In mijn laatste bericht hebben we gezien hoe een query met een scalair aggregaat door de optimizer kan worden omgezet in een efficiëntere vorm. Ter herinnering, hier is het schema nog een keer:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Plankeuzes
Met 10.000 rijen in elk van de basistabellen, komt de optimizer met een eenvoudig plan dat het maximum berekent door alle 30.000 rijen in een aggregaat te lezen:
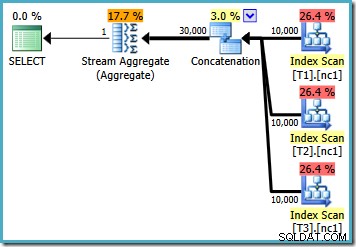
Met 50.000 rijen in elke tabel besteedt de optimizer wat meer tijd aan het probleem en vindt een slimmer plan. Het leest alleen de bovenste rij (in aflopende volgorde) van elke index en berekent vervolgens het maximum van alleen die 3 rijen:
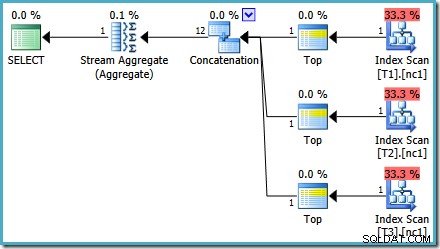
Een Optimizer-bug
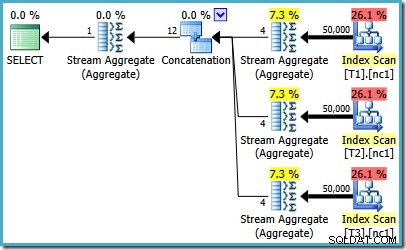
Je merkt misschien iets vreemds aan die geschatte plan. De aaneenschakelingsoperator leest één rij uit drie tabellen en produceert op de een of andere manier twaalf rijen! Dit is een fout die wordt veroorzaakt door een fout in de schatting van de kardinaliteit die ik in mei 2011 heb gemeld. Het is nog steeds niet opgelost vanaf SQL Server 2014 CTP 1 (zelfs als de nieuwe kardinaliteitsschatter wordt gebruikt), maar ik hoop dat het zal worden verholpen voor de definitieve release.
Om te zien hoe de fout ontstaat, bedenk dan dat een van de planalternatieven die door de optimizer zijn overwogen voor het geval van 50.000 rijen gedeeltelijke aggregaten heeft onder de aaneenschakelingsoperator:
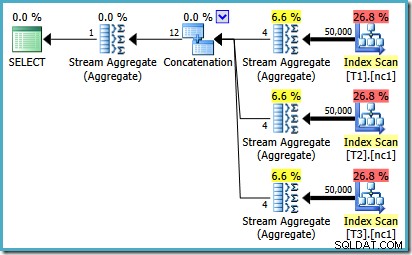
Het is de kardinaliteitsschatting voor deze gedeeltelijke MAX aggregaten die in gebreke blijven. Ze schatten vier rijen waarbij het resultaat gegarandeerd één rij is. Mogelijk ziet u een ander getal dan vier - dit hangt af van het aantal logische processors dat beschikbaar is voor de optimizer op het moment dat het plan wordt gecompileerd (zie de bug-link hierboven voor meer details).
De optimizer vervangt later de gedeeltelijke aggregaten door Top (1)-operators, die de kardinaliteitsschatting correct herberekenen. Helaas geeft de Concatenatie-operator nog steeds de schattingen weer voor de vervangen deelaggregaten (3 * 4 =12). Als resultaat krijgen we een aaneenschakeling die 3 rijen leest en er 12 oplevert.
