Iemand heeft per ongeluk een deel van de database verwijderd. Iemand is vergeten een WHERE-component in een DELETE-query op te nemen, of ze hebben de verkeerde tabel laten vallen. Dat soort dingen kunnen en zullen gebeuren, het is onvermijdelijk en menselijk. Maar de impact kan desastreus zijn. Wat kunt u doen om uzelf tegen dergelijke situaties te beschermen en hoe kunt u uw gegevens herstellen? In deze blogpost bespreken we enkele van de meest typische gevallen van gegevensverlies en hoe u zich kunt voorbereiden zodat u hiervan kunt herstellen.
Voorbereidingen
Er zijn dingen die u moet doen om een soepel herstel te garanderen. Laten we ze doornemen. Houd er rekening mee dat het geen "kies één" situatie is - idealiter implementeert u alle maatregelen die we hieronder gaan bespreken.
Back-up
Je moet een back-up hebben, er is geen ontkomen aan. U moet uw back-upbestanden laten testen - tenzij u uw back-ups test, weet u niet zeker of ze goed zijn en of u ze ooit kunt herstellen. Voor noodherstel moet u een kopie van uw back-up ergens buiten uw datacenter bewaren - voor het geval dat het hele datacenter niet meer beschikbaar is. Om het herstel te versnellen, is het erg handig om een kopie van de back-up ook op de databaseknooppunten te bewaren. Als uw dataset groot is, kan het kopiëren over het netwerk van een back-upserver naar het databaseknooppunt dat u wilt herstellen veel tijd in beslag nemen. Het lokaal bewaren van de nieuwste back-up kan de hersteltijden aanzienlijk verbeteren.
Logische back-up
Uw eerste back-up zal hoogstwaarschijnlijk een fysieke back-up zijn. Voor MySQL of MariaDB zal het iets zijn als xtrabackup of een soort snapshot van het bestandssysteem. Dergelijke back-ups zijn geweldig voor het herstellen van een hele dataset of voor het inrichten van nieuwe nodes. In het geval van verwijdering van een subset van gegevens, lijden ze echter aan aanzienlijke overhead. Allereerst kunt u niet alle gegevens herstellen, anders overschrijft u alle wijzigingen die zijn aangebracht nadat de back-up is gemaakt. Wat u zoekt, is de mogelijkheid om slechts een subset van gegevens te herstellen, alleen de rijen die per ongeluk zijn verwijderd. Om dat te doen met een fysieke back-up, moet u deze op een afzonderlijke host herstellen, verwijderde rijen lokaliseren, ze dumpen en ze vervolgens terugzetten op het productiecluster. Het kopiëren en herstellen van honderden gigabytes aan gegevens om een handvol rijen te herstellen, is iets dat we zeker een aanzienlijke overhead zouden noemen. Om dit te vermijden, kunt u logische back-ups gebruiken - in plaats van fysieke gegevens op te slaan, slaan dergelijke back-ups gegevens op in tekstformaat. Dit maakt het gemakkelijker om de exacte gegevens die zijn verwijderd te lokaliseren, die vervolgens direct op het productiecluster kunnen worden hersteld. Om het nog gemakkelijker te maken, kunt u zo'n logische back-up ook in delen splitsen en elke tabel naar een apart bestand back-uppen. Als uw dataset groot is, is het logisch om één enorm tekstbestand zoveel mogelijk te splitsen. Dit maakt de back-up inconsistent, maar in de meeste gevallen is dit geen probleem - als u de hele dataset naar een consistente staat moet herstellen, gebruikt u fysieke back-up, wat in dit opzicht veel sneller is. Als u slechts een subset van gegevens hoeft te herstellen, zijn de vereisten voor consistentie minder streng.
