Dit artikel is het derde deel in een serie over T-SQL-bugs, valkuilen en best practices. Eerder behandelde ik determinisme en subquery's. Deze keer focus ik me op joins. Sommige van de bugs en best practices die ik hier behandel, zijn het resultaat van een enquête die ik heb gehouden onder andere MVP's. Bedankt Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man en Paul White voor het aanbieden van uw inzichten!
In mijn voorbeelden gebruik ik een voorbeelddatabase met de naam TSQLV5. U vindt het script dat deze database maakt en vult hier, en het ER-diagram hier.
In dit artikel concentreer ik me op vier klassieke veelvoorkomende bugs:COUNT(*) in outer joins, double-dipping aggregaten, ON-WHERE contradictie en OUTER-INNER join contradictie. Al deze bugs houden verband met de basisprincipes van T-SQL-query's en zijn gemakkelijk te vermijden als u eenvoudige best-practices volgt.
COUNT(*) in outer joins
Onze eerste bug heeft te maken met onjuiste tellingen die zijn gerapporteerd voor lege groepen als gevolg van het gebruik van een outer join en de COUNT(*)-aggregaat. Beschouw de volgende vraag om het aantal bestellingen en de totale vracht per klant te berekenen:
GEBRUIK TSQLV5; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip SELECT custid, COUNT(*) AS aantallen, SUM(freight) AS totalfreight FROM Sales.Orders GROUP PER custid ORDER BY custid;
Deze query genereert de volgende uitvoer (afgekort):
vracht aantal totale vracht ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559,52 ... 21 7 232,75 23 5 637,94 ... 56 10 862,74 58 6 277,96 ... 87 15 822,48 88 9 194,71 89 14 1353,06 90 7 88,41 91 7 175,74 (89 rijen aangetast)
Er zijn momenteel 91 klanten aanwezig in de tabel Klanten, waarvan 89 bestellingen hebben geplaatst; daarom toont de uitvoer van deze query 89 klantgroepen en hun juiste ordertelling en totale vrachtaggregaten. Klanten met ID 22 en 57 zijn aanwezig in de tabel Klanten, maar hebben geen bestellingen geplaatst en verschijnen daarom niet in het resultaat.
Stel dat u wordt gevraagd om klanten die geen gerelateerde bestellingen hebben, in het zoekresultaat op te nemen. In een dergelijk geval is het logisch om een left outer join uit te voeren tussen klanten en bestellingen om klanten zonder bestellingen te behouden. Een typische bug bij het converteren van de bestaande oplossing naar een oplossing die de join toepast, is echter om de berekening van het aantal bestellingen op COUNT (*) te laten staan, zoals weergegeven in de volgende query (noem het Query 1):
SELECTEER C.custid, COUNT(*) AS aantallen, SUM(O.freight) AS totale vracht VAN Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid GROEP DOOR C.custid BESTELLEN DOOR C.custid;
Deze query genereert de volgende uitvoer:
vracht aantal totale vracht ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 1 NULL 23 5 637.94 ... 56 10 862.74 57 1 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rijen getroffen)
Merk op dat klanten 22 en 57 deze keer in het resultaat verschijnen, maar hun aantal bestellingen toont 1 in plaats van 0 omdat COUNT(*) rijen telt en geen bestellingen. De totale vracht wordt correct gerapporteerd omdat SUM(vracht) NULL-invoer negeert.
Het plan voor deze zoekopdracht wordt getoond in figuur 1.
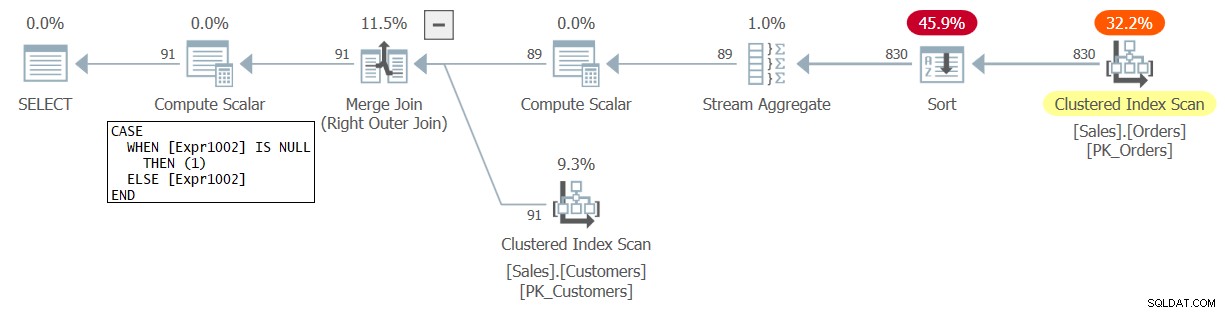 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
In dit plan vertegenwoordigt Expr1002 het aantal rijen per groep, dat als gevolg van de outer join in eerste instantie is ingesteld op NULL voor klanten zonder overeenkomende bestellingen. De Compute Scalar-operator direct onder het root-SELECT-knooppunt converteert vervolgens de NULL naar 1. Dat is het resultaat van het tellen van rijen in tegenstelling tot het tellen van bestellingen.
