Laten we beginnen aan onze SQL-reis om inzicht te krijgen in aggregatiegegevens in SQL en typen aggregaties, waaronder eenvoudige en glijdende aggregaties.
Voordat we naar de aggregaties gaan, is het de moeite waard om te kijken naar interessante feiten die sommige ontwikkelaars vaak over het hoofd zien als het gaat om SQL in het algemeen en de aggregatie in het bijzonder.
In dit artikel verwijst SQL naar T-SQL, de Microsoft-versie van SQL en heeft meer functies dan de standaard SQL.
Wiskunde achter SQL
Het is erg belangrijk om te begrijpen dat T-SQL is gebaseerd op een aantal solide wiskundige concepten, hoewel het geen rigide op wiskunde gebaseerde taal is.
Volgens het boek "Microsoft_SQL_Server_2008_T_SQL_Fundamentals" van Itzik Ben-Gan is SQL ontworpen om gegevens op te vragen en te beheren in een relationeel databasebeheersysteem (RDBMS).
Het relationele databasebeheersysteem zelf is gebaseerd op twee solide wiskundige takken:
- Set-theorie
- Predikaatlogica
Set-theorie
De verzamelingenleer is, zoals de naam al aangeeft, een tak van de wiskunde over verzamelingen die ook verzamelingen van bepaalde onderscheiden objecten kunnen worden genoemd.
Kortom, in de verzamelingenleer denken we over dingen of objecten als geheel op dezelfde manier als we aan een individueel item denken.
Een boek is bijvoorbeeld een verzameling van alle duidelijk onderscheiden boeken, dus we nemen een boek als een geheel dat voldoende is om details van alle boeken erin te krijgen.
Predikaatlogica
Predikaatlogica is een Booleaanse logica die waar of onwaar retourneert, afhankelijk van de voorwaarde of waarden van de variabelen.
Predikaatlogica kan worden gebruikt om integriteitsregels af te dwingen (prijs moet hoger zijn dan 0,00) of om gegevens te filteren (waarbij prijs hoger is dan 10,00), maar in de context van T-SQL hebben we drie logische waarden als volgt:
- Waar
- Niet waar
- Onbekend (Null)
Dit kan als volgt worden geïllustreerd:
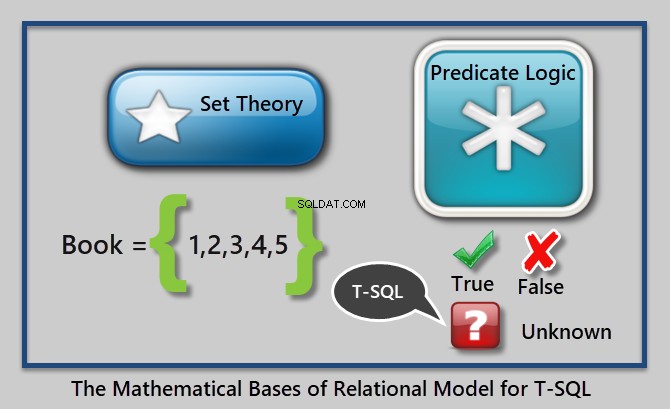
Een voorbeeld van een predikaat is "Waar de prijs van het boek hoger is dan 10,00".
Dat is genoeg over wiskunde, maar houd er rekening mee dat ik er later in het artikel naar ga verwijzen.
Waarom het aggregeren van gegevens in SQL eenvoudig is
Bij het aggregeren van gegevens in SQL in zijn eenvoudigste vorm gaat het erom in één keer de totalen te leren kennen.
Als we bijvoorbeeld een klantentabel hebben die een lijst van alle klanten bevat, samen met hun gegevens, dan kunnen geaggregeerde gegevens van de klantentabel ons het totale aantal klanten geven dat we hebben.
Zoals eerder besproken, beschouwen we een set als een enkel item, dus passen we eenvoudig een aggregatiefunctie toe op de tabel om de totalen te krijgen.