Point-In-Time Recovery
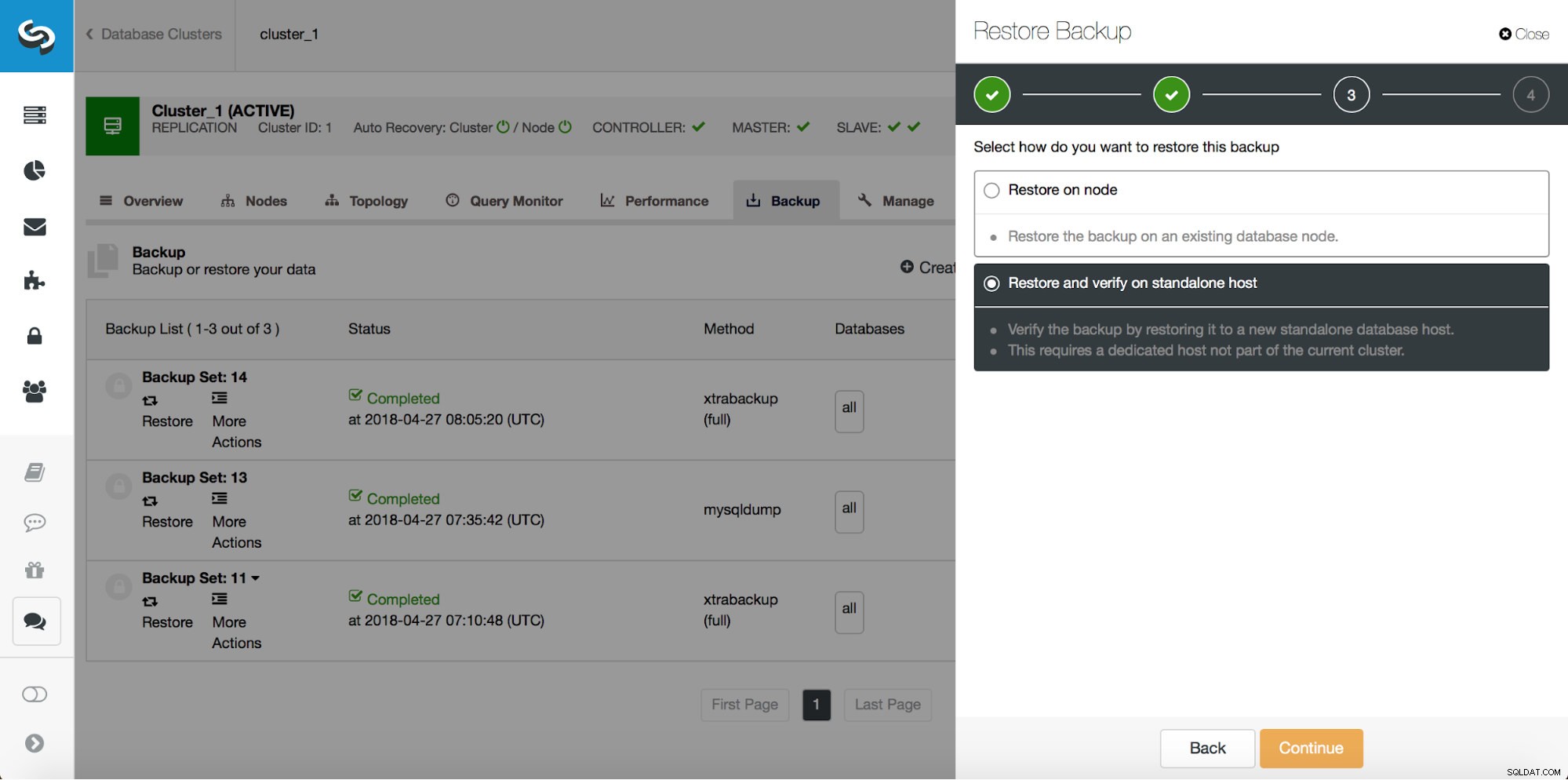
Back-up is slechts een begin - u kunt uw gegevens herstellen tot het punt waarop de back-up werd gemaakt, maar hoogstwaarschijnlijk werden de gegevens daarna verwijderd. Alleen al door ontbrekende gegevens van de laatste back-up te herstellen, kunt u alle gegevens kwijtraken die na de back-up zijn gewijzigd. Om dat te voorkomen moet u Point-In-Time Recovery implementeren. Voor MySQL betekent dit in feite dat u binaire logboeken moet gebruiken om alle wijzigingen af te spelen die zijn gebeurd tussen het moment van de back-up en het gegevensverlies. De onderstaande schermafbeelding laat zien hoe ClusterControl daarbij kan helpen.
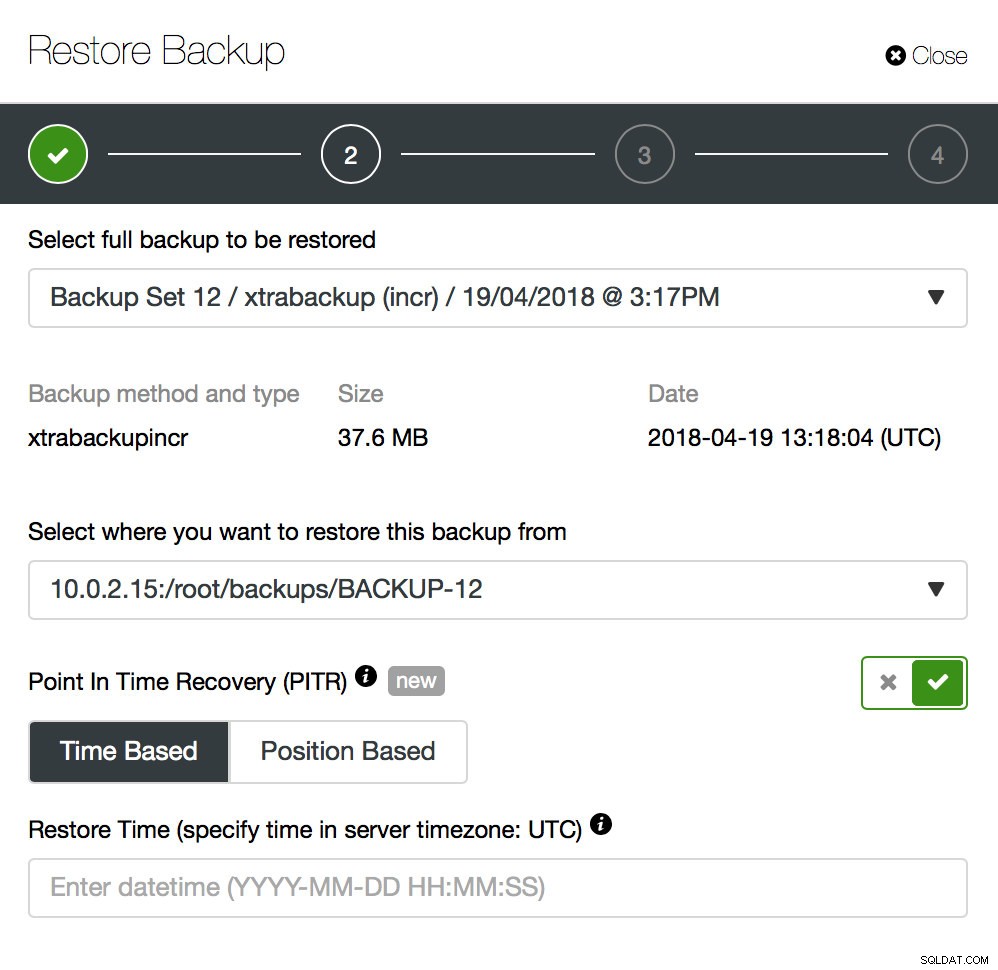
Wat u moet doen, is deze back-up terugzetten tot het moment net voor het gegevensverlies. U moet het op een afzonderlijke host herstellen om geen