In de vorige blog in de serie hebben we de voor- en nadelen besproken van het gebruik van Galera Cluster om een geo-gedistribueerde cluster te maken. In dit bericht zullen we een op Galera gebaseerd geo-gedistribueerd cluster ontwerpen en laten we zien hoe u alle vereiste onderdelen kunt implementeren met ClusterControl.
Een geo-gedistribueerde Galera-cluster ontwerpen
We beginnen met het uitleggen van de omgeving die we willen bouwen. We zullen drie externe datacenters gebruiken, verbonden via Wide Area Network (WAN). Elk datacenter ontvangt schrijfbewerkingen van lokale applicatieservers. Lezingen zullen ook alleen lokaal zijn. Dit is bedoeld om te voorkomen dat onnodig verkeer het WAN oversteekt.
Voor deze opstelling is de connectiviteit aanwezig en beveiligd, maar we zullen niet precies beschrijven hoe dit kan worden bereikt. Er zijn tal van methoden om de connectiviteit te beveiligen, beginnend bij propriëtaire hardware- en softwareoplossingen via OpenVPN en eindigend op SSH-tunnels.
We zullen ProxySQL gebruiken als loadbalancer. ProxySQL wordt lokaal in elk datacenter geïmplementeerd. Het zal ook het verkeer alleen naar de lokale knooppunten leiden. Remote nodes kunnen altijd handmatig worden toegevoegd en we zullen gevallen uitleggen waarin dit een goede oplossing kan zijn. De toepassing kan worden geconfigureerd om verbinding te maken met een van de lokale ProxySQL-knooppunten met behulp van een round-robin-algoritme. We kunnen net zo goed Keepalived en Virtual IP gebruiken om het verkeer naar het enkele ProxySQL-knooppunt te leiden, zolang een enkel ProxySQL-knooppunt al het verkeer zou kunnen verwerken.
Een andere mogelijke oplossing is om ProxySQL samen te voegen met applicatieknooppunten en de applicatie te configureren om verbinding te maken met de proxy op de localhost. Deze aanpak werkt redelijk goed in de veronderstelling dat het onwaarschijnlijk is dat ProxySQL niet beschikbaar zal zijn, maar dat de toepassing goed zou werken op hetzelfde knooppunt. Wat we meestal zien, is ofwel een knooppuntstoring ofwel een netwerkstoring, wat zowel ProxySQL als de applicatie tegelijkertijd zou beïnvloeden.
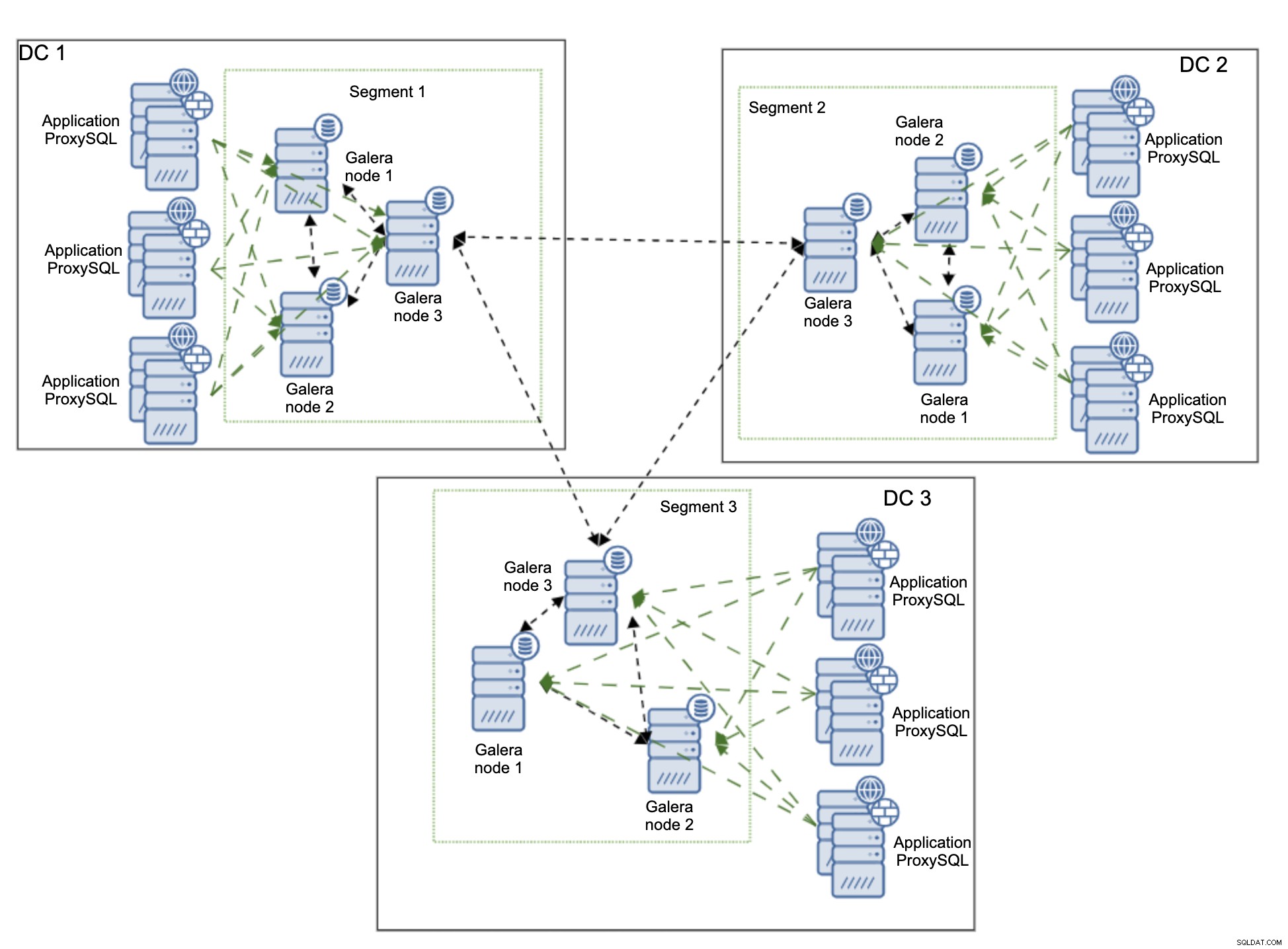
Het bovenstaande diagram toont de versie van de omgeving, waarop ProxySQL is geplaatst hetzelfde knooppunt als de toepassing. ProxySQL is geconfigureerd om de werklast te verdelen over alle Galera-knooppunten in het lokale datacenter. Een van die knooppunten zou worden gekozen als een knooppunt om de schrijfacties naar te verzenden, terwijl SELECT's over alle knooppunten zouden worden verdeeld. Het hebben van