Om deze bug te verhelpen, wilt u de COUNT-aggregaat toepassen op een element vanaf de niet-geconserveerde kant van de outer join, en u wilt ervoor zorgen dat u een niet-NULL-kolom als invoer gebruikt. De primaire sleutelkolom zou een goede keuze zijn. Hier is de oplossingsquery (noem het Query 2) met de bug opgelost:
SELECTEER C.custid, COUNT(O.orderid) AS aantallen, SUM(O.freight) AS totale vracht FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid GROUP BY C .custid BESTELLEN DOOR C.custid;
Dit is de uitvoer van deze zoekopdracht:
vracht aantal totale vracht ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 0 NULL 23 5 637.94 ... 56 10 862.74 57 0 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rijen betrokken)
Merk op dat klanten 22 en 57 deze keer de juiste nultelling tonen.
Het plan voor deze zoekopdracht wordt getoond in figuur 2.
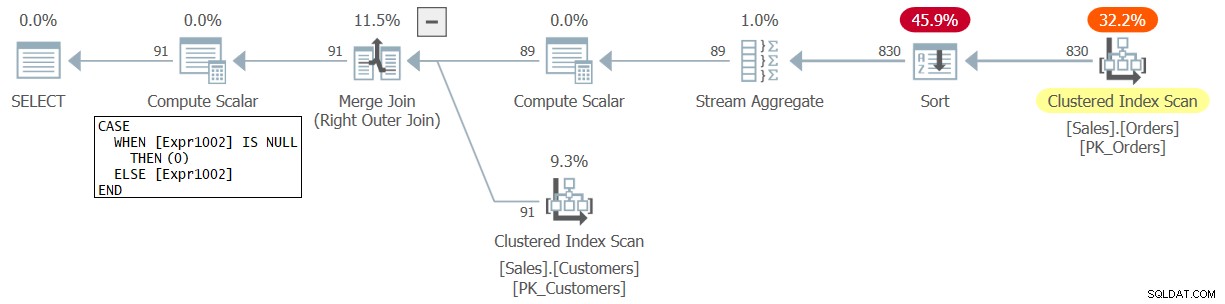 Figuur 2:Plan voor Query 2
Figuur 2:Plan voor Query 2
U kunt ook de wijziging in het plan zien, waarbij een NULL die het aantal vertegenwoordigt voor een klant zonder overeenkomende bestellingen, deze keer wordt geconverteerd naar 0 en niet naar 1.
Let bij het gebruik van joins op met het toepassen van de COUNT(*)-aggregaat. Bij het gebruik van outer joins is dit meestal een bug. U kunt het beste de COUNT-aggregaat toepassen op een niet-NULL-kolom vanaf de veelzijde van de een-op-veel-join. De primaire sleutelkolom is een goede keuze voor dit doel, aangezien deze geen NULL's toestaat. Dit kan een goede gewoonte zijn, zelfs als je inner joins gebruikt, omdat je nooit weet of je op een later moment een inner join moet veranderen in een outer als gevolg van gewijzigde vereisten.
Double-dipping aggregaten
Onze tweede bug betreft ook het mixen van joins en aggregaten, waarbij deze keer meerdere keren rekening wordt gehouden met bronwaarden. Beschouw de volgende vraag als voorbeeld:
SELECT C.custid, COUNT(O.orderid) AS aantallen, SUM(O.freight) AS totalevracht, CAST(SUM(OD.qty * OD.eenheidsprijs * (1 - OD.discount)) AS NUMERIC(12 , 2)) ALS totale waarde VAN Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid LEFT OUTER JOIN Sales.OrderDetails AS OD ON O.orderid =OD.orderid GROEP DOOR C.custid ORDER DOOR C.custid;
Deze query voegt Klanten, Orders en OrderDetails samen, groepeert de rijen op custid en wordt verondersteld om aggregaten te berekenen zoals het aantal bestellingen, de totale vracht en de totale waarde per klant. Deze query genereert de volgende uitvoer:
vracht totaal aantal vracht totaal ------ ---------- ------------- --------- 1 12 419,60 4273,00 2 10 306.59 1402.95 3 17 667.29 7023.98 4 30 1447.14 13390.65 5 52 4835.18 24927.58 ... 87 37 2611.93 15648.70 88 19 546.96 6068.20 89 40 4017.32 27363.61 90 17 262.16 3161.35 91 16 461.53 3531.95
Zie jij de bug hier?