wijzigingen aan te brengen in het productiecluster. Zodra u de back-up hebt hersteld, kunt u inloggen op die host, de ontbrekende gegevens vinden, deze dumpen en terugzetten op het productiecluster.
Vertraagde slaaf
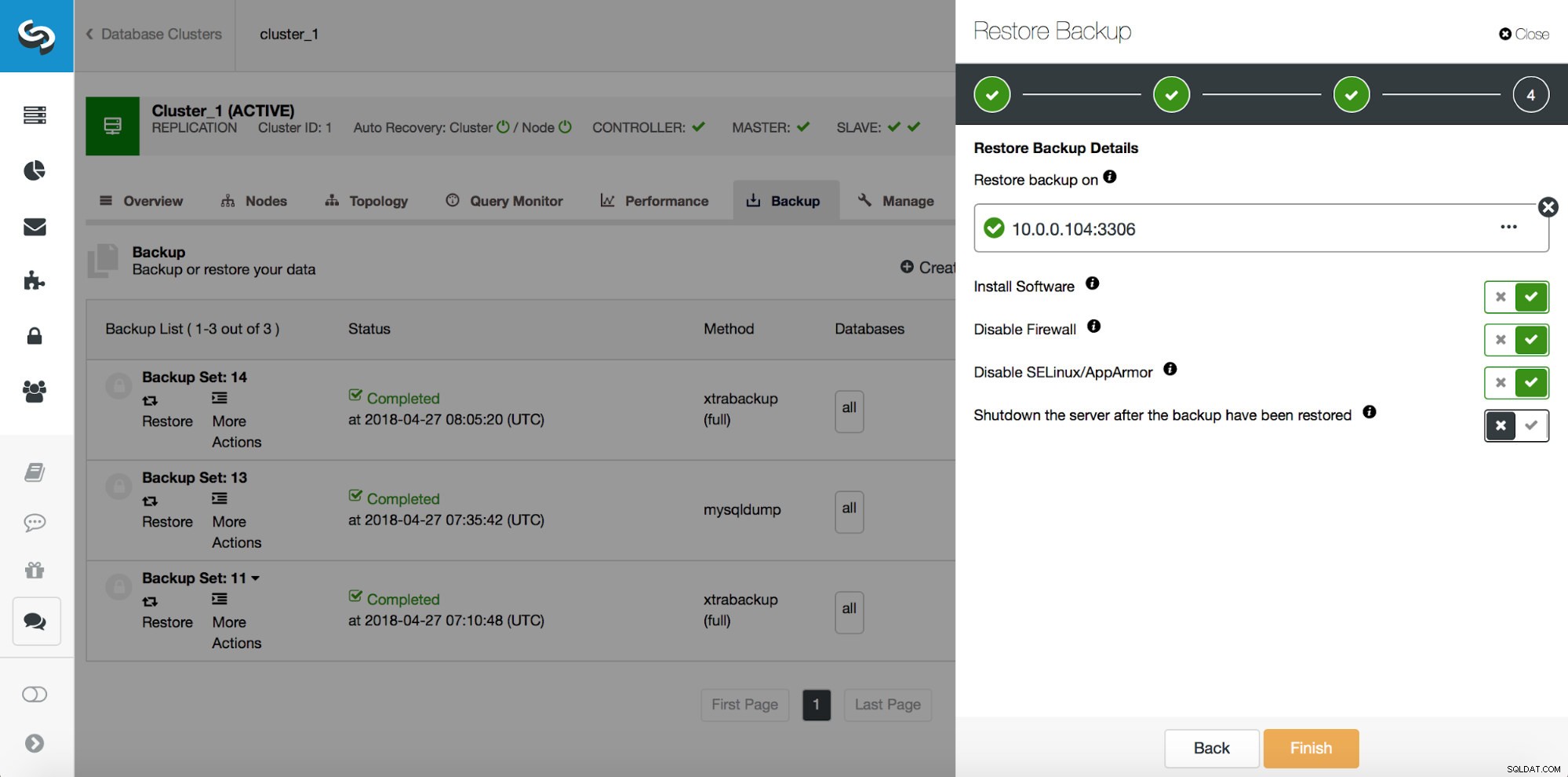
Alle methoden die we hierboven hebben besproken, hebben één gemeenschappelijk pijnpunt:het kost tijd om de gegevens te herstellen. Het kan langer duren als u alle gegevens herstelt en vervolgens alleen het interessante deel probeert te dumpen. Het kan minder tijd kosten als u een logische back-up hebt en u snel kunt inzoomen op de gegevens die u wilt herstellen, maar het is geenszins een snelle taak. Je moet nog een paar rijen vinden in een groot tekstbestand. Hoe groter het is, hoe ingewikkelder de taak wordt - soms vertraagt de enorme omvang van het bestand alle acties. Een methode om die problemen te vermijden is om een