Indexen zijn snelheidsboosters in SQL-databases. Ze kunnen geclusterd of niet-geclusterd zijn. Maar wat betekent het en waar moet je ze allemaal toepassen?
Ik ken dit gevoel. Ik ben daar geweest. First-timers zijn vaak in de war over welke index ze op welke kolommen moeten gebruiken. Maar zelfs experts moeten over deze kwestie nadenken voordat ze een beslissing nemen, en verschillende situaties vereisen verschillende beslissingen. Zoals u later zult zien, zijn er zoekopdrachten waarbij een geclusterde index zal schitteren in vergelijking met een niet-geclusterde index, en omgekeerd.
Toch moeten we ze eerst allemaal kennen. Als u op zoek bent naar dezelfde informatie, is vandaag uw geluksdag.
In dit artikel wordt uitgelegd wat deze indexen zijn en wanneer u ze moet gebruiken. Natuurlijk zijn er codevoorbeelden die u in de praktijk kunt uitproberen. Dus pak je friet of pizza en wat frisdrank of koffie en bereid je voor om jezelf onder te dompelen in deze inzichtelijke reis.
Klaar?
Wat is een geclusterde index
Een geclusterde index is een index die de fysieke sorteervolgorde van rijen in een tabel of weergave definieert.
Om dit in de werkelijke vorm te zien, nemen we de Werknemer tabel in de AdventureWorks2017 database.
De primaire sleutel is ook een geclusterde index en de sleutel is gebaseerd op de BusinessEntityID kolom. Wanneer je een SELECT doet op deze tabel zonder ORDER BY, zul je zien dat het is gesorteerd op de primaire sleutel.
Probeer het zelf met de onderstaande code:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Zie nu het resultaat in Afbeelding 1:
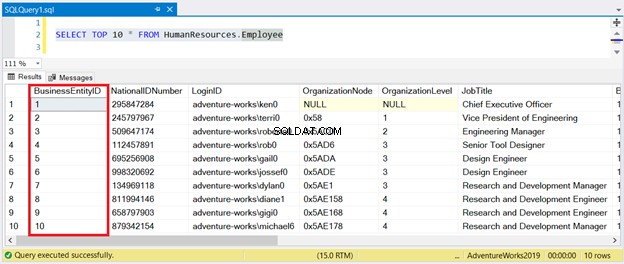
Zoals u kunt zien, hoeft u de resultatenset niet te sorteren met BusinessEntityID . De geclusterde index zorgt daarvoor.
In tegenstelling tot niet-geclusterde indexen, kunt u slechts 1 geclusterde index per tabel hebben. Wat als we dit proberen op de Werknemer tafel?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
We hebben een soortgelijke fout hieronder:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Wanneer een geclusterde index gebruiken?
Een kolom is de beste kandidaat voor een geclusterde index als een van de volgende punten waar is:
- Het wordt gebruikt in een groot aantal zoekopdrachten in de WHERE-component en joins.
- Het zal worden gebruikt als een externe sleutel naar een andere tafel en, uiteindelijk, om mee te doen.
- Unieke kolomwaarden.
- De waarde zal minder snel veranderen.
- Die kolom wordt gebruikt om een reeks waarden op te vragen. Operatoren zoals>, <,>=, <=of BETWEEN worden gebruikt met de kolom in de WHERE-component.
Maar geclusterde indexen zijn niet goed als de kolom of kolommen
- vaak wisselen
- zijn brede toetsen of een combinatie van kolommen met een grote toetsgrootte.
Voorbeelden
Geclusterde indexen kunnen worden gemaakt met behulp van T-SQL-code of een willekeurige SQL Server GUI-tool. Je kunt het in T-SQL doen bij het maken van een tabel, als volgt:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Of u kunt dit doen met ALTER TABLE na de tabel maken zonder een geclusterde index:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Een andere manier is het gebruik van CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Een ander alternatief is het gebruik van een SQL Server-tool zoals SQL Server Management Studio of dbForge Studio voor SQL Server.