Orderkoppen worden opgeslagen in de tabel Orders en hun respectieve orderregels worden opgeslagen in de tabel OrderDetails. Wanneer u orderkoppen samenvoegt met hun respectievelijke orderregels, wordt de koptekst herhaald in het resultaat van de samenvoeging per regel. Als gevolg hiervan geeft het aggregaat COUNT(O.orderid) onjuist het aantal orderregels weer en niet het aantal orders. Op dezelfde manier houdt de SOM(O.vracht) ten onrechte meerdere keren per order rekening met de vracht - zoveel als het aantal orderregels binnen de order. De enige juiste totaalberekening in deze query is degene die wordt gebruikt om de totale waarde te berekenen, aangezien deze wordt toegepast op attributen van de orderregels:SUM(OD.qty * OD.eenheidsprijs * (1 – OD.discount).
Om het juiste aantal bestellingen te krijgen, volstaat het om een aparte telling-aggregaat te gebruiken:COUNT(DISTINCT O.orderid). Je zou denken dat dezelfde oplossing kan worden toegepast op de berekening van de totale vracht, maar dit zou alleen maar een nieuwe bug introduceren. Dit is onze zoekopdracht met verschillende aggregaten toegepast op de maten van de orderkop:
SELECT C.custid, COUNT(DISTINCT O.orderid) AS aantallen, SUM(DISTINCT O.freight) AS totalfreight, CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC (12, 2)) ALS totale waarde VAN Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid LINKS OUTER JOIN Sales.OrderDetails AS OD ON O.orderid =OD.orderid GROUP BY C. custid BESTELLEN DOOR C.custid;
Deze query genereert de volgende uitvoer:
vracht totaal aantal vracht totaal ------ ---------- ------------- --------- 1 6 225,58 4273,00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 448.23 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 87.66 3161.35 ***** 91 7 175.74 3531. /pre>De ordertellingen zijn nu correct, maar de totale vrachtwaarden niet. Zie jij de nieuwe bug?
De nieuwe bug is ongrijpbaarder omdat hij zich alleen manifesteert wanneer dezelfde klant ten minste één geval heeft waarin meerdere bestellingen toevallig exact dezelfde vrachtwaarden hebben. In zo'n geval houdt u nu maar één keer per klant rekening met de vracht, en niet één keer per bestelling zoals u zou moeten.
Gebruik de volgende query (vereist SQL Server 2017 of hoger) om niet-onderscheiden vrachtwaarden voor dezelfde klant te identificeren:
WITH C AS ( SELECT custid, vracht, STRING_AGG(CAST(orderid AS VARCHAR(MAX)), ', ') BINNEN GROUP (ORDER BY orderid) ALS bestellingen VANAF Verkoop.Orders GROEP PER custid, vracht HAVING COUNT(* )> 1 ) SELECTEER custid, STRING_AGG(CONCAT('(freight:', freight, ', orders:', orders, ')'), ', ') als duplicaten VANUIT C GROUP BY custid;Deze query genereert de volgende uitvoer:
voogdij duplicaten ------- -------------------------------------- - 4 (vracht:23,72, bestellingen:10743, 10953) 90 (vracht:0,75, bestellingen:10615, 11005)Met deze bevindingen realiseert u zich dat de query met de bug onjuiste totale vrachtwaarden voor klanten 4 en 90 rapporteerde. De query rapporteerde juiste totale vrachtwaarden voor de rest van de klanten, aangezien hun vrachtwaarden uniek waren.
