Overweeg de volgende AdventureWorks-query die transactie-ID's uit de geschiedenistabel retourneert voor product-ID 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
De query-optimizer vindt snel een efficiënt uitvoeringsplan met een schatting van de kardinaliteit (rijtelling) die precies correct is, zoals weergegeven in SQL Sentry Plan Explorer:

Stel nu dat we transactie-ID's uit de geschiedenis willen vinden voor het AdventureWorks-product met de naam "Metal Plate 2". Er zijn veel manieren om deze vraag in T-SQL uit te drukken. Een natuurlijke formulering is:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Het uitvoeringsplan is als volgt:
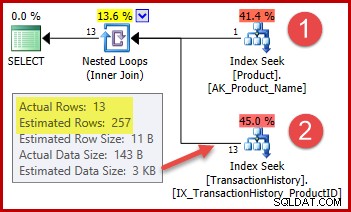
De strategie is:
- Zoek de product-ID op in de producttabel op basis van de opgegeven naam
- Zoek rijen voor die product-ID in de geschiedenistabel
Het geschatte aantal rijen voor stap 1 is precies goed omdat de gebruikte index als uniek wordt verklaard en alleen op de productnaam is gebaseerd. De gelijkheidstest op "Metalen plaat 2" levert daarom gegarandeerd precies één rij op (of nul rijen als we een productnaam opgeven die niet bestaat).
De gemarkeerde schatting van 257 rijen voor stap twee is minder nauwkeurig:er worden slechts 13 rijen aangetroffen. Deze discrepantie ontstaat omdat de optimizer niet weet welke specifieke product-ID is gekoppeld aan het product met de naam "Metal Plate 2". Het behandelt de waarde als onbekend en genereert een kardinaliteitsschatting met behulp van informatie over de gemiddelde dichtheid. De berekening maakt gebruik van elementen uit het onderstaande statistische object:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
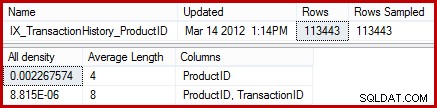
Uit de statistieken blijkt dat de tabel 113443 rijen bevat met 441 unieke product-ID's (1 / 0.002267574 =441). Ervan uitgaande dat de verdeling van rijen over product-ID's uniform is, verwacht kardinaliteitsschatting dat een product-ID overeenkomt met (113443 / 441) =257,24 rijen gemiddeld. Het blijkt dat de verdeling niet bijzonder uniform is; er zijn slechts 13 rijen voor het product "Metalen Plaat 2".
Een terzijde
U denkt misschien dat de schatting van 257 rijen nauwkeuriger zou moeten zijn. Aangezien bijvoorbeeld product-ID's en namen beide beperkt zijn om uniek te zijn, kan SQL Server automatisch informatie over deze één-op-één-relatie bijhouden. Het zou dan weten dat "Metalen plaat 2" is gekoppeld aan product-ID 479, en dat inzicht gebruiken om een nauwkeurigere schatting te genereren met behulp van het ProductID-histogram:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
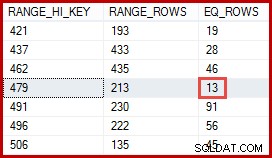
Een schatting van 13 op deze manier afgeleide rijen zou precies correct zijn geweest. Desalniettemin was de schatting van 257 rijen niet onredelijk, gezien de beschikbare statistische informatie en de normale vereenvoudigende veronderstellingen (zoals uniforme verdeling) die tegenwoordig worden toegepast door kardinaliteitsschattingen. Exacte schattingen zijn altijd leuk, maar 'redelijke' schattingen zijn ook perfect acceptabel.
