Bij Stack Overflow hebben we enkele tabellen die geclusterde columnstore-indexen gebruiken, en deze werken prima voor het grootste deel van onze werklast. Maar we kwamen onlangs een situatie tegen waarin "perfecte stormen" - meerdere processen die allemaal van dezelfde CCI proberen te verwijderen - de CPU zouden overweldigen omdat ze allemaal parallel gingen en vochten om hun operatie te voltooien. Zo zag het eruit in SolarWinds SQL Sentry:
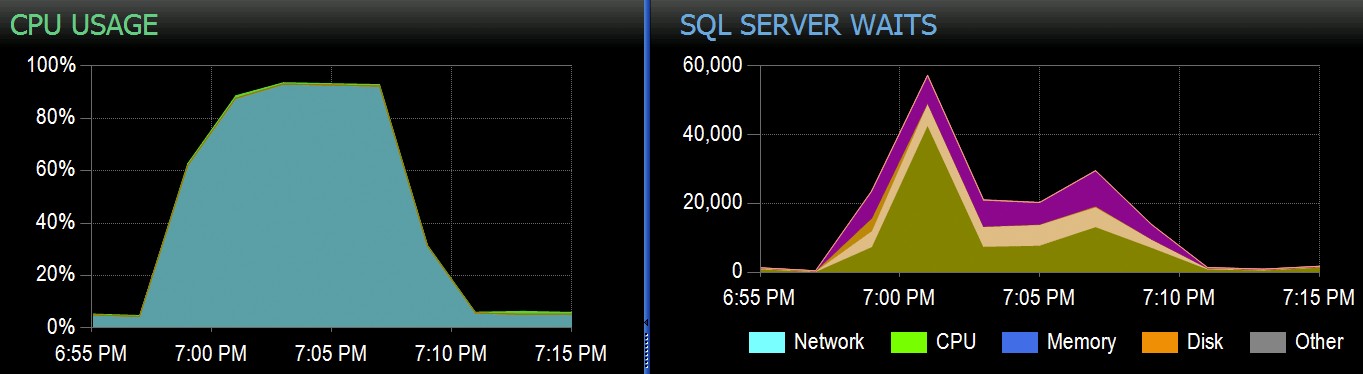
En hier zijn de interessante wachttijden die bij deze vragen horen:
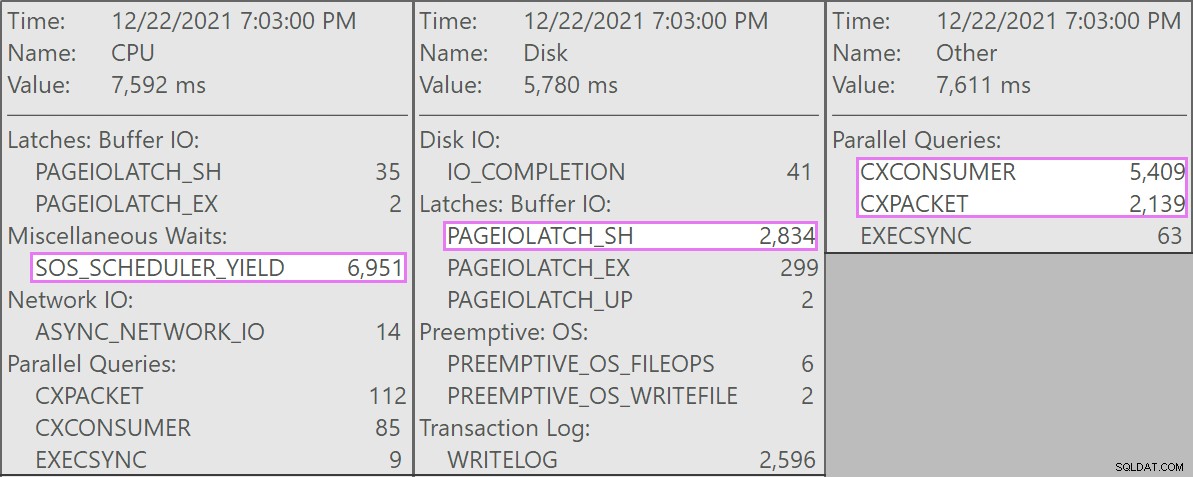
De concurrerende zoekopdrachten waren allemaal van deze vorm:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
Het plan zag er als volgt uit:

En de waarschuwing op de scan wees ons op een aantal behoorlijk extreme resterende I/O:

De tabel heeft 1,9 miljard rijen maar is slechts 32 GB (bedankt, kolomopslag!). Toch zouden deze verwijderingen van één rij elk 10 – 15 seconden duren, waarbij het grootste deel van deze tijd wordt besteed aan SOS_SCHEDULER_YIELD .
