Alle moderne databasesystemen ondersteunen een Query Optimizer-module om automatisch de meest efficiënte strategie te identificeren voor het uitvoeren van de SQL-query's. De efficiënte strategie wordt "Plan" genoemd en wordt gemeten in termen van kosten die recht evenredig zijn met "Query-uitvoering / reactietijd". Het plan wordt weergegeven in de vorm van een boomuitvoer van de Query Optimizer. De knooppunten van de planboom kunnen grofweg worden onderverdeeld in de volgende 3 categorieën:
- Knooppunten scannen :Zoals uitgelegd in mijn vorige blog "Een overzicht van de verschillende scanmethoden in PostgreSQL", geeft het aan hoe een basistabelgegevens moeten worden opgehaald.
- Deelnemen aan knooppunten :Zoals uitgelegd in mijn vorige blog "Een overzicht van de JOIN-methoden in PostgreSQL", geeft het aan hoe twee tabellen moeten worden samengevoegd om het resultaat van twee tabellen te krijgen.
- Materialiseringsknooppunten :Ook wel hulpknooppunten genoemd. De vorige twee soorten knooppunten hadden betrekking op het ophalen van gegevens uit een basistabel en het samenvoegen van gegevens die uit twee tabellen zijn opgehaald. De knooppunten in deze categorie worden toegepast bovenop de opgehaalde gegevens om het rapport verder te analyseren of voor te bereiden, enz. b.v. De gegevens sorteren, gegevens verzamelen, enz.
Beschouw een eenvoudig zoekvoorbeeld zoals...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Stel dat er een plan wordt gegenereerd dat overeenkomt met de onderstaande zoekopdracht:
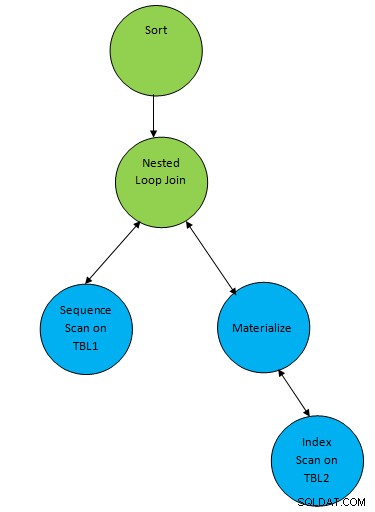
Dus hier wordt een hulpknooppunt "Sorteren" toegevoegd aan het resultaat van join om de gegevens in de vereiste volgorde te sorteren.
Sommige van de hulpknooppunten die door de PostgreSQL-queryoptimalisatie worden gegenereerd, zijn als volgt:
- Sorteren
- Totaal
- Groep op totaal
- Limiet
- Uniek
- LockRows
- SetOp
Laten we elk van deze knooppunten begrijpen.
Sorteren
Zoals de naam al doet vermoeden, wordt dit knooppunt toegevoegd als onderdeel van een planboom wanneer er behoefte is aan gesorteerde gegevens. Gesorteerde gegevens kunnen expliciet of impliciet vereist zijn, zoals in de onderstaande twee gevallen:
Het gebruikersscenario vereist gesorteerde gegevens als uitvoer. In dit geval kan het Sorteerknooppunt bovenop het ophalen van volledige gegevens staan, inclusief alle andere verwerkingen.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Opmerking: Hoewel de gebruiker de uiteindelijke uitvoer in gesorteerde volgorde nodig heeft, wordt het sorteerknooppunt mogelijk niet toegevoegd aan het definitieve plan als er een index is op de overeenkomstige tabel en sorteerkolom. In dit geval kan het indexscan kiezen, wat zal resulteren in een impliciet gesorteerde volgorde van gegevens. Laten we bijvoorbeeld een index maken op het bovenstaande voorbeeld en het resultaat bekijken:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Zoals uitgelegd in mijn vorige blog Een overzicht van de JOIN-methoden in PostgreSQL, vereist Merge Join dat beide tabelgegevens worden gesorteerd voordat ze worden toegevoegd. Het kan dus gebeuren dat Merge Join goedkoper blijkt te zijn dan elke andere join-methode, zelfs met extra sorteerkosten. Dus in dit geval wordt Sort node toegevoegd tussen join en scan-methode van de tabel, zodat gesorteerde records kunnen worden doorgegeven aan de join-methode.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Totaal
Aggregatieknooppunt wordt toegevoegd als onderdeel van een planstructuur als er een aggregatiefunctie is die wordt gebruikt om enkele resultaten van meerdere invoerrijen te berekenen. Enkele van de gebruikte statistische functies zijn COUNT, SUM, AVG (GEMIDDELDE), MAX (MAXIMUM) en MIN (MINIMUM).
Een geaggregeerd knooppunt kan bovenop een basisrelatiescan komen of (en) op het samenvoegen van relaties. Voorbeeld:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Dit soort knooppunten zijn extensies van het “Aggregate” knooppunt. Als aggregatiefuncties worden gebruikt om meerdere invoerrijen te combineren volgens hun groep, dan worden dit soort knooppunten toegevoegd aan een planboom. Dus als de query een aggregatiefunctie heeft die wordt gebruikt en daarnaast is er een GROUP BY-clausule in de query, dan wordt ofwel HashAggregate of GroupAggregate-knooppunt toegevoegd aan de planstructuur.
Aangezien PostgreSQL Cost Based Optimizer gebruikt om een optimale planboom te genereren, is het bijna onmogelijk om te raden welke van deze nodes zal worden gebruikt. Maar laten we begrijpen wanneer en hoe het wordt gebruikt.
