Tabelpartitionering in SQL Server is in wezen een manier om meerdere fysieke tabellen (rijensets) eruit te laten zien als één enkele tabel. Deze abstractie wordt volledig uitgevoerd door de query-processor, een ontwerp dat het voor gebruikers eenvoudiger maakt, maar dat complexe eisen stelt aan de query-optimizer. Dit bericht kijkt naar twee voorbeelden die de mogelijkheden van de optimizer in SQL Server 2008 en later overtreffen.
Deelnemen aan kolomvolgorde is belangrijk
Dit eerste voorbeeld laat zien hoe de tekstvolgorde van ON clausulevoorwaarden kunnen van invloed zijn op het queryplan dat wordt geproduceerd bij het samenvoegen van gepartitioneerde tabellen. Om te beginnen hebben we een partitieschema, een partitiefunctie en twee tabellen nodig:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Vervolgens laden we beide tabellen met 150.000 rijen. De gegevens doen er niet zoveel toe; in dit voorbeeld wordt een standaard Numbers-tabel gebruikt die alle integerwaarden van 1 tot 150.000 als gegevensbron bevat. Beide tabellen worden geladen met dezelfde gegevens.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Onze testquery voert een eenvoudige inner join uit van deze twee tabellen. Nogmaals, de query is niet belangrijk of bedoeld om bijzonder realistisch te zijn, hij wordt gebruikt om een vreemd effect te demonstreren bij het samenvoegen van gepartitioneerde tabellen. De eerste vorm van de zoekopdracht gebruikt een ON clausule geschreven in c3, c2, c1 kolomvolgorde:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Het uitvoeringsplan dat voor deze query is gemaakt (op SQL Server 2008 en later) bevat een parallelle hash-join, met een geschatte kostprijs van 2.6953 :
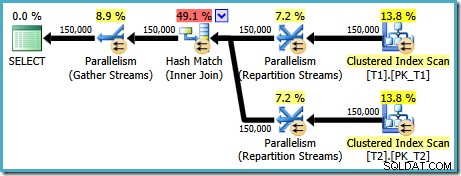
Dit is een beetje onverwacht. Beide tabellen hebben een geclusterde index in (c1, c2, c3) volgorde, gepartitioneerd door c1, dus we zouden een merge join verwachten, waarbij gebruik wordt gemaakt van de indexvolgorde. Laten we proberen de ON . te schrijven clausule in (c1, c2, c3) volgorde in plaats daarvan:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Het uitvoeringsplan gebruikt nu de verwachte merge-join, met geschatte kosten van 1,64119 (verlaagd van 2.6953 ). De optimizer besluit ook dat het niet de moeite waard is om parallelle uitvoering te gebruiken:
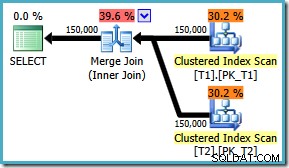
We merken op dat het plan voor het samenvoegen van samenvoegingen duidelijk efficiënter is. We kunnen proberen om een samenvoeging af te dwingen voor de originele ON clausulevolgorde met behulp van een vraaghint:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Het resulterende plan maakt gebruik van een merge-join zoals gevraagd, maar het biedt ook sorteringen op beide ingangen en gaat terug naar het gebruik van parallellisme. De geschatte kosten van dit abonnement zijn maar liefst 8.71063 :
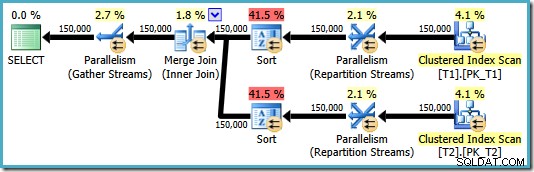
Beide sorteeroperatoren hebben dezelfde eigenschappen:
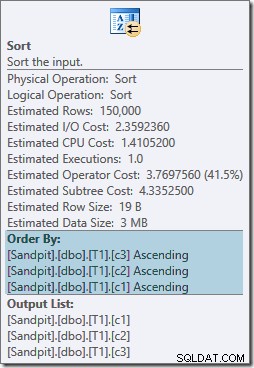
De optimizer denkt dat de samenvoeg-join zijn invoer moet sorteren in de strikte schriftelijke volgorde van de ON clausule, met als resultaat de introductie van expliciete soorten. De optimizer is zich ervan bewust dat een merge-join zijn invoer op dezelfde manier moet sorteren, maar hij weet ook dat de kolomvolgorde er niet toe doet. Samenvoegen op (c1, c2, c3) is net zo blij met invoer gesorteerd op (c3, c2, c1) als met invoer gesorteerd op (c2, c1, c3) of een andere combinatie.