Om de bug op te lossen, moet u de berekening van aggregaten van orders en orderregels scheiden in verschillende stappen met behulp van tabeluitdrukkingen, zoals:
WITH O AS ( SELECT custid, COUNT(orderid) AS aantallen, SUM(freight) AS totale vracht FROM Sales.Orders GROUP BY custid), OD AS ( SELECT O.custid, CAST(SUM(OD.qty * OD. eenheidsprijs * (1 - OD.korting)) ALS NUMERIEK (12, 2)) ALS totale waarde VAN Verkoop.Orders ALS O INNERLIJKE JOIN Sales.OrderDetails AS OD ON O.orderid =OD.orderid GROEP DOOR O.custid) SELECT C. custid, O.numorders, O.totalfreight, OD.totalval VAN Sales.Customers AS C LINKS BUITENSTE JOIN O ON C.custid =O.custid LINKER BUITENSTE JOIN OD ON C.custid =OD.custid ORDER DOOR C.custid;Deze query genereert de volgende uitvoer:
vracht totaal aantal vracht totaal ------ ---------- ------------- --------- 1 6 225,58 4273,00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 471.95 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 88.41 3161.35 ***** 91 7 175.74 3531. /pre>Merk op dat de totale vrachtwaarden voor klanten 4 en 90 nu hoger zijn. Dit zijn de juiste cijfers.
De beste werkwijze hier is om bewust te zijn bij het samenvoegen en aggregeren van gegevens. U wilt alert zijn op dergelijke gevallen wanneer u meerdere tabellen samenvoegt en aggregaties toepast op metingen uit een tabel die geen edge- of leaf-tabel in de joins is. In een dergelijk geval moet u gewoonlijk de geaggregeerde berekeningen toepassen binnen tabeluitdrukkingen en vervolgens de tabeluitdrukkingen samenvoegen.
Dus de bug met dubbele onderdompeling van aggregaten is opgelost. Er zit echter mogelijk nog een bug in deze query. Kun je het spotten? Ik zal de details geven over zo'n mogelijke bug, zoals het vierde geval dat ik later zal behandelen onder "BUITEN-INNERLIJKE join contradictie".
ON-WHERE tegenstrijdigheid
Onze derde bug is een gevolg van het verwarren van de rollen die de ON- en WHERE-clausules zouden moeten spelen. Stel dat u een taak hebt gekregen om klanten en bestellingen die ze sinds 12 februari 2019 hebben geplaatst, te matchen, maar ook klanten die sindsdien geen bestellingen hebben geplaatst, in de output op te nemen. U probeert de taak op te lossen met behulp van de volgende query (noem het Query 3):
SELECTEER C.custid, C.companyname, O.orderid, O.orderdate FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON O.custid =C.custid WHERE O.orderdate>='20190212';Wanneer u een inner join gebruikt, spelen zowel ON als WHERE dezelfde filterrollen, en daarom maakt het niet uit hoe u de predikaten tussen deze clausules organiseert. Wanneer u echter een outer join gebruikt, zoals in ons geval, hebben deze clausules verschillende betekenissen.
De ON-clausule speelt een overeenkomende rol, wat betekent dat alle rijen van de bewaarde kant van de join (klanten in ons geval) worden geretourneerd. Degenen die overeenkomsten hebben op basis van het ON-predikaat zijn verbonden met hun overeenkomsten en worden daarom per match herhaald. Degenen die geen overeenkomsten hebben, worden geretourneerd met NULL's als tijdelijke aanduidingen in de attributen van de niet-bewaarde kant.
Omgekeerd speelt de WHERE-component een eenvoudigere filterrol - altijd. Dit betekent dat rijen waarvoor het filterpredikaat true is, worden geretourneerd en dat de rest wordt weggegooid. Als gevolg hiervan kunnen sommige rijen van de bewaarde kant van de join helemaal worden verwijderd.
Onthoud dat attributen van de niet-geconserveerde kant van de outer join (Orders in ons geval) zijn gemarkeerd als NULL's voor buitenste rijen (niet-overeenkomende). Telkens wanneer u een filter toepast waarbij een element van de niet-geconserveerde kant van de join betrokken is, wordt het filterpredikaat voor alle buitenste rijen als onbekend geëvalueerd, wat resulteert in de verwijdering ervan. Dit is in overeenstemming met de driewaardige predikaatlogica die SQL volgt. In feite wordt de join daardoor een inner join. De enige uitzondering op deze regel is wanneer u specifiek naar een NULL zoekt in een element van de niet-geconserveerde kant om niet-overeenkomende te identificeren (element IS NULL).