één dedicated writer-node in een datacenter helpt het aantal mogelijke certificeringsconflicten te verminderen, wat doorgaans leidt tot betere prestaties. Om dit nog verder te verminderen, zouden we het verkeer via de WAN-verbinding moeten gaan verzenden, wat niet ideaal is omdat het bandbreedtegebruik aanzienlijk zou toenemen. Op dit moment, met segmenten op hun plaats, worden er slechts twee exemplaren van de schrijfset verzonden over datacenters - één per DC.
De grootste zorg bij geo-gedistribueerde implementaties van Galera Cluster is latentie. Dit is iets dat je altijd moet testen voordat je de omgeving opstart. Ben ik ok met de commit tijd? Bij elke commit moet certificering plaatsvinden, dus schrijfsets moeten worden verzonden en gecertificeerd op alle knooppunten in het cluster, inclusief externe. Het kan zijn dat de hoge latentie de setup ongeschikt maakt voor uw toepassing. In dat geval zijn meerdere Galera-clusters die via asynchrone replicatie zijn verbonden wellicht geschikter. Dit zou echter een onderwerp zijn voor een andere blogpost.
Een geo-gedistribueerde Galera-cluster implementeren met ClusterControl
Om zaken te verduidelijken, laten we hier zien hoe een implementatie eruit kan zien. We zullen geen echte multi-DC-configuratie gebruiken, alles wordt geïmplementeerd in een lokaal laboratorium. We gaan ervan uit dat de latentie acceptabel is en dat de hele setup levensvatbaar is. Het mooie van ClusterControl is dat het infrastructuur-agnostisch is. Het maakt niet uit of de nodes dicht bij elkaar staan, zich in hetzelfde datacenter bevinden of dat de nodes over meerdere cloudproviders zijn verdeeld. Zolang er SSH-connectiviteit is van de ClusterControl-instantie naar alle knooppunten, ziet het implementatieproces er precies hetzelfde uit. Daarom kunnen we het je stap voor stap laten zien met alleen een lokaal lab.
ClusterControl installeren
Eerst moet u ClusterControl installeren. Je kunt het gratis downloaden. Na registratie moet u naar de pagina gaan met een handleiding om ClusterControl te downloaden en te installeren. Het is net zo eenvoudig als het uitvoeren van een shellscript. Zodra u ClusterControl hebt geïnstalleerd, krijgt u een formulier te zien om een beheerder aan te maken:
Zodra je het hebt ingevuld, krijg je een welkomstscherm en toegang naar implementatiewizards:
We gaan voor implementeren. Dit opent een implementatiewizard:
We zullen MySQL Galera kiezen. We moeten SSH-connectiviteitsdetails doorgeven - ofwel root-gebruiker of sudo-gebruiker wordt ondersteund. Bij de volgende stap moeten we servers in het cluster definiëren.
