Er zijn veel use-cases voor het genereren van een reeks waarden in SQL Server. Ik heb het niet over een aanhoudende IDENTITY kolom (of de nieuwe SEQUENCE in SQL Server 2012), maar eerder een tijdelijke set die alleen wordt gebruikt voor de levensduur van een query. Of zelfs de eenvoudigste gevallen, zoals het toevoegen van een rijnummer aan elke rij in een resultatenset, waarbij mogelijk een ROW_NUMBER() moet worden toegevoegd. functie voor de query (of, beter nog, in de presentatielaag, die toch rij voor rij door de resultaten moet lopen).
Ik heb het over iets gecompliceerdere gevallen. U kunt bijvoorbeeld een rapport hebben waarin de verkopen op datum worden weergegeven. Een typische vraag zou kunnen zijn:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Het probleem met deze query is dat als er op een bepaalde dag geen bestellingen zijn, er voor die dag geen rij is. Dit kan leiden tot verwarring, misleidende gegevens of zelfs onjuiste berekeningen (denk aan daggemiddelden) voor de stroomafwaartse gebruikers van de gegevens.
Het is dus nodig om die leemten op te vullen met de datums die niet in de gegevens voorkomen. En soms stoppen mensen hun gegevens in een #temp-tabel en gebruiken ze een WHILE loop of een cursor om de ontbrekende datums één voor één in te vullen. Ik zal die code hier niet laten zien omdat ik niet wil pleiten voor het gebruik ervan, maar ik heb hem overal gezien.
Voordat we echter te diep op datums ingaan, laten we het eerst over getallen hebben, aangezien je altijd een reeks getallen kunt gebruiken om een reeks datums af te leiden.
Getallentabel
Ik ben al lang een voorstander van het opslaan van een hulp "nummertabel" op schijf (en trouwens ook een kalendertabel).
Hier is een manier om een eenvoudige getallentabel met 1.000.000 waarden te genereren:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Waarom MAXDOP 1? Zie de blogpost van Paul White en zijn Connect-item met betrekking tot rijdoelen.
Veel mensen zijn echter tegen de hulptafelbenadering. Hun argument:waarom al die gegevens op schijf (en in het geheugen) opslaan als ze de gegevens on-the-fly kunnen genereren? Mijn teller is om realistisch te zijn en na te denken over wat je optimaliseert; berekening kan duur zijn, en weet u zeker dat het direct berekenen van een reeks getallen altijd goedkoper zal zijn? Wat de ruimte betreft, neemt de Numbers-tabel slechts ongeveer 11 MB gecomprimeerd en 17 MB ongecomprimeerd in beslag. En als er vaak genoeg naar de tabel wordt verwezen, moet deze altijd in het geheugen staan, zodat de toegang snel gaat.
Laten we een paar voorbeelden bekijken en enkele van de meer gebruikelijke benaderingen die worden gebruikt om ze tevreden te stellen. Ik hoop dat we het er allemaal over eens zijn dat we, zelfs bij 1.000 waarden, deze problemen niet willen oplossen met een lus of een cursor.
Een reeks van 1.000 getallen genereren
Laten we, om eenvoudig te beginnen, een reeks getallen van 1 tot en met 1.000 genereren.