Gelukkig, aangezien in dit scenario de verwijderbewerking asynchroon zou kunnen zijn, konden we het probleem oplossen met twee wijzigingen (hoewel ik het hier enorm simplificeer):
- We hebben
MAXDOPbeperkt op databaseniveau, dus deze verwijderingen kunnen niet zo parallel gaan - We hebben de serialisatie van de processen die uit de applicatie komen verbeterd (in feite hebben we verwijderingen in de wachtrij geplaatst via een enkele dispatcher)
Als DBA kunnen we eenvoudig MAXDOP . beheren , tenzij het wordt overschreven op het queryniveau (nog een konijnenhol voor een andere dag). We hebben niet noodzakelijkerwijs controle over de toepassing in deze mate, vooral als deze wordt gedistribueerd of niet van ons. Hoe kunnen we de schrijfbewerkingen in dit geval serialiseren zonder de toepassingslogica drastisch te veranderen?
Een schijnopstelling
Ik ga niet proberen om lokaal een tabel van twee miljard rijen te maken — laat staan de exacte tabel — maar we kunnen iets op kleinere schaal benaderen en proberen hetzelfde probleem te reproduceren.
Laten we doen alsof dit de SuggestedEdits . is tafel (in werkelijkheid is het dat niet). Maar het is een eenvoudig voorbeeld om te gebruiken omdat we het schema uit de Stack Exchange Data Explorer kunnen halen. Als we dit als basis gebruiken, kunnen we een equivalente tabel maken (met een paar kleine wijzigingen om het vullen gemakkelijker te maken) en er een geclusterde columnstore-index op gooien:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Om het