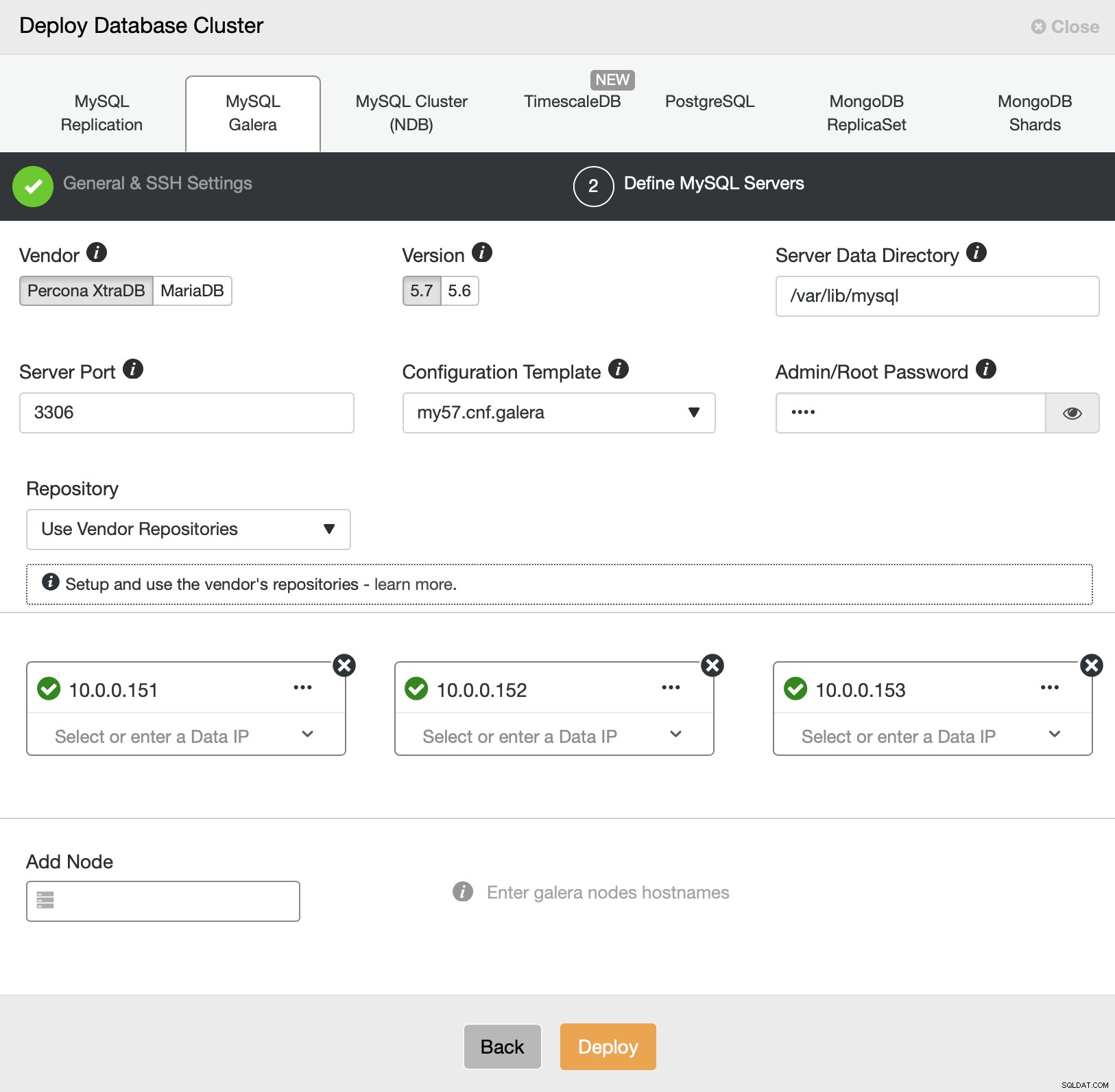
We gaan drie nodes implementeren in een van de datacenters. Dan kunnen we het cluster uitbreiden door nieuwe nodes in verschillende segmenten te configureren. Voorlopig hoeven we alleen maar op "Deploy" te klikken en te kijken hoe ClusterControl het Galera-cluster implementeert.
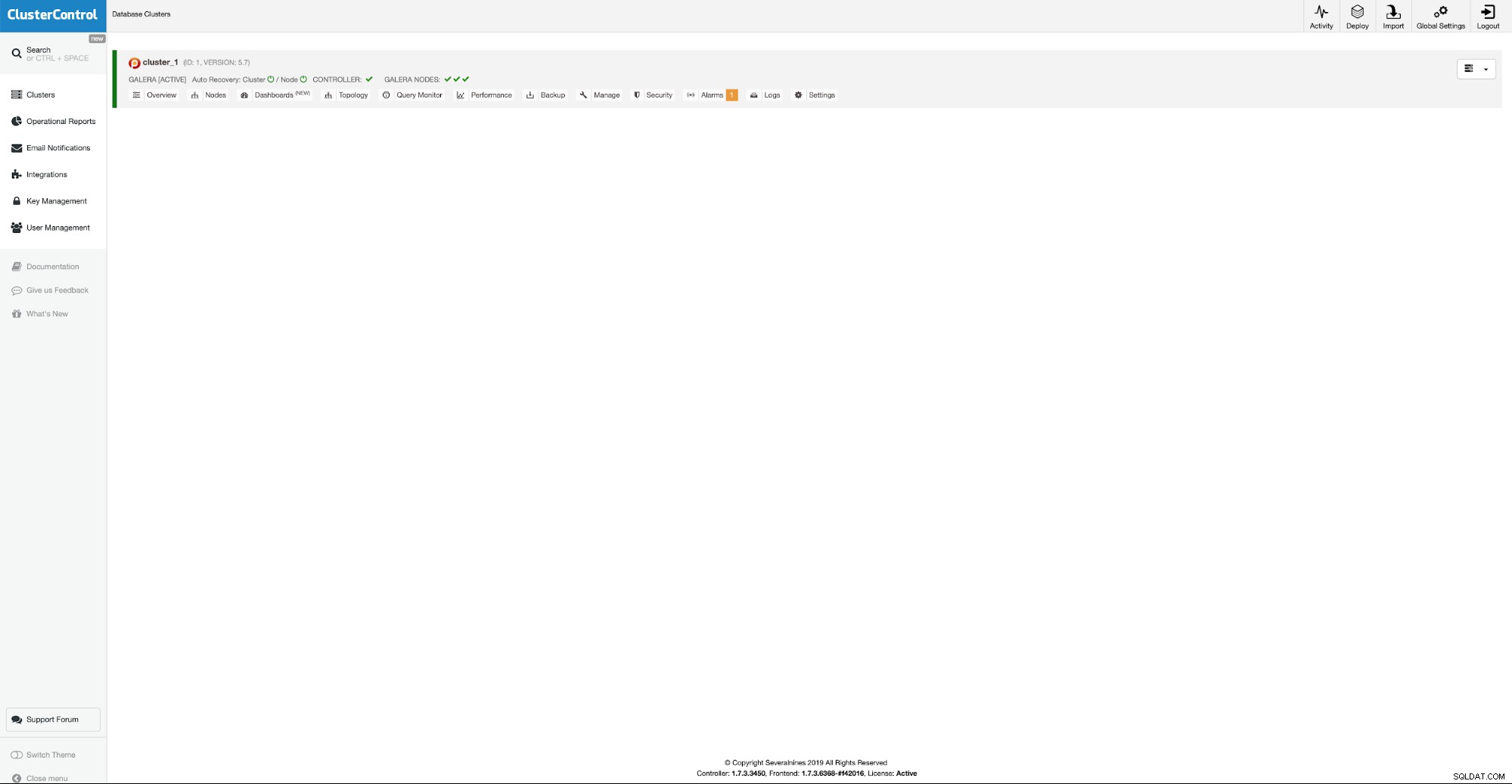
Onze eerste drie knooppunten zijn operationeel, we kunnen nu doorgaan met het toevoegen extra nodes in andere datacenters.
