SQL Server 2005 heeft de mogelijkheid toegevoegd om niet-sleutelkolommen op te nemen in een niet-geclusterde index. In SQL Server 2000 en eerder waren voor een niet-geclusterde index alle kolommen die voor een index waren gedefinieerd, sleutelkolommen, wat betekende dat ze deel uitmaakten van elk niveau van de index, van het root- tot het leaf-niveau. Wanneer een kolom is gedefinieerd als een opgenomen kolom, maakt deze alleen deel uit van het bladniveau. Books Online wijst op de volgende voordelen van opgenomen kolommen:
- Dit kunnen gegevenstypen zijn die niet zijn toegestaan als indexsleutelkolommen.
- Ze worden niet in aanmerking genomen door de Database Engine bij het berekenen van het aantal indexsleutelkolommen of de grootte van de indexsleutel.
Een varchar(max)-kolom kan bijvoorbeeld geen onderdeel zijn van een indexsleutel, maar het kan wel een opgenomen kolom zijn. Verder telt die varchar(max)-kolom niet mee voor de 900-byte (of 16-kolom) limiet die is opgelegd voor de indexsleutel.
De documentatie vermeldt ook het volgende prestatievoordeel:
Een index met niet-sleutelkolommen kan de prestaties van query's aanzienlijk verbeteren wanneer alle kolommen in de query in de index zijn opgenomen, hetzij als sleutel- of niet-sleutelkolommen. Prestatieverbeteringen worden bereikt omdat de query-optimizer alle kolomwaarden in de index kan lokaliseren; tabel- of geclusterde indexgegevens worden niet benaderd, wat resulteert in minder schijf-I/O-bewerkingen.We kunnen hieruit afleiden dat of de indexkolommen nu sleutelkolommen of niet-sleutelkolommen zijn, we een prestatieverbetering krijgen in vergelijking met wanneer alle kolommen geen deel uitmaken van de index. Maar is er een prestatieverschil tussen de twee varianten?
De installatie
Ik heb een kopie van de AdventuresWork2012-database geïnstalleerd en de indexen voor de tabel Sales.SalesOrderHeader geverifieerd met behulp van Kimberly Tripp's versie van sp_helpindex:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Standaardindexen voor Sales.SalesOrderHeader
We beginnen met een eenvoudige query om te testen die gegevens uit meerdere kolommen haalt:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Als we dit uitvoeren op de AdventureWorks2012-database met behulp van SQL Sentry Plan Explorer en het plan en de tabel I/O-uitvoer controleren, zien we dat we een geclusterde indexscan krijgen met 689 logische uitlezingen:
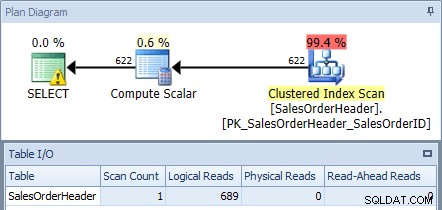
Uitvoeringsplan van oorspronkelijke zoekopdracht
(In Management Studio kon je de I/O-statistieken zien met SET STATISTICS IO ON; .)
De SELECT heeft een waarschuwingspictogram, omdat de optimizer een index voor deze zoekopdracht aanbeveelt:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Test 1
We zullen eerst de index maken die de optimizer aanbeveelt (met de naam NCI1_included), evenals de variant met alle kolommen als sleutelkolommen (met de naam NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Als we de oorspronkelijke query opnieuw uitvoeren, een keer een hint geven met NCI1 en een keer een hint geven met NCI1_included, zien we een plan dat lijkt op het origineel, maar deze keer is er een indexzoekopdracht van elke niet-geclusterde index, met equivalente waarden voor Tabel I/ O, en vergelijkbare kosten (beide ongeveer 0,006):
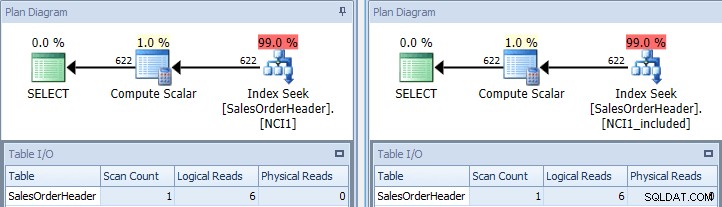
Originele zoekopdracht met indexzoekopdracht – sleutel aan de linkerkant, opnemen op rechts
(Het aantal scans is nog steeds 1 omdat het zoeken naar een index eigenlijk een vermomde bereikscan is.)
