Het is vrij gebruikelijk om databases verspreid over meerdere geografische locaties te zien. Een scenario voor het uitvoeren van dit type installatie is voor noodherstel, waarbij uw standby-datacenter zich op een andere locatie bevindt dan uw hoofddatacenter. Het kan net zo goed nodig zijn dat de databases dichter bij de gebruikers staan.
De belangrijkste uitdaging om deze opstelling te bereiken is door de database zo te ontwerpen dat de kans op problemen met betrekking tot de netwerkpartitionering wordt verkleind. Een van de oplossingen zou kunnen zijn om Galera Cluster te gebruiken in plaats van reguliere asynchrone (of semi-synchrone) replicatie. In deze blog bespreken we de voor- en nadelen van deze aanpak. Dit is het eerste deel van een serie van twee blogs. In het tweede deel zullen we de geo-gedistribueerde Galera Cluster ontwerpen en zien hoe ClusterControl ons kan helpen bij het implementeren van een dergelijke omgeving.
Waarom Galera-cluster in plaats van asynchrone replicatie voor geo-gedistribueerde clusters?
Laten we eens kijken naar de belangrijkste verschillen tussen de Galera en reguliere replicatie. Regelmatige replicatie biedt u slechts één knooppunt om naar te schrijven, dit betekent dat elke schrijfbewerking vanuit het externe datacenter via het Wide Area Network (WAN) zou moeten worden verzonden om de master te bereiken. Het betekent ook dat alle proxy's die zich in het externe datacenter bevinden, in staat moeten zijn om de hele topologie te bewaken, verspreid over alle betrokken datacenters, omdat ze moeten kunnen zien welk knooppunt momenteel de master is.
Dit leidt tot het aantal problemen. Ten eerste moeten er meerdere verbindingen over het WAN tot stand worden gebracht, dit voegt latentie toe en vertraagt eventuele controles dat de proxy mogelijk wordt uitgevoerd. Bovendien voegt dit onnodige overhead toe aan de proxy's en databases. Meestal bent u alleen geïnteresseerd in het routeren van verkeer naar de lokale databaseknooppunten. De enige uitzondering is de master en alleen hierdoor worden proxy's gedwongen om de hele infrastructuur te bekijken in plaats van alleen het deel dat zich in het lokale datacenter bevindt. Je kunt dit natuurlijk proberen te verhelpen door proxy's te gebruiken om alleen SELECT's te routeren, terwijl je een andere methode gebruikt (dedicated hostname voor master beheerd door DNS) om de applicatie naar master te verwijzen, maar dit voegt onnodige niveaus van complexiteit en bewegende delen toe, die kan ernstige gevolgen hebben voor uw vermogen om meerdere node- en netwerkstoringen af te handelen zonder de consistentie van gegevens te verliezen.
Galera Cluster kan meerdere schrijvers ondersteunen. Latentie is ook een factor, aangezien alle knooppunten in het Galera-cluster moeten coördineren en communiceren om schrijfsets te certificeren, kan dit zelfs de reden zijn dat u besluit Galera niet te gebruiken wanneer de latentie te hoog is. Het is ook een probleem in replicatieclusters - in replicatieclusters is de latentie alleen van invloed op het schrijven van de externe datacenters, terwijl de verbindingen van het datacenter waar de master zich bevindt, baat zouden hebben bij commits met een lage latentie.
In MySQL-replicatie moet u ook rekening houden met het worstcasescenario en ervoor zorgen dat de toepassing in orde is met uitgestelde schrijfacties. Master kan altijd veranderen en je kunt er niet zeker van zijn dat je de hele tijd naar een lokaal knooppunt schrijft.
Een ander verschil tussen replicatie en Galera Cluster is de verwerking van de replicatievertraging. Geo-gedistribueerde clusters kunnen ernstig worden beïnvloed door vertraging:latentie, beperkte doorvoer van de WAN-verbinding, dit alles heeft invloed op het vermogen van een gerepliceerd cluster om de replicatie bij te houden. Houd er rekening mee dat replicatie één voor al het verkeer genereert.