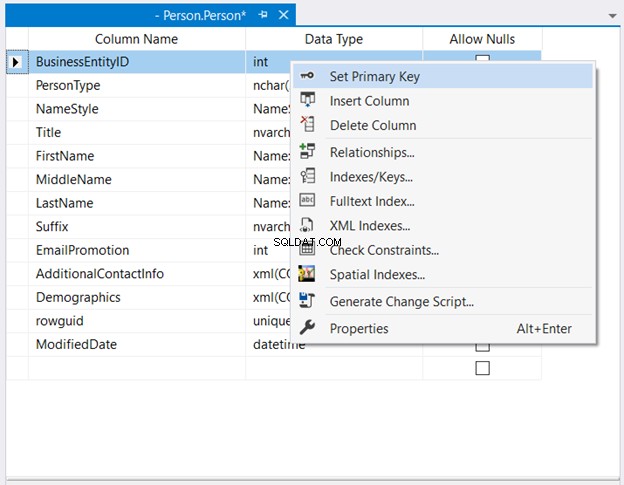
In Objectverkenner , breid de database en tabelknooppunten uit. Klik vervolgens met de rechtermuisknop op de gewenste tabel en selecteer Ontwerp . Klik ten slotte met de rechtermuisknop op de kolom die u als primaire sleutel wilt gebruiken> Primaire sleutel instellen > Sla de wijzigingen op in de tabel.
Afbeelding 2 hieronder laat zien waar BusinessEntityID is ingesteld als de primaire sleutel.
Naast het maken van een geclusterde index met één kolom, kunt u meerdere kolommen gebruiken. Zie een voorbeeld in T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Na het maken van deze geclusterde index, de Persoon tabel wordt fysiek gesorteerd op Achternaam , Voornaam , en Middennaam .
Een van de voordelen van deze aanpak is de verbeterde prestatie van query's op basis van de naam. Bovendien sorteert het de resultaten op naam zonder ORDER BY op te geven. Houd er echter rekening mee dat als de naam verandert, de tabel opnieuw moet worden gerangschikt. Hoewel dit niet elke dag zal gebeuren, kan de impact enorm zijn als de tafel erg groot is.
Wat is een niet-geclusterde index
Een niet-geclusterde index is een index met een sleutel en een aanwijzer naar de rijen of de geclusterde indexsleutels. Deze index kan van toepassing zijn op zowel tabellen als weergaven.
In tegenstelling tot geclusterde indexen, staat de structuur hier los van de tabel. Omdat het gescheiden is, heeft het een aanwijzer nodig naar de tabelrijen, ook wel een rijzoeker genoemd. Elk item in een niet-geclusterde index bevat dus een locator en een sleutelwaarde.
Niet-geclusterde indexen sorteren de tabel niet fysiek op basis van de sleutel.
Indexsleutels voor niet-geclusterde indexen hebben een maximale grootte van 1700 bytes. U kunt deze limiet omzeilen door opgenomen kolommen toe te voegen. Deze methode is goed als uw zoekopdracht meer kolommen moet beslaan zonder de sleutelgrootte te vergroten.
U kunt ook gefilterde niet-geclusterde indexen maken. Dit vermindert de onderhoudskosten en opslag van de index en verbetert tegelijkertijd de queryprestaties.
Wanneer een niet-geclusterde index gebruiken?
Een kolom of kolommen zijn goede kandidaten voor niet-geclusterde indexen als het volgende waar is:
- De kolom of kolommen worden gebruikt in een WHERE-component of join.
- De zoekopdracht levert geen grote resultatenset op.
- De exacte overeenkomst in de WHERE-component die de gelijkheidsoperator gebruikt, is nodig.
Voorbeelden
Deze opdracht maakt een unieke, niet-geclusterde index aan in de Werknemer tafel:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Naast een tabel kunt u een niet-geclusterde index maken voor een weergave:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Andere veelgestelde vragen en bevredigende antwoorden
Wat zijn de verschillen tussen geclusterde en niet-geclusterde index?
Op basis van wat je eerder hebt gezien, kun je al ideeën vormen over hoe verschillend geclusterde en niet-geclusterde indexen zijn. Maar laten we het op een tafel hebben om het gemakkelijk te kunnen raadplegen.
| Info | Geclusterde index | Niet-geclusterde index |
| Van toepassing op | Tabellen en weergaven | Tabellen en weergaven |
| Toegestaan per tafel | 1 | 999 |
| Sleutelgrootte | 900 bytes | 1700 bytes |
| Kolommen per indexsleutel | 32 | 32 |
| Goed voor | Bereikquery's (>,<,>=, <=, TUSSEN) | Exacte overeenkomsten (=) |
| Niet-sleutel opgenomen kolommen | Niet toegestaan | Toegestaan |
| Filter met voorwaarde | Niet toegestaan | Toegestaan |
Moeten primaire sleutels geclusterd of niet-geclusterd worden geïndexeerd?
Een primaire sleutel is een beperking. Zodra u van een kolom een primaire sleutel maakt, wordt er automatisch een geclusterde index van gemaakt, tenzij er al een bestaande geclusterde index is.
Verwar een primaire sleutel niet met een geclusterde index! Een primaire sleutel kan ook de geclusterde indexsleutel zijn. Maar een geclusterde indexsleutel kan een andere kolom zijn dan de primaire sleutel.