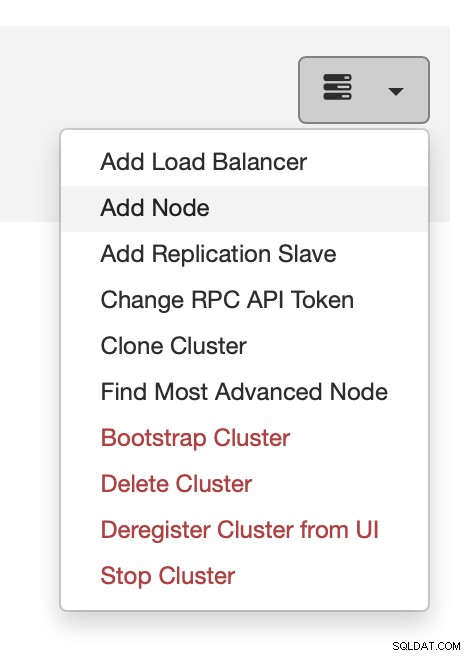
U kunt dat doen vanuit het actiemenu, zoals weergegeven in de bovenstaande schermafbeelding .
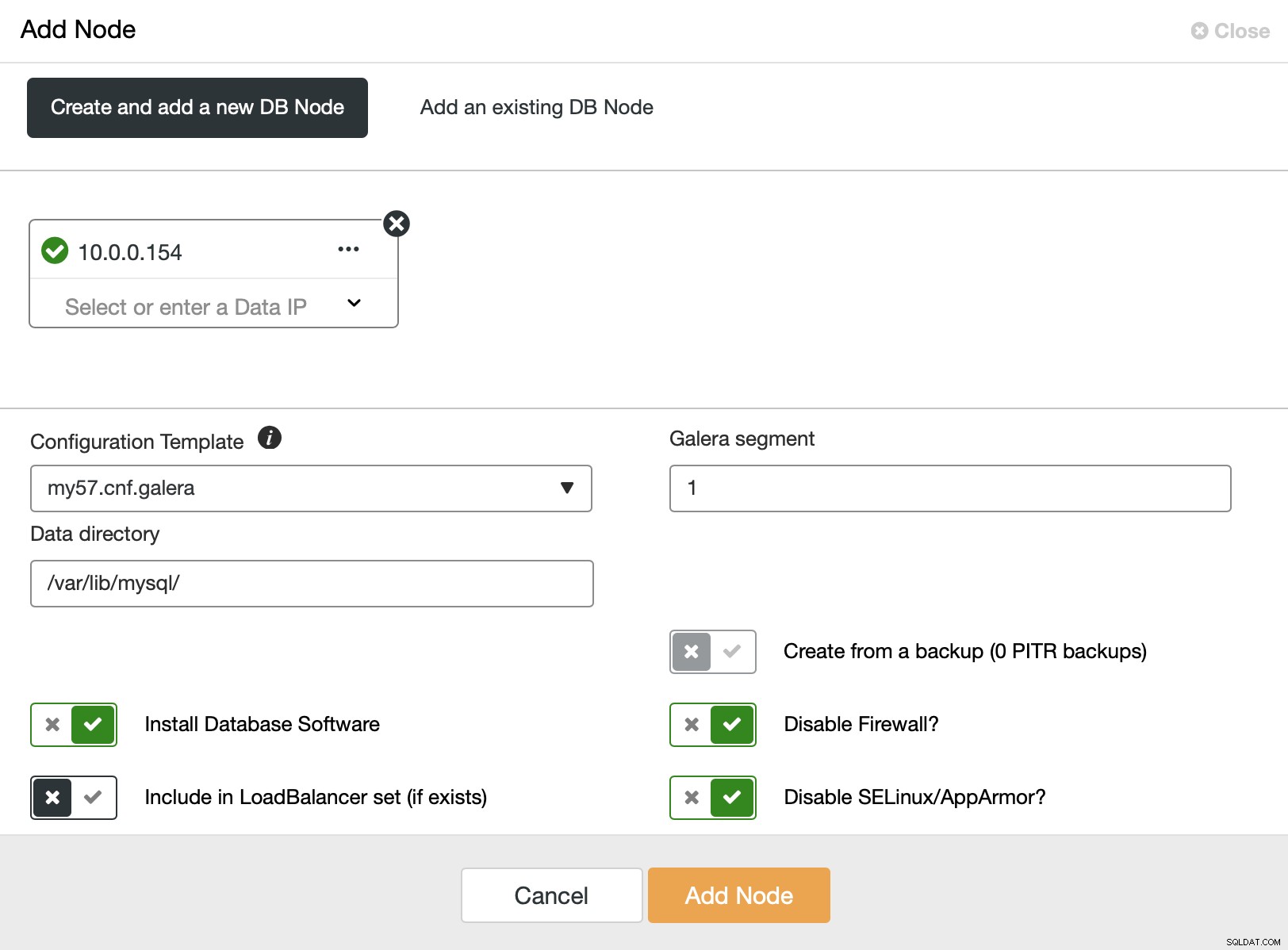
Hier kunnen we één voor één extra knooppunten toevoegen. Wat belangrijk is, u moet het Galera-segment wijzigen in niet-nul (0 wordt gebruikt voor de eerste drie knooppunten).