vertraagde slaaf te hebben. Slaven proberen meestal op de hoogte te blijven van de master, maar het is ook mogelijk om ze zo te configureren dat ze afstand houden van hun master. In de onderstaande schermafbeelding kunt u zien hoe u ClusterControl kunt gebruiken om zo'n slave in te zetten:
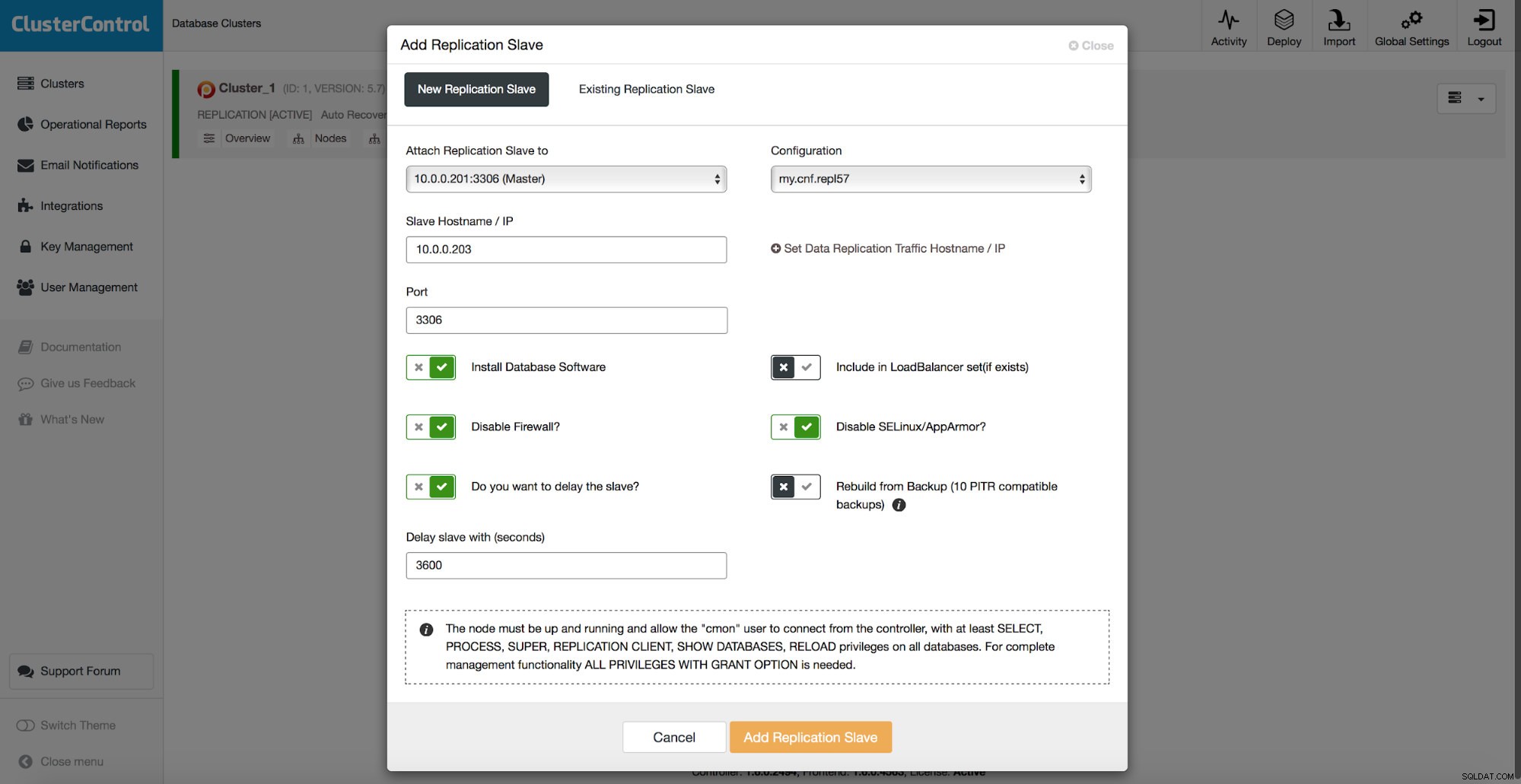
Kortom, we hebben hier een optie om een replicatieslave toe te voegen aan de database-setup en deze te configureren om vertraagd te worden. In de bovenstaande schermafbeelding wordt de slave met 3600 seconden vertraagd, wat een uur is. Hierdoor kunt u die slave gebruiken om de verwijderde gegevens tot een uur na het verwijderen van de gegevens te herstellen. U hoeft geen back-up te herstellen, het is voldoende om mysqldump of SELECT ... INTO OUTFILE uit te voeren voor de ontbrekende gegevens en u krijgt de gegevens om te herstellen op uw productiecluster.
