De ANY aggregaat is niet iets dat we rechtstreeks in Transact SQL kunnen schrijven. Het is een interne functie die alleen wordt gebruikt door de query-optimizer en uitvoeringsengine.
Persoonlijk ben ik dol op de ANY aggregaat, dus het was een beetje teleurstellend om te horen dat het op een vrij fundamentele manier is gebroken. De specifieke smaak van 'gebroken' waar ik het hier over heb, is de variëteit met verkeerde resultaten.
In dit bericht kijk ik naar twee specifieke plaatsen waar de ANY aggregaat verschijnt vaak, demonstreert het probleem met de verkeerde resultaten en stelt waar nodig tijdelijke oplossingen voor.
Voor achtergrondinformatie over de ANY aggregatie, zie mijn vorige bericht Undocumented Query Plans:The ANY Aggregate.
1. Eén rij per groep zoekopdrachten
Dit moet een van de meest voorkomende dagelijkse vraagvereisten zijn, met een zeer bekende oplossing. Je schrijft dit soort vragen waarschijnlijk elke dag, automatisch het patroon volgend, zonder er echt over na te denken.
Het idee is om de invoerreeks rijen te nummeren met de ROW_NUMBER vensterfunctie, gepartitioneerd door de groeperingskolom of kolommen. Dat is verpakt in een Common Table Expression of afgeleide tabel en gefilterd naar rijen waar het berekende rijnummer gelijk is aan één. Sinds de ROW_NUMBER herstart met één voor elke groep, dit geeft ons de vereiste één rij per groep.
Er is geen probleem met dat algemene patroon. Het type van één rij per groepsquery dat onderhevig is aan de ANY aggregatieprobleem is het probleem waarbij het ons niet uitmaakt welke specifieke rij is geselecteerd van elke groep.
In dat geval is het niet duidelijk welke kolom moet worden gebruikt in de verplichte ORDER BY clausule van de ROW_NUMBER venster functie. Per slot van rekening maakt het ons niet uit welke rij is geselecteerd. Een veelgebruikte benadering is het hergebruiken van de PARTITION BY kolom(men) in de ORDER BY clausule. Dit is waar het probleem kan optreden.
Voorbeeld
Laten we eens kijken naar een voorbeeld met een speelgoeddataset:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
De vereiste is om een volledige rij met gegevens van elke groep te retourneren, waarbij het groepslidmaatschap wordt gedefinieerd door de waarde in kolom c1 .

Na de ROW_NUMBER patroon, kunnen we een query schrijven als de volgende (let op de ORDER BY clausule van de ROW_NUMBER vensterfunctie komt overeen met de PARTITION BY clausule):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Zoals gepresenteerd, wordt deze query met succes uitgevoerd, met de juiste resultaten. De resultaten zijn technisch niet-deterministisch omdat SQL Server een van de rijen in elke groep geldig kan retourneren. Desalniettemin, als u deze query zelf uitvoert, is de kans groot dat u hetzelfde resultaat krijgt als ik:
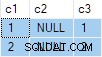
Het uitvoeringsplan is afhankelijk van de versie van SQL Server die wordt gebruikt en is niet afhankelijk van het compatibiliteitsniveau van de database.
Op SQL Server 2014 en eerder is het plan:

Voor SQL Server 2016 of later ziet u:

Beide plannen zijn veilig, maar om verschillende redenen. De verschillende sortering abonnement bevat een ANY geaggregeerd, maar de Distinct Sort operator implementatie manifesteert de bug niet.
Het meer complexe SQL Server 2016+ plan maakt geen gebruik van de ANY aggregaat helemaal niet. Het Sorteren zet de rijen in de volgorde die nodig is voor de rijnummering. Het segment operator plaatst een vlag aan het begin van elke nieuwe groep. Het Sequentiële Project berekent het rijnummer. Ten slotte, de Filter operator geeft alleen die rijen door waarvan het berekende rijnummer één is.
De bug
Om onjuiste resultaten te krijgen met deze dataset, moeten we SQL Server 2014 of eerder gebruiken en de ANY aggregaten moeten worden geïmplementeerd in een Stream Aggregate of Eager Hash Aggregate operator (Flow Distinct Hash Match Aggregate produceert de bug niet).
Een manier om de optimizer aan te moedigen een Stream Aggregate te kiezen in plaats van Afzonderlijke sortering is om een geclusterde index toe te voegen om te ordenen op kolom c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Na die wijziging wordt het uitvoeringsplan:

De ANY aggregaten zijn zichtbaar in de Eigenschappen venster wanneer de Stream Aggregate operator is geselecteerd:

Het resultaat van de zoekopdracht is:
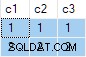
Dit is fout . SQL Server heeft rijen geretourneerd die niet bestaan in de brongegevens. Er zijn geen bronrijen waar c2 = 1 en c3 = 1 bijvoorbeeld. Ter herinnering, de brongegevens zijn:
Het uitvoeringsplan berekent ten onrechte aparte ANY aggregaten voor de c2 en c3 kolommen, het negeren van nulls. Elk aggregeert onafhankelijk geeft de eerste niet-null . terug waarde die het tegenkomt, wat een resultaat geeft waarbij de waarden voor c2 en c3 komen uit verschillende bronrijen . Dit is niet wat de oorspronkelijke SQL-queryspecificatie vroeg.
Hetzelfde verkeerde resultaat kan worden geproduceerd met of zonder de geclusterde index door een OPTION (HASH GROUP) . toe te voegen hint om een plan te maken met een Eager Hash Aggregate in plaats van een Stream Aggregate .
Voorwaarden
Dit probleem kan alleen optreden als er meerdere ANY aggregaten zijn aanwezig en de geaggregeerde gegevens bevatten nulls. Zoals opgemerkt, treft het probleem alleen Stream Aggregate en Eager Hash Aggregate exploitanten; Verschillende sortering en Flow Distinct worden niet beïnvloed.
SQL Server 2016 en later doet zijn best om de introductie van meerdere ANY . te vermijden aggregaties voor elke rij per groep rijnummering querypatroon wanneer de bronkolommen nullable zijn. Wanneer dit gebeurt, bevat het uitvoeringsplan Segment , Volgproject , en Filteren operators in plaats van een aggregaat. Deze planvorm is altijd veilig, aangezien geen ANY aggregaten worden gebruikt.
De bug reproduceren in SQL Server 2016+
De SQL Server-optimizer is niet perfect in het detecteren wanneer een kolom oorspronkelijk beperkt was tot NOT NULL kan nog steeds een null-tussenwaarde produceren door gegevensmanipulaties.
Om dit te reproduceren, beginnen we met een tabel waarin alle kolommen zijn gedeclareerd als NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
We kunnen op vele manieren nulls uit deze dataset produceren, waarvan de meeste de optimizer met succes kan detecteren, en dus vermijden we ANY te introduceren. aggregaten tijdens optimalisatie.
Een manier om nulls toe te voegen die toevallig onder de radar glippen, wordt hieronder weergegeven:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Die query levert de volgende uitvoer op:
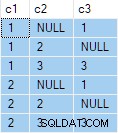
De volgende stap is om die zoekopdrachtspecificatie te gebruiken als de brongegevens voor de standaardquery 'elke rij per groep':
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Op elke versie van SQL Server, dat het volgende plan oplevert:
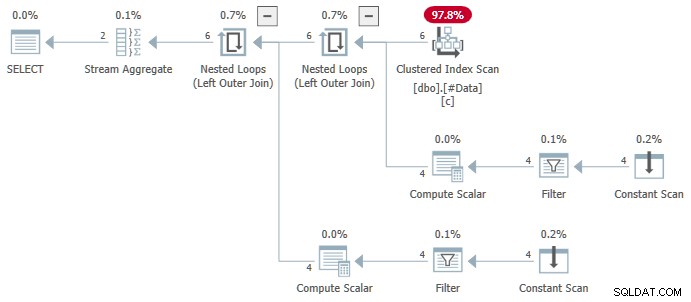
Het Streamaggregaat bevat meerdere ANY aggregaten, en het resultaat is fout . Geen van de geretourneerde rijen verschijnt in de brongegevensset:
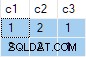
db<>fiddle online demo
Tussenoplossing
De enige volledig betrouwbare oplossing totdat deze bug is opgelost, is om het patroon te vermijden waarin de ROW_NUMBER heeft dezelfde kolom in de ORDER BY clausule zoals in de PARTITION BY clausule.
Als het ons niet uitmaakt welke één rij is geselecteerd uit elke groep, het is jammer dat een ORDER BY clausule is helemaal niet nodig. Een manier om het probleem te omzeilen is het gebruik van een runtimeconstante zoals ORDER BY @@SPID in de vensterfunctie.
2. Niet-deterministische update
Het probleem met meerdere ANY aggregaties op nullable-invoer is niet beperkt tot het querypatroon van één rij per groep. De query-optimizer kan een interne ANY . introduceren aggregeren in een aantal omstandigheden. Een van die gevallen is een niet-deterministische update.
Een niet-deterministische update is waar de instructie niet garandeert dat elke doelrij maximaal één keer wordt bijgewerkt. Met andere woorden, er zijn meerdere bronrijen voor ten minste één doelrij. De documentatie waarschuwt hier expliciet voor:
Wees voorzichtig bij het specificeren van de FROM-clausule om de criteria voor de update-bewerking op te geven.De resultaten van een UPDATE-instructie zijn niet gedefinieerd als de instructie een FROM-clausule bevat die niet zodanig is gespecificeerd dat er slechts één waarde beschikbaar is voor elke kolom die wordt bijgewerkt, dat is als de UPDATE-instructie niet deterministisch is.
Om een niet-deterministische update af te handelen, groepeert de optimizer de rijen op een sleutel (index of RID) en past ANY toe aggregeert naar de overige kolommen. Het basisidee daar is om één rij uit meerdere kandidaten te kiezen en waarden uit die rij te gebruiken om de update uit te voeren. Er zijn duidelijke parallellen met de vorige ROW_NUMBER probleem, dus het is geen verrassing dat het vrij eenvoudig is om een onjuiste update aan te tonen.
In tegenstelling tot het vorige nummer onderneemt SQL Server momenteel geen speciale stappen om meerdere ANY . te vermijden aggregaten op nullable kolommen bij het uitvoeren van een niet-deterministische update. Het volgende heeft daarom betrekking op alle SQL Server-versies , inclusief SQL Server 2019 CTP 3.0.
Voorbeeld
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>fiddle online demo
Logischerwijs zou deze update altijd een fout moeten opleveren:de doeltabel staat in geen enkele kolom nulls toe. Welke overeenkomende rij ook wordt gekozen uit de brontabel, een poging om kolom c2 . bij te werken of c3 naar null moeten voorkomen.
Helaas slaagt de update en de uiteindelijke status van de doeltabel komt niet overeen met de aangeleverde gegevens:
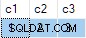
Ik heb dit gemeld als een bug. De oplossing is om niet-deterministische UPDATE te schrijven verklaringen, dus ANY aggregaten zijn niet nodig om de dubbelzinnigheid op te lossen.
Zoals vermeld, kan SQL Server ANY . introduceren aggregaten in meer omstandigheden dan de twee voorbeelden die hier worden gegeven. Als dit gebeurt wanneer de geaggregeerde kolom nulls bevat, bestaat de kans op verkeerde resultaten.