Laten we nog een voorbeeld nemen. In de Persoon tabel van AdventureWorks201 7 hebben we de BusinessEntityID hoofdsleutel. Het is ook de geclusterde indexsleutel. U kunt die geclusterde index laten vallen. Maak vervolgens een geclusterde index op basis van Achternaam , Voornaam , en Tussennaam . De primaire sleutel is nog steeds de BusinessEntityID kolom.
Maar moeten uw primaire sleutels altijd geclusterd zijn?
Het hangt er van af. Bekijk nogmaals de vraag wanneer u een geclusterde index moet gebruiken.
Als een kolom of kolommen in uw WHERE-clausule in veel zoekopdrachten voorkomen, is dit een kandidaat voor een geclusterde index. Maar een andere overweging is hoe breed de geclusterde indexsleutel is. Te breed - en de omvang van elke niet-geclusterde index zal toenemen als ze bestaan. Onthoud dat niet-geclusterde indexen ook de geclusterde indexsleutel als aanwijzer gebruiken. Houd uw geclusterde indexsleutel dus zo smal mogelijk.
Als een groot aantal query's de primaire sleutel in de WHERE-component gebruiken, laat deze dan ook als de geclusterde indexsleutel. Als dat niet het geval is, maakt u uw primaire sleutel als een niet-geclusterde index.
Maar wat als u nog steeds niet zeker bent? Vervolgens kunt u het prestatievoordeel van een kolom beoordelen wanneer deze geclusterd of niet-geclusterd is. Dus stem af op het volgende gedeelte erover.
Wat is sneller:geclusterde of niet-geclusterde index?
Goede vraag. Er is geen algemene regel. U moet de logische uitlezingen en het uitvoeringsplan van uw zoekopdrachten controleren.
Ons korte experiment bevat kopieën van de volgende tabellen uit de AdventureWorks2017 databank:
- Persoon
- BusinessEntityAddress
- Adres
- Adrestype
Hier is het script:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Met behulp van de bovenstaande structuur zullen we querysnelheden vergelijken voor geclusterde en niet-geclusterde indexen.
We hebben 2 exemplaren van de Persoon tafel. De eerste gebruikt BusinessEntityID als de primaire en geclusterde indexsleutel. De tweede gebruikt nog steeds BusinessEntityID als de primaire sleutel. De geclusterde index is gebaseerd op Achternaam , Voornaam , Tussennaam , en Suffix .
Laten we beginnen.
VRAAG EXACTE WEDSTRIJDEN OP BASIS VAN DE ACHTERNAAM
Laten we eerst een eenvoudige vraag stellen. U moet ook STATISTICS IO inschakelen. Vervolgens plakken we de resultaten in statistiekenparser.com voor een presentatie in tabelvorm.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
De verwachting is dat de eerste SELECT langzamer zal zijn omdat de WHERE-component niet overeenkomt met de geclusterde indexsleutel. Maar laten we eens kijken naar de logische waarden.
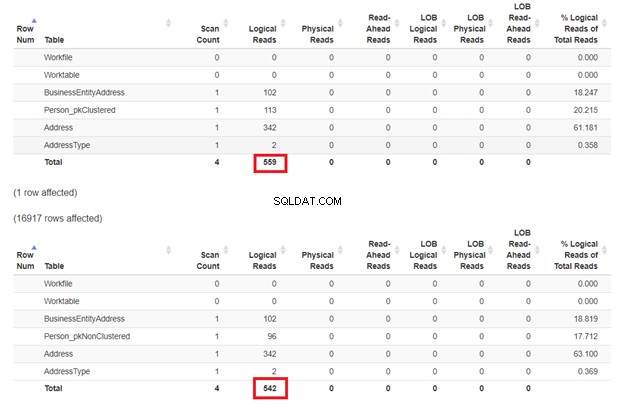
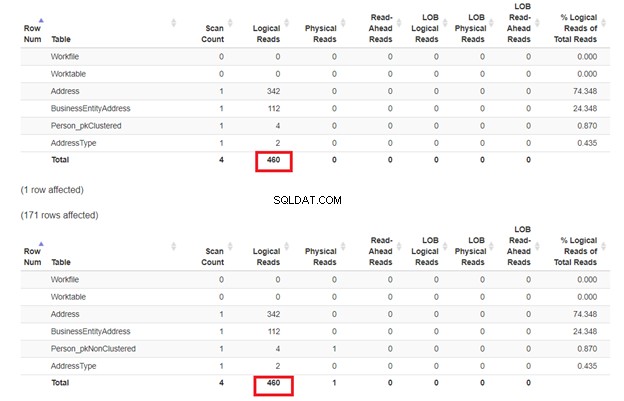
Zoals verwacht in Afbeelding 3, Person_pkClustered had meer logische leest. Daarom heeft de query meer I/O nodig. De reden? De tabel is gesorteerd op BusinessEntityID . Toch heeft de tweede tabel de geclusterde index op basis van de naam. Omdat de zoekopdracht een resultaat wil op basis van de naam, Person_pkNonClustered wint. Hoe minder logische lezingen, hoe sneller de zoekopdracht.