Na een tijdje hebben we alle negen knooppunten, verdeeld over drie segmenten.
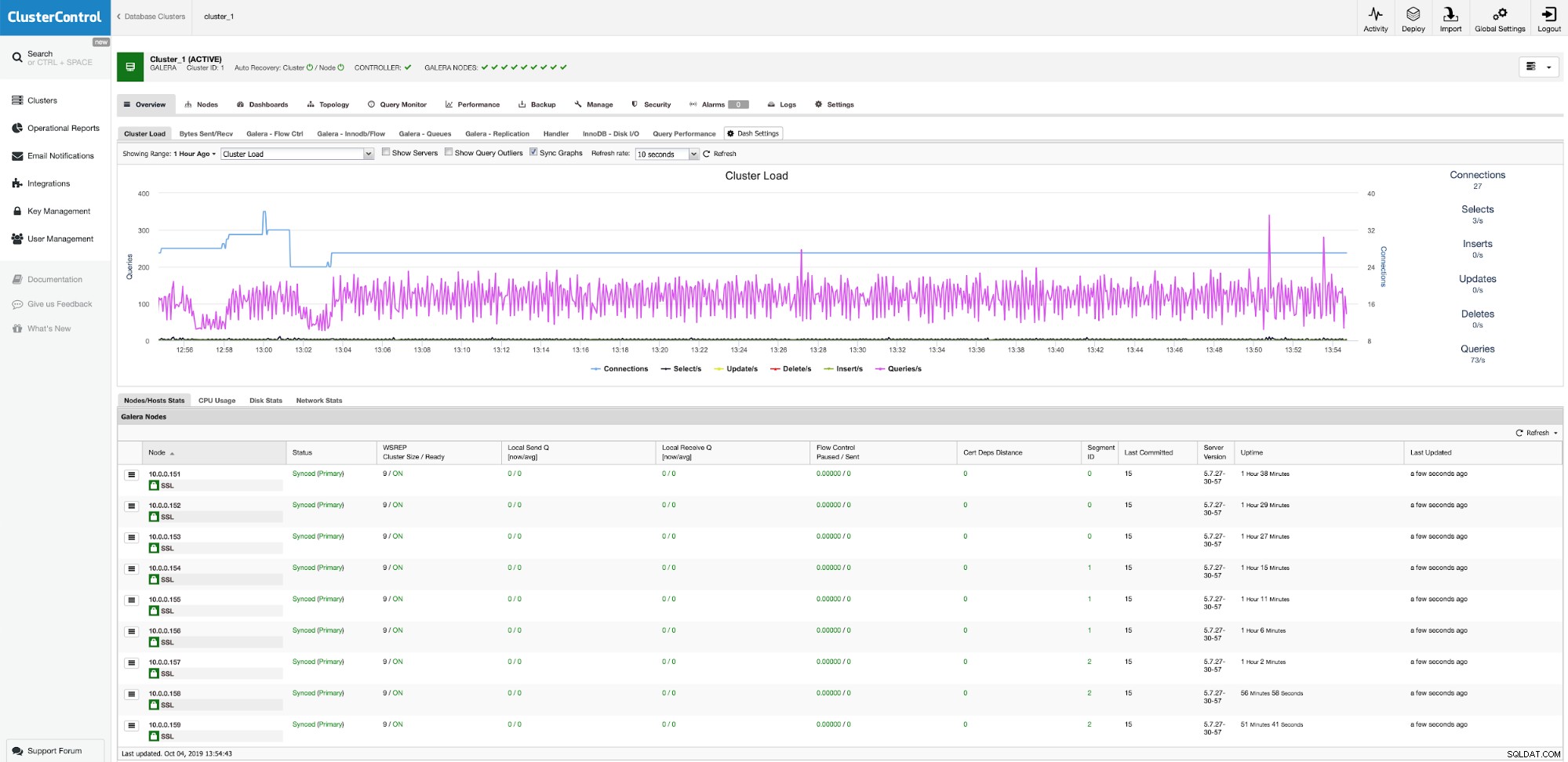
Nu moeten we de proxylaag implementeren. Daarvoor gebruiken we ProxySQL. U kunt het in ClusterControl implementeren via Beheren -> Load Balancer:
Hiermee wordt een implementatieveld geopend:
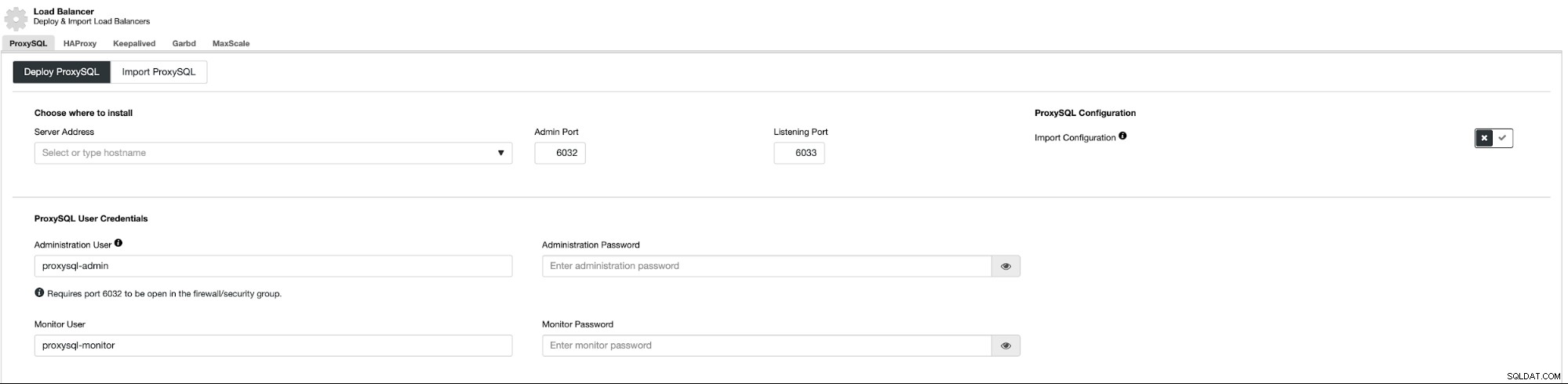
Eerst moeten we beslissen waar we ProxySQL willen inzetten. We zullen bestaande Galera-knooppunten gebruiken, maar u kunt alles in