Veel mensen gebruiken wachtstatistieken als onderdeel van hun algemene methodologie voor het oplossen van prestaties, net als ik, dus de vraag die ik in dit bericht wilde onderzoeken, gaat over wachttypen die verband houden met de overhead van de waarnemer. Met waarnemersoverhead bedoel ik de impact op de werkbelasting van SQL Server die wordt veroorzaakt door SQL Profiler, server-side traces of Extended Event-sessies. Zie de volgende twee berichten van mijn collega Jonathan Kehayias voor meer informatie over de overhead van waarnemers :
- Meten "Observer Overhead" van SQL Trace versus uitgebreide gebeurtenissen
- Impact van de query_post_execution_showplan Extended Event in SQL Server 2012
Dus in dit bericht zou ik graag een paar variaties van waarnemersoverhead willen doorlopen en kijken of we consistente wachttypen kunnen vinden die verband houden met de gemeten degradatie. Er zijn verschillende manieren waarop SQL Server-gebruikers tracering in hun productieomgevingen implementeren, dus uw resultaten kunnen variëren, maar ik wilde een paar brede categorieën behandelen en verslag uitbrengen over wat ik heb gevonden:
- SQL Profiler-sessiegebruik
- Gebruik tracering aan serverzijde
- Traceergebruik aan serverzijde, schrijven naar een langzaam I/O-pad
- Uitgebreid gebruik van gebeurtenissen met een ringbufferdoel
- Uitgebreid gebruik van gebeurtenissen met een bestandsdoel
- Uitgebreid gebruik van gebeurtenissen met een bestandsdoel op een langzaam I/O-pad
- Uitgebreid gebruik van gebeurtenissen met een bestandsdoel op een langzaam I/O-pad zonder verlies van gebeurtenissen
Je kunt waarschijnlijk andere variaties op het thema bedenken en ik nodig je uit om eventuele interessante bevindingen met betrekking tot de overhead van waarnemers en wachtstatistieken als commentaar in dit bericht te delen.
Basislijn
Voor de test gebruikte ik een virtuele VMware-machine met vier vCPU's en 4 GB RAM. Mijn gast op de virtuele machine was op OCZ Vertex SSD's. Het besturingssysteem was Windows Server 2008 R2 Enterprise en de versie van SQL Server is 2012, SP1 CU4.
Wat betreft de "werklast" gebruik ik een alleen-lezen-query in een lus tegen de 2008 Credit-voorbeelddatabase, ingesteld op GO 10.000.000 keer.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Ik voer deze query ook uit via 16 gelijktijdige sessies. Het eindresultaat op mijn testsysteem is 100% CPU-gebruik over alle vCPU's op de virtuele gast en een gemiddelde van 14.492 batchverzoeken per seconde gedurende een periode van 2 minuten.
Wat betreft het traceren van gebeurtenissen, gebruikte ik in elke test Showplan XML Statistics Profile voor de SQL Profiler en Server-side traceringstests – en query_post_execution_showplan voor Extended Event-sessies. Uitvoeringsplangebeurtenissen zijn erg duur, en dat is precies waarom ik ze heb gekozen, zodat ik kon zien of ik onder extreme omstandigheden wel of niet wait-type-thema's kon afleiden.
Voor het testen van de accumulatie van het wachttype gedurende een testperiode heb ik de volgende query gebruikt. Niets bijzonders - gewoon de statistieken wissen, 2 minuten wachten en vervolgens de top 10 wachtende accumulaties verzamelen voor de SQL Server-instantie tijdens de degradatietestperiode:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Merk op dat ik niet . ben het uitfilteren van typen wachten op de achtergrond die doorgaans worden weggefilterd, en dit is omdat ik iets dat normaal gesproken goedaardig is niet wilde elimineren, maar in dit geval wijst het in feite op een echt gebied om verder te onderzoeken.
SQL Profiler-sessie
De volgende tabel toont de batchverzoeken voor en na per seconde bij het inschakelen van een lokale SQL Profiler-tracering Showplan XML Statistics Profile (draaiend op dezelfde VM als de SQL Server-instantie):
| Basislijn batchverzoeken per seconde (gemiddelde van 2 minuten) | SQL Profiler-sessiebatchverzoeken per seconde (gemiddelde van 2 minuten) |
|---|---|
| 14.492 | 1.416 |
U kunt zien dat de SQL Profiler-tracering een aanzienlijke daling van de doorvoer veroorzaakt.