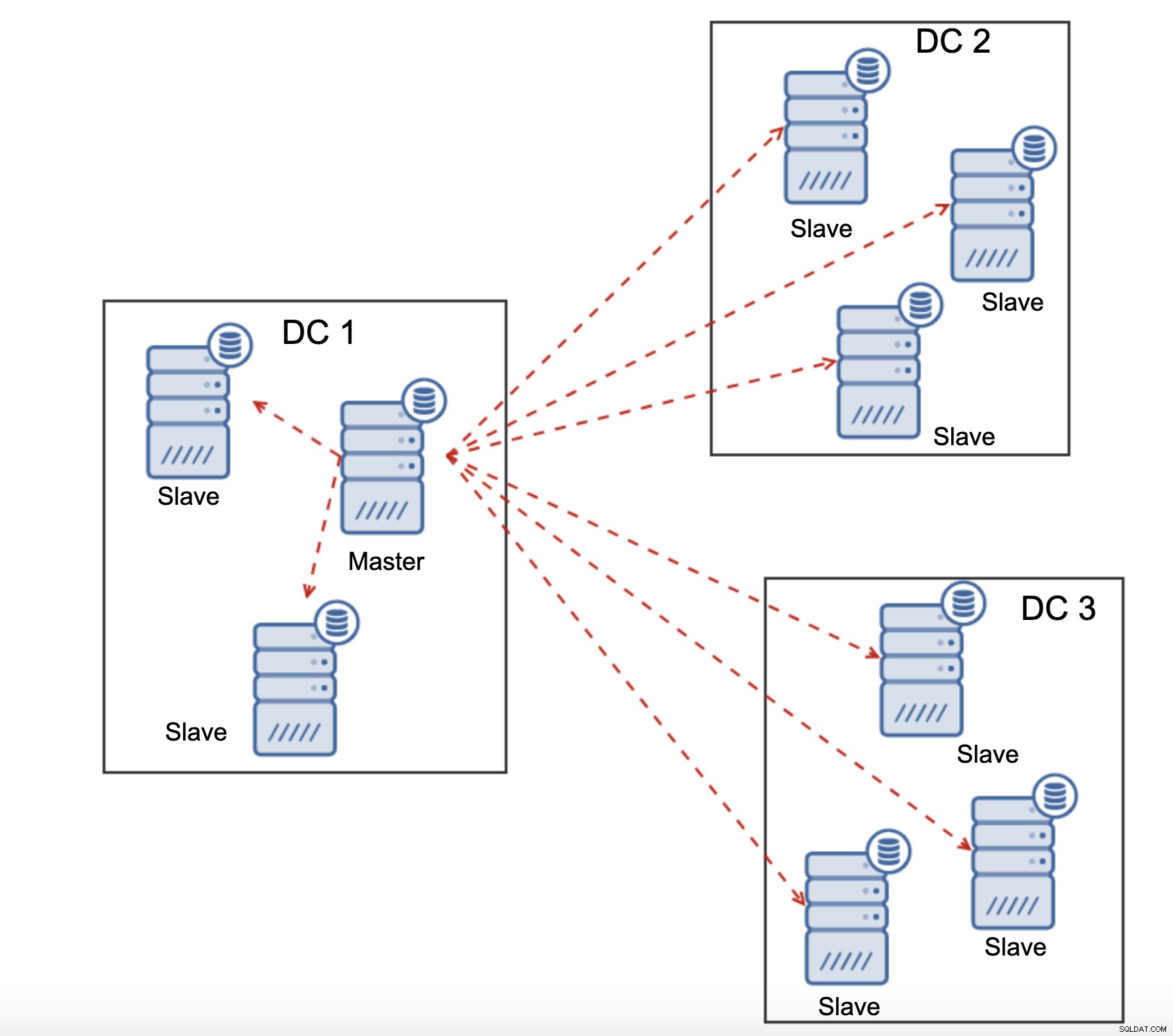
Alle slaves moeten volledig replicatieverkeer ontvangen - de hoeveelheid gegevens die je hebt om via WAN naar externe slaves te verzenden, neemt toe met elke externe slave die u toevoegt. Dit kan gemakkelijk resulteren in de verzadiging van de WAN-link, vooral als u veel wijzigingen aanbrengt en de WAN-link geen goede doorvoer heeft. Zoals u in het bovenstaande diagram kunt zien, moet de master met drie datacenters en drie knooppunten in elk van hen 6x het replicatieverkeer via een WAN-verbinding verzenden.