te vullen met 100 miljoen rijen, kunnen we cross join sys.all_objects en sys.all_columns vijf keer (op mijn systeem levert dit elke keer 2,68 miljoen rijen op, maar YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Dan kunnen we de spatie controleren:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
Het is slechts 1,3 GB, maar dit zou voldoende moeten zijn:

Onze geclusterde Columnstore-verwijdering nabootsen
Hier is een eenvoudige vraag die ongeveer overeenkomt met wat onze applicatie met de tafel deed:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
Het plan is echter niet helemaal een perfecte match:
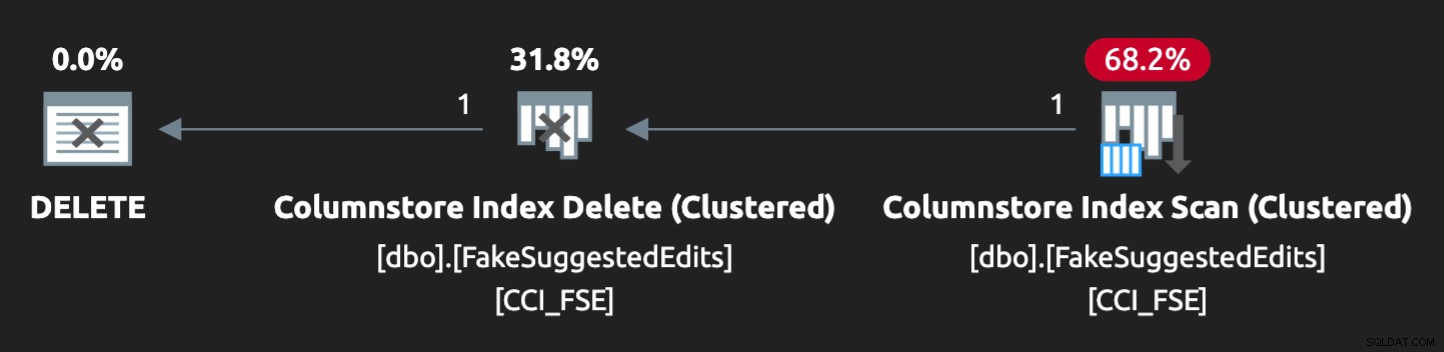
Om het parallel te laten lopen en een vergelijkbare strijd op mijn magere laptop te produceren, moest ik de optimizer een beetje dwingen met deze hint:
OPTION (QUERYTRACEON 8649);
Nu ziet het er goed uit:

Het probleem reproduceren
Vervolgens kunnen we een toename van gelijktijdige verwijderingsactiviteit creëren met SqlStressCmd om 1.000 willekeurige rijen te verwijderen met 16 en 32 threads:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
We kunnen de belasting observeren die dit op de CPU legt:
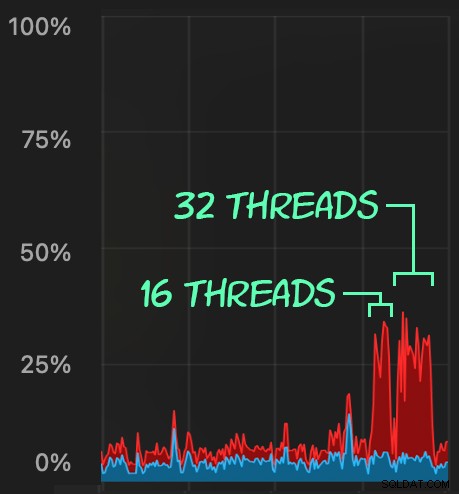
De belasting van de CPU duurt gedurende de batches van respectievelijk ongeveer 64 en 130 seconden:
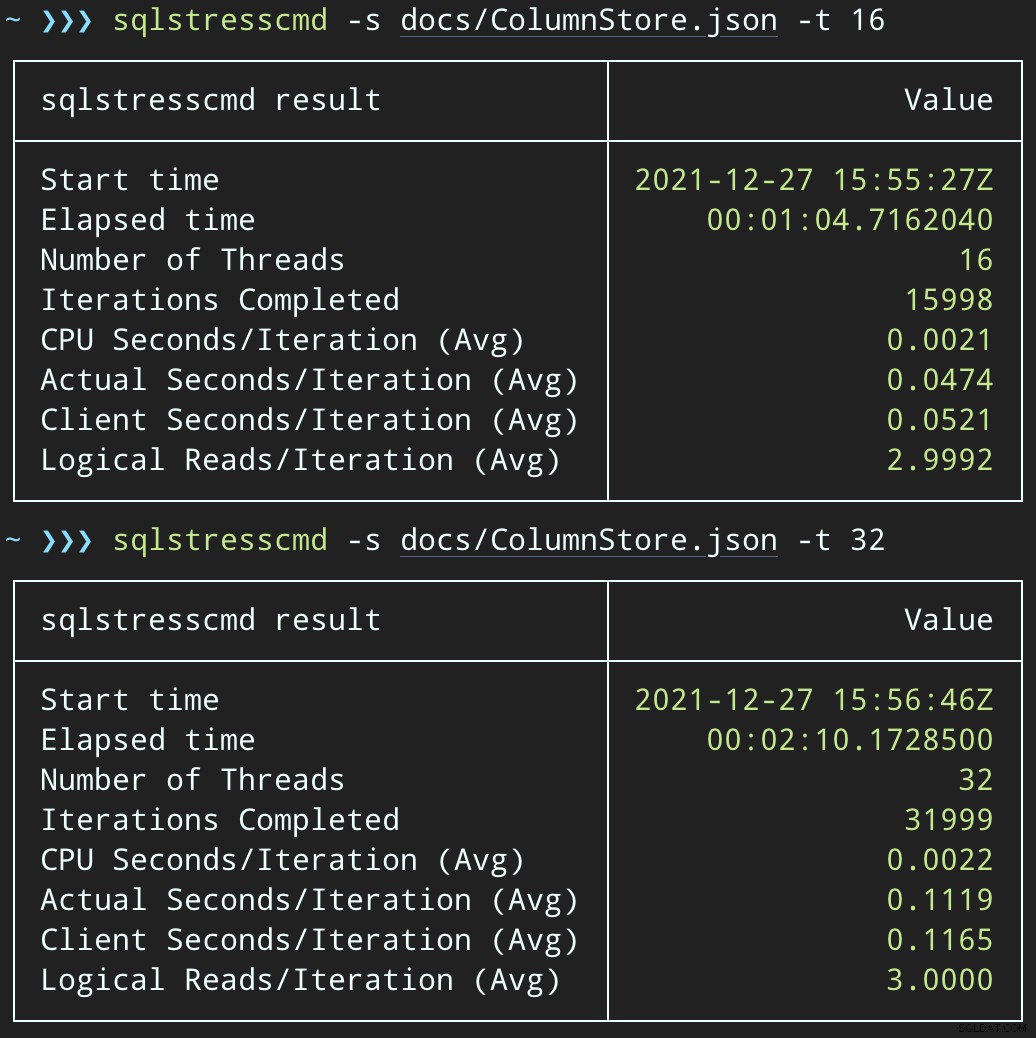
Opmerking:de uitvoer van SQLQueryStress is soms een beetje afwijkend bij herhalingen, maar ik heb bevestigd dat het werk dat u het vraagt, precies wordt gedaan.