Gegevens herstellen
In deze sectie zullen we een aantal voorbeelden doornemen van het per ongeluk verwijderen van gegevens en hoe u deze kunt herstellen. We zullen het herstel van een volledig gegevensverlies doorlopen, we zullen ook laten zien hoe u kunt herstellen van een gedeeltelijk gegevensverlies bij het gebruik van fysieke en logische back-ups. We zullen je eindelijk laten zien hoe je per ongeluk verwijderde rijen kunt herstellen als je een vertraagde slave in je setup hebt.
Volledig gegevensverlies
Toevallige “rm -rf” of “DROP SCHEMA myonlyschema;” is uitgevoerd en u heeft helemaal geen gegevens meer. Als u toevallig ook andere bestanden verwijdert dan uit de MySQL-gegevensdirectory, moet u mogelijk de host opnieuw inrichten. Om het eenvoudiger te houden, gaan we ervan uit dat alleen MySQL is getroffen. Laten we twee gevallen bekijken, met een vertraagde slaaf en zonder.
Geen vertraagde slaaf
In dit geval is het enige wat we kunnen doen de laatste fysieke back-up terugzetten. Aangezien al onze gegevens zijn verwijderd, hoeven we ons geen zorgen te maken over activiteiten die plaatsvonden na het gegevensverlies, want zonder gegevens is er geen activiteit. We zouden ons zorgen moeten maken over de activiteit die plaatsvond nadat de back-up plaatsvond. Dit betekent dat we een Point-in-Time restore moeten doen. Natuurlijk duurt het langer dan alleen gegevens herstellen vanaf de back-up. Als het belangrijker is om uw database snel te openen dan om alle gegevens te herstellen, kunt u net zo goed een back-up terugzetten en er geen probleem mee hebben.
Allereerst, als je nog toegang hebt tot binaire logs op de server die je wilt herstellen, kun je ze gebruiken voor PITR. Eerst willen we het relevante deel van de binaire logs converteren naar een tekstbestand voor verder onderzoek. We weten dat er gegevens verloren zijn gegaan na 13:00:00 uur. Laten we eerst eens kijken welk binlog-bestand we moeten onderzoeken:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Zoals te zien is, zijn we geïnteresseerd in het laatste binlog-bestand.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outAls we klaar zijn, gaan we eens kijken naar de inhoud van dit bestand. We zoeken in vim naar ‘drop schema’. Hier is een relevant deel van het bestand:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Zoals we kunnen zien, willen we herstellen tot positie 320358785. We kunnen deze gegevens doorgeven aan de gebruikersinterface van ClusterControl:
