Partitionering is een SQL Server-functie die vaak wordt geïmplementeerd om uitdagingen met betrekking tot beheersbaarheid, onderhoudstaken of vergrendeling en blokkering te verlichten. Het beheer van grote tabellen kan eenvoudiger worden met partitionering en het kan de schaalbaarheid en beschikbaarheid verbeteren. Bovendien kan een bijproduct van partitionering de prestaties van query's verbeteren. Het is geen garantie of een gegeven, en het is niet de belangrijkste reden om partitionering te implementeren, maar het is de moeite waard om te bekijken wanneer je een grote tabel partitioneert.
Achtergrond
Even een kort overzicht:de SQL Server-partitioneringsfunctie is alleen beschikbaar in Enterprise- en Developer Editions. Partitionering kan worden geïmplementeerd tijdens het initiële databaseontwerp, of het kan worden ingevoerd nadat een tabel al gegevens bevat. Begrijp dat het wijzigen van een bestaande tabel met gegevens naar een gepartitioneerde tabel niet altijd snel en eenvoudig is, maar met een goede planning best haalbaar is en de voordelen snel kunnen worden gerealiseerd.
Een gepartitioneerde tabel is een tabel waarin de gegevens worden gescheiden in kleinere fysieke structuren op basis van de waarde voor een specifieke kolom (de zogenaamde partitioneringskolom, die is gedefinieerd in de partitiefunctie). Als u gegevens per jaar wilt scheiden, kunt u een kolom met de naam DateSold gebruiken als de partitioneringskolom, en alle gegevens voor 2013 zouden in één structuur staan, alle gegevens voor 2012 in een andere structuur, enz. Deze afzonderlijke gegevenssets gefocust onderhoud mogelijk maken (u kunt slechts een partitie van een index opnieuw opbouwen in plaats van de hele index) en toestaan dat gegevens snel worden toegevoegd en verwijderd omdat het kan worden gefaseerd voordat het daadwerkelijk wordt toegevoegd aan of verwijderd uit de tabel.
De installatie
Om de verschillen in queryprestaties voor een gepartitioneerde versus een niet-gepartitioneerde tabel te onderzoeken, heb ik twee kopieën gemaakt van de tabel Sales.SalesOrderHeader uit de AdventureWorks2012-database. De niet-gepartitioneerde tabel is gemaakt met alleen een geclusterde index op SalesOrderID, de traditionele primaire sleutel voor de tabel. De tweede tabel was gepartitioneerd op OrderDate, met OrderDate en SalesOrderID als clustersleutel, en had geen extra indexen. Houd er rekening mee dat er tal van factoren zijn waarmee u rekening moet houden bij het beslissen welke kolom u wilt gebruiken voor partitionering. Bij partitionering wordt vaak, maar zeker niet altijd, een datumveld gebruikt om de partitiegrenzen te definiëren. Als zodanig is OrderDate voor dit voorbeeld geselecteerd en zijn voorbeeldquery's gebruikt om typische activiteiten op basis van de tabel SalesOrderHeader te simuleren. De instructies om beide tabellen te maken en in te vullen kunnen hier worden gedownload.
Na het maken van de tabellen en het toevoegen van gegevens, werden de bestaande indexen geverifieerd en vervolgens werden de statistieken bijgewerkt met FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Bovendien hebben beide tabellen exact dezelfde gegevensverdeling en minimale fragmentatie.
Prestaties voor een eenvoudige zoekopdracht
Voordat er aanvullende indexen werden toegevoegd, werd een basisquery uitgevoerd op beide tabellen om de totalen te berekenen die door verkopers werden verdiend voor bestellingen die in december 2012 waren geplaatst:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSTATISTIEKEN IO-UITGANG
Tafel 'Werktafel'. Scantelling 0, logische leest 0, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Big_SalesOrderHeader'. Scantelling 9, logische leest 2710440, fysieke leest 2226, read-ahead leest 2658769, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tafel 'Werktafel'. Scantelling 0, logische leest 0, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Part_SalesOrderHeader'. Scantelling 9, logische leest 248128, fysieke leest 3, read-ahead leest 245030, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.

