Het markeren van treffers is een functie waarvan veel mensen zouden willen dat SQL Server Full-Text Search native zou ondersteunen. Hier kunt u het hele document (of een uittreksel) retourneren en de woorden of woordgroepen aanwijzen die hebben geholpen bij het zoeken naar dat document. Dit op een efficiënte en nauwkeurige manier doen is geen gemakkelijke taak, zoals ik uit de eerste hand ontdekte.
Als voorbeeld van het markeren van treffers:wanneer u een zoekopdracht uitvoert in Google of Bing, krijgt u de trefwoorden vetgedrukt in zowel de titel als het fragment (klik op een van de afbeeldingen om te vergroten):

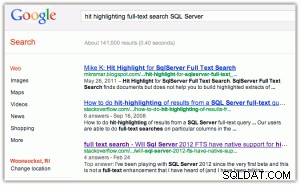
[Terzijde, ik vind hier twee dingen grappig:(1) dat Bing veel meer de voorkeur geeft aan Microsoft-eigendommen dan Google, en (2) dat Bing de moeite neemt om 2,2 miljoen resultaten terug te geven, waarvan er vele waarschijnlijk niet relevant zijn.]
Deze fragmenten worden gewoonlijk 'fragmenten' of 'op zoekvragen gebaseerde samenvattingen' genoemd. We vragen al een tijdje om deze functionaliteit in SQL Server, maar hebben nog geen goed nieuws van Microsoft gehoord:
- Connect #295100:zoeksamenvattingen in volledige tekst (hit-markering)
- Connect #722324:het zou fijn zijn als SQL Full Text Search ondersteuning voor fragmenten/accentuering zou bieden
De vraag verschijnt ook af en toe op Stack Overflow:
- Hiermee markeren van resultaten van een volledige-tekstquery van SQL Server
- Zal Sql Server 2012 FTS native ondersteuning hebben voor het markeren van treffers?
Er zijn enkele deeloplossingen. Dit script van Mike Kramar produceert bijvoorbeeld een uittreksel met de treffers, maar past niet dezelfde logica (zoals taalspecifieke woordbrekers) toe op het document zelf. Het gebruikt ook een absoluut aantal tekens, zodat het fragment kan beginnen en eindigen met gedeeltelijke woorden (zoals ik binnenkort zal aantonen). Dit laatste is vrij eenvoudig op te lossen, maar een ander probleem is dat het het hele document in het geheugen laadt, in plaats van enige vorm van streaming uit te voeren. Ik vermoed dat dit in full-text indexen met grote documentgroottes een merkbare prestatiehit zal zijn. Voor nu concentreer ik me op een relatief kleine gemiddelde documentgrootte (35 KB).
Een eenvoudig voorbeeld
Dus laten we zeggen dat we een heel eenvoudige tabel hebben, met een full-text index gedefinieerd:
CREATE FULLTEXT CATALOG [FTSDemo]; GO CREATE TABLE [dbo].[Document] ( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL, [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID) ); GO CREATE FULLTEXT INDEX ON [dbo].[Document] ( [Content] LANGUAGE [English], [Title] LANGUAGE [English] ) KEY INDEX [PK_Document] ON ([FTSDemo]);
Deze tabel is gevuld met een paar documenten (in het bijzonder 7), zoals de Onafhankelijkheidsverklaring en Nelson Mandela's "Ik ben bereid om te sterven"-toespraak. Een typische full-text zoekopdracht voor deze tabel kan zijn:
SELECT d.Title, d.[Content] FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
Het resultaat geeft 4 rijen van de 7 terug:

Gebruikt nu een UDF-functie zoals die van Mike Kramar:
SELECT d.Title, Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80) FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
De resultaten laten zien hoe het fragment werkt:a <SPAN> tag wordt geïnjecteerd bij het eerste trefwoord en het fragment wordt uitgesneden op basis van een offset vanaf die positie (zonder rekening te houden met het gebruik van volledige woorden):

(Nogmaals, dit is iets dat kan worden opgelost, maar ik wil er zeker van zijn dat ik goed representeer wat er nu is.)
ThinkHighlight
Eran Meyuchas van Interactive Thoughts heeft een component ontwikkeld die veel van deze problemen oplost. ThinkHighlight is geïmplementeerd als een CLR-assemblage met twee CLR scalaire functies:
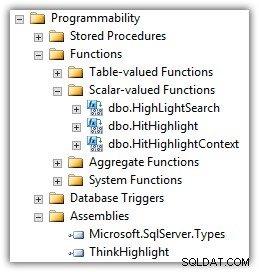
(Je ziet ook de UDF van Mike Kramar in de lijst met functies.)
Nu, zonder in te gaan op alle details over het installeren en activeren van de assembly op uw systeem, hier is hoe de bovenstaande vraag zou worden weergegeven met ThinkHighlight:
SELECT d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC; De resultaten laten zien hoe de meest relevante zoekwoorden worden gemarkeerd, en daarvan wordt een fragment afgeleid op basis van volledige woorden en een verschuiving van de term die wordt gemarkeerd:

