Gelijktijdigheidsproblemen zijn net zo moeilijk als programmeren met meerdere threads moeilijk is. Tenzij serialiseerbare isolatie wordt gebruikt, kan het moeilijk zijn om T-SQL-transacties te coderen die altijd correct zullen werken wanneer andere gebruikers tegelijkertijd wijzigingen in de database aanbrengen.
De potentiële problemen kunnen niet triviaal zijn, zelfs als de 'transactie' in kwestie een eenvoudige enkele SELECT is uitspraak. Voor complexe multi-statementtransacties die gegevens lezen en schrijven, kan het potentieel voor onverwachte resultaten en fouten bij hoge gelijktijdigheid snel overweldigend worden. Proberen om subtiele en moeilijk te reproduceren gelijktijdigheidsproblemen op te lossen door willekeurige vergrendelingshints of andere trial-and-error-methoden toe te passen, kan een uiterst frustrerende ervaring zijn.
In veel opzichten lijkt het snapshot-isolatieniveau een perfecte oplossing voor deze gelijktijdigheidsproblemen. Het basisidee is dat elke snapshot-transactie zich gedraagt alsof deze is uitgevoerd tegen zijn eigen privékopie van de vastgelegde status van de database, genomen op het moment dat de transactie begon. Door de hele transactie een onveranderlijk beeld te geven van vastgelegde gegevens, worden uiteraard consistente resultaten gegarandeerd voor alleen-lezen bewerkingen, maar hoe zit het met transacties die gegevens wijzigen?
Snapshot-isolatie gaat optimistisch om met gegevenswijzigingen, impliciet ervan uitgaande dat conflicten tussen gelijktijdige schrijvers relatief zeldzaam zullen zijn. Waar een schrijfconflict optreedt, wint de eerste committer en worden de wijzigingen van de verliezende transactie teruggedraaid. Het is natuurlijk jammer voor de teruggedraaide transactie, maar als dit maar zelden voorkomt, kunnen de voordelen van snapshot-isolatie gemakkelijk opwegen tegen de kosten van een incidentele mislukking en opnieuw proberen.
De relatief eenvoudige en schone semantiek van snapshot-isolatie (in vergelijking met de alternatieven) kan een aanzienlijk voordeel zijn, vooral voor mensen die niet uitsluitend in de databasewereld werken en daarom de verschillende isolatieniveaus niet goed kennen. Zelfs voor ervaren databaseprofessionals kan een relatief 'intuïtief' isolatieniveau een welkome opluchting zijn.
Natuurlijk zijn dingen zelden zo eenvoudig als ze op het eerste gezicht lijken, en het isoleren van snapshots is geen uitzondering. De officiële documentatie beschrijft redelijk goed de belangrijkste voor- en nadelen van het isoleren van snapshots, dus het grootste deel van dit artikel concentreert zich op het onderzoeken van enkele van de minder bekende en verrassende problemen die u tegen kunt komen. Maar eerst een snelle blik op de logische eigenschappen van dit isolatieniveau:
ACID-eigenschappen en momentopname-isolatie
Snapshot-isolatie is niet een van de isolatieniveaus die zijn gedefinieerd in de SQL-standaard, maar wordt nog steeds vaak vergeleken met behulp van de daar gedefinieerde 'concurrency-fenomenen'. De volgende vergelijkingstabel is bijvoorbeeld overgenomen uit het technische artikel van SQL Server, "SQL Server 2005 Row Versioning-Based Transaction Isolation" door Kimberly L. Tripp en Neal Graves:
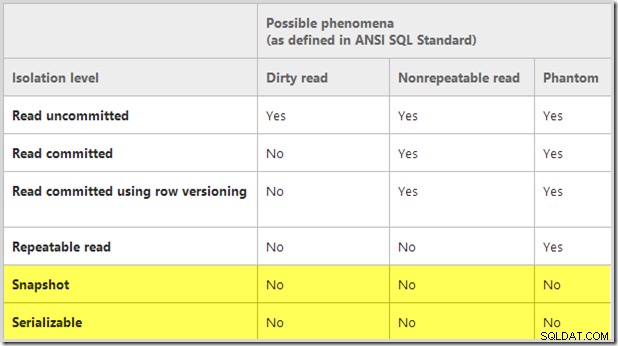
Door een point-in-time weergave . te geven van toegewezen gegevens , snapshot-isolatie biedt bescherming tegen alle drie gelijktijdigheidsfenomenen die daar worden getoond. Vuile leesbewerkingen worden voorkomen omdat alleen vastgelegde gegevens zichtbaar zijn, en de statische aard van de momentopname voorkomt dat zowel niet-herhaalbare leesbewerkingen als fantomen worden aangetroffen.