Totalen per verkoper voor december – niet-gepartitioneerde tabel
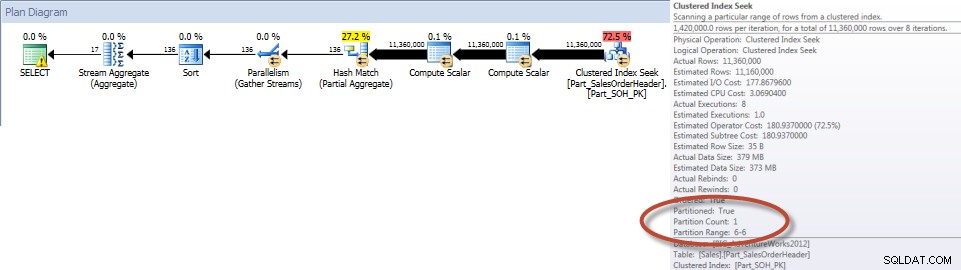
Totalen per verkoper voor december – gepartitioneerde tabel
Zoals verwacht moest de query op de niet-gepartitioneerde tabel een volledige scan van de tabel uitvoeren omdat er geen index was om deze te ondersteunen. Daarentegen was de query op de gepartitioneerde tabel alleen nodig om toegang te krijgen tot één partitie van de tabel.
Om eerlijk te zijn, als dit een query was die herhaaldelijk werd uitgevoerd met verschillende datumbereiken, zou de juiste niet-geclusterde index bestaan. Bijvoorbeeld:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Als deze index is gemaakt, dalen de I/O-statistieken wanneer de query opnieuw wordt uitgevoerd en verandert het plan om de niet-geclusterde index te gebruiken:
STATISTIEKEN IO-UITGANG
Tafel 'Werktafel'. Scantelling 0, logische leest 0, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Big_SalesOrderHeader'. Scantelling 9, logische leest 42901, fysieke leest 3, read-ahead leest 42346, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.

Totalen per verkoper voor december – NCI op niet-gepartitioneerde tabel
Met een ondersteunende index vereist de query op Sales.Big_SalesOrderHeader aanzienlijk minder leesbewerkingen dan de geclusterde indexscan op Sales.Part_SalesOrderHeader, wat niet onverwacht is omdat de geclusterde index veel breder is. Als we een vergelijkbare niet-geclusterde index maken voor Sales.Part_SalesOrderHeader, zien we vergelijkbare I/O-nummers:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATISTIEKEN IO-UITGANG
Tabel 'Part_SalesOrderHeader'. Scantelling 9, logische leest 42894, fysieke leest 1, read-ahead leest 42378, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
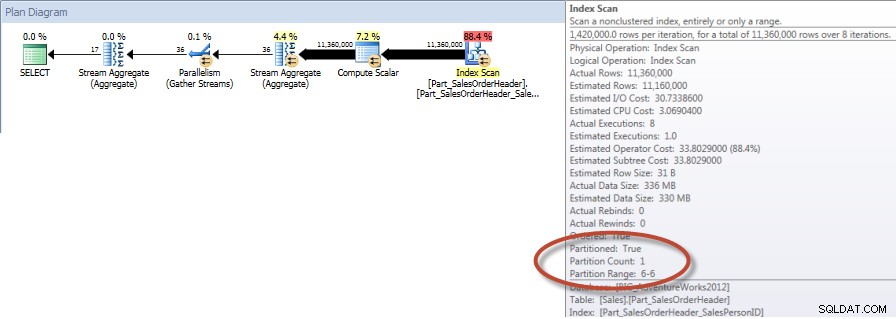
Totalen per verkoper voor december – NCI op gepartitioneerde tabel met eliminatie
En als we kijken naar de eigenschappen van de niet-geclusterde Index Scan, kunnen we verifiëren dat de engine slechts één partitie heeft benaderd (6).
Zoals oorspronkelijk vermeld, wordt partitionering meestal niet geïmplementeerd om de prestaties te verbeteren. In het bovenstaande voorbeeld presteert de query op de gepartitioneerde tabel niet significant beter zolang de juiste niet-geclusterde index bestaat.