Wat is er nog meer aan de hand? Bekijk figuur 4.
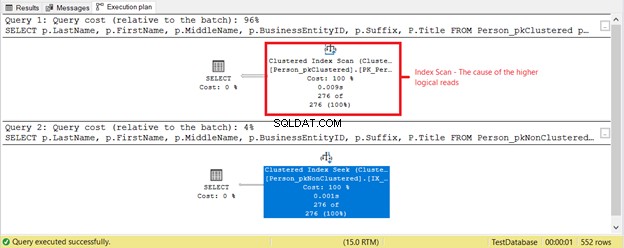
Er is nog iets anders gebeurd op basis van het uitvoeringsplan in figuur 4. Waarom staat een geclusterde indexscan in de eerste SELECT in plaats van een indexzoekopdracht? De boosdoener is de Titel kolom in de SELECT. Het wordt niet gedekt door een van de bestaande indexen. SQL Server-optimizer achtte het sneller om de geclusterde index te gebruiken op basis van BusinessEntityID. Vervolgens scande SQL Server het op de juiste achternamen en kreeg de voornaam, tweede naam en titel.
Verwijder de Titel kolom, en de gebruikte operator is Index Seek . Waarom? Omdat de rest van de velden wordt gedekt door de niet-geclusterde index op basis van Achternaam , Voornaam , Tussennaam , en Suffix . Het bevat ook BusinessEntityID als de geclusterde indexsleutelzoeker.
BEREIK QUERY GEBASEERD OP BEDRIJFSENTITEIT-ID
Geclusterde indexen kunnen goed zijn voor bereikquery's. Is dat altijd zo? Laten we erachter komen door de onderstaande code te gebruiken.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
De vermelding heeft rijen nodig op basis van een reeks BusinessEntityID's van 285 tot 290. Nogmaals, de geclusterde en niet-geclusterde indexen van de 2 tabellen zijn intact. Laten we nu de logische waarden in Afbeelding 5 bekijken. De verwachte winnaar is Person_pkClustered omdat de primaire sleutel ook de geclusterde indexsleutel is.

Zie je lagere logische uitlezingen op Person_pkClustered ? In dit scenario hebben geclusterde indexen hun waarde bewezen bij bereikquery's. Laten we eens kijken wat het uitvoeringsplan nog meer zal onthullen in figuur 6.
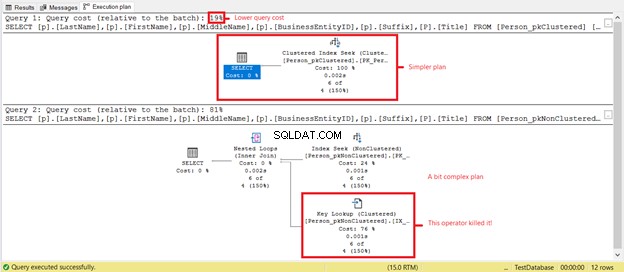
De eerste SELECT heeft een eenvoudiger plan en lagere querykosten op basis van figuur 7. Dit ondersteunt ook lagere logische leesbewerkingen. Ondertussen heeft de tweede SELECT een Key Lookup-operator die de query vertraagt. De boosdoener? Nogmaals, het is de Titel kolom. Verwijder de kolom in de query of voeg deze toe als een Opgenomen kolom in de niet-geclusterde index. Dan heb je een beter plan en lagere logische waarden.
VRAAG EXACTE WEDSTRIJDEN MET EEN JOIN
Veel SELECT-instructies bevatten joins. Laten we wat testen doen. Hier beginnen we met exacte overeenkomsten:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
We verwachten dat de tweede SELECT van Person_pkNonClustered met een geclusterde index op de naam zal minder logische reads hebben. Maar is het? Zie afbeelding 7.
Het lijkt erop dat de niet-geclusterde index op de naam het prima deed. De logische waarden zijn hetzelfde. Als u het uitvoeringsplan controleert, is het verschil in de operators de Clustered Index Seek op Person_pkNonClustered , en de Index Zoeken op Person_pkClustered .
