De wijzigingen in de interne weergave van gepartitioneerde tabellen tussen SQL Server 2005 en SQL Server 2008 resulteerden in de meeste gevallen in verbeterde queryplannen en prestaties (vooral wanneer parallelle uitvoering betrokken is). Helaas zorgden dezelfde veranderingen ervoor dat sommige dingen die goed werkten in SQL Server 2005, plotseling niet zo goed werkten in SQL Server 2008 en later. Dit bericht kijkt naar een voorbeeld waarbij de query-optimizer van SQL Server 2005 een superieur uitvoeringsplan produceerde in vergelijking met latere versies.
Voorbeeldtabel en gegevens
De voorbeelden in dit bericht gebruiken de volgende gepartitioneerde tabel en gegevens:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Gepartitioneerde gegevenslay-out
Onze tabel heeft een gepartitioneerde geclusterde index. In dit geval dient de clustersleutel ook als partitiesleutel (hoewel dit in het algemeen geen vereiste is). Partitionering resulteert in afzonderlijke fysieke opslageenheden (rijensets) die de queryprocessor als een enkele entiteit aan gebruikers presenteert.
Het onderstaande diagram toont de eerste drie partities van onze tabel (klik om te vergroten):
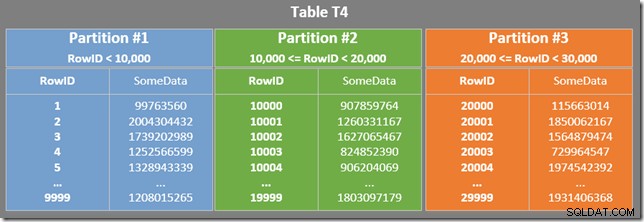
De niet-geclusterde index is op dezelfde manier gepartitioneerd (hij is "uitgelijnd"):

Elke partitie van de niet-geclusterde index omvat een reeks RowID-waarden. Binnen elke partitie worden de gegevens geordend op SomeData (maar de RowID-waarden worden in het algemeen niet geordend).
Het MIN/MAX-probleem
Het is redelijk bekend dat MIN en MAX aggregaten optimaliseren niet goed op gepartitioneerde tabellen (tenzij de kolom die wordt geaggregeerd ook de partitiekolom is). Over deze beperking (die nog steeds bestaat in SQL Server 2014 CTP 1) is in de loop der jaren vaak geschreven; mijn favoriete verslaggeving is in dit artikel van Itzik Ben-Gan. Overweeg de volgende vraag om het probleem kort te illustreren:
SELECT MIN(SomeData) FROM dbo.T4;
Het uitvoeringsplan op SQL Server 2008 of hoger is als volgt:

Dit plan leest alle 150.000 rijen uit de index en een Stream Aggregate berekent de minimumwaarde (het uitvoeringsplan is in wezen hetzelfde als we in plaats daarvan om de maximumwaarde vragen). Het uitvoeringsplan voor SQL Server 2005 is iets anders (maar niet beter):
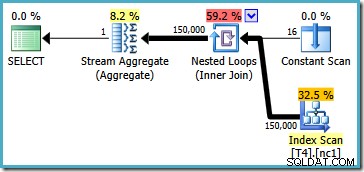
Dit plan herhaalt partitienummers (vermeld in de Constant Scan) waarbij een partitie tegelijk volledig wordt gescand. Alle 150.000 rijen worden uiteindelijk toch gelezen en verwerkt door de Stream Aggregate.
Kijk terug naar de gepartitioneerde tabel en indexdiagrammen en denk na over hoe de query efficiënter kan worden verwerkt op onze dataset. De niet-geclusterde index lijkt een goede keuze om de query op te lossen, omdat deze SomeData-waarden bevat in een volgorde die misbruikt zou kunnen worden bij het berekenen van het aggregaat.
Het feit dat de index is gepartitioneerd maakt de zaken wel wat ingewikkelder:elke partitie van de index is geordend op de SomeData-kolom, maar we kunnen niet zomaar de laagste waarde lezen van een bepaald partitie om het juiste antwoord op de hele vraag te krijgen.
Zodra de essentiële aard van het probleem is begrepen, kan een mens zien dat het een efficiënte strategie zou zijn om de laagste waarde van SomeData in elke partitie te vinden. van de index en neem vervolgens de laagste waarde van de resultaten per partitie.