Deze vergelijking (en de gemarkeerde sectie in het bijzonder) toont echter alleen aan dat de snapshot- en serialiseerbare isolatieniveaus dezelfde drie specifieke fenomenen voorkomen. Het betekent niet dat ze in alle opzichten gelijkwaardig zijn. Belangrijk is dat de SQL-92-standaard geen serialiseerbare isolatie definieert in termen van de drie fenomenen alleen. Paragraaf 4.28 van de norm geeft de volledige definitie:
Het uitvoeren van gelijktijdige SQL-transacties op isolatieniveau SERIALIZABLE is gegarandeerd serializeerbaar. Een serialiseerbare uitvoering wordt gedefinieerd als een uitvoering van de bewerkingen van het gelijktijdig uitvoeren van SQL-transacties die hetzelfde effect produceert als een seriële uitvoering van diezelfde SQL-transacties. Een seriële uitvoering is een uitvoering waarbij elke SQL-transactie volledig wordt uitgevoerd voordat de volgende SQL-transactie begint.
De omvang en het belang van de impliciete garanties worden hier vaak over het hoofd gezien. Om het in eenvoudige taal te zeggen:
Elke serialiseerbare transactie die correct wordt uitgevoerd wanneer deze alleen wordt uitgevoerd, blijft correct worden uitgevoerd met elke combinatie van gelijktijdige transacties, of wordt teruggedraaid met een foutmelding (meestal een impasse in de implementatie van SQL Server).
Niet-serializeerbare isolatieniveaus, inclusief snapshot-isolatie, bieden niet dezelfde sterke garanties voor correctheid.
Verouderde gegevens
Snapshot-isolatie lijkt bijna verleidelijk eenvoudig. Lezingen zijn altijd afkomstig van vastgelegde gegevens vanaf een enkel tijdstip, en schrijfconflicten worden automatisch gedetecteerd en afgehandeld. Hoe komt het dat dit geen perfecte oplossing is voor alle gelijktijdigheidsgerelateerde problemen?
Een mogelijk probleem is dat het lezen van snapshots niet noodzakelijk de huidige vastgelegde status van de database weerspiegelt. Een momentopnametransactie negeert alle vastgelegde wijzigingen die zijn aangebracht door andere gelijktijdige transacties nadat de momentopnametransactie is begonnen. Een andere manier om dat te zeggen is om te zeggen dat een momentopnametransactie oude, verouderde gegevens ziet. Hoewel dit gedrag misschien precies is wat nodig is om een nauwkeurig point-in-time rapport te genereren, is het in andere omstandigheden misschien niet zo geschikt (bijvoorbeeld wanneer het wordt gebruikt om een regel in een trigger af te dwingen).
Schrijf scheef
Snapshot-isolatie is ook kwetsbaar voor een enigszins gerelateerd fenomeen dat bekend staat als schrijffout. Het lezen van verouderde gegevens speelt hierbij een rol, maar dit probleem helpt ook te verduidelijken wat snapshot 'schrijfconflictdetectie' wel en niet doet.
Schrijfscheefheid treedt op wanneer twee gelijktijdige transacties elk gegevens lezen die de andere transactie wijzigt. Er treedt geen schrijfconflict op omdat de twee transacties verschillende rijen wijzigen. Geen van beide transacties ziet de wijzigingen die door de andere zijn aangebracht, omdat beide worden gelezen vanaf een tijdstip voordat die wijzigingen werden aangebracht.