Enkele extra voordelen die ik hier niet heb aangetoond, zijn de mogelijkheid om verschillende samenvattingsstrategieën te kiezen, de presentatie van elk trefwoord (in plaats van alle) te regelen met behulp van unieke CSS, evenals ondersteuning voor meerdere talen en zelfs documenten in binair formaat (de meeste IFilters worden ondersteund).
Prestatieresultaten
Aanvankelijk testte ik de runtime-statistieken voor de drie query's met behulp van SQL Sentry Plan Explorer, tegen de tabel met 7 rijen. De resultaten waren:

Vervolgens wilde ik zien hoe ze zich zouden verhouden op een veel grotere gegevensomvang. Ik heb de tabel in zichzelf ingevoegd totdat ik bij 4.000 rijen was, en voerde toen de volgende vraag uit:
SET STATISTICS TIME ON;
GO
SELECT /* FTS */ d.Title, d.[Content]
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* UDF */ d.Title,
Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* ThinkHighlight */ d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC;
GO
SET STATISTICS TIME OFF;
GO Ik heb ook sys.dm_exec_memory_grants gecontroleerd terwijl de query's werden uitgevoerd, om eventuele discrepanties in geheugentoelagen op te pikken. Resultaten gemiddeld over 10 runs:
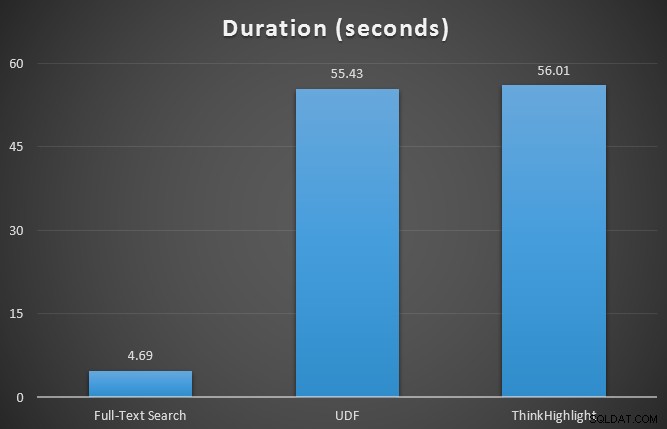
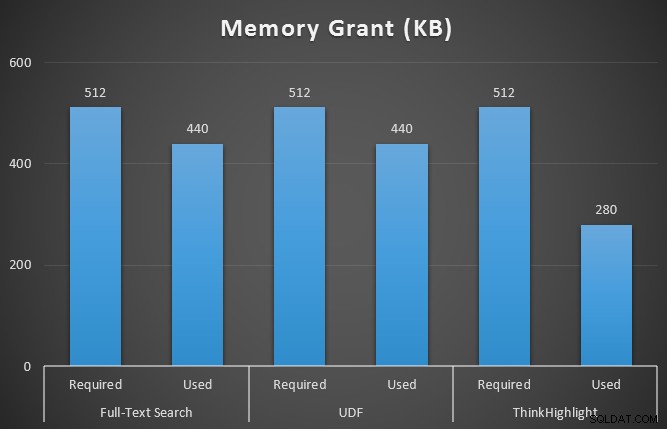
Hoewel beide opties voor het markeren van treffers een aanzienlijke straf opleveren omdat ze helemaal niet worden gemarkeerd, vertegenwoordigt de ThinkHighlight-oplossing - met meer flexibele opties - een zeer marginale incrementele kosten in termen van duur (~1%), terwijl aanzienlijk minder geheugen wordt gebruikt (36%) dan de UDF-variant.
Conclusie
Het zou geen verrassing moeten zijn dat het markeren van treffers een dure operatie is, en op basis van de complexiteit van wat moet worden ondersteund (denk aan meerdere talen), dat er maar heel weinig oplossingen bestaan. Ik denk dat Mike Kramar uitstekend werk heeft geleverd door een baseline UDF te produceren waarmee je het probleem op een goede manier kunt oplossen, maar ik was aangenaam verrast toen ik een robuuster commercieel aanbod vond – en ik vond het erg stabiel, zelfs in bètavorm. Ik ben van plan om grondigere tests uit te voeren met een breder scala aan documentformaten en -soorten. Als het markeren van treffers in de tussentijd deel uitmaakt van uw toepassingsvereisten, moet u Mike Kramar's UDF uitproberen en overwegen om ThinkHighlight mee te nemen voor een proefrit.