het veld typen, dus het is perfect mogelijk om ProxySQL bovenop de toepassingsknooppunten te implementeren. Bovendien moet u toegangsreferenties doorgeven aan de administratieve en controlerende gebruiker.
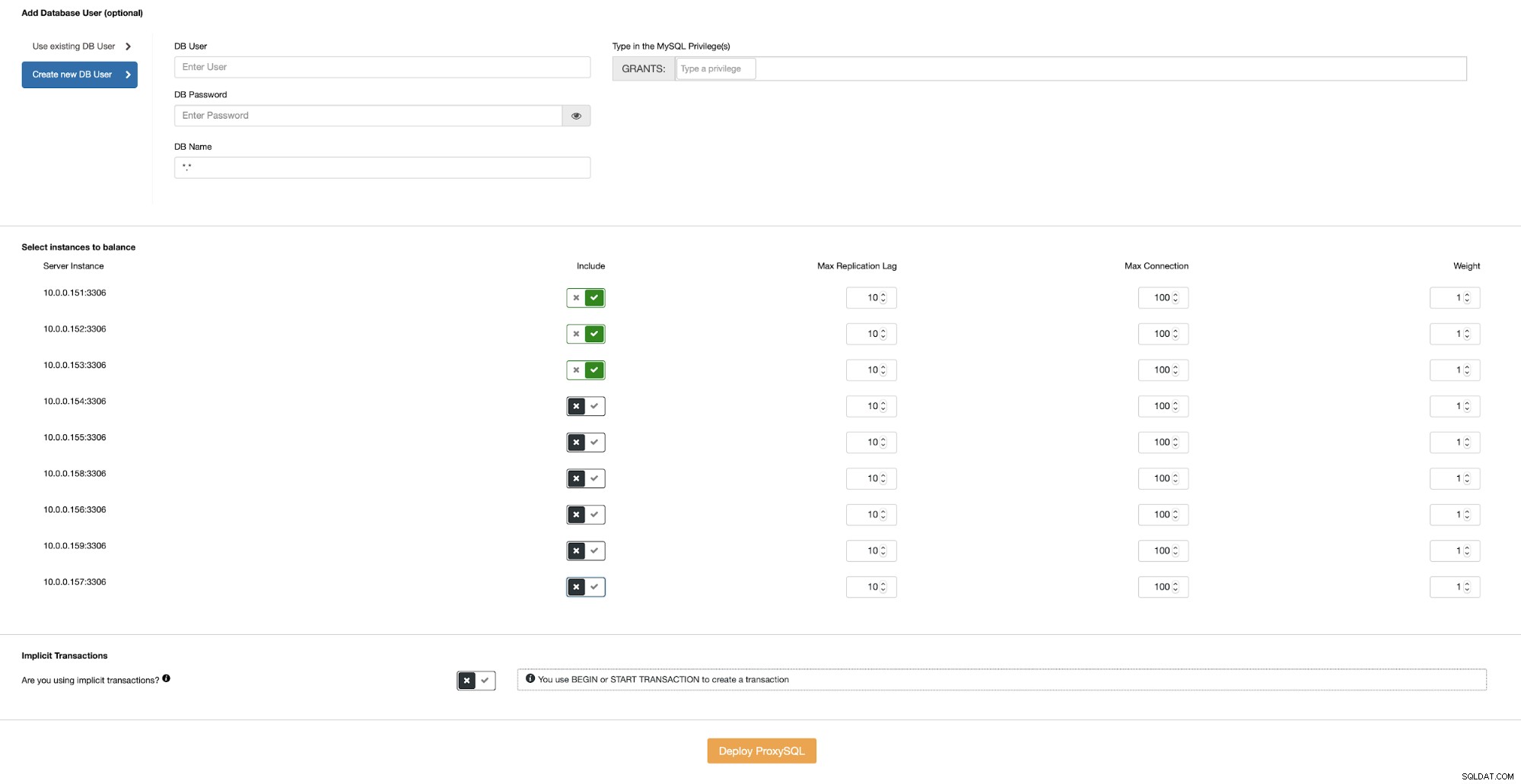
Vervolgens moeten we een van de bestaande gebruikers in MySQL kiezen of er een maken nu. We willen er ook voor zorgen dat de ProxySQL is geconfigureerd om Galera-knooppunten te gebruiken die zich alleen in hetzelfde datacenter bevinden.