HashAggregate
HashAggregate werkt door de hashtabel van de gegevens te bouwen om ze te groeperen. Dus HashAggregate kan worden gebruikt door aggregaat op groepsniveau als het aggregeren plaatsvindt op ongesorteerde dataset.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Hier zijn de schemagegevens van de demo1 tabel zoals in het voorbeeld in de vorige sectie. Aangezien er slechts 1000 rijen zijn om te groeperen, is de benodigde resource voor het maken van een hashtabel lager dan de sorteerkosten. De queryplanner besluit HashAggregate te kiezen.
GroupAggregate
GroupAggregate werkt op gesorteerde gegevens, dus er is geen extra gegevensstructuur voor nodig. GroupAggregate kan worden gebruikt door aggregatie op groepsniveau als de aggregatie zich op een gesorteerde dataset bevindt. Om te groeperen op gesorteerde gegevens, kan het ofwel expliciet sorteren (door Sort node toe te voegen) of het kan werken op gegevens die zijn opgehaald door de index, in welk geval het impliciet wordt gesorteerd.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Hier zijn de schemagegevens van de demo2-tabel zoals in het voorbeeld in de vorige sectie. Aangezien er hier 100000 rijen zijn om te groeperen, kan de bron die nodig is om een hashtabel te bouwen duurder zijn dan de sorteerkosten. Dus de queryplanner besluit GroupAggregate te kiezen. Merk op dat hier de records die zijn geselecteerd uit de tabel "demo2" expliciet zijn gesorteerd en waarvoor een knooppunt is toegevoegd in de planboom.
Zie hieronder een ander voorbeeld, waar reeds gegevens worden opgehaald gesorteerd vanwege indexscan:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Zie hieronder nog een voorbeeld, dat, hoewel het Index Scan heeft, toch expliciet moet worden gesorteerd als de kolom waarop de index daar en de groeperingskolom niet hetzelfde zijn. Het moet dus nog steeds sorteren volgens de groeperingskolom.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Opmerking: GroupAggregate/HashAggregate kan voor veel andere indirecte query's worden gebruikt, hoewel aggregatie met group by niet in de query voorkomt. Het hangt af van hoe de planner de vraag interpreteert. bijv. Stel dat we een duidelijke waarde uit de tabel moeten halen, dan kan deze worden gezien als een groep door de corresponderende kolom en neem dan één waarde uit elke groep.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Dus hier wordt HashAggregate gebruikt, ook al is er geen aggregatie en groeperen bij betrokken.
Limiet
Limietknooppunten worden toegevoegd aan de planstructuur als de “limit/offset”-clausule wordt gebruikt in de SELECT-query. Deze clausule wordt gebruikt om het aantal rijen te beperken en optioneel een offset te geven om te beginnen met het lezen van gegevens. Voorbeeld hieronder:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Uniek
Dit knooppunt wordt geselecteerd om een onderscheidende waarde te krijgen van het onderliggende resultaat. Houd er rekening mee dat, afhankelijk van de query, selectiviteit en andere informatie over bronnen, de distinct-waarde kan worden opgehaald met HashAggregate/GroupAggregate, ook zonder Unique node te gebruiken. Voorbeeld:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL biedt functionaliteit om alle geselecteerde rijen te vergrendelen. Rijen kunnen worden geselecteerd in de modus "Gedeeld" of "Exclusief", afhankelijk van respectievelijk de clausules "FOR SHARE" en "FOR UPDATE". Een nieuw knooppunt "LockRows" wordt toegevoegd aan de planboom om deze bewerking uit te voeren.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL biedt functionaliteit om de resultaten van twee of meer zoekopdrachten te combineren. Dus als het type Join-knooppunt wordt geselecteerd om twee tabellen samen te voegen, wordt een vergelijkbaar type SetOp-knooppunt geselecteerd om de resultaten van twee of meer query's te combineren. Beschouw bijvoorbeeld een tabel met werknemers met hun id, naam, leeftijd en hun salaris zoals hieronder:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Laten we nu werknemers nemen die ouder zijn dan 25 jaar:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Laten we nu werknemers krijgen met een salaris van meer dan 95 miljoen:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Om nu werknemers met een leeftijd van meer dan 25 jaar en een salaris van meer dan 95M te krijgen, kunnen we de onderstaande intersect-query schrijven:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Dus hier wordt een nieuw soort knooppunt HashSetOp toegevoegd om het snijpunt van deze twee afzonderlijke zoekopdrachten te evalueren.
Merk op dat er hier twee andere soorten nieuwe nodes zijn toegevoegd:
Toevoegen
Dit knooppunt wordt toegevoegd om meerdere resultatensets in één te combineren.
Subqueryscan
Dit knooppunt wordt toegevoegd om elke subquery te evalueren. In het bovenstaande plan wordt de subquery toegevoegd om één extra constante kolomwaarde te evalueren die aangeeft welke invoerset een specifieke rij heeft bijgedragen.
HashedSetop werkt met de hash van het onderliggende resultaat, maar het is mogelijk om op Sorteren gebaseerde SetOp-bewerkingen te genereren door de query-optimizer. Op sorteren gebaseerd Setop-knooppunt wordt aangeduid als "Setop".
Opmerking:het is mogelijk om hetzelfde resultaat te bereiken als in het bovenstaande resultaat met een enkele zoekopdracht, maar hier wordt het weergegeven met intersect, alleen voor een eenvoudige demonstratie.
Conclusie
Alle knooppunten van PostgreSQL zijn nuttig en worden geselecteerd op basis van de aard van de query, gegevens, enz. Veel van de clausules zijn één op één toegewezen met knooppunten. Voor sommige clausules zijn er meerdere opties voor knooppunten, die worden bepaald op basis van de onderliggende gegevenskostenberekeningen.