Dit is in wezen de oplossing die Itzik in zijn artikel presenteert; herschrijf de query om een geaggregeerde per partitie te berekenen (met behulp van APPLY syntaxis) en aggregeer vervolgens opnieuw over die resultaten per partitie. Met behulp van die aanpak, de herschreven MIN query produceert dit uitvoeringsplan (zie het artikel van Itzik voor de exacte syntaxis):
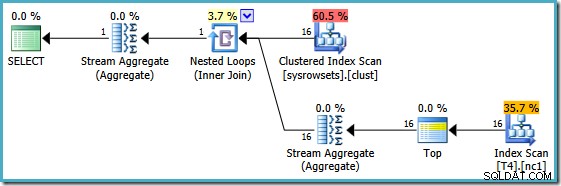
Dit plan leest partitienummers uit een systeemtabel en haalt de laagste waarde van SomeData in elke partitie op. De uiteindelijke Stream Aggregate berekent alleen het minimum over de resultaten per partitie.
Het belangrijkste kenmerk van dit plan is dat het een enkele rij . leest van elke partitie (gebruik makend van de sorteervolgorde van de index binnen elke partitie). Het is veel efficiënter dan het plan van de optimizer dat alle 150.000 rijen in de tabel heeft verwerkt.
MIN en MAX binnen één partitie
Overweeg nu de volgende query om de minimumwaarde in de SomeData-kolom te vinden, voor een reeks RowID-waarden die zich binnen één partitie bevinden :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
We hebben gezien dat de optimizer problemen heeft met MIN en MAX over meerdere partities, maar we zouden verwachten dat die beperkingen niet van toepassing zijn op een enkele partitiequery.
De enkele partitie is de partitie die wordt begrensd door de RowID-waarden 10.000 en 20.000 (zie de definitie van de partitioneringsfunctie). De partitioneringsfunctie is gedefinieerd als RANGE RIGHT , dus de grenswaarde van 10.000 hoort bij partitie #2 en de grens van 20.000 hoort bij partitie #3. Het bereik van RowID-waarden dat door onze nieuwe query is gespecificeerd, bevindt zich daarom alleen in partitie 2.
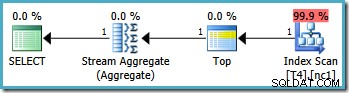
De grafische uitvoeringsplannen voor deze query zien er vanaf 2005 hetzelfde uit op alle SQL Server-versies:
Plananalyse
De optimizer nam het RowID-bereik dat is opgegeven in de WHERE en vergeleek het met de partitiefunctiedefinitie om te bepalen dat alleen partitie 2 van de niet-geclusterde index moest worden geopend. De eigenschappen van het SQL Server 2005-plan voor de Index Scan laten de toegang tot één partitie duidelijk zien:
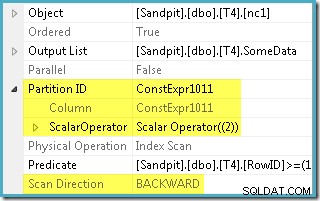
De andere gemarkeerde eigenschap is de scanrichting. De volgorde van de scan verschilt afhankelijk van of de query zoekt naar de minimale of maximale SomeData-waarde. De niet-geclusterde index is geordend (per partitie, onthoud) op oplopende SomeData-waarden, dus de Index Scan-richting is FORWARD als de zoekopdracht om de minimumwaarde vraagt, en BACKWARD als de maximale waarde nodig is (de schermafbeelding hierboven is genomen van de MAX zoekplan).
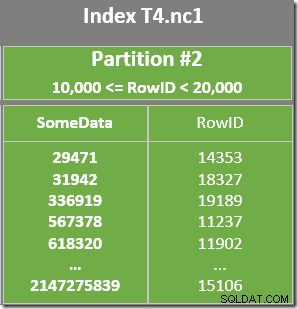
Er is ook een residuaal predikaat op de indexscan om te controleren of de RowID-waarden die zijn gescand vanaf partitie 2 overeenkomen met de WHERE clausule predikaat. De optimizer gaat ervan uit dat RowID-waarden vrij willekeurig worden verdeeld via de niet-geclusterde index, dus verwacht de eerste rij te vinden die overeenkomt met de WHERE clausule predikaat vrij snel. Het gepartitioneerde gegevenslay-outdiagram laat zien dat de RowID-waarden inderdaad vrij willekeurig zijn verdeeld in de index (die is geordend door de SomeData-kolom onthoud):
De topoperator in het zoekplan beperkt de indexscan tot een enkele rij (van het lage of het hoge uiteinde van de index, afhankelijk van de scanrichting). Indexscans kunnen problematisch zijn in zoekplannen, maar de Top-operator maakt het hier een efficiënte optie:de scan kan maar één rij produceren, dan stopt het. De combinatie Top en geordende Index Scan voert effectief een zoekactie uit naar de hoogste of laagste waarde in de index die ook overeenkomt met de WHERE clausule predikaten. Een Stream Aggregate verschijnt ook in het plan om ervoor te zorgen dat een NULL wordt gegenereerd als er geen rijen worden geretourneerd door de Index Scan. Scalaire MIN en MAX aggregaten worden gedefinieerd om een NULL . te retourneren wanneer de invoer een lege set is.