Als u één ProxySQL gereed heeft in het datacenter, kunt u deze gebruiken als bron voor de configuratie:
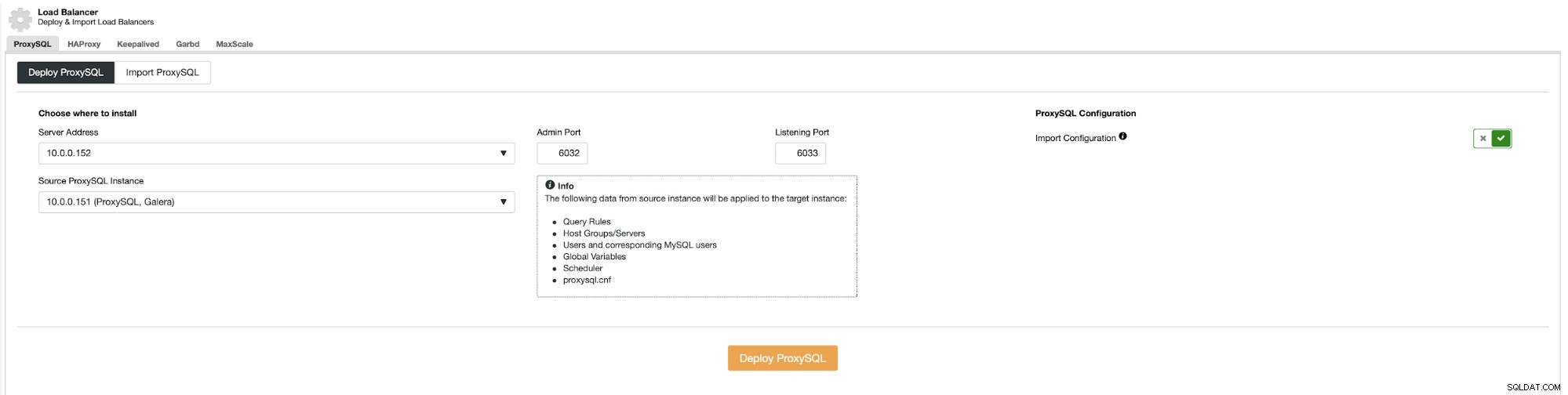
Dit moet worden herhaald voor elke applicatieserver die je in alle datacenters hebt . Vervolgens moet de applicatie worden geconfigureerd om verbinding te maken met de lokale ProxySQL-instantie, idealiter via de Unix-socket. Dit wordt geleverd met de beste prestaties en de laagste latentie.
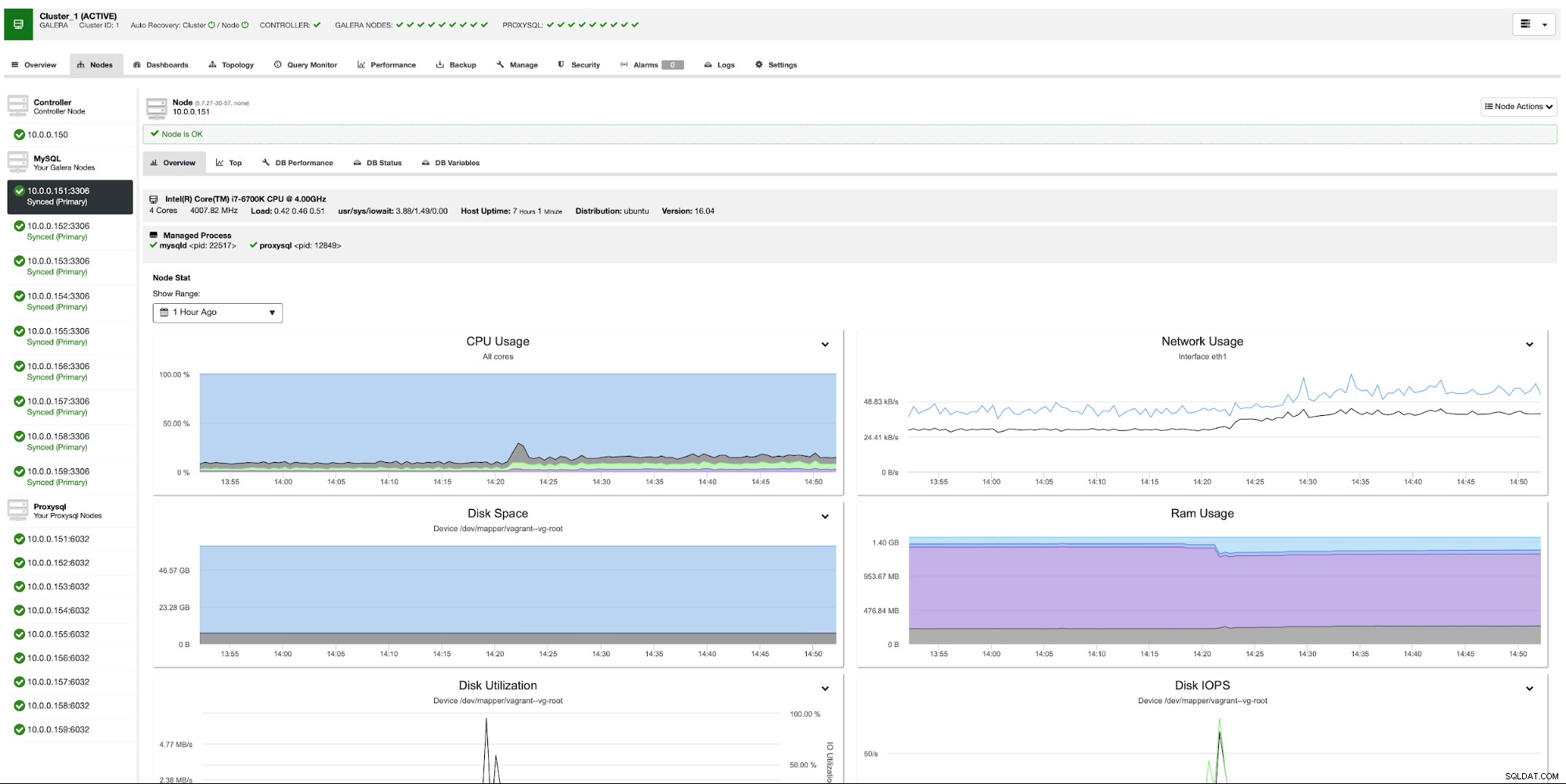