Onze zoekopdracht met fouten genereert de volgende uitvoer:
custid firmanaam orderid orderdatum ------- --------------- -------- ---------- 1 Klant NRZBB 11011 2019-04-09 1 Klant NRZBB 10952 2019-03-16 2 Klant MLTDN 10926 2019-03-04 4 Klant HFBZG 11016 2019-04-10 4 Klant HFBZG 10953 2019-03-16 4 Klant HFBZG 10920 2019-03- 03 5 Klant HGVLZ 10924 2019-03-04 6 Klant XHXJV 11058 2019-04-29 6 Klant XHXJV 10956 2019-03-17 8 Klant QUHWH 10970 2019-03-24 ... 20 Klant THHDP 10979 2019-03-26 20 Klant THHDP 10968 2019-03-23 20 Klant THHDP 10895 2019-02-18 24 Klant CYZTN 11050 2019-04-27 24 Klant CYZTN 11001 2019-04-06 24 Klant CYZTN 10993 2019-04-01 ... (195 rijen getroffen)De gewenste uitvoer zou 213 rijen moeten hebben, waaronder 195 rijen die bestellingen vertegenwoordigen die sinds 12 februari 2019 zijn geplaatst, en 18 extra rijen die klanten vertegenwoordigen die sindsdien geen bestellingen hebben geplaatst. Zoals u kunt zien, omvat de werkelijke uitvoer niet de klanten die sinds de opgegeven datum geen bestellingen hebben geplaatst.
Het plan voor deze zoekopdracht wordt getoond in figuur 3.
Figuur 3:Plan voor Query 3
Merk op dat de optimizer de tegenstrijdigheid heeft gedetecteerd en de outer join intern heeft geconverteerd naar een inner join. Dat is goed om te zien, maar tegelijkertijd een duidelijke indicatie dat er een bug in de query zit.
Ik heb gevallen gezien waarin mensen probeerden de bug te repareren door het predikaat OR O.orderid IS NULL toe te voegen aan de WHERE-clausule, zoals:
SELECTEER C.custid, C.companyname, O.orderid, O.orderdate FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON O.custid =C.custid WHERE O.orderdate>='20190212' OF O.orderid IS NULL;Het enige overeenkomende predikaat is het predikaat dat de klant-ID's van beide kanten vergelijkt. Dus de join zelf retourneert klanten die bestellingen in het algemeen hebben geplaatst, samen met hun overeenkomende bestellingen, evenals klanten die helemaal geen bestellingen hebben geplaatst, met NULL's in hun bestelkenmerken. Vervolgens filtert de filtering de klanten die bestellingen hebben geplaatst sinds de opgegeven datum, evenals klanten die helemaal geen bestellingen hebben geplaatst (klanten 22 en 57). De zoekopdracht mist klanten die een aantal bestellingen hebben geplaatst, maar niet sinds de opgegeven datum!
Deze query genereert de volgende uitvoer:
custid firmanaam orderid orderdatum ------- --------------- -------- ---------- 1 Klant NRZBB 11011 2019-04-09 1 Klant NRZBB 10952 2019-03-16 2 Klant MLTDN 10926 2019-03-04 4 Klant HFBZG 11016 2019-04-10 4 Klant HFBZG 10953 2019-03-16 4 Klant HFBZG 10920 2019-03- 03 5 Klant HGVLZ 10924 2019-03-04 6 Klant XHXJV 11058 2019-04-29 6 Klant XHXJV 10956 2019-03-17 8 Klant QUHWH 10970 2019-03-24 ... 20 Klant THHDP 10979 2019-03-26 20 Klant THHDP 10968 2019-03-23 20 Klant THHDP 10895 2019-02-18 22 Klant DTDMN NULL NULL 24 Klant CYZTN 11050 2019-04-27 24 Klant CYZTN 11001 2019-04-06 24 Klant CYZTN 10993 2019-04-01 . .. (197 rijen aangetast)Om de bug correct op te lossen, moet u zowel het predikaat dat de klant-ID's van beide kanten vergelijkt, als het predikaat met de besteldatum als overeenkomende predikaten beschouwen. Om dit te bereiken, moeten beide worden gespecificeerd in de ON-component, zoals zo (noem deze Query 4):
SELECT C.custid, C.companyname, O.orderid, O.orderdate FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON O.custid =C.custid AND O.orderdate>='20190212';Deze query genereert de volgende uitvoer:
custid firmanaam orderid orderdatum ------- --------------- -------- ---------- 1 Klant NRZBB 11011 2019-04-09 1 Klant NRZBB 10952 2019-03-16 2 Klant MLTDN 10926 2019-03-04 3 Klant KBUDE NULL NULL 4 Klant HFBZG 11016 2019-04-10 4 Klant HFBZG 10953 2019-03-16 4 Klant HFBZG 10920 2019-03-03 5 Klant HGVLZ 10924 2019-03-04 6 Klant XHXJV 11058 2019-04-29 6 Klant XHXJV 10956 2019-03-17 7 Klant QXVLA NULL NULL 8 Klant QUHWH 10970 2019-03-24 ... 20 Klant THHDP 10979 2019-03-26 20 Klant THHDP 10968 2019-03-23 20 Klant THHDP 10895 2019-02-18 21 Klant KIDPX NULL NULL 22 Klant DTDMN NULL NULL 23 Klant WVFAF NULL NULL 24 Klant CYZTN 11050 2019-04- 27 24 Klant CYZTN 11001 2019-04-06 24 Klant CYZTN 10993 2019-04-01 ... (213 rijen getroffen)Het plan voor deze zoekopdracht wordt getoond in figuur 4.