Prestaties voor een ad-hocquery
Een query op de gepartitioneerde tabel can presteren in sommige gevallen beter dan dezelfde query ten opzichte van de niet-gepartitioneerde tabel, bijvoorbeeld wanneer de query de geclusterde index moet gebruiken. Hoewel het ideaal is om de meeste zoekopdrachten te laten ondersteunen door niet-geclusterde indexen, staan sommige systemen ad-hocquery's van gebruikers toe, en andere hebben zoekopdrachten die zo zeldzaam kunnen worden uitgevoerd dat ze geen ondersteuning van indexen rechtvaardigen. Tegen de SalesOrderHeader-tabel kan een gebruiker de volgende zoekopdracht uitvoeren om bestellingen van december 2012 te vinden die tegen het einde van het jaar moesten worden verzonden, maar dat niet zijn gedaan, voor een bepaalde groep klanten en met een TotalDue groter dan $ 1000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSTATISTIEKEN IO-UITGANG
Tabel 'Big_SalesOrderHeader'. Scantelling 9, logische leest 2711220, fysieke leest 8386, read-ahead leest 2662400, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Part_SalesOrderHeader'. Scantelling 9, logische leest 248128, fysieke leest 0, read-ahead leest 243792, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
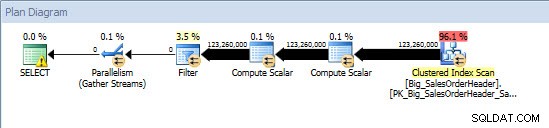
Ad-hocquery – niet-gepartitioneerde tabel
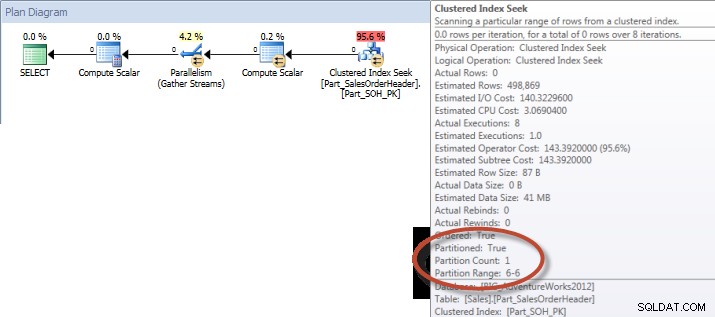
Ad-hocquery – gepartitioneerde tabel
Tegen de niet-gepartitioneerde tabel vereiste de query een volledige scan tegen de geclusterde index, maar tegen de gepartitioneerde tabel voerde de query een indexzoektocht uit van de geclusterde index, omdat de engine partitie-eliminatie gebruikte en alleen de gegevens las die absoluut nodig waren. In dit voorbeeld is het een aanzienlijk verschil in termen van I/O, en afhankelijk van de hardware kan het een dramatisch verschil in uitvoeringstijd zijn. De zoekopdracht kan worden geoptimaliseerd door de juiste index toe te voegen, maar het is meestal niet haalbaar om te indexeren voor elke enkel vraag. Met name voor oplossingen die ad-hocquery's mogelijk maken, is het eerlijk om te zeggen dat u nooit weet wat gebruikers gaan doen. Een query kan één keer worden uitgevoerd en nooit meer worden uitgevoerd, en het is nutteloos om achteraf een index te maken. Daarom is het belangrijk om bij het overschakelen van een niet-gepartitioneerde tabel naar een gepartitioneerde tabel dezelfde inspanning en benadering toe te passen als bij het regelmatig afstemmen van indexen; u wilt controleren of de juiste indexen bestaan om de meeste zoekopdrachten te ondersteunen.
Prestaties en indexuitlijning
Een extra factor waarmee u rekening moet houden bij het maken van indexen voor een gepartitioneerde tabel, is of de index moet worden uitgelijnd of niet. Indexen moeten worden uitgelijnd met de tabel als u van plan bent om gegevens in en uit partities te schakelen. Door een niet-geclusterde index op een gepartitioneerde tabel te maken, wordt standaard een uitgelijnde index gemaakt, waarbij de partitioneringskolom als een opgenomen kolom aan de index wordt toegevoegd.
Een niet-uitgelijnde index wordt gemaakt door een ander partitieschema of een andere bestandsgroep op te geven. De partitioneringskolom kan deel uitmaken van de index als een sleutelkolom of een opgenomen kolom, maar als het partitieschema van de tabel niet wordt gebruikt of als een andere bestandsgroep wordt gebruikt, wordt de index niet uitgelijnd.