Wat betreft de geaccumuleerde wachttijden in diezelfde periode, waren de meest voorkomende soorten wachttijden als volgt (net als bij de rest van de tests in dit artikel heb ik een paar testruns uitgevoerd en de uitvoer was over het algemeen consistent):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67.142 | 1.149.824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 313 | 180.449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.086 |
| LAZYWRITER_SLEEP | 120 | 120.059 |
| DIRTY_PAGE_POLL | 1.198 | 120.038 |
| HADR_WORK_QUEUE | 12 | 120.015 |
| LOGMGR_QUEUE | 937 | 120.011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
Het type wacht dat me opvalt is TRACEWRITE - die door Books Online is gedefinieerd als een wachttype dat "optreedt wanneer de SQL Trace-rijenset-traceerprovider wacht op een vrije buffer of een buffer met te verwerken gebeurtenissen". De rest van de wachttypen zien eruit als standaard wachttypen op de achtergrond die je normaal gesproken uit je resultatenset zou filteren. Bovendien sprak ik over een soortgelijk probleem met over-tracing in een artikel in 2011 genaamd Observer overhead - de gevaren van te veel tracing - dus ik was bekend met dit type wacht soms correct wijzen op problemen met de overhead van de waarnemer. In dat specifieke geval waarover ik blogde, was het niet SQL Profiler, maar een andere toepassing die de rowset-traceerprovider (inefficiënt) gebruikte.
Server-Side Trace
Dat was voor SQL Profiler, maar hoe zit het met de traceeroverhead aan de serverzijde? De volgende tabel toont de voor-en-na batchverzoeken per seconde bij het inschakelen van een lokale server-side tracering naar een bestand:
| Basislijn batchverzoeken per seconde (gemiddelde van 2 minuten) | SQL Profiler-batchverzoeken per seconde (gemiddelde van 2 minuten) |
|---|---|
| 14.492 | 4015 |
De beste soorten wachten waren als volgt (ik heb een paar testruns gedaan en de uitvoer was consistent):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.015 |
| SLEEP_TASK | 253 | 180.871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.046 |
| HADR_WORK_QUEUE | 12 | 120.042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.021 |
| XE_DISPATCHER_WAIT | 3 | 120.006 |
| WAITFOR | 1 | 120.000 |
| LOGMGR_QUEUE | 931 | 119.993 |
| DIRTY_PAGE_POLL | 1.193 | 119.958 |
| XE_TIMER_EVENT | 55 | 119.954 |
Deze keer zien we geen TRACEWRITE (we gebruiken nu een bestandsprovider) en het andere traceergerelateerde wachttype, het ongedocumenteerde SQLTRACE_INCREMENTAL_FLUSH_SLEEP klom naar boven - maar heeft in vergelijking met de eerste test een zeer vergelijkbare geaccumuleerde wachttijd (120.046 vs. 120.006) - en mijn collega Erin Stellato (@erinstellato) sprak over dit specifieke type wachten in haar bericht Uitzoeken wanneer wachtstatistieken voor het laatst zijn gewist . Dus kijkend naar de andere soorten wachten, springt er geen eruit als een betrouwbare rode vlag.
Server-Side Trace schrijven naar een langzaam I/O-pad
Wat als we het traceerbestand aan de serverzijde op een langzame schijf zetten? De volgende tabel toont de batchverzoeken voor en na per seconde bij het inschakelen van een lokale server-side trace die naar een bestand op een USB-stick schrijft:
| Basislijn batchverzoeken per seconde (gemiddelde van 2 minuten) | SQL Profiler-batchverzoeken per seconde (gemiddelde van 2 minuten) |
|---|---|
| 14.492 | 260 |
Zoals we kunnen zien, zijn de prestaties aanzienlijk verslechterd, zelfs in vergelijking met de vorige test.
De beste wachttypes waren als volgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351.174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.273 | 299.995 |
| SLEEP_TASK | 240 | 194.264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181.458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125.007 |
| LAZYWRITER_SLEEP | 63 | 124.437 |
| LOGMGR_QUEUE | 941 | 120.559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120.516 |
| WAITFOR | 1 | 120.515 |
| DIRTY_PAGE_POLL | 1204 | 120.513 |
Een type wacht dat eruit springt voor deze test is de ongedocumenteerde SQLTRACE_FILE_BUFFER . Hierover is niet veel gedocumenteerd, maar op basis van de naam kunnen we een weloverwogen gok doen (vooral gezien de configuratie van deze specifieke test).