Aangezien SQL oorspronkelijk een op een set gebaseerde taal is (zoals eerder besproken), is het relatief eenvoudiger om geaggregeerde functies erop toe te passen in vergelijking met andere talen.
Als we bijvoorbeeld een producttabel hebben met records van alle producten in de database, kunnen we de telfunctie meteen toepassen op een producttabel om het totale aantal producten te krijgen in plaats van ze één voor één in een lus te tellen.
Recept voor gegevensaggregatie
Om gegevens in SQL te aggregeren, hebben we minimaal de volgende dingen nodig:
- Gegevens (tabel) met kolommen die logisch zijn wanneer ze worden samengevoegd
- Een aggregatiefunctie die op de gegevens moet worden toegepast
Voorbereiden van voorbeeldgegevens (tabel)
Laten we een voorbeeld nemen van een eenvoudige besteltabel die drie dingen (kolommen) bevat:
- Bestelnummer (OrderId)
- Datum waarop de bestelling is geplaatst (OrderDate)
- Bedrag van de bestelling (TotalAmount)
Laten we de AggregateSample-database maken om verder te gaan:
-- Create aggregate sample database CREATE DATABASE AggregateSample
Maak nu als volgt de besteltabel in de voorbeelddatabase aan:
-- Create order table in the aggregate sample database USE AggregateSample CREATE TABLE SimpleOrder (OrderId INT PRIMARY KEY IDENTITY(1,1), OrderDate DATETIME2, TotalAmount DECIMAL(10,2) )
Voorbeeldgegevens invullen
Vul de tabel door één rij toe te voegen:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ); GO
Laten we nu naar de tafel kijken:
-- View order table SELECT OrderId ,OrderDate ,TotalAmount FROM SimpleOrder
Houd er rekening mee dat ik in dit artikel dbForge Studio voor SQL Server gebruik, dus alleen het uiterlijk van de uitvoer kan verschillen als u dezelfde code uitvoert in SSMS (SQL Server Management Studio), er is geen verschil wat betreft scripts en hun resultaten.
Algemene basisfuncties
De basisaggregatiefuncties die op de tabel kunnen worden toegepast zijn als volgt:
- Som
- Tellen
- Min
- Max
- Gemiddeld
Aggregatietabel met één record
Nu is de interessante vraag:"kunnen we gegevens (records) samenvoegen (optellen of tellen) in een tabel als deze maar één rij heeft, zoals in ons geval?" Het antwoord is "Ja", dat kunnen we, hoewel het niet veel zin heeft, maar het kan ons helpen te begrijpen hoe gegevens klaar worden voor aggregatie.
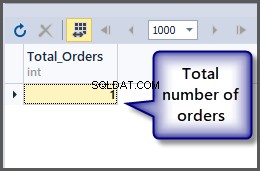
Om het totale aantal bestellingen te krijgen, gebruiken we de functie count () met de tabel, zoals eerder besproken, we kunnen eenvoudig de aggregatiefunctie op de tabel toepassen, aangezien SQL een op sets gebaseerde taal is en bewerkingen kunnen worden toegepast op een set rechtstreeks.
-- Getting total number of orders placed so far SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
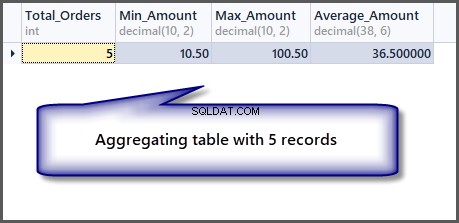
Hoe zit het nu met de bestelling met een minimum, maximum en gemiddeld bedrag voor een enkel record:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
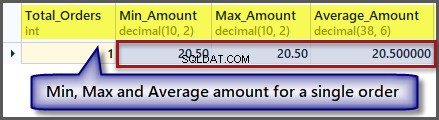
Zoals we aan de uitvoer kunnen zien, is het minimum, maximum en gemiddelde bedrag hetzelfde als we een enkele record hebben, dus het is mogelijk om een aggregatiefunctie op een enkele record toe te passen, maar het geeft ons dezelfde resultaten.