Nu is de AdventureWorks2012-database niet representatief voor een productiedatabase in termen van grootte, en als we kijken naar het aantal pagina's in elke index, zien we dat ze precies hetzelfde zijn:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
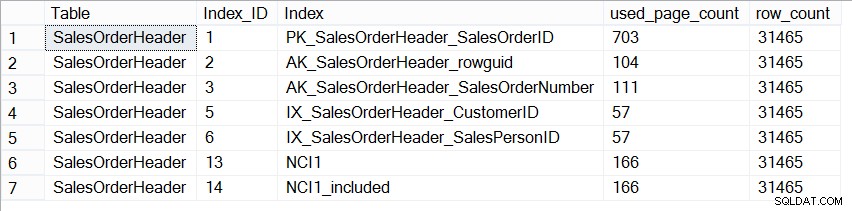
Grootte van indexen op Sales.SalesOrderHeader
Als we naar prestaties kijken, is het ideaal (en leuker) om te testen met een grotere dataset.
Test 2
Ik heb een kopie van de AdventureWorks2012-database met een SalesOrderHeader-tabel met meer dan 200 miljoen rijen (script HIER), dus laten we dezelfde niet-geclusterde indexen in die database maken en de query's opnieuw uitvoeren:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
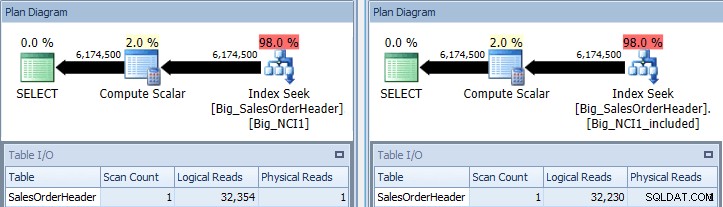
Originele zoekopdracht met index zoekt tegen Big_NCI1 (l) en Big_NCI1_Included ( r)
Nu krijgen we wat gegevens. De query retourneert meer dan 6 miljoen rijen en het zoeken naar elke index vereist iets meer dan 32.000 reads, en de geschatte kosten zijn hetzelfde voor beide query's (31.233). Er zijn nog geen prestatieverschillen en als we de grootte van de indexen controleren, zien we dat de index met de opgenomen kolommen 5.578 pagina's minder heeft:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Grootte van indexen op Sales.Big_SalesOrderHeader
Als we hier dieper op ingaan en dm_dm_index_physical_stats controleren, kunnen we zien dat er verschil bestaat in de tussenliggende niveaus van de index:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
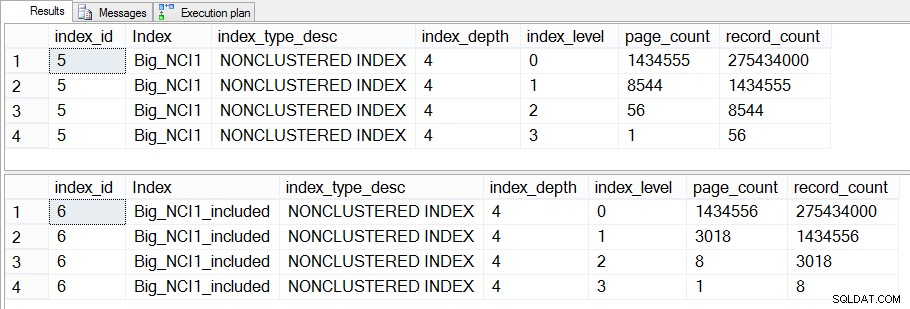
Grootte van indexen (niveauspecifiek) op Sales.Big_SalesOrderHeader
Het verschil tussen de tussenliggende niveaus van de twee indexen is 43 MB, wat misschien niet significant is, maar ik zou waarschijnlijk nog steeds geneigd zijn om de index te maken met de meegeleverde kolommen om ruimte te besparen - zowel op de schijf als in het geheugen. Vanuit een queryperspectief zien we nog steeds geen grote prestatieverandering tussen de index met alle kolommen in de sleutel en de index met de opgenomen kolommen.