Met Galera-cluster is het iets anders. Om te beginnen gebruikt Galera flow control om de nodes synchroon te houden. Als een van de knooppunten begint achter te lopen, heeft deze de mogelijkheid om de rest van het cluster te vragen om te vertragen en deze in te halen. Natuurlijk vermindert dit de prestaties van het hele cluster, maar het is nog steeds beter dan wanneer je slaves niet echt kunt gebruiken voor SELECT's, omdat ze van tijd tot tijd vertraging hebben - in dergelijke gevallen kunnen de resultaten die je krijgt verouderd en onjuist zijn.
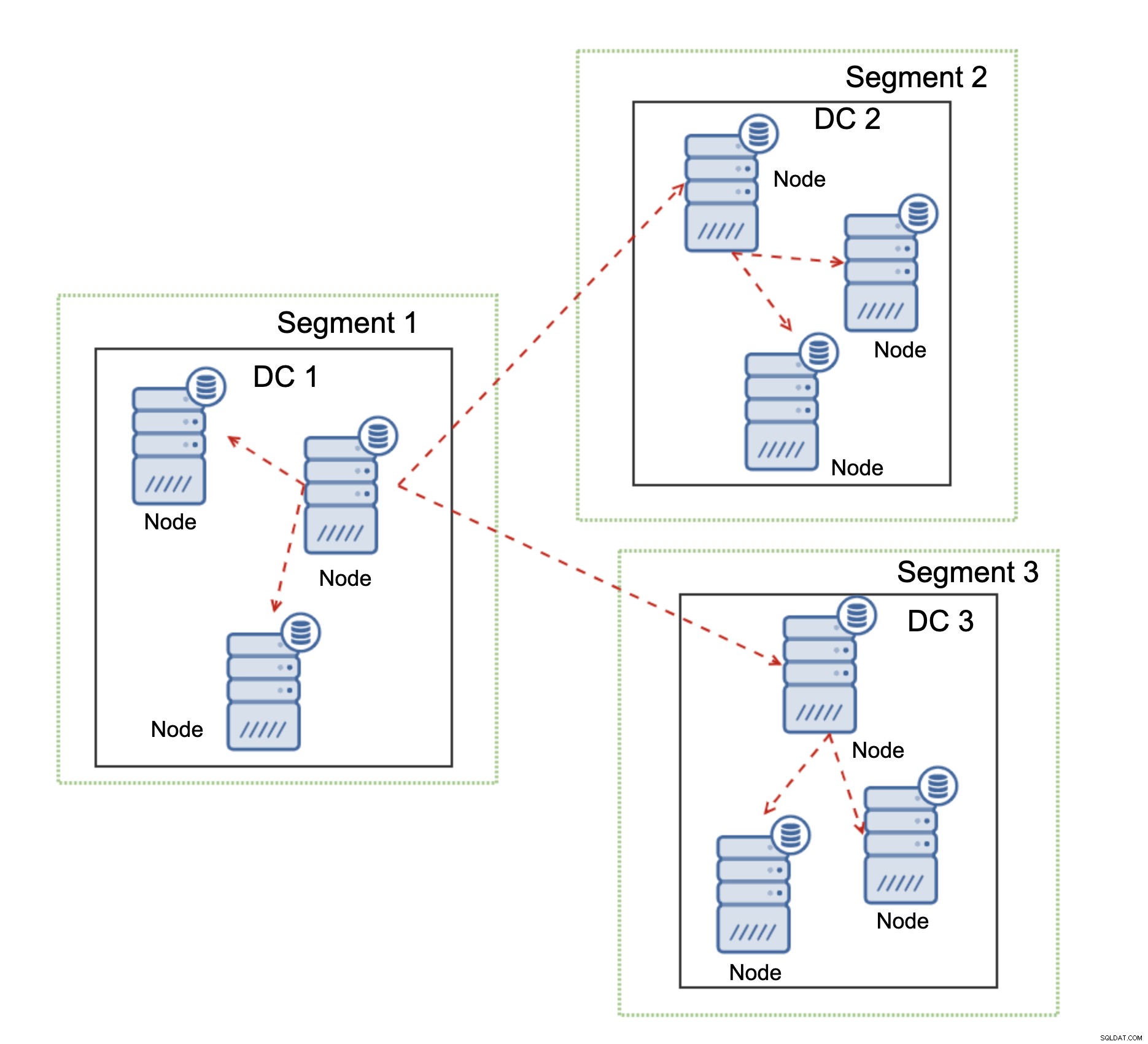
Een andere functie van Galera Cluster, die de prestaties aanzienlijk kan verbeteren bij gebruik WAN, zijn segmenten. Standaard gebruikt Galera alle communicatie en elke schrijfset wordt door het knooppunt naar alle andere knooppunten in het cluster verzonden. Dit gedrag kan worden gewijzigd met behulp van segmenten. Met segmenten kunnen gebruikers het Galera-cluster in verschillende delen splitsen. Elk segment kan meerdere knooppunten bevatten en het kiest een ervan als een relaisknooppunt. Een dergelijk knooppunt ontvangt schrijfsets van andere