We hebben ten minste meer dan één record nodig om de geaggregeerde gegevens te begrijpen.
Tabel met meerdere records samenvoegen
Laten we nu als volgt nog vier records toevoegen:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ), ( '20180102' -- OrderDate - datetime2 ,30.50 -- TotalAmount - decimal(10, 2) ), ( '20180103' -- OrderDate - datetime2 ,10.50 -- TotalAmount - decimal(10, 2) ), ( '20180110' -- OrderDate - datetime2 ,100.50 -- TotalAmount - decimal(10, 2) ); GO
De tabel ziet er nu als volgt uit:
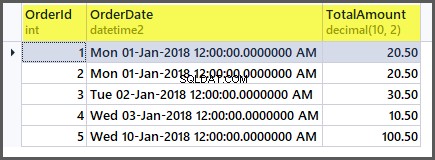
Als we nu de aggregatiefuncties op de tabel toepassen, krijgen we goede resultaten:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
Geaggregeerde gegevens groeperen
We kunnen de geaggregeerde gegevens groeperen op elke kolom of reeks kolommen om op basis van die kolom aggregaties te krijgen.
Als we bijvoorbeeld het totale aantal bestellingen per datum willen weten, we moeten de tabel als volgt groeperen op datum met behulp van Groeperen op clausule:
-- Getting total orders per date SELECT OrderDate ,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate
De uitvoer is als volgt:
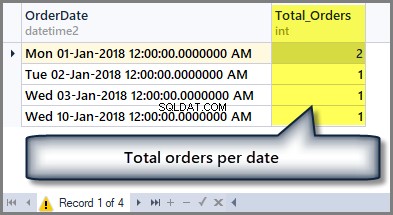
Dus als we de som van het totale orderbedrag willen zien, we kunnen de somfunctie eenvoudig toepassen op de kolom totaalbedrag zonder enige groepering als volgt:
-- Sum of all the orders amount SELECT SUM(TotalAmount) AS Sum_of_Orders_Amount FROM SimpleOrder
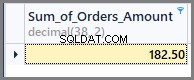
Om de som van het orderbedrag per datum te krijgen, voegen we eenvoudig als volgt gegroepeerd op datum toe aan het bovenstaande SQL-statement:
-- Sum of all the orders amount per date SELECT OrderDate ,SUM(TotalAmount) AS Sum_of_Orders FROM SimpleOrder GROUP BY OrderDate
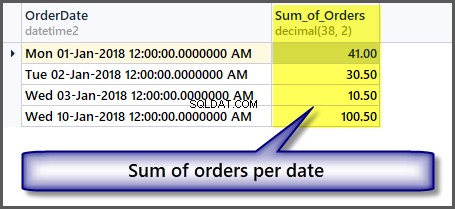
Totalen ophalen zonder gegevens te groeperen
We kunnen meteen totalen krijgen zoals totale bestellingen, maximum bestelbedrag, minimum bestelbedrag, som van bestelbedrag, gemiddeld bestelbedrag zonder dat we het hoeven te groeperen als de aggregatie bedoeld is voor alle tabellen.