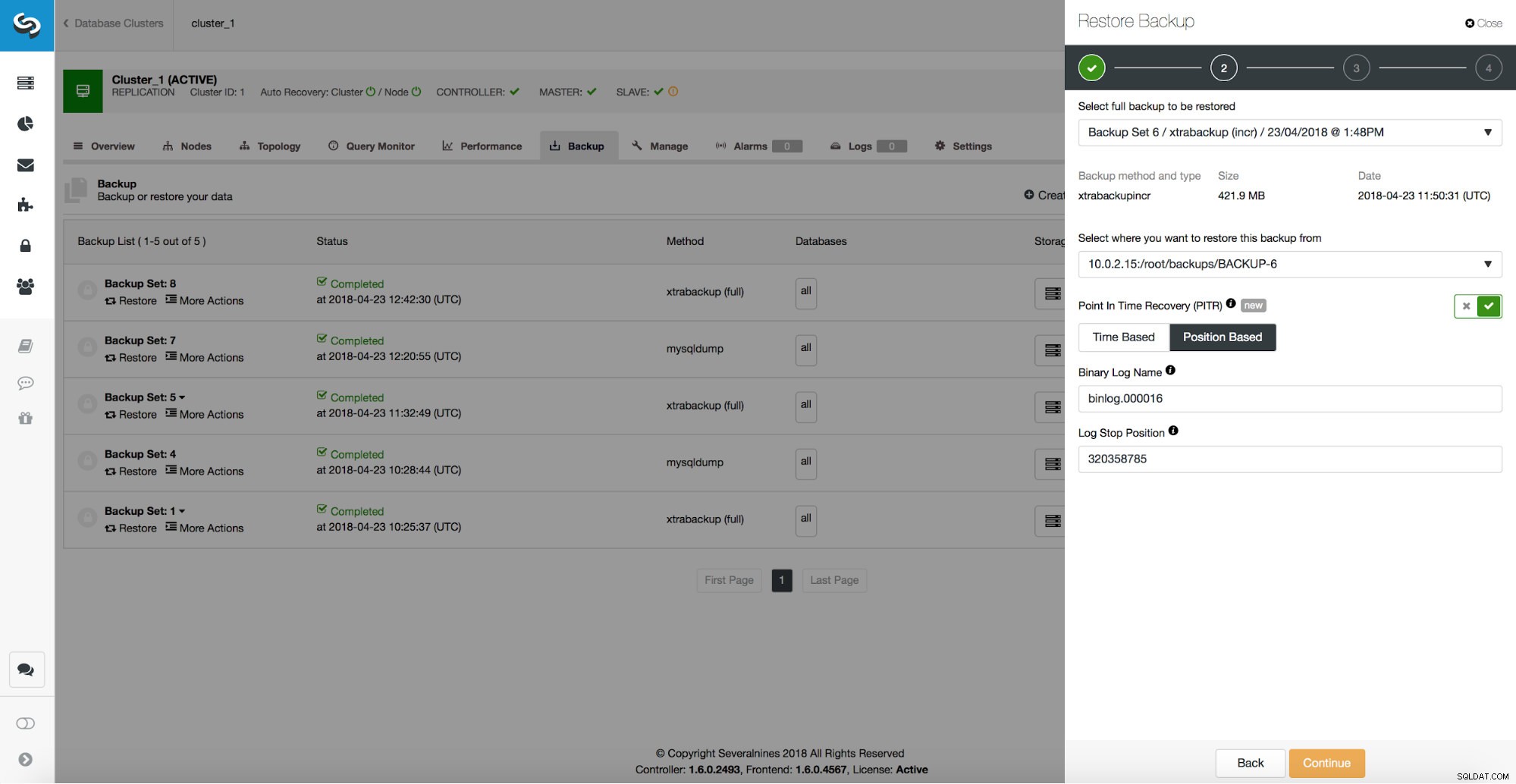
Vertraagde slaaf
Als we een vertraagde slave hebben en die host is genoeg om al het verkeer af te handelen, dan kunnen we hem gebruiken en promoveren tot master. Maar eerst moeten we ervoor zorgen dat het de oude meester heeft ingehaald tot het punt van het gegevensverlies. We zullen hier wat CLI gebruiken om het voor elkaar te krijgen. Eerst moeten we uitzoeken op welke positie het gegevensverlies heeft plaatsgevonden. Dan stoppen we de slaaf en laten we hem naar de gebeurtenis voor gegevensverlies lopen. We hebben in de vorige sectie laten zien hoe u de juiste positie kunt krijgen - door binaire logbestanden te onderzoeken. We kunnen die positie gebruiken (binlog.000016, positie 320358785) of, als we een multithreaded slave gebruiken, moeten we GTID van de gebeurtenis voor gegevensverlies gebruiken (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) en query's opnieuw afspelen tot die GTID.
Laten we eerst de slave stoppen en de vertraging uitschakelen:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Dan kunnen we het starten tot een bepaalde binaire logpositie.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Als we GTID willen gebruiken, ziet de opdracht er anders uit:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Zodra de replicatie is gestopt (wat betekent dat alle gebeurtenissen waar we om hebben gevraagd zijn uitgevoerd), moeten we controleren of de host de ontbrekende gegevens bevat. Als dat zo is, kun je het promoveren tot master en vervolgens andere hosts herbouwen met de nieuwe master als gegevensbron.
Dit is niet altijd de beste optie. Alles hangt af van hoe vertraagd je slave is - als hij een paar uur vertraging heeft, heeft het misschien geen zin om te wachten tot hij zijn achterstand inhaalt, vooral als er veel schrijfverkeer is in je omgeving. In dat geval is het waarschijnlijk sneller om hosts opnieuw op te bouwen met behulp van fysieke back-up. Aan de andere kant, als je een vrij klein verkeersvolume hebt, kan dit een leuke manier zijn om het probleem snel op te lossen, een nieuwe master te promoten en door te gaan met het bedienen van verkeer, terwijl de rest van de knooppunten op de achtergrond worden herbouwd .