Uitgebreide gebeurtenissen naar het ringbufferdoel
Laten we vervolgens de bevindingen bekijken voor equivalenten van Extended Event-sessies. Ik heb de volgende sessiedefinitie gebruikt:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
De volgende tabel toont de voor-en-na batchverzoeken per seconde bij het inschakelen van een XE-sessie met een ringbufferdoel (waarbij het query_post_execution_showplan wordt vastgelegd evenement):
| Basislijn batchverzoeken per seconde (gemiddelde van 2 minuten) | SQL Profiler-batchverzoeken per seconde (gemiddelde van 2 minuten) |
|---|---|
| 14.492 | 4.737 |
De beste wachttypes waren als volgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299.992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.006 |
| SLEEP_TASK | 240 | 181.739 |
| LAZYWRITER_SLEEP | 120 | 120.219 |
| HADR_WORK_QUEUE | 12 | 120.038 |
| DIRTY_PAGE_POLL | 1.198 | 120.035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.011 |
| LOGMGR_QUEUE | 936 | 120.008 |
| WAITFOR | 1 | 120.001 |
Niets sprong eruit als XE-gerelateerd, alleen achtergrondtaak "ruis".
Uitgebreide gebeurtenissen naar een bestandsdoel
Hoe zit het met het wijzigen van de sessie om een bestandsdoel te gebruiken in plaats van een ringbufferdoel? De volgende tabel toont de batchverzoeken voor en na per seconde bij het inschakelen van een XE-sessie met een bestandsdoel in plaats van een ringbufferdoel:
| Basislijn batchverzoeken per seconde (gemiddelde van 2 minuten) | SQL Profiler-batchverzoeken per seconde (gemiddelde van 2 minuten) |
|---|---|
| 14.492 | 4.299 |
De beste wachttypes waren als volgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2,103 | 299.996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 253 | 180.663 |
| LAZYWRITER_SLEEP | 120 | 120.187 |
| HADR_WORK_QUEUE | 12 | 120.029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| WAITFOR | 1 | 120.001 |
| XE_TIMER_EVENT | 59 | 119.966 |
| LOGMGR_QUEUE | 935 | 119.957 |
Niets, met uitzondering van XE_TIMER_EVENT , sprong eruit als XE-gerelateerd. De Wait Type Repository van Bob Ward verwijst naar deze als veilig om te negeren, tenzij er mogelijk iets mis is - maar realistisch gezien zou u dit gewoonlijk goedaardige wachttype opmerken als het op de 9e plaats op uw systeem stond tijdens een prestatievermindering? En wat als je het er al uit filtert vanwege zijn normaal goedaardige aard?
Uitgebreide gebeurtenissen naar een langzaam I/O-padbestandsdoel
Wat nu als ik het bestand op een langzaam I/O-pad zet? De volgende tabel toont de voor-en-na batchverzoeken per seconde bij het inschakelen van een XE-sessie met een bestandsdoel op een USB-stick:
| Basislijn batchverzoeken per seconde (gemiddelde van 2 minuten) | SQL Profiler-batchverzoeken per seconde (gemiddelde van 2 minuten) |
|---|---|
| 14.492 | 4.386 |
De beste wachttypes waren als volgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.046 |
| SLEEP_TASK | 253 | 180.719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.427 |
| LAZYWRITER_SLEEP | 120 | 120.190 |
| HADR_WORK_QUEUE | 12 | 120.025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| WAITFOR | 1 | 120.002 |
| DIRTY_PAGE_POLL | 1.197 | 119.977 |
| XE_TIMER_EVENT | 59 | 119.949 |
Nogmaals, er springt niets XE-gerelateerd uit behalve de XE_TIMER_EVENT .
