In april schreef ik over enkele native methoden binnen SQL Server die kunnen worden gebruikt om automatische updates van statistieken bij te houden. De drie opties die ik gaf waren SQL Trace, Extended Events en snapshots van sys.dm_db_stats_properties. Hoewel deze drie opties levensvatbaar blijven (zelfs in SQL Server 2014, hoewel mijn topaanbeveling nog steeds XE is), is SQL Sentry Plan Explorer een extra optie die me opviel toen ik onlangs enkele tests uitvoerde.
Velen van jullie gebruiken Plan Explorer alleen voor het lezen van uitvoeringsplannen, wat geweldig is. Het heeft tal van voordelen ten opzichte van Management Studio als het gaat om het beoordelen van plannen - van de kleine dingen, zoals het kunnen sorteren op topoperators en gemakkelijk problemen met kardinaliteitsschattingen zien, tot grotere voordelen, zoals het omgaan met complexe en grote plannen en het kunnen selecteren van een verklaring binnen een batch voor een eenvoudigere beoordeling van het plan. Maar achter de beelden die het gemakkelijker maken om plannen te ontleden, biedt Plan Explorer ook de mogelijkheid om een query uit te voeren en het daadwerkelijke plan te bekijken (in plaats van het in Management Studio uit te voeren en op te slaan). En bovendien, wanneer u het plan vanuit PE uitvoert, wordt er aanvullende informatie vastgelegd die nuttig kan zijn.
Laten we beginnen met de demo die ik heb gebruikt in mijn recente post, Hoe automatische updates van statistieken de prestaties van zoekopdrachten kunnen beïnvloeden. Ik begon met de AdventureWorks2012-database en ik maakte een kopie van de SalesOrderHeader-tabel met meer dan 200 miljoen rijen. De tabel heeft een geclusterde index op SalesOrderID en een niet-geclusterde index op CustomerID, OrderDate, SubTotal. [Nogmaals:als je herhaalde tests gaat doen, maak dan nu een back-up van deze database om jezelf wat tijd te besparen.] Ik heb eerst het huidige aantal rijen in de tabel geverifieerd en het aantal rijen dat zou moeten veranderen om een automatische update aan te roepen:
SELECT OBJECT_NAME([p].[object_id]) [TableName], [si].[name] [IndexName], [au].[type_desc] [Type], [p].[rows] [RowCount], ([p].[rows]*.20) + 500 [UpdateThreshold], [au].total_pages [PageCount], (([au].[total_pages]*8)/1024)/1024 [TotalGB] FROM [sys].[partitions] [p] JOIN [sys].[allocation_units] [au] ON [p].[partition_id] = [au].[container_id] JOIN [sys].[indexes] [si] on [p].[object_id] = [si].object_id and [p].[index_id] = [si].[index_id] WHERE [p].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Big_SalesOrderHeader CIX- en NCI-informatie
Ik heb ook de huidige statistiekenkop voor de index geverifieerd:
DBCC SHOW_STATISTICS ('Sales.Big_SalesOrderHeader',[IX_Big_SalesOrderHeader_CustomerID_OrderDate_SubTotal]);

NCI-statistieken:bij het begin
De opgeslagen procedure die ik gebruik voor het testen is al gemaakt, maar voor de volledigheid staat de code hieronder:
CREATE PROCEDURE Sales.usp_GetCustomerStats
@CustomerID INT,
@StartDate DATETIME,
@EndDate DATETIME
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate), COUNT([SalesOrderID]) as Computed
FROM [Sales].[Big_SalesOrderHeader]
WHERE CustomerID = @CustomerID
AND OrderDate BETWEEN @StartDate and @EndDate