Getallentabel
Met een getallentabel is deze taak natuurlijk vrij eenvoudig:
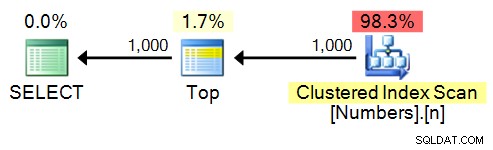
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plan:
spt_values
Dit is een tabel die voor verschillende doeleinden door interne opgeslagen procedures wordt gebruikt. Het gebruik ervan online lijkt vrij algemeen te zijn, ook al is het niet gedocumenteerd en wordt het niet ondersteund, het kan op een dag verdwijnen en omdat het slechts een eindige, niet-unieke en niet-aangrenzende reeks waarden bevat. Er zijn 2.164 unieke en 2.508 totale waarden in SQL Server 2008 R2; in 2012 zijn er 2.167 unieke en 2.515 in totaal. Dit omvat duplicaten, negatieve waarden en zelfs bij gebruik van DISTINCT , genoeg gaten als je voorbij het getal 2.048 komt. Dus de tijdelijke oplossing is om ROW_NUMBER() . te gebruiken om een aaneengesloten reeks te genereren, beginnend bij 1, op basis van de waarden in de tabel.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plan:

Dat gezegd hebbende, zou je voor slechts 1.000 waarden een iets eenvoudigere query kunnen schrijven om dezelfde reeks te genereren:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Dit leidt natuurlijk tot een eenvoudiger plan, maar wordt vrij snel afgebroken (zodra uw reeks meer dan 2.048 rijen moet zijn):
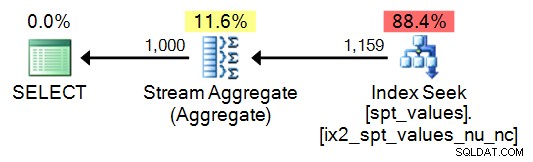
Ik raad het gebruik van deze tabel in ieder geval niet aan; Ik neem het op voor vergelijkingsdoeleinden, alleen omdat ik weet hoeveel hiervan beschikbaar is en hoe verleidelijk het kan zijn om de code die je tegenkomt gewoon opnieuw te gebruiken.
sys.all_objects
Een andere benadering die in de loop der jaren een van mijn favorieten is geweest, is het gebruik van sys.all_objects . Zoals spt_values , is er geen betrouwbare manier om rechtstreeks een aaneengesloten reeks te genereren, en we hebben dezelfde problemen met een eindige set (iets minder dan 2.000 rijen in SQL Server 2008 R2 en iets meer dan 2.000 rijen in SQL Server 2012), maar voor 1.000 rijen we kunnen dezelfde ROW_NUMBER() . gebruiken truc. De reden dat ik deze aanpak leuk vind, is dat (a) er minder zorgen zijn dat deze weergave snel zal verdwijnen, (b) de weergave zelf is gedocumenteerd en ondersteund, en (c) deze op elke database zal draaien op elke versie sinds SQL Server 2005 zonder databasegrenzen te overschrijden (inclusief ingesloten databases).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plan:

Gestapelde CTE's
Ik geloof dat Itzik Ben-Gan de ultieme lof verdient voor deze aanpak; eigenlijk construeer je een CTE met een kleine set waarden, dan maak je het Cartesiaanse product tegen zichzelf om het aantal rijen te genereren dat je nodig hebt. En nogmaals, in plaats van te proberen een aaneengesloten set te genereren als onderdeel van de onderliggende query, kunnen we gewoon ROW_NUMBER() toepassen naar het eindresultaat.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plan:
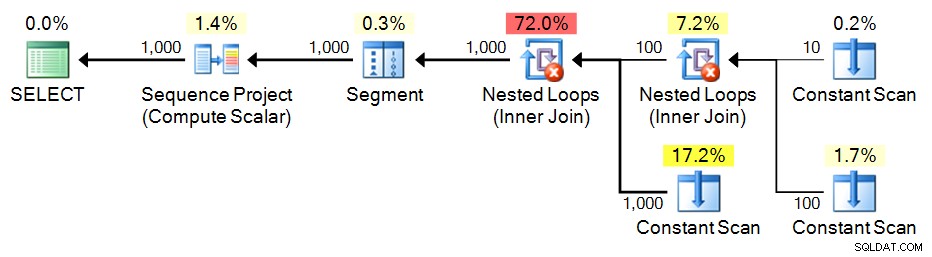
Recursieve CTE
Ten slotte hebben we een recursieve CTE, die 1 als anker gebruikt en 1 toevoegt totdat we het maximum bereiken. Voor de veiligheid specificeer ik het maximum in zowel de WHERE clausule van het recursieve gedeelte, en in de MAXRECURSION instelling. Afhankelijk van het aantal nummers dat u nodig heeft, moet u mogelijk MAXRECURSION . instellen naar 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plan:
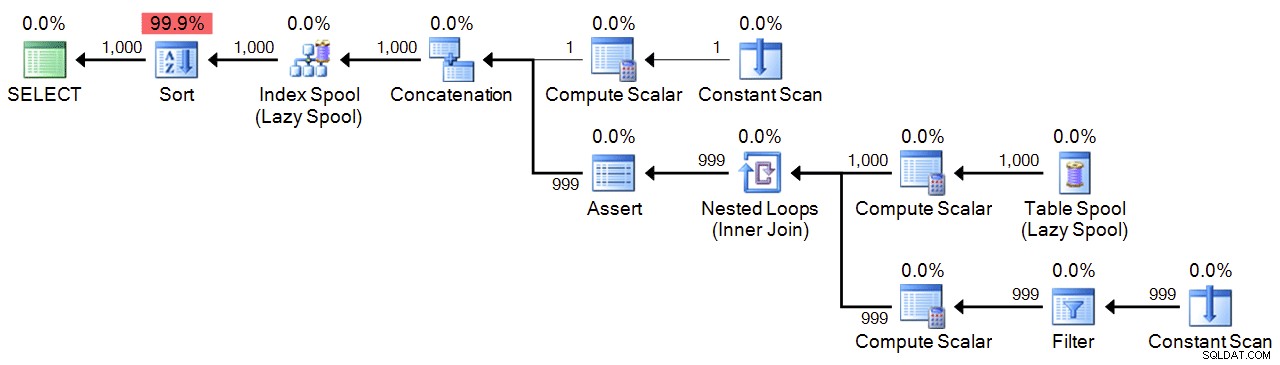
Prestaties
Met 1000 waarden zijn de verschillen in prestatie natuurlijk verwaarloosbaar, maar het kan handig zijn om te zien hoe deze verschillende opties presteren:
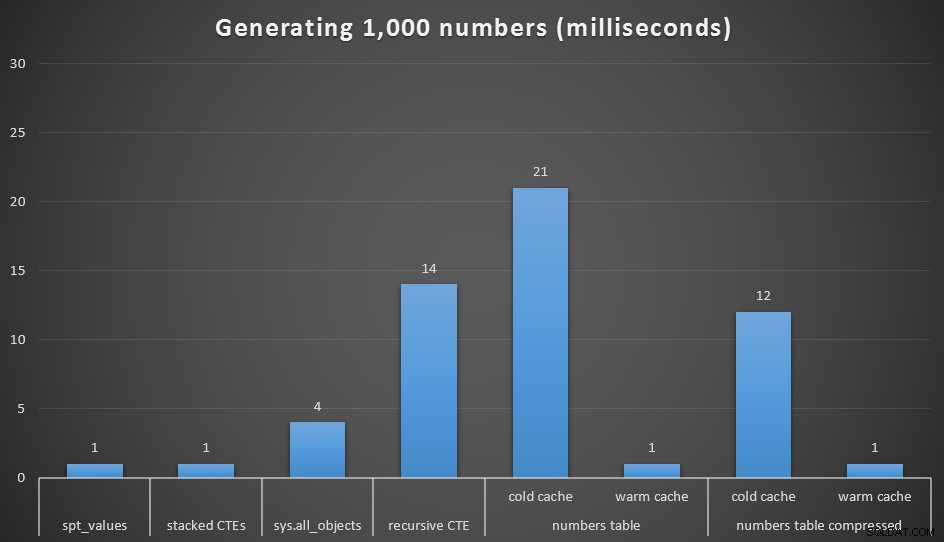
Runtime, in milliseconden, om 1.000 aaneengesloten getallen te genereren
Ik heb elke query 20 keer uitgevoerd en de gemiddelde looptijd genomen. Ik heb ook de dbo.Numbers . getest table, in zowel gecomprimeerde als niet-gecomprimeerde formaten, en met zowel een koude cache als een warme cache. Met een warme cache wedijvert het zeer nauw met de andere snelste opties die er zijn (spt_values , niet aanbevolen, en gestapelde CTE's), maar de eerste hit is relatief duur (hoewel ik bijna lach om het zo te noemen).
Wordt vervolgd…
Als dit uw typische gebruiksscenario is en u niet veel verder dan 1.000 rijen komt, dan hoop ik dat ik u de snelste manieren heb laten zien om die getallen te genereren. Als uw use-case een groter aantal is, of als u op zoek bent naar oplossingen om reeksen datums te genereren, houd ons dan in de gaten. Later in deze serie zal ik het genereren van reeksen van 50.000 en 1.000.000 getallen onderzoeken, en van datumbereiken variërend van een week tot een jaar.
[ Deel 1 | Deel 2 | Deel 3 ]