Gedeeltelijk gegevensverlies - fysieke back-up
In het geval van gedeeltelijk gegevensverlies kunnen fysieke back-ups inefficiënt zijn, maar aangezien dit het meest voorkomende type back-up is, is het erg belangrijk om te weten hoe u ze kunt gebruiken voor gedeeltelijk herstel. De eerste stap zal altijd zijn om een back-up te herstellen tot een tijdstip vóór het gegevensverlies. Het is ook erg belangrijk om het op een aparte host te herstellen. ClusterControl gebruikt xtrabackup voor fysieke back-ups, dus we zullen laten zien hoe het te gebruiken. Laten we aannemen dat we de volgende onjuiste zoekopdracht hebben uitgevoerd:
DELETE FROM sbtest1 WHERE id < 23146;
We wilden slechts een enkele rij verwijderen ('=' in de WHERE-clausule), in plaats daarvan hebben we er een aantal verwijderd (
Laten we nu naar het uitvoerbestand kijken en kijken wat we daar kunnen vinden. We gebruiken replicatie op basis van rijen, daarom zien we niet de exacte SQL die is uitgevoerd. In plaats daarvan (zolang we --verbose flag gebruiken voor mysqlbinlog) zullen we gebeurtenissen zien zoals hieronder:
Zoals te zien is, identificeert MySQL rijen die moeten worden verwijderd met behulp van een zeer nauwkeurige WHERE-voorwaarde. Mysterieuze tekens in het voor mensen leesbare commentaar, "@1", "@2", betekenen "eerste kolom", "tweede kolom". We weten dat de eerste kolom 'id' is, iets waar we in geïnteresseerd zijn. We moeten een grote DELETE-gebeurtenis vinden op een 'sbtest1'-tabel. Opmerkingen die zullen volgen, moeten id van 1 vermelden, dan id van '2', dan '3' enzovoort - allemaal tot id van '23145'. Alles moet worden uitgevoerd in een enkele transactie (enkele gebeurtenis in een binair logboek). Na analyse van de uitvoer met 'minder', vonden we:
Het evenement, waaraan deze opmerkingen zijn toegevoegd, begon om:
Dus we willen de back-up terugzetten naar de vorige commit op positie 29600687. Laten we dat nu doen. Daarvoor gebruiken we een externe server. We zullen de back-up terugzetten naar die positie en we houden de herstelserver actief zodat we later de ontbrekende gegevens kunnen extraheren.
Zodra het herstel is voltooid, laten we ervoor zorgen dat onze gegevens zijn hersteld:
Ziet er goed uit. Nu kunnen we deze gegevens extraheren in een bestand dat we terug zullen laden op de master.
Er klopt iets niet - dit komt omdat de server is geconfigureerd om alleen bestanden op een bepaalde locatie te kunnen schrijven - het draait allemaal om beveiliging, we willen niet dat gebruikers inhoud opslaan waar ze maar willen. Laten we eens kijken waar we ons bestand kunnen opslaan:
Oké, laten we het nog een keer proberen:
Nu ziet het er veel beter uit. Laten we de gegevens naar de master kopiëren:
Nu is het tijd om de ontbrekende rijen op de master te laden en te testen of het gelukt is:
Dat is alles, we hebben onze ontbrekende gegevens hersteld.
In het vorige gedeelte hebben we verloren gegevens hersteld met behulp van fysieke back-up en een externe server. Wat als we een logische back-up hadden gemaakt? Laten we kijken. Laten we eerst controleren of we een logische back-up hebben:
Ja, het is er. Nu is het tijd om het te decomprimeren.
Als je erin kijkt, zul je zien dat de gegevens zijn opgeslagen in INSERT-indeling met meerdere waarden. Bijvoorbeeld:
Het enige dat we nu moeten doen, is bepalen waar onze tabel zich bevindt en vervolgens waar de rijen die voor ons van belang zijn, worden opgeslagen. Laten we eerst, als we mysqldump-patronen kennen (tabel neerzetten, nieuwe maken, indexen uitschakelen, gegevens invoegen), uitzoeken welke regel de CREATE TABLE-instructie voor de tabel 'sbtest1' bevat:
Nu, met behulp van een methode van vallen en opstaan, moeten we uitzoeken waar we onze rijen moeten zoeken. We laten je de laatste opdracht zien die we hebben bedacht. De hele truc is om te proberen verschillende reeksen regels af te drukken met sed en vervolgens te controleren of de laatste regel rijen bevat die dicht bij, maar later zijn dan waar we naar zoeken. In het onderstaande commando zoeken we naar regels tussen 971 (CREATE TABLE) en 993. We vragen sed ook om te stoppen zodra het regel 994 bereikt, omdat de rest van het bestand voor ons niet interessant is:
De uitvoer ziet er als volgt uit:
Dit betekent dat ons rijbereik (tot rij met id van 23145) dichtbij is. Vervolgens draait het allemaal om het handmatig opschonen van het bestand. We willen dat het begint met de eerste rij die we moeten herstellen:
En eindig met de laatste rij om te herstellen:
We moesten enkele onnodige gegevens bijsnijden (het is een invoeging van meerdere regels) maar na dit alles hebben we een bestand dat we terug kunnen laden op de master.
Eindelijk, laatste controle:
Alles is goed, gegevens zijn hersteld.