Een mogelijke oplossing:een verwijderwachtrij
Aanvankelijk dacht ik erover om een wachtrijtabel in de database te introduceren, die we zouden kunnen gebruiken om verwijderingsactiviteiten te ontlasten:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Alles wat we nodig hebben is een IN PLAATS VAN een trigger om deze frauduleuze verwijderingen die uit de applicatie komen te onderscheppen en ze in de wachtrij te plaatsen voor verwerking op de achtergrond. Helaas kunt u geen trigger maken voor een tabel met een geclusterde columnstore-index:
Msg 35358, Level 16, State 1CREATE TRIGGER op tabel 'dbo.FakeSuggestedEdits' is mislukt omdat u geen trigger kunt maken voor een tabel met een geclusterde columnstore-index. Overweeg om de logica van de trigger op een andere manier af te dwingen, of als u een trigger moet gebruiken, gebruik in plaats daarvan een heap- of B-tree-index.
We hebben een minimale wijziging in de applicatiecode nodig, zodat deze een opgeslagen procedure aanroept om het verwijderen af te handelen:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Dit is geen permanente toestand; dit is gewoon om het gedrag hetzelfde te houden terwijl je slechts één ding in de app verandert. Zodra de app is gewijzigd en deze opgeslagen procedure met succes aanroept in plaats van ad hoc verwijderquery's in te dienen, kan de opgeslagen procedure veranderen:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