Figuur 4:Plan voor Query 4
Zoals je kunt zien, behandelde de optimizer de join deze keer als een outer join.
Dit is een heel eenvoudige vraag die ik ter illustratie heb gebruikt. Met veel uitgebreidere en complexere zoekopdrachten kunnen zelfs ervaren ontwikkelaars het moeilijk vinden om uit te zoeken of een predikaat in de ON-clausule of in de WHERE-clausule thuishoort. Wat het voor mij gemakkelijk maakt, is om me gewoon af te vragen of het predikaat een matchend of een filterend predikaat is. Als het eerste het geval is, hoort het in de ON-clausule; als het laatste het geval is, hoort het in de WHERE-clausule.
OUTER-INNER join contradictie
Onze vierde en laatste bug is in zekere zin een variatie op de derde bug. Het gebeurt meestal in query's met meerdere joins waarbij u join-typen combineert. Stel bijvoorbeeld dat u de tabellen Klanten, Orders, OrderDetails, Producten en Leveranciers moet samenvoegen om klant-leverancierparen te identificeren die gezamenlijke activiteit hadden. Je schrijft de volgende vraag (noem het vraag 5):
SELECT DISTINCT C.custid, C.companyname AS klant, S.supplierid, S.companyname AS leverancier FROM Sales.Customers AS C INNER JOIN Sales.Orders AS O ON O.custid =C.custid INNER JOIN Sales.OrderDetails AS OD ON OD.orderid =O.orderid INNER JOIN Production.Products AS P ON P.productid =OD.productid INNER JOIN Production.Suppliers AS S ON S.supplierid =P.supplierid;Deze query genereert de volgende uitvoer met 1.236 rijen:
custid klant leverancier-id leverancier ------- --------------- ----------- ---------- ----- 1 Klant NRZBB 1 Leverancier SWRXU 1 Klant NRZBB 3 Leverancier STUAZ 1 Klant NRZBB 7 Leverancier GQRCV ... 21 Klant KIDPX 24 Leverancier JNNES 21 Klant KIDPX 25 Leverancier ERVYZ 21 Klant KIDPX 28 Leverancier OAVQT 23 Klant WVFAF 3 Leverancier STUAZ 23 Klant WVFAF 7 Leverancier GQRCV 23 Klant WVFAF 8 Leverancier BWGYE ... 56 Klant QNIVZ 26 Leverancier ZWZDM 56 Klant QNIVZ 28 Leverancier OAVQT 56 Klant QNIVZ 29 Leverancier OGLRK 58 Klant AHXHT 1 Leverancier SWRXU 58 Klant AHXHT 5 Leverancier EQPNC 58 Klant AHXHT 6 Leverancier QWUSF ... (1236 rijen aangetast)Het plan voor deze zoekopdracht wordt getoond in figuur 5.
Figuur 5:Plan voor Query 5
Alle joins in het plan worden zoals je zou verwachten als inner joins verwerkt.
U kunt in het plan ook zien dat de optimizer join-ordering-optimalisatie heeft toegepast. Met inner joins weet de optimizer dat het de fysieke volgorde van de joins op elke gewenste manier kan herschikken, terwijl de betekenis van de oorspronkelijke query behouden blijft, dus het heeft veel flexibiliteit. Hier resulteerde de op kosten gebaseerde optimalisatie in de volgorde:join(Customers, join(Orders, join(join(Suppliers, Products), OrderDetails))).