De twee zoekopdrachten combineren
Stel dat we nu alle transactiegeschiedenis-ID's willen zien waarbij de product-ID 421 is OF de naam van het product is "Metalen Plaat 2". Een natuurlijke manier om de twee voorgaande zoekopdrachten te combineren is:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Het uitvoeringsplan is nu iets complexer, maar bevat nog steeds herkenbare elementen van de enkelvoudige predikaatplannen:
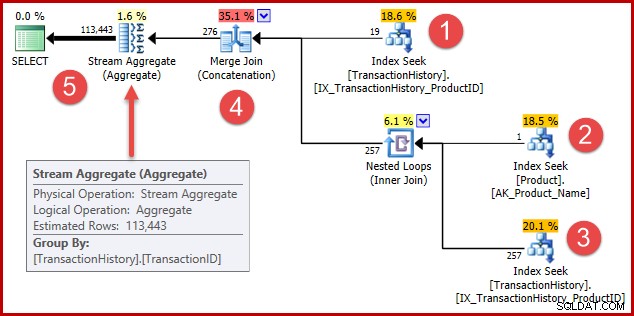
De strategie is:
- Vind geschiedenisrecords voor product 421
- Zoek de product-ID op voor het product met de naam "Metal Plate 2"
- Zoek geschiedenisrecords voor de product-ID gevonden in stap 2
- Combineer rijen uit stap 1 en 3
- Verwijder eventuele duplicaten (omdat product 421 ook degene kan zijn met de naam "Metal Plate 2")
Stappen 1 t/m 3 zijn precies hetzelfde als voorheen. Om dezelfde redenen worden dezelfde schattingen gemaakt. Stap 4 is nieuw, maar heel eenvoudig:het voegt naar verwachting 19 rijen samen met naar verwachting 257 rijen, om een schatting van 276 rijen te geven.
Stap 5 is de interessante. Het duplicaat-verwijderende Stream Aggregate heeft een geschatte invoer van 276 rijen en een geschatte uitvoer van 113443 rijen. Een aggregaat dat meer rijen uitvoert dan het ontvangt, lijkt onmogelijk, toch?
* Je ziet hier een schatting van 102099 rijen als je het kardinaliteitsschattingsmodel van vóór 2014 gebruikt.
De kardinaliteitsschattingsbug
De onmogelijke schatting van Stream Aggregate in ons voorbeeld wordt veroorzaakt door een fout in de schatting van de kardinaliteit. Het is een interessant voorbeeld, dus we zullen het wat gedetailleerder onderzoeken.
Subquery verwijderen
Het zal u misschien verbazen te horen dat de SQL Server-queryoptimalisatie niet rechtstreeks met subquery's werkt. Ze worden vroeg in het compilatieproces uit de logische zoekstructuur verwijderd en vervangen door een equivalente constructie waarvoor de optimizer is ingesteld om mee te werken en erover te redeneren. De optimizer heeft een aantal regels die subquery's verwijderen. Deze kunnen op naam worden weergegeven met behulp van de volgende zoekopdracht (de DMV waarnaar wordt verwezen is minimaal gedocumenteerd, maar wordt niet ondersteund):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Resultaten (op SQL Server 2014):
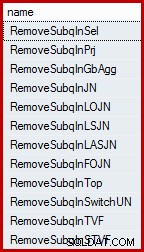
De gecombineerde testquery heeft twee predikaten ("selecties" in relationele termen) in de geschiedenistabel, verbonden door OR . Een van deze predikaten bevat een subquery. De hele substructuur (zowel predikaten als de subquery) wordt getransformeerd door de eerste regel in de lijst ("subquery verwijderen in selectie") naar een semi-join over de vereniging van de individuele predikaten. Hoewel het niet mogelijk is om het resultaat van deze interne transformatie exact weer te geven met behulp van de T-SQL-syntaxis, komt het er redelijk dichtbij:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Het is een beetje jammer dat mijn T-SQL-benadering van de interne boomstructuur na het verwijderen van een subquery een subquery bevat, maar in de taal van de queryprocessor niet (het is een semi-join). Als u liever de onbewerkte interne vorm wilt zien in plaats van mijn poging tot een T-SQL-equivalent, kunt u er zeker van zijn dat dit zo zal zijn.