De impact van de wachtrij testen
Als we nu SqlQueryStress veranderen om in plaats daarvan de opgeslagen procedure aan te roepen:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
En dien gelijkaardige batches in (plaatst 16K of 32K rijen in de wachtrij):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
De CPU-impact is iets hoger:
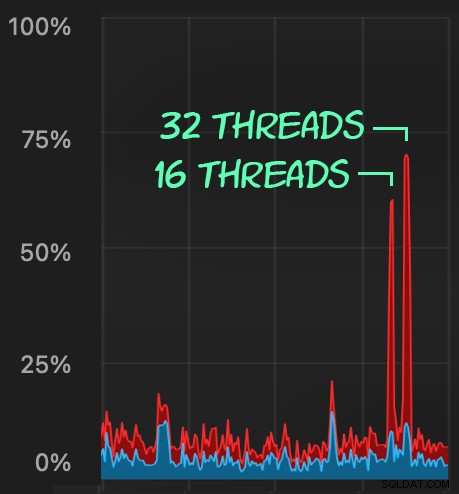
Maar de workloads zijn veel sneller klaar — respectievelijk 16 en 23 seconden:
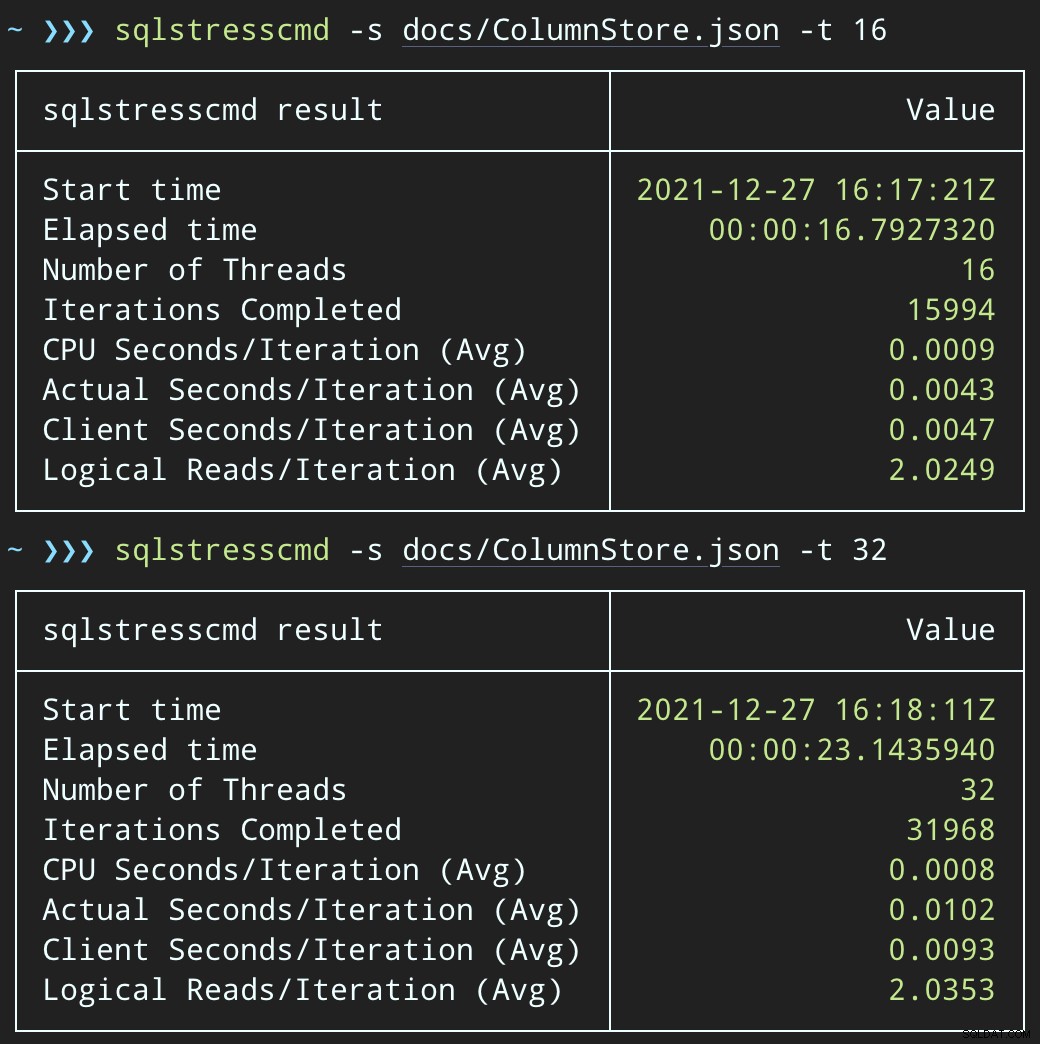
Dit is een aanzienlijke vermindering van de pijn die de applicaties zullen voelen als ze in perioden van hoge gelijktijdigheid komen.
We moeten de verwijdering echter nog steeds uitvoeren
We moeten die verwijderingen nog steeds op de achtergrond verwerken, maar we kunnen nu batching introduceren en volledige controle hebben over de snelheid en eventuele vertragingen die we tussen bewerkingen willen injecteren. Hier is de basisstructuur van een opgeslagen procedure om de wachtrij te verwerken (weliswaar zonder volledig verworven transactiecontrole, foutafhandeling of het opschonen van wachtrijtabellen):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END Het verwijderen van rijen duurt nu langer:het gemiddelde van 10.000 rijen is 223 seconden, waarvan ongeveer 100 opzettelijke vertraging. Maar er zit geen gebruiker te wachten, dus wat maakt het uit? Het CPU-profiel is bijna nul en de app kan doorgaan met het toevoegen van items aan de