Nadat de laatste ProxySQL is geïmplementeerd, is onze omgeving klaar. Applicatieknooppunten maken verbinding met lokale ProxySQL. Elke ProxySQL is geconfigureerd om te werken met Galera-knooppunten in hetzelfde datacenter:
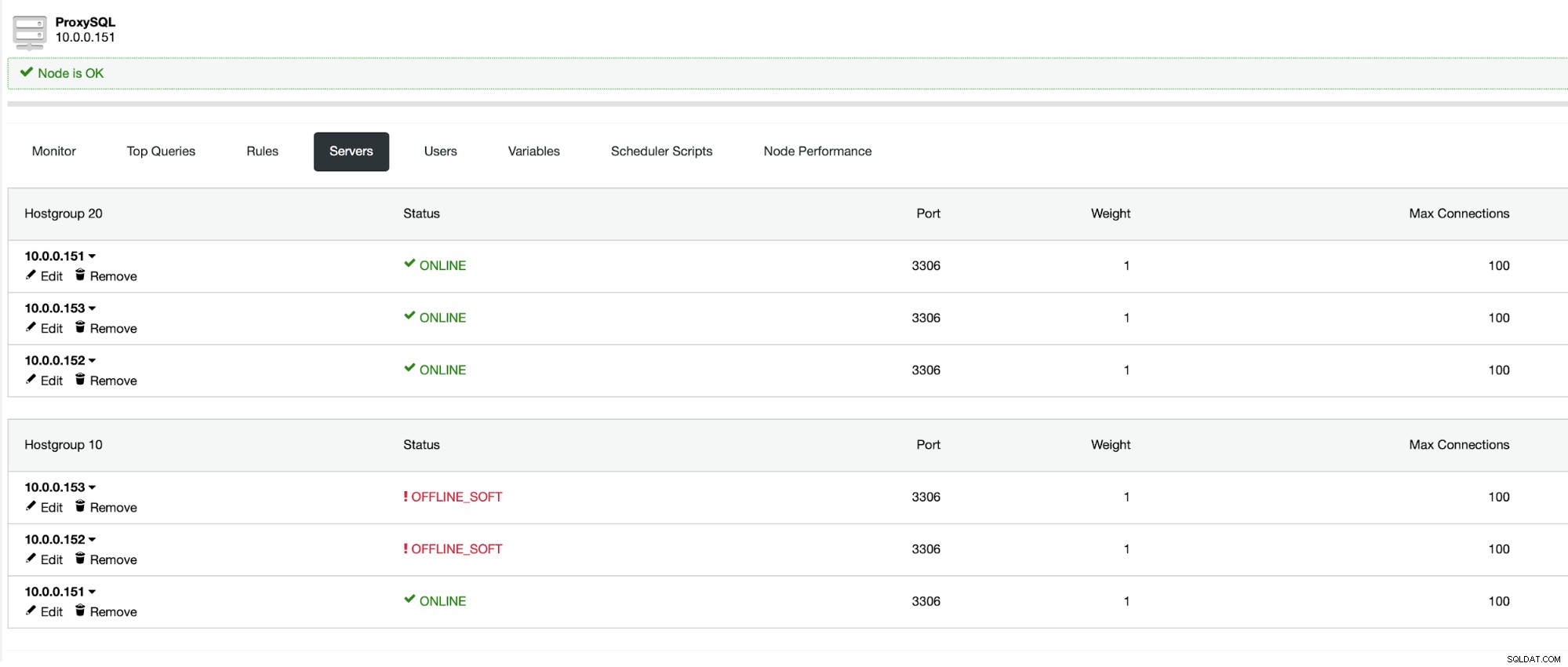
Conclusie
We hopen dat deze tweedelige serie u heeft geholpen om de sterke en zwakke punten van geo-gedistribueerde Galera-clusters te begrijpen en hoe ClusterControl het zeer eenvoudig maakt om een dergelijk cluster te implementeren en te beheren.