De ongedocumenteerde query-hint in de bovenstaande T-SQL is bedoeld om een volgende transformatie te voorkomen voor degenen onder u die de getransformeerde logica in uitvoeringsplanvorm willen zien. De annotaties hieronder tonen de posities van de twee predikaten na transformatie:
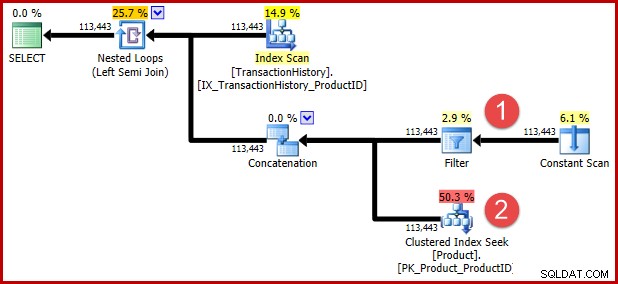
De intuïtie achter de transformatie is dat een geschiedenisrij in aanmerking komt als aan een van de predikaten is voldaan. Ongeacht hoe nuttig je mijn geschatte T-SQL- en uitvoeringsplanillustratie vindt, ik hoop dat het op zijn minst redelijk duidelijk is dat het herschrijven dezelfde vereiste uitdrukt als de oorspronkelijke vraag.
Ik moet benadrukken dat de optimizer niet letterlijk alternatieve T-SQL-syntaxis genereert of volledige uitvoeringsplannen produceert in tussenstadia. De bovenstaande weergaven van T-SQL en uitvoeringsplan zijn puur bedoeld als hulpmiddel bij het begrijpen. Als u geïnteresseerd bent in de ruwe details, is de beloofde interne representatie van de getransformeerde zoekboom (enigszins aangepast voor de duidelijkheid/ruimte):
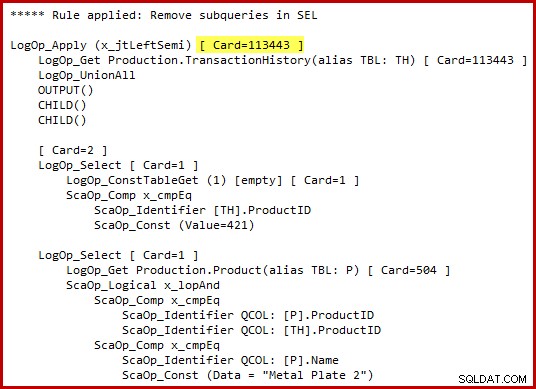
Let op de gemarkeerde schatting van de semi-joinkardinaliteit toepassen. Het is 113443 rijen bij gebruik van de kardinaliteitsschatter van 2014 (102099 rijen bij gebruik van de oude CE). Houd er rekening mee dat de geschiedenistabel van AdventureWorks in totaal 113443 rijen bevat, dus dit vertegenwoordigt 100% selectiviteit (90% voor de oude CE).
We hebben eerder gezien dat het toepassen van een van deze predikaten alleen resulteert in slechts een klein aantal overeenkomsten:19 rijen voor product-ID 421 en 13 rijen (naar schatting 257) voor "Metal Plate 2". Inschatting dat de disjunctie (OR) van de twee predikaten zullen alle rijen in de basistabel retourneren, lijkt volkomen gestoord.
