Mijn vriend Peter Larsson stuurde me een T-SQL-uitdaging waarbij vraag en aanbod worden afgestemd. Wat uitdagingen betreft, het is een formidabele. Het is een vrij veel voorkomende behoefte in het echte leven; het is eenvoudig te beschrijven en het is vrij eenvoudig op te lossen met redelijke prestaties met behulp van een op een cursor gebaseerde oplossing. Het lastige is om het op te lossen met een efficiënte set-gebaseerde oplossing.
Als Peter me een puzzel stuurt, reageer ik meestal met een voorgestelde oplossing, en hij komt meestal met een beter presterende, briljante oplossing. Ik vermoed soms dat hij me puzzels stuurt om zichzelf te motiveren om met een geweldige oplossing te komen.
Omdat de taak een veelvoorkomende behoefte vertegenwoordigt en zo interessant is, vroeg ik Peter of hij het erg zou vinden als ik de taak en zijn oplossingen met de lezers van sqlperformance.com zou delen, en hij was blij dat ik dat mocht.
Deze maand presenteer ik de uitdaging en de klassieke cursorgebaseerde oplossing. In volgende artikelen zal ik op sets gebaseerde oplossingen presenteren, inclusief de oplossingen waaraan Peter en ik hebben gewerkt.
De uitdaging
De uitdaging bestaat uit het opvragen van een tabel met de naam Auctions, die u maakt met behulp van de volgende code:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Deze tabel bevat vraag- en aanbodposten. Vraaginvoeren zijn gemarkeerd met de code D en aanbodinvoeringen met S. Uw taak is om vraag- en aanbodhoeveelheden op elkaar af te stemmen op basis van ID-bestelling, en het resultaat in een tijdelijke tabel te schrijven. De vermeldingen kunnen koop- en verkooporders voor cryptocurrency vertegenwoordigen, zoals BTC/USD, aandelenkoop- en verkooporders zoals MSFT/USD, of elk ander item of goed waarbij u vraag en aanbod moet afstemmen. Merk op dat de Veilingen-items een prijskenmerk missen. Zoals vermeld, moet u de vraag- en aanbodhoeveelheden afstemmen op basis van ID-bestelling. Deze volgorde kan zijn afgeleid van prijs (oplopend voor invoer van aanbod en aflopend voor invoer van vraag) of andere relevante criteria. Bij deze uitdaging was het de bedoeling om het simpel te houden en aan te nemen dat de ID al de relevante volgorde voor het matchen vertegenwoordigt.
Gebruik als voorbeeld de volgende code om de tabel Veilingen te vullen met een kleine set voorbeeldgegevens:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Het is de bedoeling dat je de vraag- en aanbodhoeveelheden als volgt op elkaar afstemt:
- Een hoeveelheid van 5,0 komt overeen met vraag 1 en aanbod 1000, waardoor vraag 1 opraakt en 3,0 van aanbod 1000 overblijft
- Een hoeveelheid van 3,0 wordt geëvenaard voor vraag 2 en aanbod 1000, waardoor zowel vraag 2 als aanbod 1000 wordt uitgeput
- Een hoeveelheid van 6,0 wordt geëvenaard voor vraag 3 en aanbod 2000, waardoor 2,0 van vraag 3 overblijft en aanbod 2000 opraakt
- Een hoeveelheid van 2,0 wordt geëvenaard voor vraag 3 en aanbod 3000, waardoor zowel vraag 3 als aanbod 3000 uitgeput raken
- Een hoeveelheid van 2,0 komt overeen met vraag 5 en aanbod 4000, waardoor zowel vraag 5 als aanbod 4000 wordt uitgeput
- Een hoeveelheid van 4,0 komt overeen met vraag 6 en aanbod 5000, waardoor 4,0 van vraag 6 overblijft en aanbod 5000 opraakt
- Een hoeveelheid van 3,0 komt overeen met vraag 6 en aanbod 6000, waardoor 1,0 van vraag 6 overblijft en aanbod 6000 opraakt
- Een hoeveelheid van 1,0 komt overeen met vraag 6 en aanbod 7000, waardoor vraag 6 wordt uitgeput en 1,0 van aanbod 7000 overblijft
- Een hoeveelheid van 1,0 komt overeen met vraag 7 en aanbod 7000, waardoor 3,0 van vraag 7 overblijft en aanbod 7000 opraakt; Vraag 8 komt niet overeen met leveringsitems en blijft daarom over met de volledige hoeveelheid 2,0
Uw oplossing zou de volgende gegevens in de resulterende tijdelijke tabel moeten schrijven:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Grote reeks voorbeeldgegevens
Om de prestaties van de oplossingen te testen, hebt u een grotere set voorbeeldgegevens nodig. Om hierbij te helpen, kunt u de functie GetNums gebruiken, die u maakt door de volgende code uit te voeren:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Deze functie retourneert een reeks gehele getallen in het gevraagde bereik.