TOP gebruiken in plaats van MAX
Als we nog eens kijken naar het 50.000 rijenplan, lijkt de grootste verbetering die de optimizer heeft gevonden, het gebruik van Top (1)-operators in plaats van alle rijen te lezen en de maximale waarde te berekenen met brute kracht. Wat gebeurt er als we iets soortgelijks proberen en de zoekopdracht expliciet herschrijven met Top?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Het uitvoeringsplan voor de nieuwe query is:
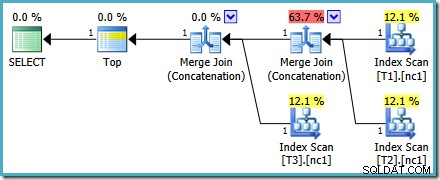
Dit plan verschilt nogal van het plan dat door de optimizer is gekozen voor de MAX vraag. Het beschikt over drie geordende Index Scans, twee Merge Joins die draaien in de Concatenatie-modus en een enkele Top-operator. Dit nieuwe zoekplan heeft een aantal interessante functies die de moeite waard zijn om in detail te onderzoeken.
Plananalyse
De eerste rij (in aflopende indexvolgorde) wordt gelezen uit de niet-geclusterde index van elke tabel en er wordt een samenvoegverbinding gebruikt die in de aaneenschakelingsmodus werkt. Hoewel de operator Samenvoegen geen samenvoeging uitvoert in de normale zin, kan het verwerkingsalgoritme van deze operator eenvoudig worden aangepast om de invoer samen te voegen in plaats van samenvoegingscriteria toe te passen.
Het voordeel van het gebruik van deze operator in het nieuwe plan is dat Samenvoegen samenvoegen de sorteervolgorde over de invoer behoudt. Daarentegen leest een gewone aaneenschakelingsoperator op volgorde van zijn invoer. Het onderstaande diagram illustreert het verschil (klik om uit te vouwen):
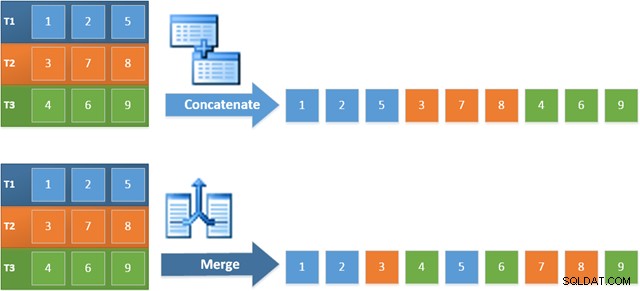
Het orderbehoudgedrag van Samenvoegen Samenvoegen betekent dat de eerste rij die wordt geproduceerd door de meest linkse samenvoegoperator in het nieuwe plan, gegarandeerd de rij is met de hoogste waarde in kolom c1 in alle drie de tabellen. Meer specifiek werkt het plan als volgt:
- Eén rij wordt gelezen uit elke tabel (in index aflopende volgorde); en
- Elke samenvoeging voert één test uit om te zien welke van zijn invoerrijen de hoogste waarde heeft
Dit lijkt een zeer efficiënte strategie, dus het lijkt misschien vreemd dat de MAX . van de optimizer plan heeft een geschatte kostprijs van minder dan de helft van het nieuwe plan. De reden hiervoor is voor een groot deel dat wordt aangenomen dat het bewaren van een samenvoeging duurder is dan een eenvoudige aaneenschakeling. De optimizer realiseert zich niet dat elke samenvoeging maximaal één rij kan zien, en overschat daardoor de kosten ervan.
Meer kostenproblemen
Strikt genomen vergelijken we hier geen appels met appels, omdat de twee plannen voor verschillende vragen zijn. Dergelijke kosten vergelijken is over het algemeen niet correct, hoewel SSMS precies dat doet door kostenpercentages voor verschillende overzichten in een batch weer te geven. Maar ik dwaal af.
Als u naar het nieuwe plan kijkt in SSMS in plaats van SQL Sentry Plan Explorer, ziet u zoiets als dit:
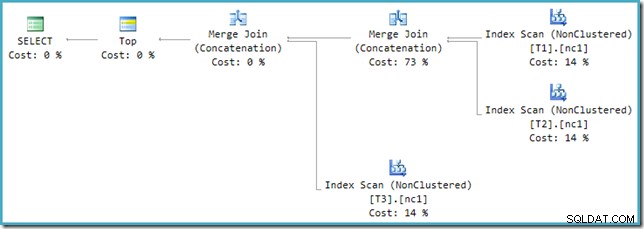
Een van de operators voor het samenvoegen van samenvoegen heeft een geschatte kostprijs van 73%, terwijl de tweede (die op exact hetzelfde aantal rijen werkt) wordt weergegeven als helemaal niets te kosten. Een ander teken dat hier iets mis is, is dat de operatorkostenpercentages in dit plan niet optellen tot 100%.