Stel dat u een vereiste krijgt om de zoekopdracht te wijzigen zodat deze ook klanten omvat die geen bestellingen hebben geplaatst. Bedenk dat we momenteel twee van dergelijke klanten hebben (met ID's 22 en 57), dus het gewenste resultaat zou 1.238 rijen moeten hebben. Een veelvoorkomende fout in zo'n geval is om de inner join tussen klanten en bestellingen te veranderen in een left outer join, maar de rest van de joins als inner joins te laten, zoals zo:
SELECT DISTINCT C.custid, C.companyname AS klant, S.supplierid, S.companyname AS leverancier VAN Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON O.custid =C.custid INNER JOIN Sales. OrderDetails AS OD ON OD.orderid =O.orderid INNER JOIN Production.Products AS P ON P.productid =OD.productid INNER JOIN Production.Suppliers AS S ON S.supplierid =P.supplierid;Wanneer een linker outer join vervolgens wordt gevolgd door inner of right outer joins, en het join-predikaat iets van de niet-geconserveerde kant van de linker outer join vergelijkt met een ander element, is de uitkomst van het predikaat de logische waarde onbekend, en de oorspronkelijke outer join rijen worden weggegooid. De linker outer join wordt in feite een inner join.
Als gevolg hiervan genereert deze query dezelfde uitvoer als voor Query 5, waarbij slechts 1.236 rijen worden geretourneerd. Ook hier detecteert de optimizer de tegenstrijdigheid en converteert de outer join naar een inner join, waarbij hetzelfde plan wordt gegenereerd als eerder in figuur 5.
Een veelvoorkomende poging om de bug op te lossen is om alle joins naar de buitenste join te laten gaan, zoals:
SELECT DISTINCT C.custid, C.companyname AS klant, S.supplierid, S.companyname AS leverancier VAN Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON O.custid =C.custid LEFT OUTER JOIN Sales .OrderDetails AS OD ON OD.orderid =O.orderid LEFT OUTER JOIN Production.Products AS P ON P.productid =OD.productid LEFT OUTER JOIN Production.Suppliers AS S ON S.supplierid =P.supplierid;Deze query genereert de volgende uitvoer, inclusief klanten 22 en 57:
custid klant leverancier-id leverancier ------- --------------- ----------- ---------- ----- 1 Klant NRZBB 1 Leverancier SWRXU 1 Klant NRZBB 3 Leverancier STUAZ 1 Klant NRZBB 7 Leverancier GQRCV ... 21 Klant KIDPX 24 Leverancier JNNES 21 Klant KIDPX 25 Leverancier ERVYZ 21 Klant KIDPX 28 Leverancier OAVQT 22 Klant DTDMN NULL NULL 23 Klant WVFAF 3 Leverancier STUAZ 23 Klant WVFAF 7 Leverancier GQRCV 23 Klant WVFAF 8 Leverancier BWGYE ... 56 Klant QNIVZ 26 Leverancier ZWZDM 56 Klant QNIVZ 28 Leverancier OAVQT 56 Klant QNIVZ 29 Leverancier OGLRK 57 Klant WVAXS NULL NULL 58 Klant AHXHT 1 Leverancier SWRXU 58 Klant AHXHT 5 Leverancier EQPNC 58 Klant AHXHT 6 Leverancier QWUSF ... (1238 rijen affe ctd)Er zijn echter twee problemen met deze oplossing. Stel dat u naast Klanten ook rijen in een andere tabel in de query zou kunnen hebben zonder overeenkomende rijen in een volgende tabel, en dat u in zo'n geval die buitenste rijen niet wilt behouden. Wat als het in uw omgeving bijvoorbeeld is toegestaan om een koptekst voor een order aan te maken, en deze op een later moment te vullen met orderregels. Stel dat in een dergelijk geval de query dergelijke lege orderheaders niet zou moeten retourneren. Toch zou de zoekopdracht klanten zonder bestellingen moeten retourneren. Aangezien de join tussen Orders en OrderDetails een left outer join is, retourneert deze query dergelijke lege bestellingen, ook al zou dit niet moeten.
Een ander probleem is dat wanneer u outer joins gebruikt, u meer beperkingen oplegt aan de optimizer in termen van de herschikkingen die het mag onderzoeken als onderdeel van de optimalisatie van de join-ordering. De optimizer kan de join A LEFT OUTER JOIN B herschikken naar B RIGHT OUTER JOIN A, maar dat is vrijwel de enige herschikking die het mag verkennen. Met inner joins kan het optimalisatieprogramma ook tabellen herschikken die verder gaan dan alleen het omdraaien van zijden, het kan bijvoorbeeld join(join(join(join(A, B), C), D), E)))) herschikken naar join(A, join(B, join(join(E, D), C))) zoals eerder getoond in figuur 5.
