In mijn berichten van dit jaar heb ik de reflexmatige reacties op verschillende soorten wachten besproken, en in dit bericht ga ik verder met het thema wachtstatistieken en bespreek ik de PAGEIOLATCH_XX wacht. Ik zeg "wacht" maar er zijn echt meerdere soorten PAGEIOLATCH wacht, wat ik aan het eind heb aangegeven met de XX. De meest voorkomende voorbeelden zijn:
PAGEIOLATCH_SH– (SH zijn) wachten op een gegevensbestandspagina die van schijf naar de bufferpool wordt gebracht, zodat de inhoud kan worden gelezenPAGEIOLATCH_EXofPAGEIOLATCH_UP– (EX inclusief of UP datum) wachten op een gegevensbestandspagina die van schijf naar de bufferpool wordt gebracht, zodat de inhoud ervan kan worden gewijzigd
Hiervan is veruit het meest voorkomende type PAGEIOLATCH_SH .
Wanneer dit type wacht het meest voorkomt op een server, is de reflexmatige reactie dat het I/O-subsysteem een probleem moet hebben en dat het onderzoek daarop moet worden gericht.
Het eerste dat u moet doen, is de PAGEIOLATCH_SH . vergelijken wachttelling en duur ten opzichte van uw basislijn. Als het aantal wachttijden min of meer hetzelfde is, maar de duur van elke leeswachttijd veel langer is geworden, dan zou ik me zorgen maken over een I/O-subsysteemprobleem, zoals:
- Een verkeerde configuratie/storing op het niveau van het I/O-subsysteem
- Netwerklatentie
- Nog een I/O-werklast die conflict veroorzaakt met onze werklast
- Configuratie van synchrone I/O-subsysteem replicatie/mirroring
In mijn ervaring is het patroon vaak dat het aantal PAGEIOLATCH_SH Het aantal wachttijden is aanzienlijk toegenomen ten opzichte van de basislijn (normaal) en de wachttijd is ook toegenomen (d.w.z. de tijd voor een lees-I/O is toegenomen), omdat het grote aantal leesbewerkingen het I/O-subsysteem overbelast. Dit is geen probleem met een I/O-subsysteem - dit is SQL Server die meer I/O's aanstuurt dan zou moeten. De focus moet nu verschuiven naar SQL Server om de oorzaak van de extra I/O's te identificeren.
Oorzaken van grote aantallen gelezen I/O's
SQL Server heeft twee soorten leesbewerkingen:logische I/O's en fysieke I/O's. Wanneer het Access Methods-gedeelte van de Storage Engine toegang moet krijgen tot een pagina, vraagt het de Buffer Pool om een verwijzing naar de pagina in het geheugen (een logische I/O genoemd) en de Buffer Pool controleert zijn metadata om te zien of die pagina is al in het geheugen.
Als de pagina zich in het geheugen bevindt, geeft de bufferpool de toegangsmethoden de aanwijzer en blijft de I/O een logische I/O. Als de pagina zich niet in het geheugen bevindt, geeft de bufferpool een "echte" I/O uit (een fysieke I/O genoemd) en moet de thread wachten tot deze is voltooid - wat resulteert in een PAGEIOLATCH_XX wacht. Zodra de I/O is voltooid en de aanwijzer beschikbaar is, wordt de thread op de hoogte gebracht en kan deze verder worden uitgevoerd.
In een ideale wereld zou uw volledige werklast in het geheugen passen en dus zodra de bufferpool is "opgewarmd" en alle werklast vasthoudt, zijn er geen leesbewerkingen meer nodig, alleen het schrijven van bijgewerkte gegevens. Het is echter geen ideale wereld, en de meesten van jullie hebben die luxe niet, dus sommige reads zijn onvermijdelijk. Zolang het aantal reads rond uw basisbedrag blijft, is er geen probleem.
Wanneer plotseling en onverwacht een groot aantal leesbewerkingen nodig is, is dat een teken dat er een significante verandering is in ofwel de werklast, de hoeveelheid bufferpoolgeheugen die beschikbaar is voor het opslaan van in-memory kopieën van pagina's, of beide.