Optimizer versus uitvoeringsengine
Het probleem ligt in een incompatibiliteit tussen de optimizer en de uitvoeringsengine. In de optimizer kunnen Union en Union All 2 of meer ingangen hebben. In de uitvoeringsengine kan alleen de concatenatie-operator 2 of meer . accepteren ingangen; Samenvoegen Samenvoegen vereist precies twee ingangen, zelfs wanneer geconfigureerd om een aaneenschakeling uit te voeren in plaats van een samenvoeging.
Om deze incompatibiliteit op te lossen, wordt een herschrijving na de optimalisatie toegepast om de uitvoerstructuur van de optimizer te vertalen naar een vorm die de uitvoeringsengine aankan. Wanneer een Union of Union All met meer dan twee inputs wordt geïmplementeerd met behulp van Merge, is een keten van operators nodig. Met drie ingangen voor de Union All zijn in dit geval twee Merge Unions nodig:
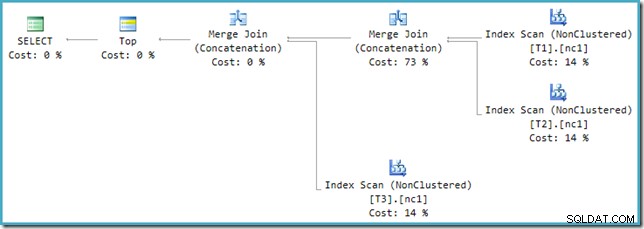
We kunnen de output-boom van de optimizer zien (met drie inputs voor een fysieke merge-unie) met behulp van traceringsvlag 8607:
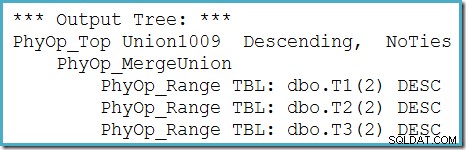
Een onvolledige oplossing
Helaas is de herschrijving na de optimalisatie niet perfect geïmplementeerd. Het maakt een beetje een puinhoop van de kostencijfers. Afgezien van de problemen, tellen de plankosten op tot 114%, waarbij de extra 14% afkomstig is van de invoer naar de extra samenvoeging, samenvoeging, aaneenschakeling gegenereerd door het herschrijven:
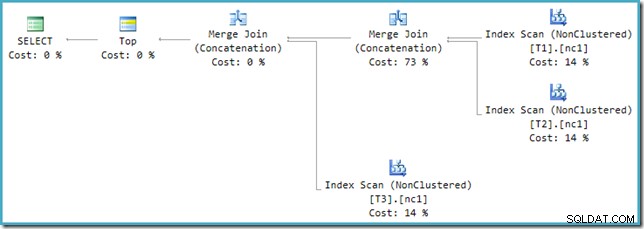
De meest rechtse samenvoeging in dit plan is de oorspronkelijke operator in de uitvoerstructuur van de optimizer. Het wordt toegewezen aan de volledige kosten van de operatie Union All. De andere samenvoeging wordt toegevoegd door het herschrijven en kost nul.
Hoe we er ook naar kijken (en er zijn verschillende problemen die van invloed zijn op reguliere aaneenschakeling), de cijfers zien er vreemd uit. Plan Explorer doet zijn best om de gebrekkige informatie in het XML-abonnement te omzeilen door er in ieder geval voor te zorgen dat de getallen optellen tot 100%:
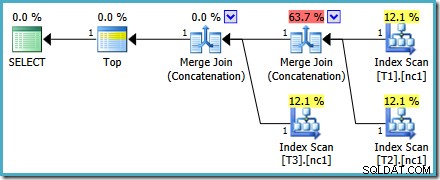
Dit specifieke kostenprobleem is opgelost in SQL Server 2014 CTP 1:
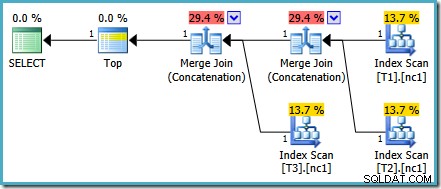
De kosten van de Merge Concatenation zijn nu gelijk verdeeld over de twee operators, en de percentages tellen op tot 100%. Doordat de onderliggende XML vastligt, slaagt SSMS er ook in om dezelfde getallen weer te geven.