Bugdetails
De details van de selectiviteitsberekening voor de semi-join zijn alleen zichtbaar in SQL Server 2014 bij gebruik van de nieuwe kardinaliteitsschatter met (ongedocumenteerde) traceringsvlag 2363. Het is waarschijnlijk mogelijk om iets soortgelijks te zien met Extended Events, maar de uitvoer van de traceringsvlag is handiger hier te gebruiken. Het relevante gedeelte van de uitvoer wordt hieronder weergegeven:
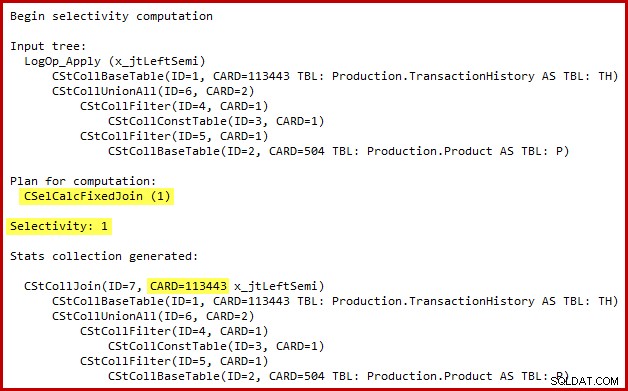
De kardinaliteitsschatter gebruikt de Fixed Join-calculator met 100% selectiviteit. Als gevolg hiervan is de geschatte uitvoerkardinaliteit van de semi-join hetzelfde als de invoer, wat betekent dat alle 113443 rijen uit de geschiedenistabel in aanmerking komen.
De exacte aard van de bug is dat de berekening van de semi-join selectiviteit alle predikaten mist die zich buiten een unie in de invoerboom bevinden. In de onderstaande afbeelding wordt het ontbreken van predikaten op de semi-join zelf bedoeld om te betekenen dat elke rij in aanmerking komt; het negeert het effect van predikaten onder de aaneenschakeling (union all).
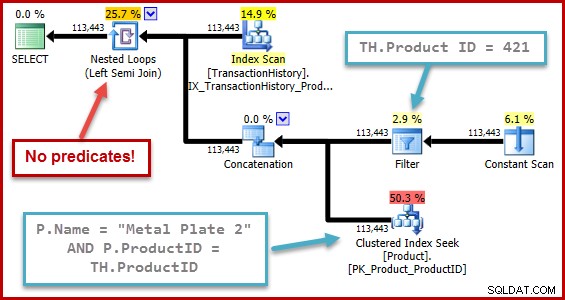
Dit gedrag is des te verrassender als je bedenkt dat selectiviteitsberekening werkt op een boomweergave die de optimizer zelf heeft gegenereerd (de vorm van de boom en de positionering van de predikaten is het resultaat van het verwijderen van de subquery).
Een soortgelijk probleem doet zich voor met de kardinaliteitsschatter van vóór 2014, maar de uiteindelijke schatting is in plaats daarvan vastgesteld op 90% van de geschatte semi-joininvoer (om vermakelijke redenen die verband houden met een omgekeerde vaste predikaatschatting van 10% die te veel afleiding is om te krijgen in).
Voorbeelden
Zoals hierboven vermeld, manifesteert deze bug zich wanneer een schatting wordt uitgevoerd voor een semi-join met gerelateerde predikaten die zich buiten een union all bevinden. Of deze interne rangschikking optreedt tijdens query-optimalisatie hangt af van de oorspronkelijke T-SQL-syntaxis en de precieze volgorde van interne optimalisatiebewerkingen. De volgende voorbeelden tonen enkele gevallen waarin de bug wel en niet optreedt:
Voorbeeld 1
Dit eerste voorbeeld bevat een triviale wijziging in de testquery:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Het geschatte uitvoeringsplan is:
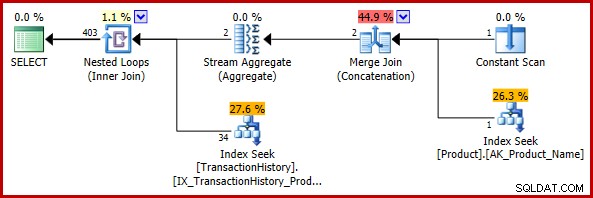
De uiteindelijke schatting van 403 rijen is niet consistent met de invoerschattingen van de geneste loops join, maar is nog steeds redelijk (in de eerder besproken zin). Als de bug was aangetroffen, zou de uiteindelijke schatting 113443 rijen zijn (of 102099 rijen bij gebruik van het CE-model van vóór 2014).