Helaas wordt deze redenering doorbroken in de query-optimizer als er sprake is van partitionering. Dit is een optimalisatiefout dat is opgelost in SQL Server 2008 R2 en later, hoewel traceringsvlag 4199 is vereist om de fix te activeren:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Normaal gesproken zou u deze traceringsvlag inschakelen met DBCC TRACEON of als opstartoptie, omdat de QUERYTRACEON hint is niet gedocumenteerd voor gebruik met 4199. De traceringsvlag is vereist in SQL Server 2008 R2, SQL Server 2012 en SQL Server 2014 CTP1.
Hoe dan ook, hoe de vlag ook is ingeschakeld, de query produceert nu de optimale merge join, ongeacht de ON clausule bestellen:
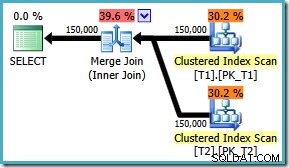
Er is geen oplossing voor SQL Server 2008 , de oplossing is om de ON . te schrijven clausule in de ‘juiste’ volgorde! Als je een query als deze tegenkomt op SQL Server 2008, probeer dan een merge join te forceren en kijk naar de sorteringen om de 'juiste' manier te bepalen om je query's ON te schrijven. clausule.
Dit probleem doet zich niet voor in SQL Server 2005 omdat die release gepartitioneerde query's implementeerde met behulp van de APPLY model:

Het queryplan voor SQL Server 2005 voegt één partitie van elke tabel tegelijk toe, met behulp van een in-memory tabel (de constante scan) die partitienummers bevat om te verwerken. Elke partitie wordt afzonderlijk samengevoegd aan de binnenkant van de join, en de 2005-optimizer is slim genoeg om te zien dat de ON clausule kolomvolgorde maakt niet uit.
Dit laatste abonnement is een voorbeeld van een collocated merge join , een voorziening die verloren ging bij het overstappen van SQL Server 2005 naar de nieuwe partitie-implementatie in SQL Server 2008. Een suggestie voor Connect om samengevoegde samenvoeg-joins te herstellen is gesloten omdat het niet zal worden opgelost.
Groep op bestelling is belangrijk
De tweede eigenaardigheid waar ik naar wil kijken volgt een soortgelijk thema, maar heeft betrekking op de volgorde van kolommen in een GROUP BY clausule in plaats van de ON clausule van een inner join. We hebben een nieuwe tabel nodig om te demonstreren:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; De tabel heeft een uitgelijnde niet-geclusterde index, waarbij 'uitgelijnd' simpelweg betekent dat deze op dezelfde manier is gepartitioneerd als de geclusterde index (of heap):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Onze testquery groepeert gegevens over de drie niet-geclusterde indexkolommen en retourneert een telling voor elke groep:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Het queryplan scant de niet-geclusterde index en gebruikt een Hash Match Aggregate om rijen in elke groep te tellen:
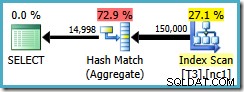
Er zijn twee problemen met Hash Aggregate:
- Het is een blokkerende operator. Er worden geen rijen teruggestuurd naar de client totdat alle rijen zijn geaggregeerd.
- Het vereist een geheugentoekenning om de hashtabel vast te houden.
In veel real-world scenario's geven we hier de voorkeur aan een Stream Aggregate omdat die operator alleen per groep blokkeert en geen geheugentoekenning vereist. Met deze optie zou de clienttoepassing eerder beginnen met het ontvangen van gegevens, niet hoeven te wachten op het verlenen van geheugen en de SQL Server kan het geheugen voor andere doeleinden gebruiken.
We kunnen de query-optimizer vragen om een Stream Aggregate voor deze query te gebruiken door een OPTION (ORDER GROUP) toe te voegen. vraag hint. Dit resulteert in het volgende uitvoeringsplan:

De sorteeroperator blokkeert volledig en vereist ook een geheugentoekenning, dus dit plan lijkt slechter te zijn dan alleen het gebruik van een hash-aggregaat. Maar waarom is het soort nodig? De eigenschappen laten zien dat de rijen worden gesorteerd in de volgorde die is opgegeven door onze GROUP BY clausule:
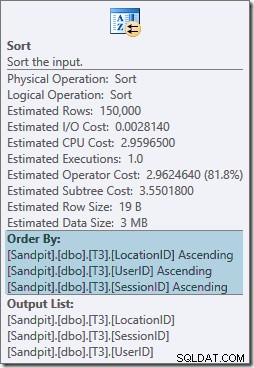
Deze soort is verwacht omdat het uitlijnen van de index (vanaf SQL Server 2008) betekent dat het partitienummer wordt toegevoegd als een leidende kolom van de index. In feite zijn de niet-geclusterde indexsleutels (partitie, gebruiker, sessie, locatie) te wijten aan de partitionering. Rijen in de index worden nog steeds gesorteerd op gebruiker, sessie en locatie, maar alleen binnen elke partitie.