Een klassiek voorbeeld van scheef schrijven is het probleem van wit en zwart marmer, maar ik wil hier nog een eenvoudig voorbeeld laten zien:
-- Create two empty tables CREATE TABLE A (x integer NOT NULL); CREATE TABLE B (x integer NOT NULL); -- Connection 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; INSERT A (x) SELECT COUNT_BIG(*) FROM B; -- Connection 2 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; INSERT B (x) SELECT COUNT_BIG(*) FROM A; COMMIT TRANSACTION; -- Connection 1 COMMIT TRANSACTION;
Bij snapshot-isolatie eindigen beide tabellen in dat script met een enkele rij met een nulwaarde. Dit is een correct resultaat, maar het is niet serialiseerbaar:het komt niet overeen met een mogelijke uitvoeringsopdracht voor seriële transacties. In elk echt serieel schema moet de ene transactie worden voltooid voordat de andere begint, dus de tweede transactie telt de rij die door de eerste is ingevoegd. Dit klinkt misschien als een technisch detail, maar onthoud dat de krachtige serialiseerbare garanties alleen van toepassing zijn wanneer transacties echt serialiseerbaar zijn.
Een subtiliteit van conflictdetectie
Een momentopname-schrijfconflict treedt op wanneer een momentopname-transactie probeert een rij te wijzigen die is gewijzigd door een andere transactie die is vastgelegd nadat de momentopname-transactie is begonnen. Er zijn hier twee subtiliteiten:
- De transacties hoeven eigenlijk niet te veranderen eventuele gegevenswaarden; en
- De transacties hoeven geen algemene kolommen te wijzigen .
Het volgende script demonstreert beide punten:
-- Test table
CREATE TABLE dbo.Conflict
(
ID1 integer UNIQUE,
Value1 integer NOT NULL,
ID2 integer UNIQUE,
Value2 integer NOT NULL
);
-- Insert one row
INSERT dbo.Conflict
(ID1, ID2, Value1, Value2)
VALUES
(1, 1, 1, 1);
-- Connection 1
BEGIN TRANSACTION;
UPDATE dbo.Conflict
SET Value1 = 1
WHERE ID1 = 1;
-- Connection 2
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRANSACTION;
UPDATE dbo.Conflict
SET Value2 = 1
WHERE ID2 = 1;
-- Connection 1
COMMIT TRANSACTION; Let op het volgende:
- Elke transactie lokaliseert dezelfde rij met een andere index
- Geen update resulteert in een wijziging van de reeds opgeslagen gegevens
- De twee transacties 'updaten' verschillende kolommen in de rij.
Ondanks dat alles, wanneer de eerste transactie wordt uitgevoerd, eindigt de tweede transactie met een update-conflictfout:
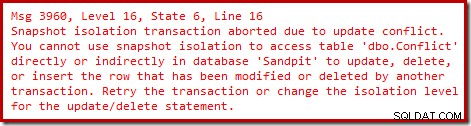
Samenvatting:Conflictdetectie werkt altijd op het niveau van een hele rij, en een 'update' hoeft eigenlijk geen gegevens te wijzigen. (Voor het geval u zich dit afvroeg, wijzigingen in off-row LOB- of SLOB-gegevens tellen ook als een wijziging in de rij voor conflictdetectiedoeleinden).
Het Foreign Key-probleem
Conflictdetectie is ook van toepassing op de bovenliggende rij in een externe-sleutelrelatie. Bij het wijzigen van een onderliggende rij onder snapshot-isolatie, kan een wijziging in de bovenliggende rij in een andere transactie een conflict veroorzaken. Zoals eerder is deze logica van toepassing op de hele bovenliggende rij - de bovenliggende update hoeft geen invloed te hebben op de externe sleutelkolom zelf. Elke bewerking op de onderliggende tabel die een automatische externe sleutelcontrole in het uitvoeringsplan vereist, kan resulteren in een onverwacht conflict.