Voorbeeld 2
Als je op het punt stond al je constante vergelijkingen te herschrijven als triviale subquery's om deze bug te vermijden, kijk dan wat er gebeurt als we nog een triviale wijziging aanbrengen, deze keer de gelijkheidstest in het tweede predikaat vervangen door IN. De betekenis van de zoekopdracht blijft ongewijzigd:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); De bug keert terug:
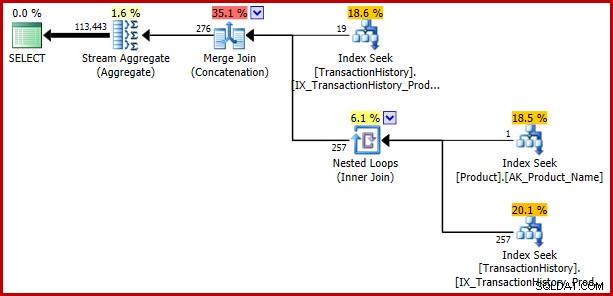
Voorbeeld 3
Hoewel dit artikel zich tot nu toe heeft geconcentreerd op een disjunctief predikaat dat een subquery bevat, laat het volgende voorbeeld zien dat dezelfde queryspecificatie, uitgedrukt met EXISTS en UNION ALL, ook kwetsbaar is:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Uitvoeringsplan:
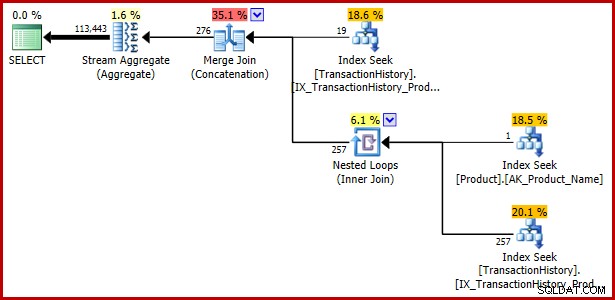
Voorbeeld 4
Hier zijn nog twee manieren om dezelfde logische query uit te drukken in T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Geen van beide zoekopdrachten vindt de bug en beide produceren hetzelfde uitvoeringsplan:
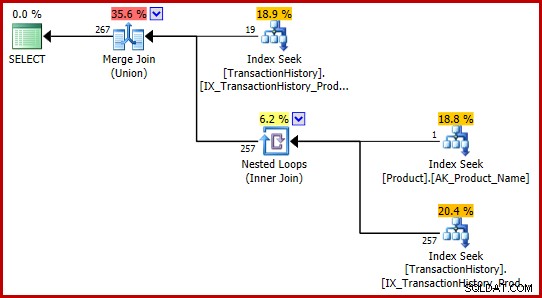
Deze T-SQL-formuleringen produceren toevallig een uitvoeringsplan met volledig consistente (en redelijke) schattingen.