Als deze functie is ingeschakeld, kunt u de volgende code gebruiken die door Peter is geleverd om de veilingtabel te vullen met voorbeeldgegevens en de invoer naar behoefte aan te passen:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Zoals u kunt zien, kunt u het aantal kopers en verkopers aanpassen, evenals de minimale en maximale hoeveelheden voor kopers en verkopers. De bovenstaande code specificeert 200.000 kopers en 200.000 verkopers, wat resulteert in een totaal van 400.000 rijen in de veilingtabel. De laatste query vertelt u hoeveel vraag- (D) en aanbod (S)-items naar de tabel zijn geschreven. Het retourneert de volgende uitvoer voor de bovengenoemde ingangen:
Code Items ---- ----------- D 200000 S 200000
Ik ga de prestaties van verschillende oplossingen testen met behulp van de bovenstaande code, waarbij ik het aantal kopers en verkopers elk op het volgende stel:50.000, 100.000, 150.000 en 200.000. Dit betekent dat ik het volgende totale aantal rijen in de tabel krijg:100.000, 200.000, 300.000 en 400.000. Natuurlijk kunt u de invoer naar wens aanpassen om de prestaties van uw oplossingen te testen.
Op cursor gebaseerde oplossing
Peter zorgde voor de cursorgebaseerde oplossing. Het is vrij eenvoudig, wat een van de belangrijke voordelen is. Het zal als benchmark worden gebruikt.
De oplossing maakt gebruik van twee cursors:één voor vraaginvoeren die op ID zijn geordend en de andere voor leveringsinvoeren die op ID zijn geordend. Maak de volgende index om een volledige scan en een sortering per cursor te vermijden:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Hier is de code van de volledige oplossing:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Zoals je kunt zien, begint de code met het maken van een tijdelijke tabel. Vervolgens declareert het de twee cursors en haalt uit elk een rij op, waarbij de huidige vraaghoeveelheid wordt geschreven naar de variabele @DemandQuantity en de huidige aanbodhoeveelheid naar @SupplyQuantity. Vervolgens verwerkt het de invoer in een lus zolang de laatste ophaalactie succesvol was. De code past de volgende logica toe in de body van de lus:
Als de huidige vraaghoeveelheid kleiner is dan of gelijk is aan de huidige aanbodhoeveelheid, doet de code het volgende:
- Schrijft een rij in de tijdelijke tabel met de huidige koppeling, met de gevraagde hoeveelheid (@DemandQuantity) als de overeenkomende hoeveelheid
- Trekt de huidige vraaghoeveelheid af van de huidige aanbodhoeveelheid (@SupplyQuantity)
- Haalt de volgende rij op van de vraagcursor
Anders doet de code het volgende:
- Controleert of de huidige leveringshoeveelheid groter is dan nul, en zo ja, doet het het volgende:
- Schrijft een rij in de tijdelijke tabel met de huidige koppeling, met de leveringshoeveelheid als de overeenkomende hoeveelheid
- Trekt de huidige aanbodhoeveelheid af van de huidige vraaghoeveelheid
- Haalt de volgende rij op van de aanbodcursor
Zodra de lus is voltooid, zijn er geen paren meer om te matchen, dus de code ruimt alleen de cursorbronnen op.
Vanuit het oogpunt van prestaties krijg je de typische overhead van het ophalen en herhalen van de cursor. Aan de andere kant voert deze oplossing een enkele orderpassage uit over de vraaggegevens en een enkele orderpassage over de aanbodgegevens, elk met behulp van een zoek- en bereikscan in de index die u eerder hebt gemaakt. De plannen voor de cursorquery's worden getoond in figuur 1.