GROUP BY CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate)
ORDER BY DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate);
END Voorheen startte ik ofwel een Trace- of Extended Events-sessie, of stelde ik mijn methode in om sys.dm_db_stats_properties snapshot te maken naar een tabel. Voor dit voorbeeld heb ik de bovenstaande opgeslagen procedure een paar keer uitgevoerd:
EXEC Sales.usp_GetCustomerStats 11331, '2012-08-01 00:00:00.000', '2012-08-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11330, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11506, '2012-11-01 00:00:00.000', '2012-11-30 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 17061, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11711, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15131, '2013-02-01 00:00:00.000', '2013-02-28 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 29837, '2012-10-01 00:00:00.000', '2012-10-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15750, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO
Ik heb vervolgens de procedurecache gecontroleerd om het aantal uitvoeringen te verifiëren en ook het plan dat in de cache was opgeslagen:
SELECT OBJECT_NAME([st].[objectid]), [st].[text], [qs].[execution_count], [qs].[creation_time], [qs].[last_execution_time], [qs].[min_worker_time], [qs].[max_worker_time], [qs].[min_logical_reads], [qs].[max_logical_reads], [qs].[min_elapsed_time], [qs].[max_elapsed_time], [qp].[query_plan] FROM [sys].[dm_exec_query_stats] [qs] CROSS APPLY [sys].[dm_exec_sql_text]([qs].plan_handle) [st] CROSS APPLY [sys].[dm_exec_query_plan]([qs].plan_handle) [qp] WHERE [st].[text] LIKE '%usp_GetCustomerStats%' AND OBJECT_NAME([st].[objectid]) IS NOT NULL;

Plancache-informatie voor de SP:bij het begin
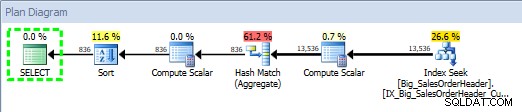
Queryplan voor opgeslagen procedure, met SQL Sentry Plan Explorer
Het plan is gemaakt op 29-09-2014 23:23.01.
Vervolgens heb ik 61 miljoen rijen aan de tabel toegevoegd om de huidige statistieken ongeldig te maken, en toen het invoegen voltooid was, controleerde ik het aantal rijen:

Big_SalesOrderHeader CIX- en NCI-informatie:na invoeging van 61 miljoen rijen
Voordat ik de opgeslagen procedure opnieuw uitvoerde, controleerde ik dat het aantal uitvoeringen niet was veranderd, dat de creation_time nog steeds 2014-09-29 23:23.01 was voor het plan en dat de statistieken niet waren bijgewerkt:
Plan cache-info voor de SP:onmiddellijk na invoegen

NCI-statistieken:na invoegen
In de vorige blogpost heb ik de verklaring uitgevoerd in Management Studio, maar deze keer heb ik de query rechtstreeks vanuit Plan Explorer uitgevoerd en het werkelijke plan vastgelegd via PE (optie rood omcirkeld in de afbeelding hieronder).
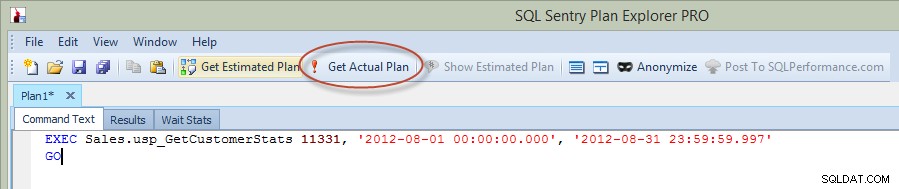
Opgeslagen procedure uitvoeren vanuit Plan Explorer
Wanneer u een instructie van PE uitvoert, moet u het exemplaar en de database invoeren waarmee u verbinding wilt maken, en dan krijgt u een melding dat de query wordt uitgevoerd en dat het daadwerkelijke plan wordt geretourneerd, maar dat er geen resultaten worden geretourneerd. Merk op dat dit anders is dan Management Studio, waar je wel de resultaten ziet.