We moeten dus de logische uitlezingen en het uitvoeringsplan controleren om zeker te zijn.
BEREIK QUERY MET JOINS
Aangezien onze verwachtingen kunnen verschillen van de werkelijkheid, laten we het proberen met bereikquery's. Geclusterde indexen zijn er over het algemeen goed mee. Maar wat als je een join toevoegt?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Inspecteer nu de logische waarden van deze 2 queries in Afbeelding 8:
Wat is er gebeurd? In figuur 9 bijt de realiteit op Person_pkClustered . Er werden meer I/O-kosten waargenomen in vergelijking met Person_pkNonClustered . Dat is anders dan we verwachten. Maar op basis van dit forumantwoord kan een niet-geclusterde indexzoekactie sneller zijn dan een geclusterde indexzoekactie wanneer alle kolommen in de zoekopdracht voor 100% in de index worden gedekt. In ons geval is de zoekopdracht voor Person_pkNonClustered bedekt de kolommen met behulp van de niet-geclusterde index (BusinessEntityID - sleutel; Achternaam , Voornaam , Tussennaam , Suffix – aanwijzer naar geclusterde indexsleutel).
PRESTATIES INVOEREN
Probeer vervolgens de INSERT-prestaties over dezelfde tabellen te testen.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Afbeelding 9 toont de INSERT logische waarden:

Beide genereerden dezelfde I/O. Beide presteerden dus hetzelfde.
PRESTATIE VERWIJDEREN
Onze laatste test omvat DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Afbeelding 10 toont de logische uitlezingen. Let op het verschil.

Waarom hebben we hogere logische waarden voor Person_pkClustered ? Het punt is dat de DELETE-instructievoorwaarde is gebaseerd op een exacte overeenkomst met een naam. De optimizer zal eerst zijn toevlucht moeten nemen tot de niet-geclusterde index. Het betekent meer I/O. Laten we bevestigen met behulp van het uitvoeringsplan in Afbeelding 11.
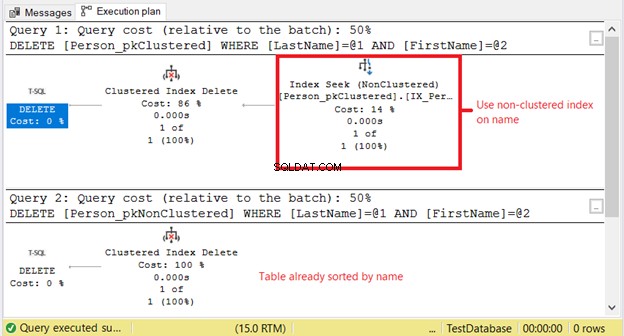
De eerste SELECT heeft een Index Seek nodig op de niet-geclusterde index. De reden is de WHERE-clausule op Achternaam en Voornaam . Ondertussen, Person_pkNonClustered is al fysiek gesorteerd op naam vanwege de geclusterde index.
Afhaalmaaltijden
Het vormen van goed presterende zoekopdrachten gaat niet over geluk. U kunt niet zomaar een geclusterde en een niet-geclusterde index plaatsen en dan plotseling hebben uw zoekopdrachten de snelheidskracht. Je moet de tools blijven gebruiken als je lens om je te concentreren op de kleine details, behalve de resultatenset.
Maar soms heb je gewoon geen tijd om al deze dingen te doen. Ik denk dat dat normaal is. Maar zolang je niet zoveel verknoeit, heb je de volgende dag je baan en kun je het oplossen. Dit zal in het begin niet gemakkelijk zijn. Het zal inderdaad verwarrend zijn. Je zult ook veel vragen hebben. Maar met constante oefening kun je het bereiken. Dus houd je bek.
Onthoud dat zowel geclusterde als niet-geclusterde indexen zijn bedoeld om zoekopdrachten te stimuleren. Het kennen van de belangrijkste verschillen, de gebruiksscenario's en de tools zal u helpen bij uw zoektocht naar het coderen van krachtige query's.
Ik hoop dat dit bericht uw meest prangende vragen over geclusterde en niet-geclusterde indexen beantwoordt. Heb je nog iets toe te voegen voor onze lezers? Het gedeelte Opmerkingen is geopend.
En als je dit bericht verhelderend vindt, deel het dan op je favoriete sociale-mediaplatforms.
Meer informatie over indexen en queryprestaties vindt u in de onderstaande artikelen:
- 22 handige SQL-indexvoorbeelden om uw zoekopdrachten te versnellen
- SQL-queryoptimalisatie:5 kernfeiten om uw zoekopdrachten een boost te geven