In dit geval zullen we niet het hele proces doorlopen. We hebben al beschreven hoe u de positie van een gegevensverliesgebeurtenis in de binaire logboeken kunt identificeren. We hebben ook beschreven hoe u een vertraagde slave kunt stoppen en de replicatie opnieuw kunt starten, tot een punt vóór het gegevensverlies. We hebben ook uitgelegd hoe u SELECT INTO OUTFILE en LOAD DATA INFILE kunt gebruiken om gegevens van een externe server te exporteren en op de master te laden. Dat is alles wat je nodig hebt. Zolang de gegevens nog op de vertraagde slave staan, moet je deze stoppen. Vervolgens moet u de positie vóór de gegevensverliesgebeurtenis lokaliseren, de slave tot dat punt starten en, zodra dit is gebeurd, de vertraagde slave gebruiken om de verwijderde gegevens te extraheren, het bestand naar de master kopiëren en het laden om de gegevens te herstellen .
Het herstellen van verloren gegevens is niet leuk, maar als je de stappen volgt die we in deze blog hebben doorlopen, heb je een goede kans om te herstellen wat je bent kwijtgeraakt.mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826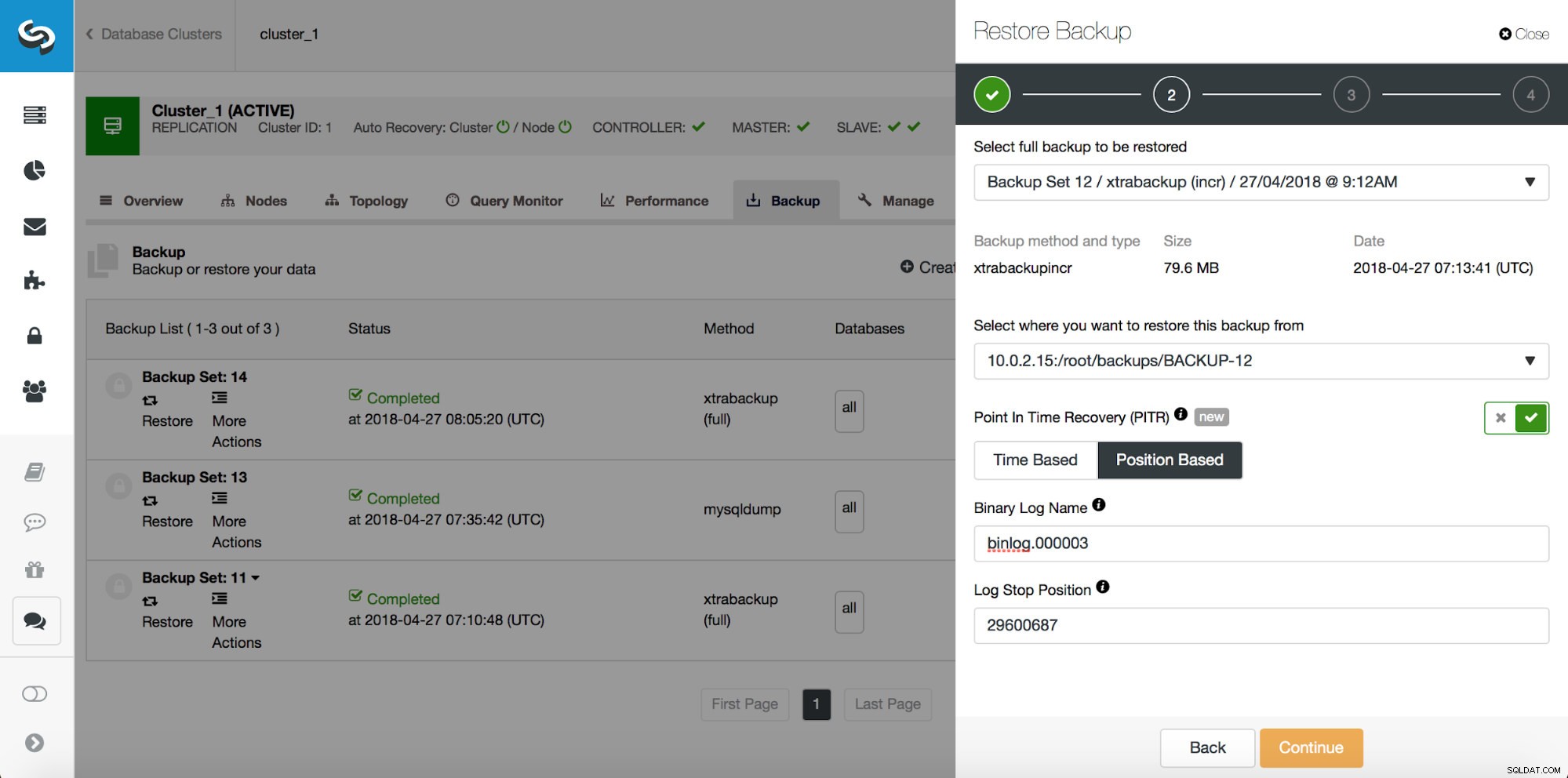
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Gedeeltelijk gegevensverlies - logische back-up
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Gedeeltelijk gegevensverlies, vertraagde slave
Conclusie