Voorbeeld 5
U vraagt zich misschien af of de onnauwkeurige schatting belangrijk is. In de gevallen die tot nu toe zijn gepresenteerd, is dat niet, althans niet direct. Er ontstaan problemen wanneer de bug zich voordoet in een grotere query en de onjuiste schatting invloed heeft op beslissingen van de optimalisatie elders. Als een minimaal uitgebreid voorbeeld, kunt u overwegen de resultaten van onze testquery in willekeurige volgorde te retourneren:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Het uitvoeringsplan laat zien dat de onjuiste schatting gevolgen heeft voor latere bewerkingen. Het is bijvoorbeeld de basis voor de geheugentoekenning die is gereserveerd voor de sortering:
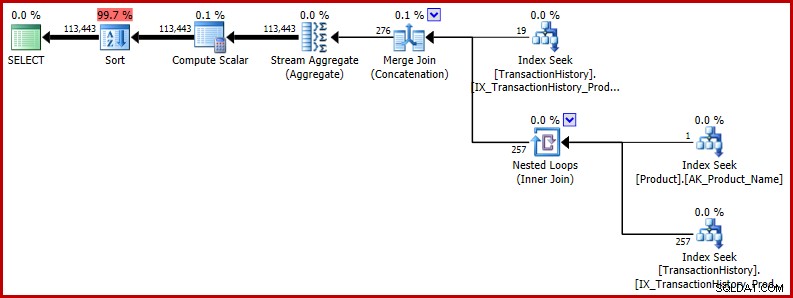
Als je een realistischer voorbeeld wilt zien van de mogelijke impact van deze bug, bekijk dan deze recente vraag van Richard Mansell op de Q &A-site van SQLPerformance.com, Answers.SQLPerformance.com.
Samenvatting en laatste gedachten
Deze bug wordt geactiveerd wanneer de optimizer kardinaliteitsschatting uitvoert voor een semi-join, in specifieke omstandigheden. Het is om een aantal redenen een lastige bug om op te sporen en te omzeilen:
- Er is geen expliciete T-SQL-syntaxis om een semi-join te specificeren, dus het is moeilijk om van tevoren te weten of een bepaalde query kwetsbaar is voor deze bug.
- De optimizer kan een semi-join introduceren in een groot aantal verschillende omstandigheden, die niet allemaal voor de hand liggende semi-join-kandidaten zijn.
- De problematische semi-join wordt vaak getransformeerd in iets anders door latere optimalisatie-activiteit, dus we kunnen er niet eens op vertrouwen dat er een semi-join-operatie is in het uiteindelijke uitvoeringsplan.
- Niet elke vreemd uitziende kardinaliteitsschatting wordt veroorzaakt door deze bug. Veel voorbeelden van dit type zijn inderdaad een verwacht en onschadelijk neveneffect van de normale werking van de optimizer.
- De foutieve schatting van de semi-join selectiviteit zal altijd 90% of 100% van de invoer zijn, maar dit komt meestal niet overeen met de kardinaliteit van een tabel die in het plan wordt gebruikt. Bovendien is het mogelijk dat de semi-join-invoerkardinaliteit die in de berekening wordt gebruikt, niet eens zichtbaar is in het uiteindelijke uitvoeringsplan.
- Er zijn doorgaans veel manieren om dezelfde logische query uit te drukken in T-SQL. Sommige hiervan zullen de bug activeren, andere niet.
Deze overwegingen maken het moeilijk om praktisch advies te geven om deze bug op te sporen of te omzeilen. Het is zeker de moeite waard om de uitvoeringsplannen te controleren op "buitensporige" schattingen en om query's te onderzoeken met prestaties die veel slechter zijn dan verwacht, maar beide kunnen oorzaken hebben die geen verband houden met deze bug. Dat gezegd hebbende, is het vooral de moeite waard om zoekopdrachten te controleren die een disjunctie van predikaten en een subquery bevatten. Zoals de voorbeelden in dit artikel laten zien, is dit niet de enige manier om de bug op te lossen, maar ik verwacht dat het een veelvoorkomend probleem zal zijn.
Als je het geluk hebt SQL Server 2014 te gebruiken, met de nieuwe kardinaliteitsschatter ingeschakeld, kun je de bug misschien bevestigen door de uitvoer van traceringsvlag 2363 handmatig te controleren op een vaste 100% selectiviteitsschatting op een semi-join, maar dit is nauwelijks handig. U wilt natuurlijk geen ongedocumenteerde traceervlaggen gebruiken op een productiesysteem.
Het User Voice-bugrapport voor dit probleem is hier te vinden. Stem en reageer als je dit probleem onderzocht (en mogelijk opgelost) wilt zien.