Als je erover nadenkt, is wat je echt wilt, links-join klanten met het resultaat van de inner joins tussen de rest van de tafels. Uiteraard kunt u dit bereiken met tabeluitdrukkingen. T-SQL ondersteunt echter nog een andere truc. Wat echt de volgorde van logische joins bepaalt, is niet precies de volgorde van de tabellen in de FROM-clausule, maar de volgorde van de ON-clausules. Om ervoor te zorgen dat de query geldig is, moet elke ON-clausule direct onder de twee eenheden worden weergegeven waaraan deze wordt toegevoegd. Dus om de verbinding tussen klanten en de rest als laatste te beschouwen, hoeft u alleen maar de ON-clausule te verplaatsen die klanten verbindt en de rest om als laatste te verschijnen, zoals zo:
SELECT DISTINCT C.custid, C.companyname AS klant, S.supplierid, S.companyname AS leverancier VAN Sales.Customers AS C LINKS BUITEN JOIN Sales.Orders AS O -- verplaatsen van hier ------- ---------------- INNER JOIN Sales.OrderDetails AS OD -- ON OD.orderid =O.orderid -- INNER JOIN Production.Products AS P -- ON P.productid =OD .productid -- INNER JOIN Production.Suppliers AS S -- ON S.supplierid =P.supplierid -- ON O.custid =C.custid; -- <-- naar hier --De logische volgorde van joins is nu:leftjoin(Customers, join(join(join(Orders, OrderDetails), Products), Suppliers)). Deze keer behoudt u klanten die geen bestellingen hebben geplaatst, maar u behoudt geen orderkoppen die geen overeenkomende orderregels hebben. Ook geeft u de optimizer volledige flexibiliteit bij het bestellen van joins in de interne joins tussen bestellingen, orderdetails, producten en leveranciers.
Het enige nadeel van deze syntaxis is de leesbaarheid. Het goede nieuws is dat dit eenvoudig kan worden opgelost door haakjes te gebruiken, zoals (noem dit Query 6):
SELECT DISTINCT C.custid, C.companyname AS klant, S.supplierid, S.companyname AS leverancier FROM Sales.Customers AS C LEFT OUTER JOIN ( Sales.Orders AS O INNER JOIN Sales.OrderDetails AS OD ON OD.orderid =O.orderid INNER JOIN Production.Products AS P ON P.productid =OD.productid INNER JOIN Production.Suppliers AS S ON S.supplierid =P.supplierid ) ON O.custid =C.custid;Verwar het gebruik van haakjes hier niet met een afgeleide tabel. Dit is geen afgeleide tabel, maar slechts een manier om enkele tabeloperators te scheiden in hun eigen eenheid, voor de duidelijkheid. De taal heeft deze haakjes niet echt nodig, maar ze worden sterk aanbevolen voor de leesbaarheid.
Het plan voor deze query wordt getoond in figuur 6.
Figuur 6:Plan voor Query 6
Merk op dat deze keer de join tussen klanten en de rest wordt verwerkt als een outer join en dat de optimizer de optimalisatie van join-ordering heeft toegepast.
Conclusie
In dit artikel heb ik vier klassieke bugs behandeld die te maken hebben met joins. Bij het gebruik van outer joins resulteert het berekenen van de COUNT(*)-aggregaat meestal in een bug. Het beste is om de aggregatie toe te passen op een niet-NULL-kolom vanaf de niet-bewaarde kant van de join.
When joining multiple tables and involving aggregate calculations, if you apply the aggregates to a nonleaf table in the joins, it’s usually a bug resulting in double-dipping aggregates. The best practice is then to apply the aggregates within table expressions and joining the table expressions.
It’s common to confuse the meanings of the ON and WHERE clauses. With inner joins, they’re both filters, so it doesn’t really matter how you organize your predicates within these clauses. However, with outer joins the ON clause serves a matching role whereas the WHERE clause serves a filtering role. Understanding this helps you figure out how to organize your predicates within these clauses.
In multi-join queries, a left outer join that is subsequently followed by an inner join, or a right outer join, where you compare an element from the nonpreserved side of the join with others (other than the IS NULL test), the outer rows of the left outer join are discarded. To avoid this bug, you want to apply the left outer join last, and this can be achieved by shifting the ON clause that connects the preserved side of this join with the rest to appear last. Use parentheses for clarity even though they are not required.