-- Getting order with minimum amount, maximum amount, average amount, sum of amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) AS Average_Amount ,SUM(TotalAmount) AS Sum_of_Amount FROM SimpleOrder
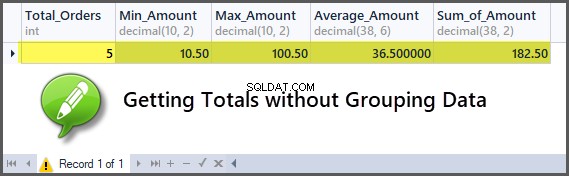
Klanten toevoegen aan de bestellingen
Laten we wat plezier toevoegen door klanten aan onze tafel toe te voegen. We kunnen dit doen door een andere tabel met klanten te maken en de klant-ID door te geven aan de besteltabel, maar om het simpel te houden en de datawarehouse-stijl te imiteren (waar tabellen gedenormaliseerd zijn), voeg ik de kolom met de naam van de klant als volgt toe aan de besteltabel :
-- Adding CustomerName column and data to the order table ALTER TABLE SimpleOrder ADD CustomerName VARCHAR(40) NULL GO UPDATE SimpleOrder SET CustomerName = 'Eric' WHERE OrderId = 1 GO UPDATE SimpleOrder SET CustomerName = 'Sadaf' WHERE OrderId = 2 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 3 GO UPDATE SimpleOrder SET CustomerName = 'Asif' WHERE OrderId = 4 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 5 GO
Totaal aantal bestellingen per klant ontvangen
Kun je nu raden hoe je het totale aantal bestellingen per klant kunt krijgen? U moet groeperen op klant (Klantnaam) en de aggregatiefunctie count() als volgt op alle records toepassen:
-- Total orders per customer
SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder
GROUP BY CustomerName
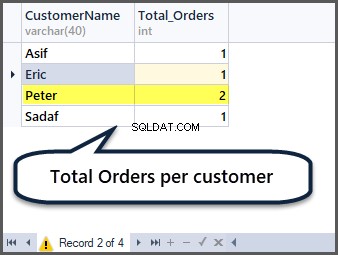
Vijf records toevoegen aan de besteltabel
Nu gaan we als volgt nog vijf rijen toevoegen aan de eenvoudige besteltabel:
-- Adding 5 more records to order table
INSERT INTO SimpleOrder (OrderDate, TotalAmount, CustomerName)
VALUES
('01-Jan-2018', 70.50, 'Sam'),
('02-Jan-2018', 170.50, 'Adil'),
('03-Jan-2018',50.00,'Sarah'),
('04-Jan-2018',50.00,'Asif'),
('11-Jan-2018',50.00,'Peter')
GO
Bekijk nu de gegevens:
-- Viewing order table after adding customer name and five more rows SELECT OrderId,CustomerName,OrderDate,TotalAmount FROM SimpleOrder GO
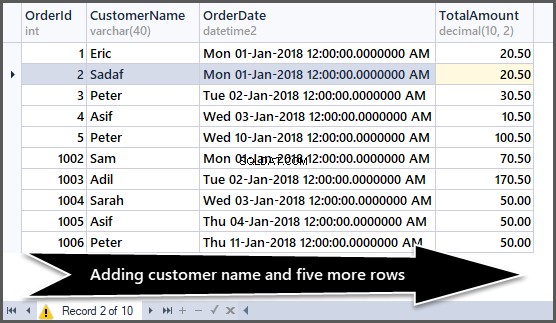
Totaal aantal bestellingen per klant gesorteerd op maximum tot minimum bestellingen
Als u geïnteresseerd bent in het totaal aantal bestellingen per klant gesorteerd van maximum tot minimum, is het helemaal geen slecht idee om dit als volgt in kleinere stappen op te splitsen:
-- (1) Getting total orders SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
-- (2) Getting total orders per customer SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName
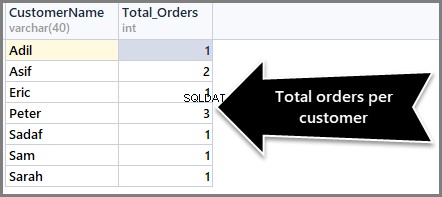
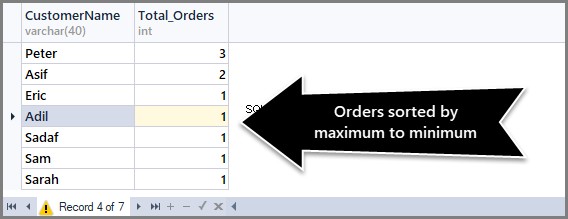
Om het aantal bestellingen van maximum naar minimum te sorteren, moeten we de Order By DESC-clausule (aflopende volgorde) gebruiken met count() aan het einde als volgt:
-- (3) Getting total orders per customer from maximum to minimum orders SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName ORDER BY COUNT(*) DESC
Totaal aantal bestellingen per datum gesorteerd op meest recente bestelling eerst
Met behulp van de bovenstaande methode kunnen we nu het totale aantal bestellingen per datum achterhalen, gesorteerd op de meest recente bestelling als volgt:
-- Getting total orders per date from most recent first SELECT CAST(OrderDate AS DATE) AS OrderDate,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate ORDER BY OrderDate DESC
De CAST-functie helpt ons om alleen het datumgedeelte te krijgen. De uitvoer is als volgt:
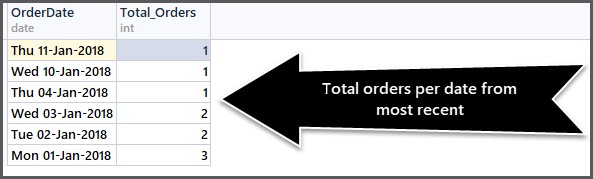
Je kunt zoveel mogelijk combinaties gebruiken, zolang ze maar logisch zijn.