Hier zijn enkele mogelijke hoofdoorzaken (geen volledige lijst):
- Externe Windows-geheugendruk op SQL Server waardoor de geheugenbeheerder de bufferpool kleiner maakt
- Plan cache-bloat waardoor extra geheugen wordt geleend uit de bufferpool
- Een queryplan dat een tabel/geclusterde indexscan uitvoert (in plaats van een indexzoekopdracht) vanwege:
- een toename van het werkdrukvolume
- een probleem met het snuiven van parameters
- een vereiste niet-geclusterde index die is verwijderd of gewijzigd
- een impliciete conversie
Een patroon om naar te zoeken dat suggereert dat een tabel/geclusterde indexscan de oorzaak is, is ook het zien van een groot aantal CXPACKET wacht samen met de PAGEIOLATCH_SH wacht. Dit is een veelvoorkomend patroon dat aangeeft dat grote, parallelle tabel/geclusterde indexscans plaatsvinden.
In alle gevallen kunt u kijken welk queryplan de PAGEIOLATCH_SH veroorzaakt wacht met behulp van de sys.dm_os_waiting_tasks en andere DMV's, en je kunt code krijgen om dat te doen in mijn blogpost hier. Als je een monitoringtool van een derde partij beschikbaar hebt, kan deze je misschien helpen de boosdoener te identificeren zonder je handen vuil te maken.
Voorbeeld van workflow met SQL Sentry en Plan Explorer
Laten we in een eenvoudig (duidelijk gekunsteld) voorbeeld aannemen dat ik op een clientsysteem werk dat de reeks tools van SQL Sentry gebruikt en een piek in I/O-wachttijden zie in de dashboardweergave van SQL Sentry, zoals hieronder weergegeven:
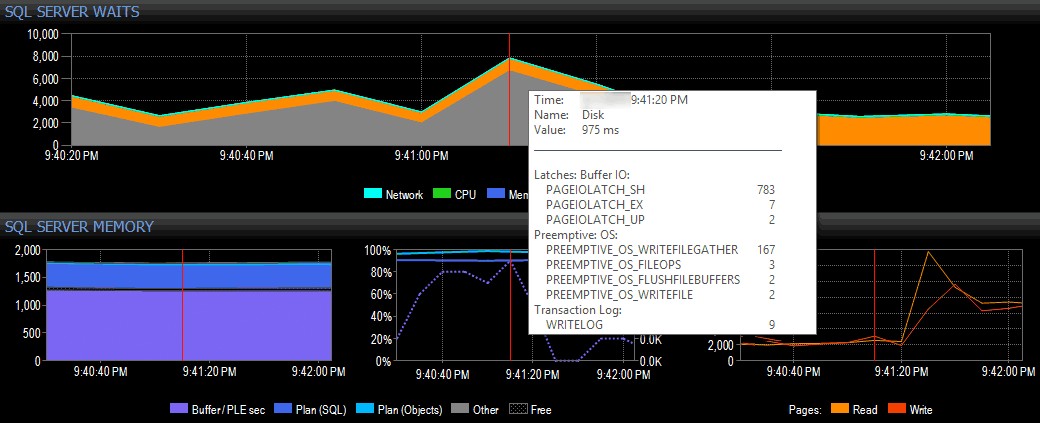
Een piek zien in I/O-wachttijden in SQL Sentry
Ik besluit het te onderzoeken door met de rechtermuisknop op een geselecteerd tijdsinterval rond de tijd van de piek te klikken en vervolgens naar de Top SQL-weergave te springen, die me de duurste query's laat zien die zijn uitgevoerd:
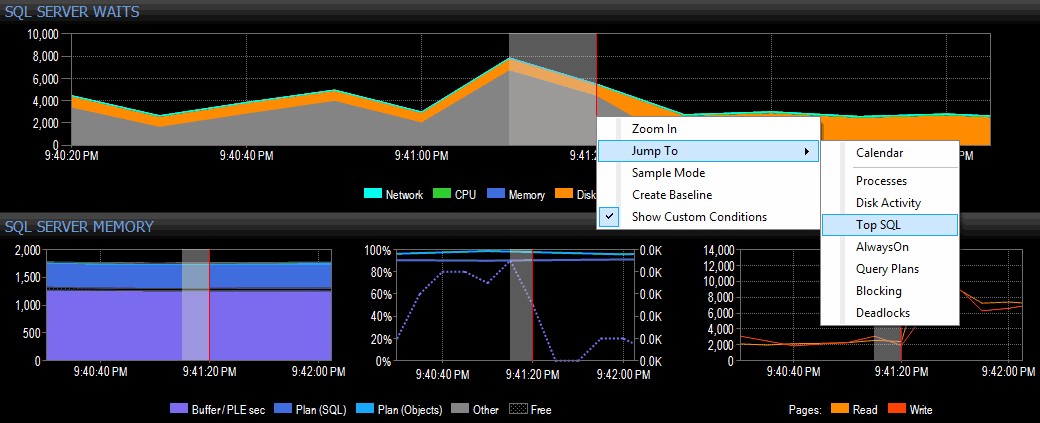
Een tijdbereik markeren en naar Top SQL navigeren
In deze weergave kan ik zien welke langlopende of hoge I/O-query's werden uitgevoerd op het moment dat de piek zich voordeed, en er vervolgens voor kiezen om in te zoomen op hun queryplannen (in dit geval is er slechts één langlopende query, die bijna een minuut duurde):
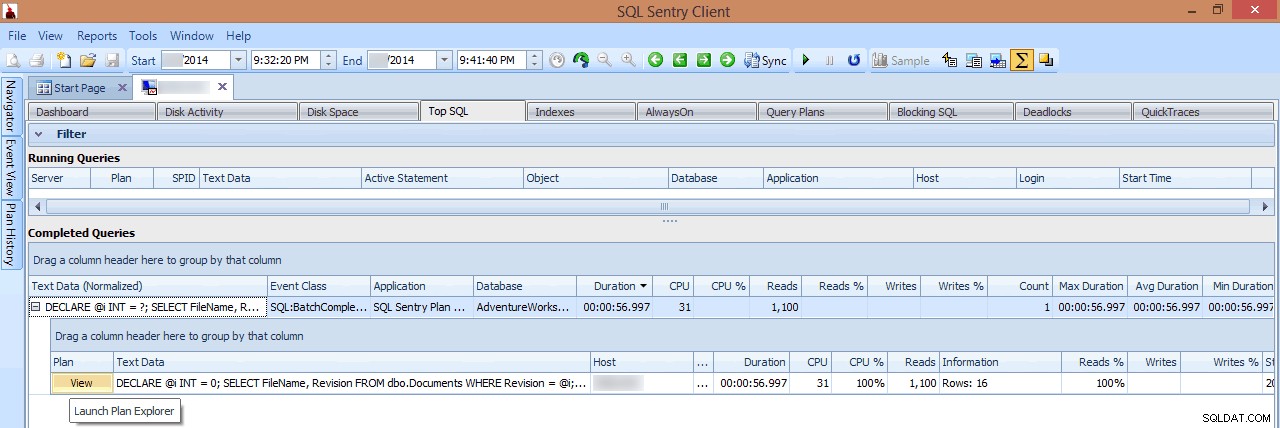
Een langlopende query bekijken in Top SQL
Als ik het plan in de SQL Sentry-client bekijk of in SQL Sentry Plan Explorer open, zie ik meteen meerdere problemen. Het aantal leesbewerkingen dat nodig is om 7 rijen te retourneren, lijkt veel te hoog, de delta tussen geschatte en werkelijke rijen is groot en het plan toont een indexscan die plaatsvindt waar ik een zoekopdracht had verwacht:
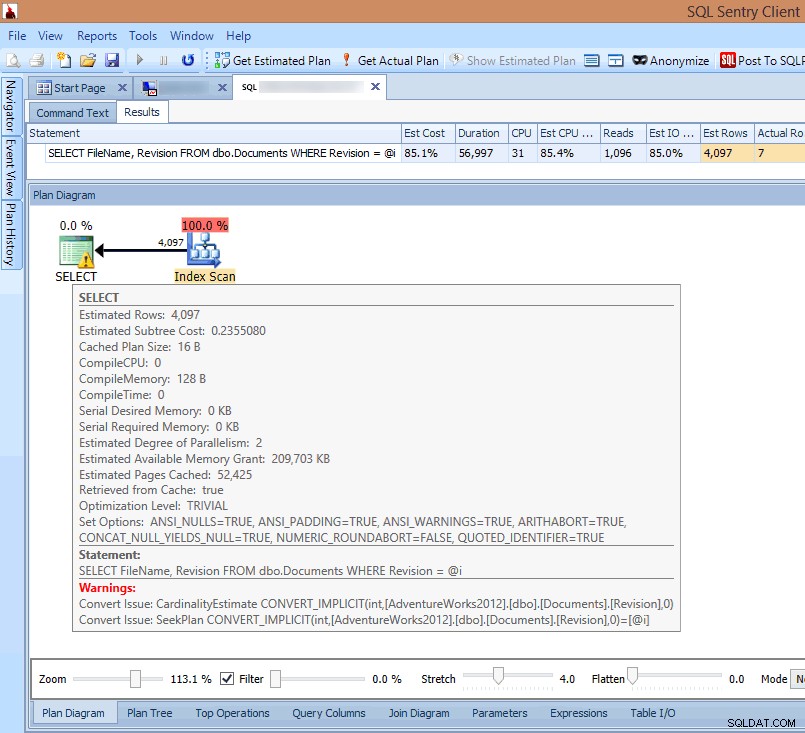
Impliciete conversiewaarschuwingen zien in het queryplan
De oorzaak van dit alles wordt benadrukt in de waarschuwing op de SELECT operator:Het is een impliciete conversie!
Impliciete conversies zijn een verraderlijk probleem dat wordt veroorzaakt door een mismatch tussen het gegevenstype van het zoekpredikaat en het gegevenstype van de kolom die wordt doorzocht, of een berekening die wordt uitgevoerd op de tabelkolom in plaats van op het zoekpredikaat. In beide gevallen kan SQL Server geen indexzoekopdracht gebruiken in de tabelkolom en moet in plaats daarvan een scan gebruiken.