Een uitgelijnde index is net als de tabel gepartitioneerd - de gegevens zullen in afzonderlijke structuren bestaan - en daarom kan partitie-eliminatie plaatsvinden. Een niet-uitgelijnde index bestaat als één fysieke structuur en biedt mogelijk niet het verwachte voordeel voor een zoekopdracht, afhankelijk van het predikaat. Overweeg een zoekopdracht die de verkopen telt op rekeningnummer, gegroepeerd op maand:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Als u niet zo bekend bent met partitioneren, kunt u een dergelijke index maken om de query te ondersteunen (merk op dat de PRIMARY bestandsgroep is opgegeven):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Deze index is niet uitgelijnd, ook al bevat deze OrderDate omdat deze deel uitmaakt van de primaire sleutel. De kolommen worden ook opgenomen als we een uitgelijnde index maken, maar let op het verschil in syntaxis:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
We kunnen controleren welke kolommen in de index voorkomen met behulp van Kimberly Tripp's sp_helpindex:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex voor Sales.Part_SalesOrderHeader
Wanneer we onze query uitvoeren en deze dwingen om de niet-uitgelijnde index te gebruiken, wordt de hele index gescand. Ook al is OrderDate onderdeel van de index, het is niet de leidende kolom, dus de engine moet de OrderDate-waarde voor elk AccountNumber controleren om te zien of het tussen 1 januari 2013 en 31 juli 2013 valt:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIEKEN IO-UITGANG
Tafel 'Werktafel'. Scantelling 0, logische leest 0, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Part_SalesOrderHeader'. Scantelling 9, logische leest 786861, fysieke leest 1, read-ahead leest 770929, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
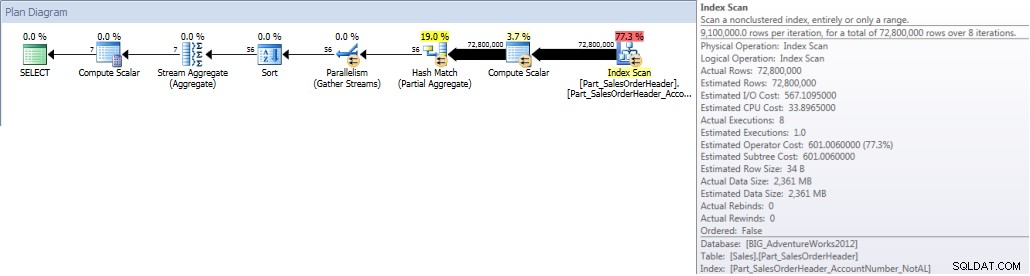
Accounttotalen per maand (januari – juli 2013) met niet- Uitgelijnde NCI (gedwongen)
Wanneer daarentegen de query wordt gedwongen om de uitgelijnde index te gebruiken, kan partitieverwijdering worden gebruikt en zijn er minder I/O's vereist, ook al is OrderDate geen leidende kolom in de index.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIEKEN IO-UITGANG
Tafel 'Werktafel'. Scantelling 0, logische leest 0, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Part_SalesOrderHeader'. Scantelling 9, logische leest 456258, fysieke leest 16, read-ahead leest 453241, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
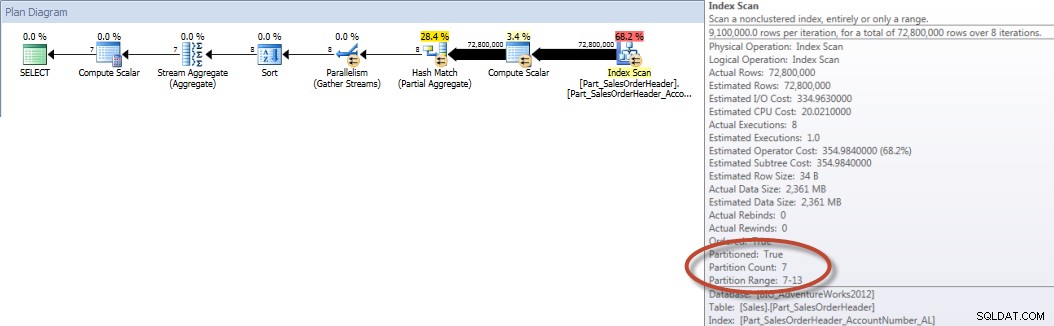
Accounttotalen per maand (januari – juli 2013) met behulp van uitgelijnde NCI (gedwongen)
Samenvatting
De beslissing om partitionering te implementeren is er een die de nodige aandacht en planning vereist. Beheersgemak, verbeterde schaalbaarheid en beschikbaarheid en een vermindering van blokkering zijn veelvoorkomende redenen om tabellen te partitioneren. Het verbeteren van de queryprestaties is geen reden om partitionering toe te passen, hoewel het in sommige gevallen een gunstig neveneffect kan zijn. Wat de prestaties betreft, is het belangrijk ervoor te zorgen dat uw implementatieplan een beoordeling van de queryprestaties bevat. Bevestig dat uw indexen uw zoekopdrachten na . goed blijven ondersteunen de tabel is gepartitioneerd en controleer of query's die gebruik maken van de geclusterde en niet-geclusterde indexen profiteren van partitie-eliminatie waar van toepassing.