Aggregaties uitvoeren
Nu we bekend zijn met het toepassen van aggregatiefuncties op onze gegevens, gaan we verder met de geavanceerde vorm van aggregaties. Een van die aggregaties is de lopende aggregatie.
Actieve aggregaties zijn de aggregaties die worden toegepast op een subset van gegevens in plaats van op de hele dataset, wat ons helpt om kleine vensters op de gegevens te creëren.
Tot nu toe hebben we gezien dat alle aggregatiefuncties worden toegepast op alle rijen van de tabel die kunnen worden gegroepeerd op een kolom, zoals de besteldatum of de naam van de klant, maar met actieve aggregaties hebben we de vrijheid om de aggregatiefuncties toe te passen zonder het geheel te groeperen gegevensset.
Dit betekent uiteraard dat we de aggregatiefunctie kunnen toepassen zonder de Group By-clausule te gebruiken, wat enigszins vreemd is voor die SQL-beginners (of soms zien sommige ontwikkelaars dit over het hoofd) die niet bekend zijn met de vensterfuncties en het uitvoeren van aggregaties.
Windows op gegevens
Zoals eerder gezegd, wordt de lopende aggregatie toegepast op een subset van datasets of (met andere woorden) op kleine datavensters.
Denk aan vensters als een set(s) binnen een set of een tafel(s) binnen een tafel. Een goed voorbeeld van gegevensvensters in ons geval is dat we de besteltabel hebben die bestellingen bevat die op verschillende datums zijn geplaatst, dus wat als elke datum een afzonderlijk venster is, dan kunnen we op elk venster geaggregeerde functies toepassen op dezelfde manier als waarop we hebben toegepast op de tafel.
Als we de besteltabel (SimpleOrder) als volgt sorteren op besteldatum (OrderDate):
-- View order table sorted by order date
SELECT so.OrderId
,so.OrderDate
,so.TotalAmount
,so.CustomerName FROM SimpleOrder so
ORDER BY so.OrderDate
Windows op gegevens die klaar zijn om aggregaties uit te voeren, ziet u hieronder:

We kunnen deze vensters of subsets ook beschouwen als zes tabellen op basis van minibestellingsdatums en op elk van deze minitabellen kunnen aggregaten worden toegepast.
Gebruik van partitie door binnen OVER()-clausule
Actieve aggregaties kunnen worden toegepast door de tabel te partitioneren met behulp van "Partition by" in de OVER()-clausule.