wachtrij zo gelijktijdig als hij wil, met bijna geen conflicten met de achtergrondtaak. Terwijl ik 10.000 rijen verwerkte, voegde ik nog eens 16K rijen toe aan de wachtrij, en het gebruikte dezelfde CPU als voorheen — het duurde slechts een seconde langer dan wanneer de taak niet actief was:
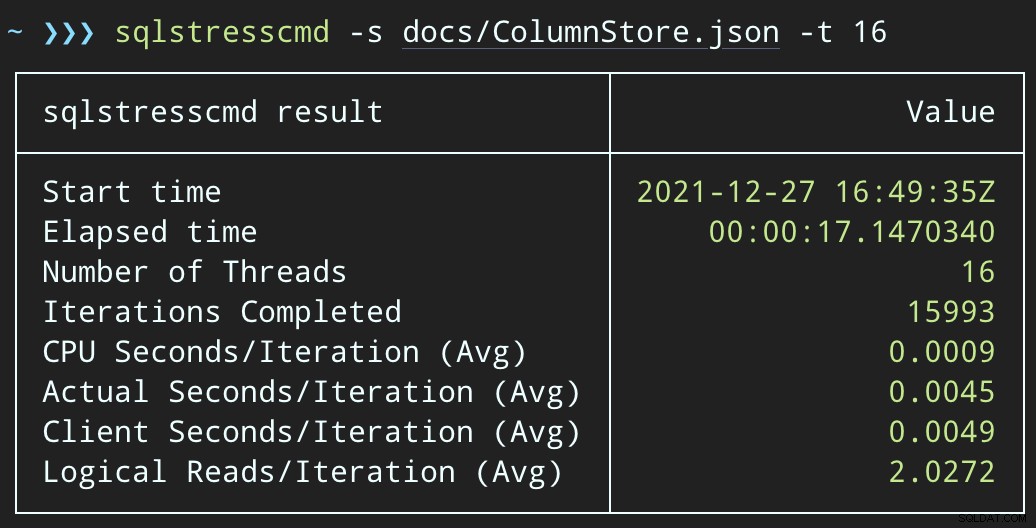
En het plan ziet er nu zo uit, met veel betere geschatte / werkelijke rijen:
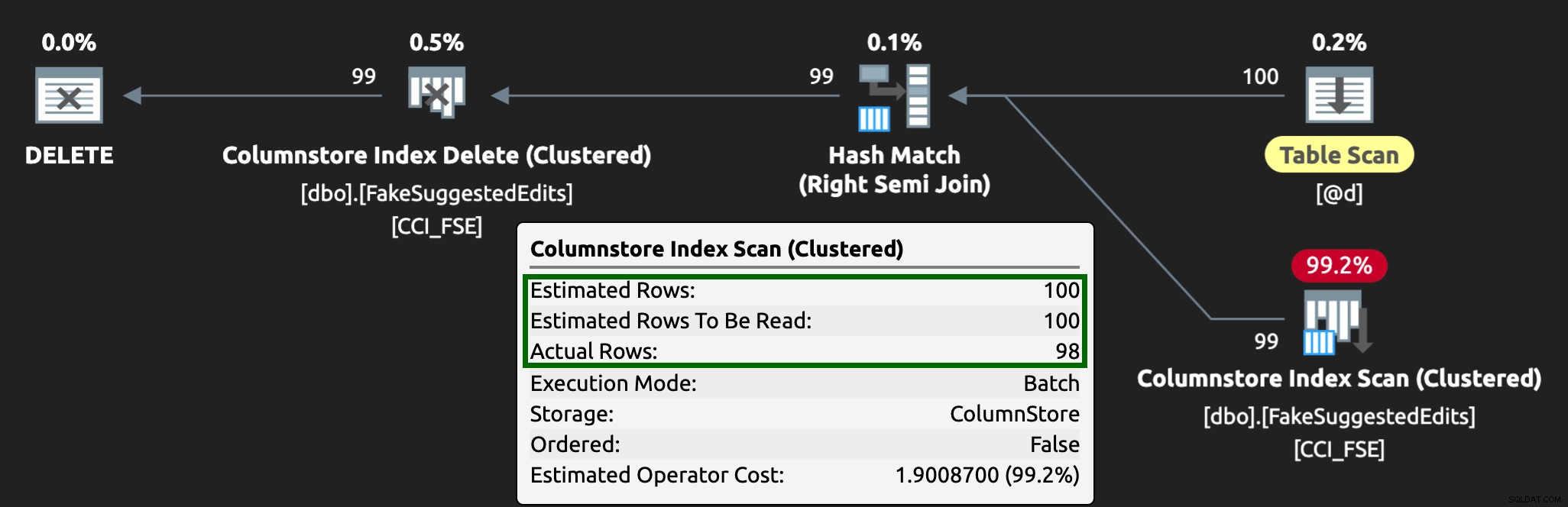
Ik kan zien dat deze wachtrijtabelbenadering een effectieve manier is om met hoge DML-gelijktijdigheid om te gaan, maar het vereist op zijn minst een beetje flexibiliteit met de applicaties die DML indienen - dit is een reden waarom ik het erg leuk vind als applicaties opgeslagen procedures aanroepen, omdat ze geef ons veel meer controle dichter bij de gegevens.
Andere opties
Als u de verwijderingsquery's die afkomstig zijn van de toepassing niet kunt wijzigen, of als u de verwijderingen niet kunt uitstellen tot een achtergrondproces, kunt u andere opties overwegen om de impact van de verwijderingen te verminderen:
- Een niet-geclusterde index op de predikaatkolommen om puntzoekacties te ondersteunen (we kunnen dit afzonderlijk doen zonder de toepassing te wijzigen)
- Alleen zachte verwijderingen gebruiken (vereist nog steeds wijzigingen in de applicatie)
Het zal interessant zijn om te zien of deze opties vergelijkbare voordelen bieden, maar ik bewaar ze voor een volgende post.