Uitgebreide gebeurtenissen naar een langzaam I/O-padbestandsdoel, geen gebeurtenisverlies
De volgende tabel toont de batchverzoeken voor en na per seconde bij het inschakelen van een XE-sessie met een bestandsdoel op een USB-stick, maar deze keer zonder gebeurtenisverlies toe te staan (EVENT_RETENTION_MODE=NO_EVENT_LOSS) - wat niet wordt aanbevolen en u zult zien in de resultaten waarom dat zou kunnen zijn:
| Basislijn batchverzoeken per seconde (gemiddelde van 2 minuten) | SQL Profiler-batchverzoeken per seconde (gemiddelde van 2 minuten) |
|---|---|
| 14.492 | 539 |
De beste wachttypes waren als volgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8.773 | 1.707.845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 337 | 180.446 |
| LAZYWRITER_SLEEP | 120 | 120.032 |
| DIRTY_PAGE_POLL | 1.198 | 120.026 |
| HADR_WORK_QUEUE | 12 | 120.009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
| WAITFOR | 1 | 120.000 |
| XE_TIMER_EVENT | 59 | 119.944 |
Met de extreme doorvoerreductie zien we XE_BUFFERMGR_FREEBUF_EVENT spring naar de nummer één positie op onze verzamelde wachttijdresultaten. Deze is gedocumenteerd in Books Online, en Microsoft vertelt ons dat deze gebeurtenis is gekoppeld aan XE-sessies die zijn geconfigureerd voor geen verlies van gebeurtenissen en waarbij alle buffers in de sessie vol zijn.
Invloed van waarnemer
Afgezien van de typen wacht, was het interessant om te zien welke impact elke observatiemethode had op het vermogen van onze werklast om batchverzoeken te verwerken:
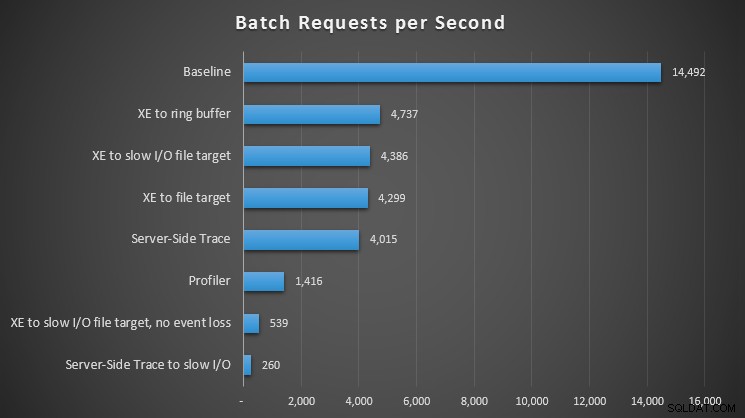
Impact van verschillende observatiemethoden op batchverzoeken per seconde
Voor alle benaderingen was er een significante – maar niet schokkende – hit in vergelijking met onze baseline (geen observatie); de meeste pijn werd echter gevoeld bij het gebruik van Profiler, bij het gebruik van Server-Side Trace naar een langzaam I/O-pad, of Extended Events naar een bestandsdoel op een langzaam I/O-pad - maar alleen wanneer geconfigureerd voor geen gebeurtenisverlies. Met verlies van gebeurtenissen presteerde deze opstelling eigenlijk op hetzelfde niveau als een bestandsdoel naar een snel I/O-pad, vermoedelijk omdat het in staat was om veel meer gebeurtenissen te laten vallen.
Samenvatting
Ik heb niet elk mogelijk scenario getest en er zijn zeker andere interessante combinaties (om nog maar te zwijgen van verschillende gedragingen op basis van de SQL Server-versie), maar de belangrijkste conclusie die ik uit deze verkenning trek, is dat je niet altijd kunt vertrouwen op een voor de hand liggende accumulatie van het wachttype aanwijzer wanneer geconfronteerd met een waarnemer overhead scenario. Op basis van de tests in dit bericht vertoonden slechts drie van de zeven scenario's een specifiek wachttype dat u mogelijk in de goede richting zou kunnen wijzen. Zelfs toen - deze tests waren op een gecontroleerd systeem - en vaak filteren mensen de bovengenoemde wachttypes uit als goedaardige achtergrondtypes - zodat je ze misschien helemaal niet ziet.
Gezien dit, wat kunt u doen? Voor prestatievermindering zonder duidelijke of voor de hand liggende symptomen, raad ik aan om de reikwijdte uit te breiden om te vragen naar sporen en XE-sessies (terzijde - ik raad ook aan om je reikwijdte uit te breiden als het systeem gevirtualiseerd is of mogelijk onjuiste stroomopties heeft). Als onderdeel van het oplossen van problemen met een systeem, controleert u bijvoorbeeld sys.[traces] en sys.[dm_xe_sessions] om te zien of er iets onverwachts op het systeem draait. Het is een extra laag waar u zich zorgen over moet maken, maar een paar snelle validaties kunnen u een aanzienlijke hoeveelheid tijd besparen.