Als we bijvoorbeeld de besteltabel willen partitioneren op datums, zoals elke datum een subtabel of venster in de gegevensset is, dan moeten we gegevens op besteldatum partitioneren en dit kan worden bereikt door een aggregatiefunctie zoals COUNT( ) met OVER() en Partitie door binnen OVER() als volgt:
-- Running Aggregation on Order table by partitioning by dates SELECT OrderDate, Total_Orders=COUNT(*) OVER(PARTITION BY OrderDate) FROM SimpleOrder

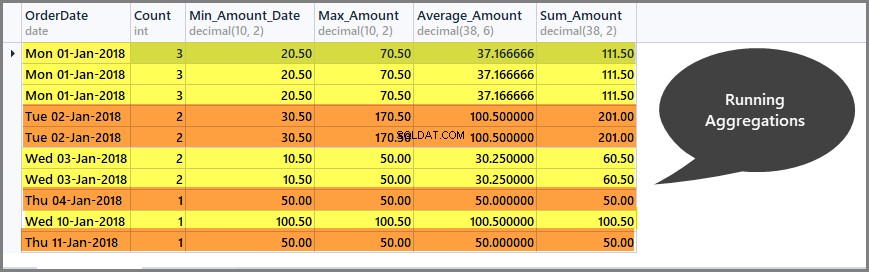
Lopende totalen per datumvenster krijgen (partitie)
Het uitvoeren van aggregaties helpt ons om het aggregatiebereik te beperken tot alleen het gedefinieerde venster en we kunnen als volgt lopende totalen per venster krijgen:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per date window (partition by date) SELECT CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY OrderDate), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY OrderDate) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY OrderDate) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY OrderDate), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY OrderDate) FROM SimpleOrder
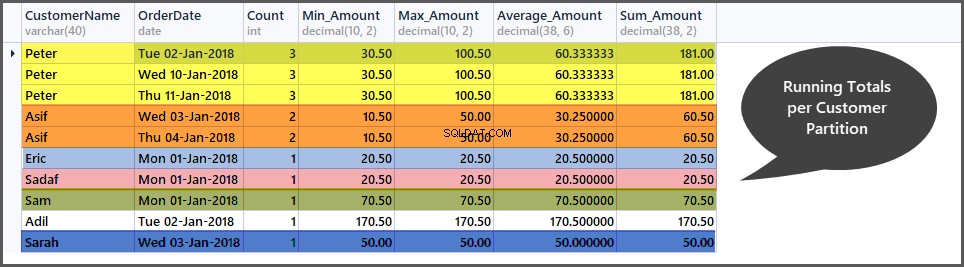
Lopende totalen krijgen per klantvenster (partitie)
Net als de lopende totalen per datumvenster, kunnen we ook de lopende totalen per klantvenster berekenen door de bestellingset (tabel) als volgt in kleine klantensubsets (partities) te verdelen:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per customer window (partition by customer) SELECT CustomerName, CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY CustomerName), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY CustomerName) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY CustomerName) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY CustomerName) FROM SimpleOrder ORDER BY Count DESC,OrderDate
Glijdende aggregaties
Schuifaggregaties zijn de aggregaties die kunnen worden toegepast op de frames binnen een venster, wat betekent dat het bereik binnen het venster (partitie) verder wordt beperkt.
Met andere woorden, lopende totalen geven ons totalen (som, gemiddelde, min, max, telling) voor het hele venster (subset) die we binnen een tabel maken, terwijl glijdende totalen ons totalen geven (som, gemiddelde, min, max, telling) voor het frame (subset van subset) binnen het venster (subset) van de tabel.
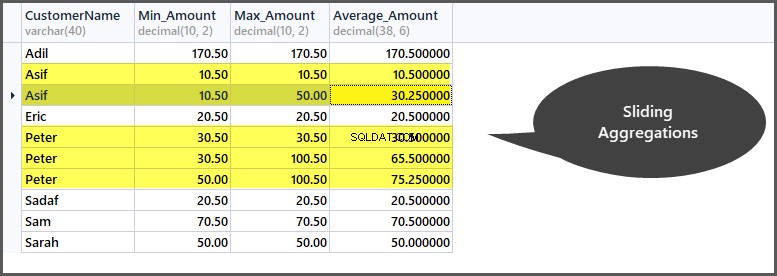
Als we bijvoorbeeld een venster met gegevens maken op basis van (partitie per klant) klant, kunnen we zien dat klant "Peter" drie records in zijn venster heeft en dat alle aggregaties worden toegepast op deze drie records. Als we nu een frame voor slechts twee rijen tegelijk willen maken, betekent dit dat de aggregatie verder wordt beperkt en vervolgens wordt toegepast op de eerste en tweede rij en vervolgens op de tweede en derde rij, enzovoort.