Om dit te demonstreren, maakt u eerst de volgende tabellen en voorbeeldgegevens:
CREATE TABLE dbo.Dummy
(
x integer NULL
);
CREATE TABLE dbo.Parent
(
ParentID integer PRIMARY KEY,
ParentValue integer NOT NULL
);
CREATE TABLE dbo.Child
(
ChildID integer PRIMARY KEY,
ChildValue integer NOT NULL,
ParentID integer NULL FOREIGN KEY REFERENCES dbo.Parent
);
INSERT dbo.Parent
(ParentID, ParentValue)
VALUES (1, 1);
INSERT dbo.Child
(ChildID, ChildValue, ParentID)
VALUES (1, 1, 1); Voer nu het volgende uit vanaf twee afzonderlijke verbindingen zoals aangegeven in de opmerkingen:
-- Connection 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; SELECT COUNT_BIG(*) FROM dbo.Dummy; -- Connection 2 (any isolation level) UPDATE dbo.Parent SET ParentValue = 1 WHERE ParentID = 1; -- Connection 1 UPDATE dbo.Child SET ParentID = NULL WHERE ChildID = 1; UPDATE dbo.Child SET ParentID = 1 WHERE ChildID = 1;
De lezing van de dummy-tabel is er om ervoor te zorgen dat de snapshot-transactie officieel is gestart. Uitgifte van BEGIN TRANSACTION is niet genoeg om dit te doen; we moeten een soort van gegevenstoegang uitvoeren op een gebruikerstabel.
De eerste update van de onderliggende tabel veroorzaakt geen conflict omdat de verwijzende kolom wordt ingesteld op NULL vereist geen bovenliggende tabelcontrole in het uitvoeringsplan (er valt niets te controleren). De queryprocessor raakt de bovenliggende rij in het uitvoeringsplan niet aan, dus er ontstaat geen conflict.
De tweede update van de Child-tabel veroorzaakt wel een conflict omdat er automatisch een externe sleutelcontrole wordt uitgevoerd. Wanneer de bovenliggende rij wordt benaderd door de queryprocessor, wordt deze ook gecontroleerd op een updateconflict. In dit geval treedt een fout op omdat de bovenliggende rij waarnaar wordt verwezen een wijziging heeft ondergaan nadat de momentopnametransactie is gestart. Merk op dat de wijziging van de bovenliggende tabel geen invloed had op de externe sleutelkolom zelf.
Er kan ook een onverwacht conflict optreden als een wijziging in de tabel Child verwijst naar een bovenliggende rij die gemaakt is. door een gelijktijdige transactie (en die transactie die is gepleegd nadat de snapshot-transactie is gestart).
Samenvatting:een queryplan dat een automatische externe-sleutelcontrole omvat, kan een conflictfout veroorzaken als de rij waarnaar wordt verwezen enige wijziging heeft ondergaan (inclusief creatie!) sinds de momentopnametransactie is gestart.
Het probleem met de afbreektabel
Een momentopnametransactie mislukt met een fout als een tabel waartoe deze toegang heeft, is afgekapt sinds het begin van de transactie. Dit is zelfs van toepassing als de afgekapte tabel om te beginnen geen rijen had, zoals het onderstaande script laat zien:
CREATE TABLE dbo.AccessMe
(
x integer NULL
);
CREATE TABLE dbo.TruncateMe
(
x integer NULL
);
-- Connection 1
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRANSACTION;
SELECT COUNT_BIG(*) FROM dbo.AccessMe;
-- Connection 2
TRUNCATE TABLE dbo.TruncateMe;
-- Connection 1
SELECT COUNT_BIG(*) FROM dbo.TruncateMe; De laatste SELECT mislukt met de volgende fout:

Dit is een ander subtiel neveneffect om op te controleren voordat snapshot-isolatie op een bestaande database wordt ingeschakeld.
Volgende keer
De volgende (en laatste) post in deze serie gaat over het gelezen niet-gecommitteerde isolatieniveau (liefkozend bekend als "nolock").
[ Zie de index voor de hele serie ]