weergaven dat een somaggregaat niet kan werken op een uitdrukking die zou kunnen resulteren in null. De bovenstaande weergavedefinitie gebruikt ISNULL om aan die vereiste te voldoen. Hieronder ziet u een voorbeeld van een updatequery die een behoorlijk uitgebreide component voor een indexonderhoudsplan oplevert, samen met het uitvoeringsplan dat het produceert:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
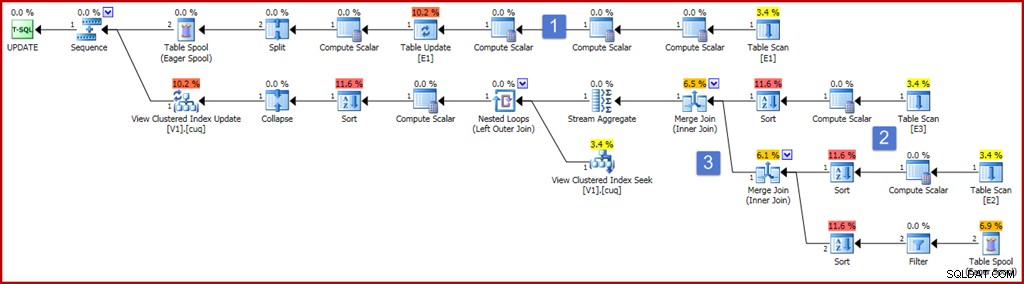
Het plan ziet er nu vrij groot en ingewikkeld uit, maar de meeste elementen zijn precies zoals we al hebben gezien. De belangrijkste verschillen zijn:
- De bovenste tak van het plan omvat een aantal extra Compute Scalar-operators. Deze zouden compacter kunnen worden gerangschikt, maar in wezen zijn ze aanwezig om de pre-update-waarden van de niet-groeperende kolommen vast te leggen. De Compute Scalar links van de tabelupdate legt de post-update waarde van kolom "a" vast met de ISNULL-projectie toegepast.
- De nieuwe Compute Scalars in dit gebied van het plan berekenen de waarde die wordt geproduceerd door de ISNULL-expressie op elke brontabel. Over het algemeen worden projecties op de samengevoegde tabellen in de weergave hier weergegeven door Compute Scalars. De soorten in dit gebied van het plan zijn puur aanwezig omdat de optimizer om kostenredenen een merge-join-strategie heeft gekozen (onthoud, voor merge is een met de join-sleutel gesorteerde invoer vereist).
- De twee join-operators zijn nieuw en implementeren de joins eenvoudig in de weergavedefinitie. Deze joins verschijnen altijd vóór de Stream Aggregate die het incrementele effect van de wijzigingen op de weergave berekent. Houd er rekening mee dat een wijziging in een basistabel ertoe kan leiden dat een rij die vroeger aan de criteria voor samenvoegen voldeed, niet meer deelneemt, en vice versa. Al deze potentiële complexiteiten worden correct afgehandeld (gezien de geïndexeerde weergavebeperkingen) door de Stream Aggregate die een samenvatting produceert van de wijzigingen per weergavesleutel nadat de samenvoegingen zijn uitgevoerd.
Laatste gedachten
Dat laatste plan vertegenwoordigt vrijwel de volledige sjabloon voor het onderhouden van een geïndexeerde weergave, hoewel de toevoeging van niet-geclusterde indexen aan de weergave ook extra operators zou toevoegen die de uitvoer van de weergave-update-operator in de wachtrij plaatsen. Afgezien van een extra Split (en een Sort en Collapse combinatie als de niet-geclusterde index van de view uniek is), is er niets bijzonders aan deze mogelijkheid. Het toevoegen van een uitvoerclausule aan de basistabelquery kan ook enkele interessante extra operators opleveren, maar nogmaals, deze zijn niet per se specifiek voor onderhoud van geïndexeerde weergaven.
Om de volledige algemene strategie samen te vatten:
- Wijzigingen in de basistabel worden normaal toegepast; pre-update waarden kunnen worden vastgelegd.
- Een split-operator kan worden gebruikt om updates om te zetten in delete/insert-paren.
- Een enthousiaste spoel slaat de wijzigingsinformatie van de basistabel op in tijdelijke opslag.
- Alle tabellen in de weergave zijn toegankelijk, behalve de bijgewerkte basistabel (die van de spool wordt gelezen).
- Projecties in de weergave worden weergegeven door Compute Scalars.
- Filters in de weergave worden toegepast. Filters kunnen als restanten in scans of zoekacties worden geduwd.
- De in de weergave gespecificeerde joins worden uitgevoerd.
- Een aggregaat berekent netto incrementele wijzigingen gegroepeerd op geclusterde weergavesleutel.
- De incrementele wijzigingsset is aan de buitenkant verbonden met de weergave.
- Een Compute Scalar berekent een actiecode (invoegen/bijwerken/verwijderen tegen de weergave) voor elke wijziging en berekent de werkelijke waarden die moeten worden ingevoegd of bijgewerkt. De computationele logica is gebaseerd op de output van het aggregaat en het resultaat van de buitenste verbinding met de weergave.
- Wijzigingen worden gesorteerd op volgorde van weergavesleutel en actiecode, en indien nodig samengevouwen tot updates.
- Ten slotte worden de incrementele wijzigingen toegepast op de weergave zelf.
Zoals we hebben gezien, wordt de normale set tools die beschikbaar zijn voor de query-optimizer nog steeds toegepast op de automatisch gegenereerde delen van het plan, wat betekent dat een of meer van de bovenstaande stappen kunnen worden vereenvoudigd, getransformeerd of volledig kunnen worden verwijderd. De basisvorm en werking van het plan blijft echter intact.
Als je de codevoorbeelden hebt gevolgd, kun je het volgende script gebruiken om op te schonen:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;