Figuur 1:Plannen voor cursorquery's
Aangezien het plan een zoek- en bestelbereikscan uitvoert van elk van de onderdelen (vraag en aanbod) zonder dat er een sortering aan te pas komt, heeft het een lineaire schaal. Dit werd bevestigd door de prestatiecijfers die ik kreeg bij het testen, zoals weergegeven in figuur 2.
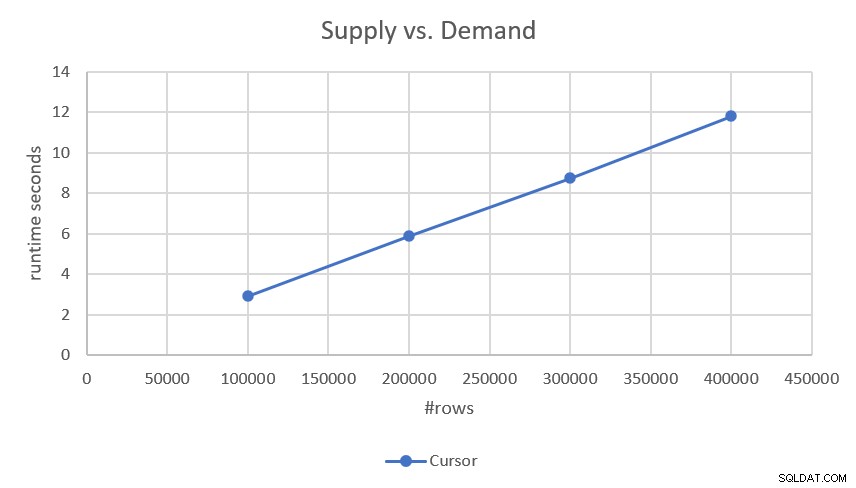
Figuur 2:Prestaties van op cursor gebaseerde oplossing
Als je geïnteresseerd bent in de preciezere looptijden, hier zijn ze:
- 100.000 rijen (50.000 aanvragen en 50.000 benodigdheden):2,93 seconden
- 200.000 rijen:5,89 seconden
- 300.000 rijen:8,75 seconden
- 400.000 rijen:11,81 seconden
Aangezien de oplossing lineaire schaal heeft, kunt u de looptijd eenvoudig voorspellen met andere schalen. Met een miljoen rijen (bijvoorbeeld 500.000 aanvragen en 500.000 leveringen) zou het ongeveer 29,5 seconden duren om te draaien.
De uitdaging is begonnen
De op cursor gebaseerde oplossing heeft lineaire schaling en is als zodanig niet slecht. Maar het brengt wel de typische cursor-ophaal- en looping-overhead met zich mee. Het is duidelijk dat u deze overhead kunt verminderen door hetzelfde algoritme te implementeren met een op CLR gebaseerde oplossing. De vraag is, kun je een goed presterende set-gebaseerde oplossing bedenken voor deze taak?
Zoals gezegd, zal ik vanaf volgende maand op set gebaseerde oplossingen onderzoeken, zowel slecht presterende als goed presterende. Als je ondertussen de uitdaging aankunt, kijk dan of je zelf op set gebaseerde oplossingen kunt bedenken.
Om de juistheid van uw oplossing te controleren, vergelijkt u eerst het resultaat met het resultaat dat hier wordt weergegeven voor de kleine set voorbeeldgegevens. U kunt ook de geldigheid van het resultaat van uw oplossing controleren met een grote set voorbeeldgegevens door te controleren of het symmetrische verschil tussen het resultaat van de cursoroplossing en dat van u leeg is. Ervan uitgaande dat het resultaat van de cursor is opgeslagen in een tijdelijke tabel met de naam #PairingsCursor en die van u in een tijdelijke tabel met de naam #MyPairings, kunt u de volgende code gebruiken om dit te bereiken:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Het resultaat zou leeg moeten zijn.
Veel succes!
[ Ga naar oplossingen:Deel 1 | Deel 2 | Deel 3 ]