Over het algemeen is dit een zeer efficiënte strategie en de kosten van de plannen worden geschat op slechts 0,0032921 eenheden als resultaat. Tot nu toe zo goed.
Het grenswaardeprobleem
Dit volgende voorbeeld wijzigt de bovenkant van het RowID-bereik:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
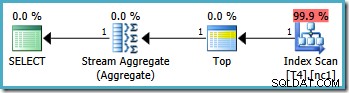
Merk op dat de zoekopdracht uitsluit de waarde van 20.000 door een "minder dan"-operator te gebruiken. Bedenk dat de 20.000 waarde bij partitie 3 hoort (niet partitie 2) omdat de partitiefunctie is gedefinieerd als RANGE RIGHT . De SQL Server 2005 Optimizer handelt deze situatie correct af en produceert het optimale queryplan met één partitie, met geschatte kosten van 0,0032878 :
Dezelfde query produceert echter een ander plan op SQL Server 2008 en later (inclusief SQL Server 2014 CTP 1):
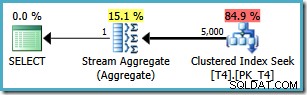
Nu hebben we een Clustered Index Seek (in plaats van de gewenste combinatie van Index Scan en Top-operator). Alle 5.000 rijen die overeenkomen met de WHERE clausule worden verwerkt via het Stroomaggregaat in dit nieuwe uitvoeringsplan. De geschatte kosten van dit abonnement zijn 0.0199319 eenheden – meer dan zes keer de kosten van het SQL Server 2005-abonnement.
Oorzaak
De optimalisatieprogramma's voor SQL Server 2008 (en later) krijgen de interne logica niet helemaal goed wanneer een interval verwijst, maar uitsluit , een grenswaarde die bij een andere partitie hoort. De optimizer denkt ten onrechte dat er toegang zal worden verkregen tot meerdere partities en concludeert dat het de optimalisatie van één partitie voor MIN niet kan gebruiken en MAX aggregaten.
Oplossingen
Een optie is om de query te herschrijven met behulp van>=en <=operators, zodat we niet verwijzen naar een grenswaarde van een andere partitie (zelfs om deze uit te sluiten!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Dit resulteert in het optimale plan, waarbij een enkele partitie wordt aangeraakt:
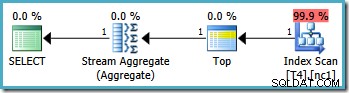
Helaas is het niet altijd mogelijk om op deze manier correcte grenswaarden op te geven (afhankelijk van het type scheidingskolom). Een voorbeeld hiervan is bij datum- en tijdtypen waarbij het het beste is om halfopen intervallen te gebruiken. Een ander bezwaar tegen deze tijdelijke oplossing is subjectiever:de partitioneringsfunctie sluit één grens uit van het bereik, dus het lijkt het meest natuurlijk om de query ook te schrijven met half-open intervalsyntaxis.
Een tweede oplossing is om het partitienummer expliciet op te geven (en het half-open interval te behouden):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Dit levert het optimale plan op, maar kost wel een extra predikaat en vertrouwt op de gebruiker om te bepalen wat het partitienummer zou moeten zijn.
Het zou natuurlijk beter zijn als de optimizers van 2008 en later hetzelfde optimale plan zouden produceren als SQL Server 2005. In een perfecte wereld zou een uitgebreidere oplossing ook de zaak met meerdere partities aanpakken, waardoor de tijdelijke oplossing die Itzik beschrijft ook onnodig zou zijn.