segmenten en verdeelt deze opnieuw over Galera-knooppunten die lokaal zijn voor het segment. Als gevolg hiervan is het, zoals u in het bovenstaande diagram kunt zien, mogelijk om het replicatieverkeer dat via WAN gaat drie keer te verminderen - slechts twee "replica's" van de replicatiestroom worden via WAN verzonden:één per datacenter vergeleken met één per slave in MySQL-replicatie.
Galera Cluster Network Partitioning Handling
Waar Galera Cluster in uitblinkt, is de afhandeling van de netwerkpartitionering. Galera Cluster bewaakt continu de status van de nodes in het cluster. Elk knooppunt probeert verbinding te maken met zijn peers en de status van het cluster uit te wisselen. Als een subset van knooppunten niet bereikbaar is, probeert Galera de communicatie door te sturen, dus als er een manier is om die knooppunten te bereiken, zullen ze worden bereikt.

Een voorbeeld is te zien in het bovenstaande diagram:DC 1 verloor de connectiviteit met DC2 maar DC2 en DC3 kunnen verbinding maken. In dit geval wordt een van de knooppunten in DC3 gebruikt om gegevens van DC1 naar DC2 door te sturen, zodat de intra-clustercommunicatie kan worden gehandhaafd.
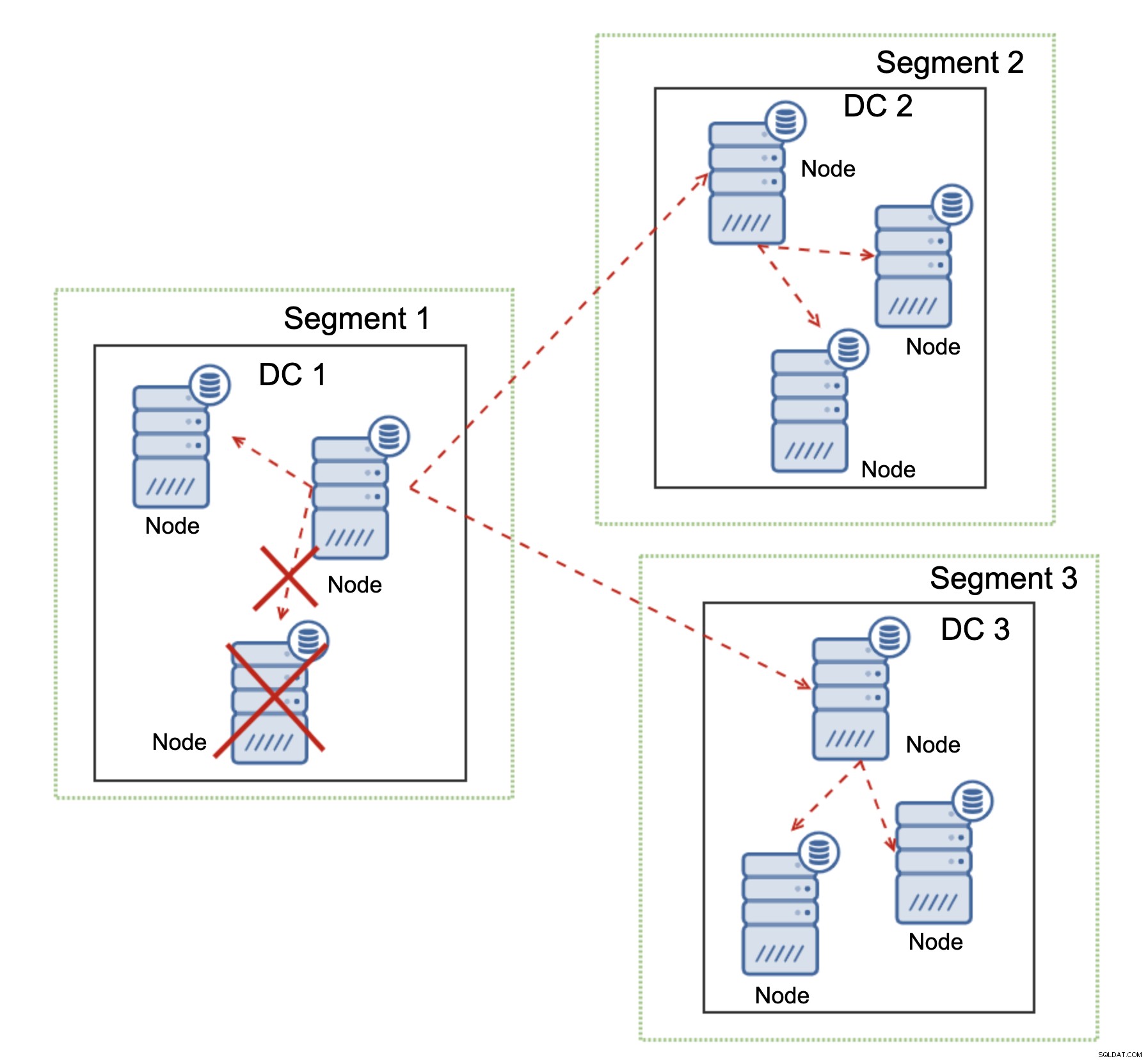
Galera Cluster kan acties ondernemen op basis van de status van het cluster. Het implementeert quorum - de meerderheid van de knooppunten moet beschikbaar zijn om het cluster te laten werken. Als het knooppunt wordt losgekoppeld van het cluster en geen ander knooppunt kan bereiken, stopt het met werken.
Zoals te zien is in het bovenstaande diagram, is er een gedeeltelijk verlies van de netwerkcommunicatie in DC1 en wordt het getroffen knooppunt uit het cluster verwijderd, zodat de toepassing geen toegang krijgt tot verouderde gegevens.
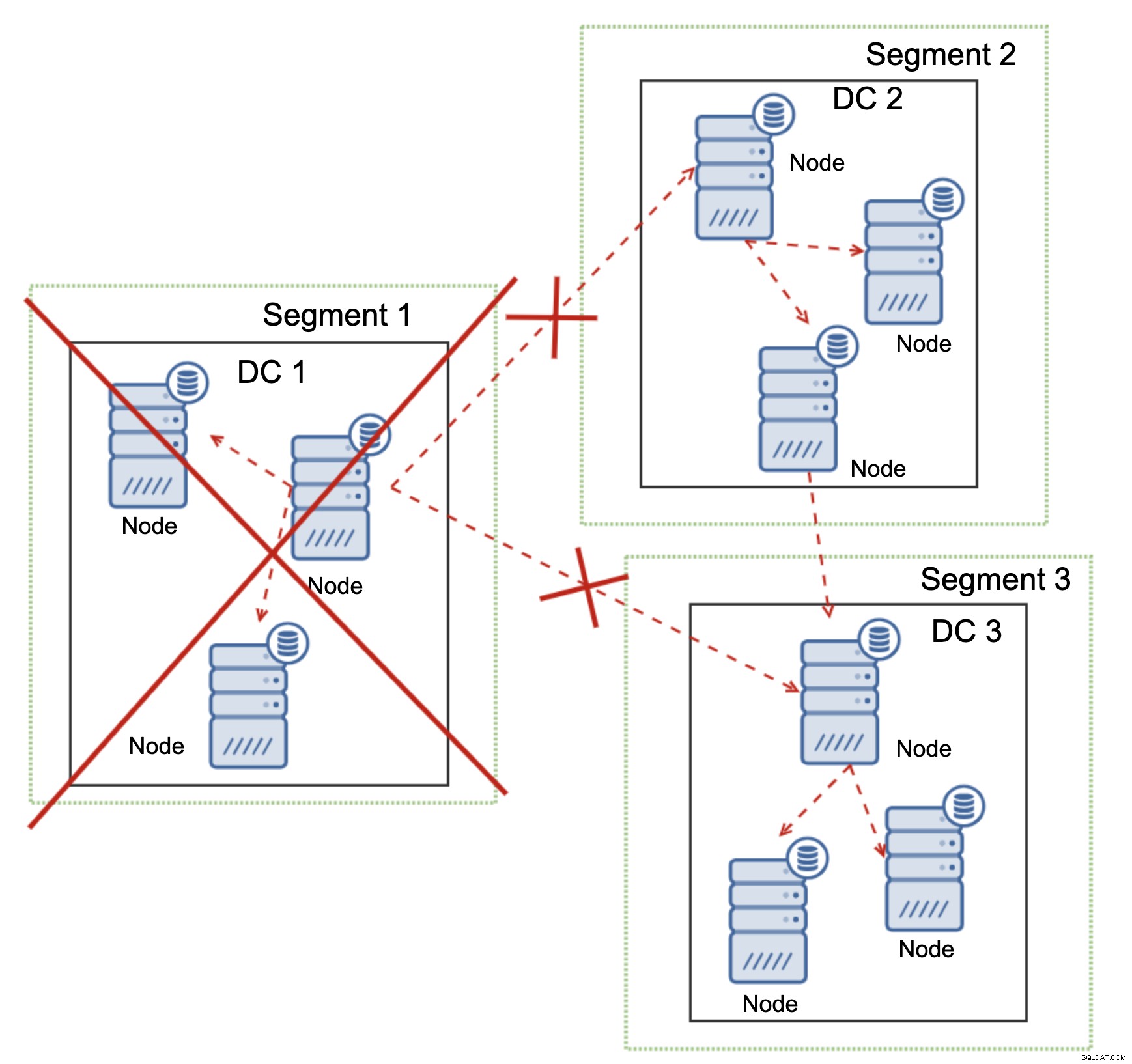
Dit geldt ook op grotere schaal. De DC1 heeft alle communicatie verbroken. Als gevolg hiervan is het hele datacenter uit het cluster verwijderd en zal geen van de knooppunten het verkeer bedienen. De rest van het cluster behield de meerderheid (6 van de 9 knooppunten zijn beschikbaar) en herconfigureerde zichzelf om de verbinding tussen DC 2 en DC3 te behouden. In het bovenstaande diagram gingen we ervan uit dat het schrijven het knooppunt in DC2 raakt, maar houd er rekening mee dat Galera met meerdere schrijvers kan werken.
MySQL-replicatie heeft geen enkele vorm van clusterbewustzijn, waardoor het problematisch is om netwerkproblemen op te lossen. Het kan zichzelf niet afsluiten wanneer de verbinding met andere knooppunten wordt verbroken. Er is geen gemakkelijke manier om te voorkomen dat de oude meester verschijnt na de netwerksplitsing.
De enige mogelijkheden zijn beperkt tot de proxylaag of zelfs hoger. U moet een systeem ontwerpen dat probeert de status van het cluster te begrijpen en de nodige acties te ondernemen. Een mogelijke manier is om clusterbewuste tools zoals Orchestrator te gebruiken en vervolgens scripts uit te voeren die de status van het Orchestrator RAFT-cluster controleren en, op basis van deze status, de vereiste acties ondernemen op de databaselaag. Dit is verre van ideaal omdat elke actie die wordt ondernomen op een laag hoger dan de database, extra latentie toevoegt:het maakt het mogelijk dat het probleem opduikt en de gegevensconsistentie in gevaar komt voordat de juiste actie kan worden ondernomen. Galera daarentegen onderneemt acties op databaseniveau en zorgt voor een zo snel mogelijke reactie.