Test 3
Laten we voor deze test de zoekopdracht wijzigen en een filter toevoegen voor [SubTotal] >= 100 naar de WHERE-clausule:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
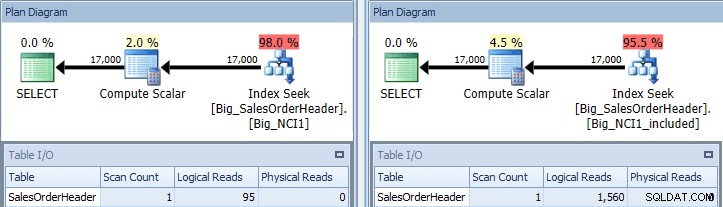
Uitvoeringsplan van query met SubTotal-predikaat tegen beide indexen
Nu zien we een verschil in I/O (95 reads versus 1.560), kosten (0,848 versus 1.55) en een subtiel maar opmerkelijk verschil in het queryplan. Bij gebruik van de index met alle kolommen in de sleutel, is het zoekpredikaat de Klant-ID en het Subtotaal:
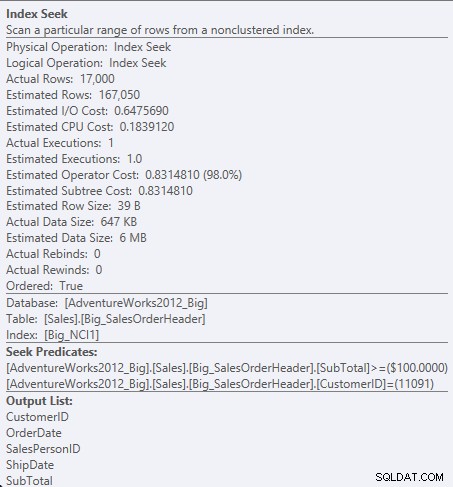
Zoek predikaat tegen NCI1
Omdat SubTotaal de tweede kolom in de indexsleutel is, zijn de gegevens geordend en bestaat het Subtotaal in de tussenliggende niveaus van de index. De engine kan rechtstreeks zoeken naar het eerste record met een klant-ID van 11091 en een subtotaal groter dan of gelijk aan 100, en vervolgens de index doorlezen totdat er geen records meer zijn voor de klant-ID 11091.
Voor de index met de opgenomen kolommen bestaat het SubTotaal alleen op het bladniveau van de index, dus CustomerID is het zoekpredikaat en SubTotaal is een restpredikaat (alleen vermeld als Predikaat in de schermafbeelding):
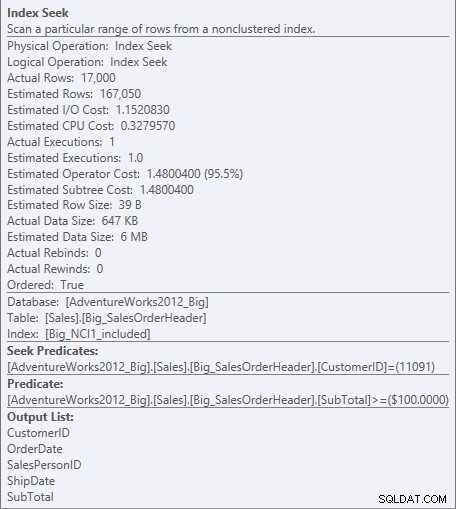
Zoek predikaat en restpredikaat tegen NCI1_included
De engine kan direct zoeken naar het eerste record waar CustomerID 11091 is, maar dan moet het naar elke kijken record voor CustomerID 11091 om te zien of het Subtotaal 100 of hoger is, omdat de gegevens zijn geordend op CustomerID en SalesOrderID (clustersleutel).