Dit kan opduiken in ogenschijnlijk onschuldige code, en een veelvoorkomend voorbeeld is het gebruik van een datumberekening. Als u een tabel heeft waarin de leeftijd van klanten is opgeslagen, en u wilt een berekening uitvoeren om te zien hoeveel er vandaag 21 jaar of ouder zijn, kunt u de volgende code schrijven:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Met deze code bevindt de berekening zich in de tabelkolom en kan er dus geen indexzoekopdracht worden gebruikt, wat resulteert in een niet-zoekbare uitdrukking (technisch bekend als een niet-SARGeerbare uitdrukking) en een tabel/geclusterde indexscan. Dit kan worden opgelost door de berekening naar de andere kant van de operator te verplaatsen:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
Wat betreft wanneer een basiskolomvergelijking een conversie van gegevenstypes vereist die een impliciete conversie kan veroorzaken, schreef mijn collega Jonathan Kehayias een uitstekende blogpost waarin elke combinatie van gegevenstypen wordt vergeleken en vermeldt wanneer een impliciete conversie vereist is.
Samenvatting
Trap niet in de val door te denken dat buitensporige PAGEIOLATCH_XX wachttijden worden veroorzaakt door het I/O-subsysteem. In mijn ervaring worden ze meestal veroorzaakt door iets dat met SQL Server te maken heeft en daar zou ik beginnen met het oplossen van problemen.
Wat algemene wachtstatistieken betreft, kunt u meer informatie vinden over het gebruik ervan voor het oplossen van problemen met de prestaties in:
- Mijn serie SQLskills-blogposts, te beginnen met Wachtstatistieken, of vertel me alsjeblieft waar het pijn doet
- Mijn bibliotheek met wachttypen en Latch-klassen hier
- Mijn online Pluralsight-trainingscursus SQL Server:prestatieproblemen oplossen met behulp van wachtstatistieken
- SQL Sentry
In het volgende artikel in de serie zal ik een ander type wachten bespreken dat een veelvoorkomende oorzaak is van overhaaste reacties. Tot dan, veel plezier met het oplossen van problemen!