Welk abonnement is beter?
Als we de query schrijven met MAX , moeten we erop vertrouwen dat de optimizer ervoor kiest om het extra werk uit te voeren dat nodig is om een efficiënt plan te vinden. Als de optimizer in een vroeg stadium een schijnbaar goed genoeg plan vindt, kan het een relatief inefficiënt plan produceren dat elke rij van elk van de basistabellen leest:
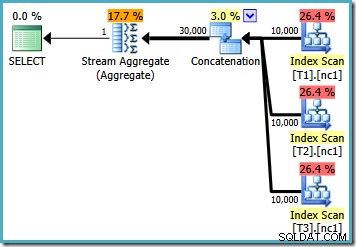
Als u SQL Server 2008 of SQL Server 2008 R2 gebruikt, kiest de optimizer nog steeds een inefficiënt plan, ongeacht het aantal rijen in de basistabellen. Het volgende plan is gemaakt op SQL Server 2008 R2 met 50.000 rijen:
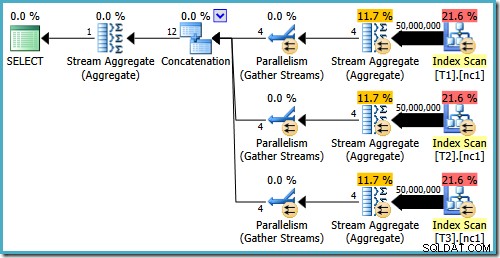
Zelfs met 50 miljoen rijen in elke tabel, voegt de 2008 en 2008 R2 optimizer alleen maar parallellisme toe, het introduceert niet de Top operators:
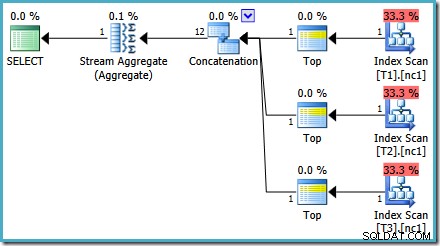
Zoals vermeld in mijn vorige bericht, is traceringsvlag 4199 vereist om SQL Server 2008 en 2008 R2 te krijgen om het plan met Top-operators te produceren. Voor SQL Server 2005 en 2012 is de traceringsvlag niet vereist:
TOP met BESTELLEN BY
Als we eenmaal begrijpen wat er gaande is in de vorige uitvoeringsplannen, kunnen we een bewuste (en geïnformeerde) keuze maken om de query te herschrijven met een expliciete TOP met ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Het resulterende uitvoeringsplan kan kostenpercentages hebben die er vreemd uitzien in sommige versies van SQL Server, maar het onderliggende plan is degelijk. De herschrijving na de optimalisatie die ervoor zorgt dat de getallen er vreemd uitzien, wordt toegepast nadat de query-optimalisatie is voltooid, dus we kunnen er zeker van zijn dat de planselectie van de optimizer niet door dit probleem is beïnvloed.
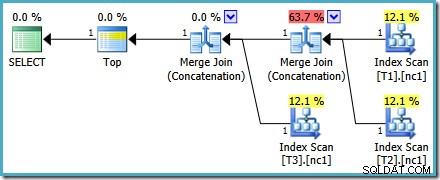
Dit plan verandert niet afhankelijk van het aantal rijen in de basistabel en vereist geen traceervlaggen om te genereren. Een klein extra voordeel is dat dit plan gevonden wordt door de optimizer tijdens de eerste fase van kostengebaseerde optimalisatie (zoek 0):
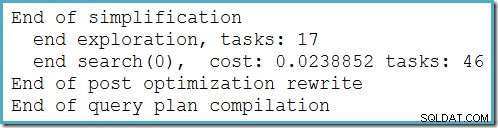
Het beste plan geselecteerd door de optimizer voor de MAX zoekopdracht vereist twee fasen van op kosten gebaseerde optimalisatie (zoek 0 en zoeken 1).