Gebruik van RIJEN VOORAFGAAND aan Order By binnen OVER() Clausule
Glijdende aggregaties kunnen worden toegepast door RIJEN
Als we bijvoorbeeld gegevens voor slechts twee rijen tegelijk voor elke klant willen verzamelen, moeten we als volgt glijdende aggregaties toepassen op de besteltabel:
-- Getting minimum amount, maximum amount, average amount per frame per customer window SELECT CustomerName, Min_Amount=Min(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING), Max_Amount=Max(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) FROM SimpleOrder so ORDER BY CustomerName
Laten we, om te begrijpen hoe het werkt, naar de originele tabel kijken in de context van kozijnen en vensters:
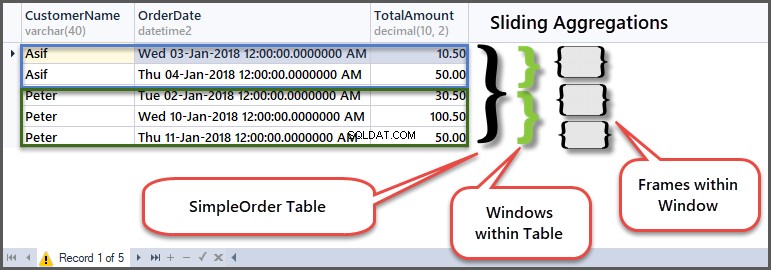
In de eerste rij van klant Peter-venster plaatste hij een bestelling met een bedrag van 30,50 omdat dit het begin is van het frame in het klantenvenster, dus min en max zijn hetzelfde omdat er geen vorige rij is om mee te vergelijken.
Vervolgens blijft het minimumbedrag hetzelfde, maar het maximum wordt 100,50 aangezien het bedrag van de vorige rij (eerste rij) 30,50 is en dit rijbedrag 100,50 is, dus het maximum van de twee is 100,50.
Vervolgens, door naar de derde rij te gaan, vindt de vergelijking plaats met de tweede rij, dus het minimum aantal van de twee is 50,00 en het maximum aantal van de twee rijen is 100,50.
MDX Year-to-date (YTD)-functie en actieve aggregaties
MDX is een multidimensionale expressietaal die wordt gebruikt voor het opvragen van multidimensionale gegevens (zoals kubus) en wordt gebruikt in business intelligence (BI)-oplossingen.
Volgens https://docs.microsoft.com/en-us/sql/mdx/ytd-mdx werkt de Year to Date (YTD)-functie in MDX op dezelfde manier als actieve of glijdende aggregaties. YTD bijvoorbeeld, vaak gebruikt in combinatie zonder opgegeven parameter, geeft een lopend totaal tot nu toe weer.
Dit betekent dat als we deze functie op jaar toepassen, het alle jaargegevens geeft, maar als we naar maart gaan, krijgen we alle totalen van het begin van het jaar tot maart enzovoort.
Dit is erg handig in SSRS-rapporten.
Dingen om te doen
Dat is het! U bent klaar om enkele basisgegevensanalyses uit te voeren nadat u dit artikel hebt doorgenomen en u kunt uw vaardigheden verder verbeteren door de volgende dingen:
- Probeer een lopend aggregatiescript te schrijven door vensters te maken in andere kolommen, zoals Totaalbedrag.
- Probeer ook een script voor glijdende aggregaties te schrijven door frames op andere kolommen te maken, zoals Totaalbedrag.
- Je kunt meer kolommen en records aan de tabel toevoegen (of zelfs meer tabellen) om andere aggregatiecombinaties te proberen.
- De voorbeeldscripts die in dit artikel worden genoemd, kunnen worden omgezet in opgeslagen procedures die kunnen worden gebruikt in SSRS-rapporten achter dataset(s).
Referenties:
- Ytd (MDX)
- dbForge Studio voor SQL Server