Test 4
We proberen nog een variant van onze zoekopdracht, en deze keer voegen we een ORDER BY toe:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
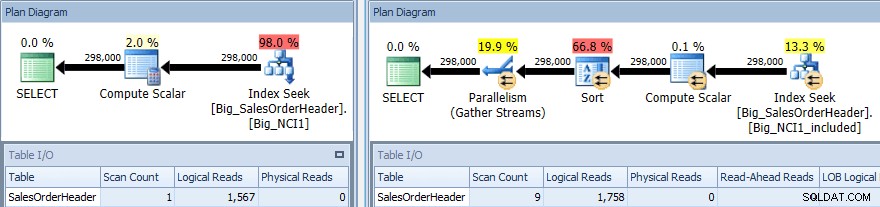
Uitvoeringsplan van query met SORT tegen beide indexen
Wederom hebben we een verandering in I/O (hoewel zeer klein), een verandering in kosten (1,5 versus 9,3) en een veel grotere verandering in de vorm van het plan; we zien ook een groter aantal scans (1 vs 9). De query vereist dat de gegevens worden gesorteerd op SubTotaal; wanneer SubTotaal deel uitmaakt van de indexsleutel, wordt het gesorteerd, dus wanneer de records voor CustomerID 11091 worden opgehaald, bevinden ze zich al in de gevraagde volgorde.
Als SubTotaal bestaat als een opgenomen kolom, moeten de records voor Klant-ID 11091 worden gesorteerd voordat ze aan de gebruiker kunnen worden geretourneerd. Daarom voegt het optimalisatieprogramma een sorteeroperator toe aan de query. Als gevolg hiervan vraagt de query die de index Big_NCI1_included gebruikt ook om een geheugentoekenning van 29.312 KB, wat opmerkelijk is (en te vinden is in de eigenschappen van het plan).
Samenvatting
De oorspronkelijke vraag die we wilden beantwoorden, was of we een prestatieverschil zouden zien wanneer een query de index met alle kolommen in de sleutel gebruikte, versus de index met de meeste kolommen in het bladniveau. In onze eerste reeks tests was er geen verschil, maar in onze derde en vierde tests wel. Het hangt uiteindelijk af van de vraag. We hebben alleen gekeken naar twee varianten - de ene had een extra predikaat, de andere had een ORDER BY - er zijn er nog veel meer.
Wat ontwikkelaars en DBA's moeten begrijpen, is dat er enkele grote voordelen zijn aan het opnemen van kolommen in een index, maar ze zullen niet altijd hetzelfde presteren als indexen die alle kolommen in de sleutel hebben. Het kan verleidelijk zijn om kolommen die geen deel uitmaken van predikaten en joins uit de sleutel te verplaatsen en ze gewoon op te nemen, om de totale grootte van de index te verkleinen. In sommige gevallen vereist dit echter meer bronnen voor het uitvoeren van query's en kunnen de prestaties afnemen. De degradatie kan onbeduidend zijn; het is misschien niet ... je zult het niet weten totdat je het test. Daarom is het bij het ontwerpen van een index belangrijk om na te denken over de kolommen na de leidende - en te begrijpen of ze deel moeten uitmaken van de sleutel (bijvoorbeeld omdat het geordend houden van de gegevens voordelen biedt) of dat ze hun doel kunnen dienen zoals opgenomen kolommen.
Zoals gebruikelijk bij indexering in SQL Server, moet u uw query's testen met uw indexen om de beste strategie te bepalen. Het blijft een kunst en een wetenschap - proberen het minimum aantal indexen te vinden om aan zoveel mogelijk vragen te voldoen.