Nadat ik de opgeslagen procedure heb uitgevoerd, krijg ik in de uitvoer niet alleen het plan, maar ik zie ook welke instructies zijn uitgevoerd:
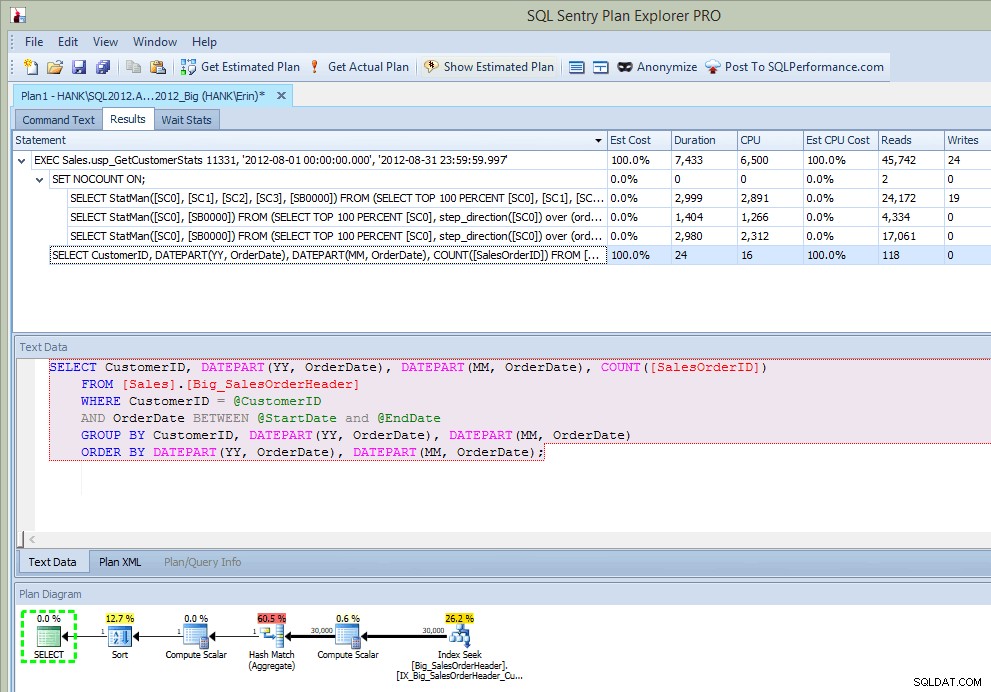
Plan Explorer-uitvoer na uitvoering SP (na invoegen)
Dit is best cool ... naast het zien van de instructie die wordt uitgevoerd in de opgeslagen procedure, zie ik ook de updates voor statistieken, net zoals ik deed toen ik updates vastlegde met Extended Events of SQL Trace. Naast de uitvoering van de instructie kunnen we ook CPU-, duur- en IO-informatie zien. Nu – het voorbehoud hier is dat ik deze informatie kan zien als Ik voer de verklaring uit die de statistische update van Plan Explorer aanroept. Dat zal waarschijnlijk niet vaak gebeuren in uw productieomgeving, maar u kunt dit zien wanneer u aan het testen bent (omdat hopelijk bij uw testen niet alleen SELECT-query's worden uitgevoerd, maar ook INSERT/UPDATE/DELETE-query's, net zoals u zou doen zie bij een normale werkdruk). Als u uw omgeving echter bewaakt met een tool als SQL Sentry, ziet u deze updates mogelijk in Top SQL zolang ze de drempelwaarde voor het verzamelen van Top SQL overschrijden. SQL Sentry heeft standaarddrempels die query's moeten overschrijden voordat ze worden vastgelegd als Top SQL (d.w.z. de duur moet langer zijn dan vijf (5) seconden), maar u kunt deze wijzigen en andere drempels toevoegen, zoals reads. In dit voorbeeld alleen voor testdoeleinden , ik heb mijn drempel voor de minimale duur van Top SQL gewijzigd in 10 milliseconden en mijn leesdrempel in 500, en SQL Sentry kon enkele van de statistische updates vastleggen:
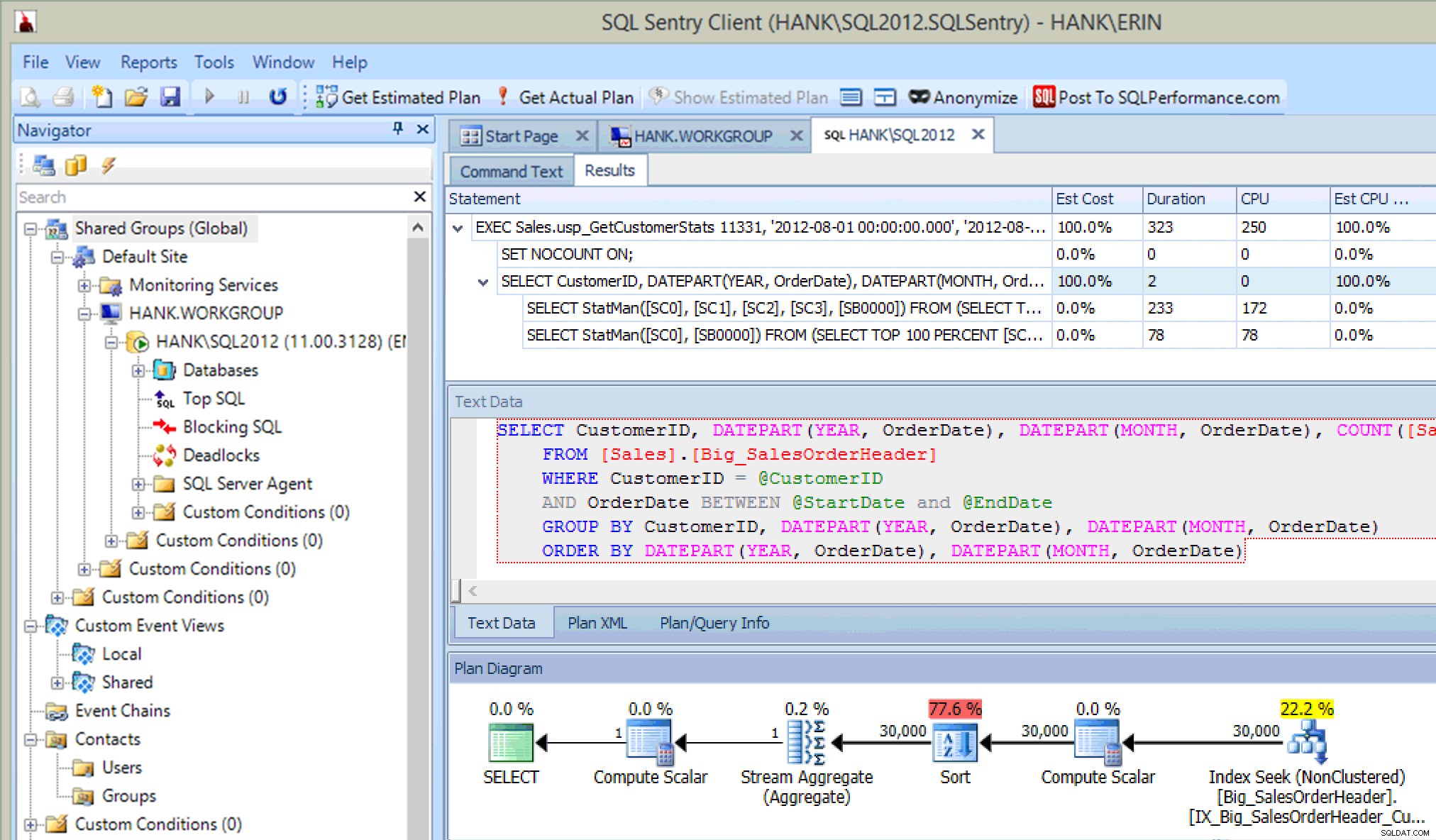
Statistische updates vastgelegd door SQL Sentry
Dat gezegd hebbende, of monitoring deze gebeurtenissen kan vastleggen, zal uiteindelijk afhangen van systeembronnen en de hoeveelheid gegevens die moet worden gelezen om de statistiek bij te werken. Uw statistische updates mogen deze drempels niet overschrijden, dus het kan zijn dat u proactiever moet graven om ze te vinden.
Samenvatting
Ik moedig DBA's altijd aan om statistieken proactief te beheren - wat betekent dat er een taak is om statistieken regelmatig bij te werken. Maar zelfs als die taak elke nacht wordt uitgevoerd (wat ik niet per se aanbeveel), is het nog steeds goed mogelijk dat de statistieken gedurende de dag automatisch worden bijgewerkt, omdat sommige tabellen vluchtiger zijn dan andere en een groot aantal wijzigingen ondergaan. Dit is niet abnormaal, en afhankelijk van de grootte van de tabel en het aantal wijzigingen, zullen de automatische updates de vragen van gebruikers mogelijk niet significant verstoren. Maar de enige manier om erachter te komen is door die updates te volgen – of u nu native tools of tools van derden gebruikt – zodat u potentiële problemen voor kunt blijven en ze kunt oplossen voordat ze escaleren.