Als we de query beperken tot een enkele partitie, zou de optimizer de index moeten kunnen gebruiken om een Stream Aggregate te voeden zonder te sorteren. In het geval dat enige uitleg vereist, betekent het specificeren van een enkele partitie dat het queryplan alle andere partities uit de niet-geclusterde indexscan kan elimineren, wat resulteert in een stroom van rijen die is geordend op (gebruiker, sessie, locatie).
We kunnen deze partitie-eliminatie expliciet bereiken met behulp van de $PARTITION functie:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Helaas gebruikt deze zoekopdracht nog steeds een hash-aggregaat, met geschatte abonnementskosten van 0,287878 :
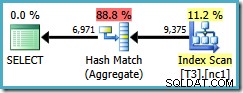
De scan is nu iets meer dan één partitie, maar de volgorde (gebruiker, sessie, locatie) heeft de optimizer niet geholpen om een Stream Aggregate te gebruiken. U kunt bezwaar maken dat (gebruiker, sessie, locatie) bestellen niet helpt omdat de GROUP BY clausule is (locatie, gebruiker, sessie), maar de volgorde van de sleutels is niet van belang voor een groeperingsbewerking.
Laten we een ORDER BY . toevoegen clausule in de volgorde van de indexsleutels om het punt te bewijzen:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Merk op dat de ORDER BY clausule komt overeen met de niet-geclusterde indexsleutelvolgorde, hoewel de GROUP BY clausule niet. Het uitvoeringsplan voor deze query is:
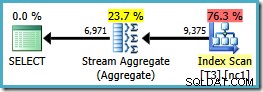
Nu hebben we het Stream Aggregate waar we naar op zoek waren, met geschatte abonnementskosten van 0.0423925 (vergeleken met 0,287878 voor het Hash Aggregate-plan - bijna 7 keer meer).
De andere manier om hier een Stream Aggregate te bereiken, is door de GROUP BY . opnieuw te ordenen kolommen die overeenkomen met de niet-geclusterde indexsleutels:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Deze query levert hetzelfde Stream Aggregate-plan op als direct hierboven, met exact dezelfde kosten. Deze gevoeligheid voor GROUP BY kolomvolgorde is specifiek voor gepartitioneerde tabelquery's in SQL Server 2008 en later.
U herkent misschien dat de hoofdoorzaak van het probleem hier vergelijkbaar is met het vorige geval met betrekking tot een Merge Join. Zowel Merge Join als Stream Aggregate vereisen invoer gesorteerd op de join- of aggregatiesleutels, maar geen van beide geeft om de volgorde van die sleutels. Een Merge Join op (x, y, z) is net zo blij met het ontvangen van rijen gerangschikt op (y, z, x) of (z, y, x) en hetzelfde geldt voor Stream Aggregate.
Deze optimalisatiebeperking is ook van toepassing op DISTINCT in dezelfde omstandigheden. De volgende zoekopdracht resulteert in een Hash Aggregate-abonnement met geschatte kosten van 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
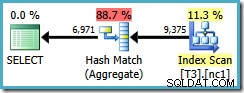
Als we de DISTINCT . schrijven kolommen in de volgorde van de niet-geclusterde indexsleutels...
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
...we worden beloond met een Stream Aggregate-abonnement met een kostprijs van 0,041455 :

Samenvattend is dit een beperking van de query-optimizer in SQL Server 2008 en later (inclusief SQL Server 2014 CTP 1) die niet wordt opgelost door traceringsvlag 4199 te gebruiken zoals het geval was voor het Merge Join-voorbeeld. Het probleem doet zich alleen voor bij gepartitioneerde tabellen met een GROUP BY of DISTINCT over drie of meer kolommen met behulp van een uitgelijnde gepartitioneerde index, waar een enkele partitie wordt verwerkt.
Net als bij het Merge Join-voorbeeld, vertegenwoordigt dit een stap achteruit ten opzichte van het gedrag van SQL Server 2005. SQL Server 2005 heeft geen impliciete leidende sleutel toegevoegd aan gepartitioneerde indexen, met behulp van een APPLY techniek in plaats daarvan. In SQL Server 2005 werden alle query's die hier worden gepresenteerd met behulp van $PARTITION om een enkel partitieresultaat op te geven in queryplannen die partitieverwijdering uitvoeren en Stream Aggregates gebruiken zonder dat de querytekst opnieuw wordt gerangschikt.
De wijzigingen in de verwerking van gepartitioneerde tabellen in SQL Server 2008 hebben de prestaties op verschillende belangrijke gebieden verbeterd, voornamelijk met betrekking tot de efficiënte parallelle verwerking van partities. Helaas hadden deze wijzigingen bijwerkingen die niet allemaal in latere releases zijn opgelost.