Er is een klein semantisch verschil tussen de TOP query en de originele MAX vorm die ik moet noemen. Als geen van de tabellen een rij bevat, zou de oorspronkelijke zoekopdracht een enkele NULL . opleveren resultaat. De vervangende TOP (1) query produceert helemaal geen uitvoer in dezelfde omstandigheden. Dit verschil is niet vaak belangrijk bij vragen in de echte wereld, maar het is iets om rekening mee te houden. We kunnen het gedrag van TOP repliceren met behulp van MAX in SQL Server 2008 en later door een lege set toe te voegen GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Deze wijziging heeft geen invloed op de uitvoeringsplannen die zijn gegenereerd voor de MAX vraag op een manier die zichtbaar is voor eindgebruikers.
MAX met samenvoegen aaneenschakeling
Gezien het succes van Merge Join Concatenation in de TOP (1) uitvoeringsplan, is het natuurlijk de vraag of hetzelfde optimale plan zou kunnen worden gegenereerd voor de oorspronkelijke MAX vraag of we de optimizer dwingen om samenvoeging samen te voegen in plaats van gewone samenvoeging voor de UNION ALL bediening.
Er is een vraaghint voor dit doel – MERGE UNION – maar helaas werkt het alleen correct in SQL Server 2012. In eerdere versies was de UNION hint heeft alleen invloed op UNION zoekopdrachten, niet UNION ALL . In SQL Server 2012 en later kunnen we dit proberen:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
We worden beloond met een plan met aaneenschakeling van samenvoegen. Helaas is het niet helemaal alles waar we op hadden gehoopt:
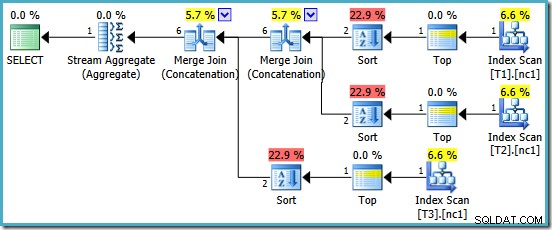
De interessante operators in dit plan zijn de soorten. Let op de schatting van de invoerkardinaliteit van 1 rij en de schatting van 4 rijen op de uitvoer. De oorzaak zou u inmiddels bekend moeten zijn:het is dezelfde gedeeltelijke geaggregeerde kardinaliteitsschattingsfout die we eerder hebben besproken.
De aanwezigheid van de soorten onthult nog een probleem met de gedeeltelijke aggregaten. Ze produceren niet alleen een onjuiste kardinaliteitsschatting, ze behouden ook de indexvolgorde die sorteren onnodig zou maken (samenvoegen samenvoegen vereist gesorteerde invoer). De gedeeltelijke aggregaten zijn scalair MAX aggregaten, die gegarandeerd één rij produceren, dus de kwestie van bestellen zou hoe dan ook ter discussie moeten staan (er is maar één manier om één rij te sorteren!)
Dat is jammer, want zonder de soorten zou dit een degelijk uitvoeringsplan zijn. Als de gedeeltelijke aggregaten correct zijn geïmplementeerd en de MAX geschreven met een GROUP BY () clausule, we zouden zelfs kunnen hopen dat de optimizer zou kunnen ontdekken dat de drie Tops en de laatste Stream Aggregate zouden kunnen worden vervangen door een enkele laatste Top-operator, die precies hetzelfde plan geeft als de expliciete TOP (1) vraag. De optimizer bevat die transformatie vandaag niet, en ik denk niet dat het vaak genoeg nuttig genoeg zou zijn om het in de toekomst de moeite waard te maken.
Laatste woorden
TOP gebruiken zal niet altijd de voorkeur hebben boven MIN of MAX . In sommige gevallen zal het een aanzienlijk minder optimaal plan opleveren. Het punt van dit bericht is dat het begrijpen van de transformaties die door de optimizer zijn toegepast, manieren kan suggereren om de oorspronkelijke query te herschrijven die nuttig kan blijken te zijn.