Dit bericht biedt nieuwe informatie over de randvoorwaarden voor minimaal gelogde bulklading bij gebruik van INSERT...SELECT in geïndexeerde tabellen .
De interne faciliteit die deze gevallen mogelijk maakt, heet FastLoadContext . Het kan worden geactiveerd van SQL Server 2008 tot en met 2014 met behulp van gedocumenteerde traceringsvlag 610. Vanaf SQL Server 2016, FastLoadContext is standaard ingeschakeld; de traceervlag is niet vereist.
Zonder FastLoadContext , de enige index-inserts die minimaal gelogd kunnen worden zijn die in een leeg geclusterde index zonder secundaire indexen, zoals behandeld in deel twee van deze serie. De minimale logboekregistratie voorwaarden voor niet-geïndexeerde heaptabellen werden behandeld in deel één.
Zie voor meer achtergrondinformatie de Gids voor het laden van gegevensprestaties en het Tiger Team opmerkingen over de gedragsveranderingen voor SQL Server 2016.
Snel laadcontext
Ter herinnering:de RowsetBulk faciliteit (bedekt in deel 1 en 2) maakt minimaal gelogd bulklading voor:
- Lege en niet-lege hoop tabellen met:
- Tafelvergrendeling; en
- Geen secundaire indexen.
- Geclusterde tabellen leegmaken , met:
- Tafelvergrendeling; en
- Geen secundaire indexen; en
DMLRequestSort=trueop de Geclusterde Index Insert operator.
De FastLoadContext codepad voegt ondersteuning toe voor minimaal gelogde en gelijktijdig bulklading op:
- Leeg en niet-leeg geclusterd b-tree indexen.
- Leeg en niet-leeg niet-geclusterd b-tree indexen onderhouden door een dedicated Index invoegen planoperator.
De FastLoadContext vereist ook DMLRequestSort=true in alle gevallen op de overeenkomstige planoperator.
Je hebt misschien een overlap opgemerkt tussen RowsetBulk en FastLoadContext voor lege geclusterde tabellen zonder secundaire indexen. Een TABLOCK hint is niet vereist met FastLoadContext , maar het is niet verplicht om afwezig te zijn een van beide. Dientengevolge, een geschikte invoeging met TABLOCK komt mogelijk nog steeds in aanmerking voor minimale logboekregistratie via FastLoadContext als het niet de gedetailleerde RowsetBulk testen.
FastLoadContext kan worden uitgeschakeld op SQL Server 2016 met behulp van gedocumenteerde traceringsvlag 692. Het foutopsporingskanaal Extended Event fastloadcontext_enabled kan worden gebruikt om FastLoadContext te controleren gebruik per indexpartitie (rijenset). Deze gebeurtenis wordt niet geactiveerd voor RowsetBulk laadt.
Gemengde logging
Een enkele INSERT...SELECT instructie met behulp van FastLoadContext mag volledig inloggen enkele rijen tijdens minimaal loggen anderen.
Rijen worden een voor een ingevoegd door de Index Insert operator en volledig ingelogd in de volgende gevallen:
- Alle rijen toegevoegd aan de eerste indexpagina, als de index leeg was aan het begin van de operatie.
- Rijen toegevoegd aan bestaande indexpagina's.
- Rijen verplaatst tussen pagina's door een paginasplitsing.
Anders worden rijen uit de bestelde invoegstroom toegevoegd aan een gloednieuwe pagina met behulp van een geoptimaliseerde en minimaal gelogde code pad. Zodra er zoveel mogelijk rijen naar de nieuwe pagina zijn geschreven, wordt deze direct gekoppeld aan de bestaande doelindexstructuur.
De nieuw toegevoegde pagina zal niet noodzakelijk vol zijn (hoewel dat natuurlijk het ideale geval is) omdat SQL Server moet oppassen dat er geen rijen worden toegevoegd aan de nieuwe pagina die logischerwijs thuishoren op een bestaande indexpagina. De nieuwe pagina wordt als een eenheid in de index 'genaaid', dus we kunnen geen rijen op de nieuwe pagina hebben die ergens anders thuishoren. Dit is vooral een probleem bij het toevoegen van rijen binnen het bestaande sleutelbereik van de index, in plaats van vóór het begin of na het einde van het bestaande indexsleutelbereik.
Het is nog mogelijk om nieuwe pagina's toe te voegen binnen het bestaande indexsleutelbereik, maar de nieuwe rijen moeten hoger sorteren dan de hoogste sleutel op de vorige bestaande indexpagina en sorteer lager dan de laagste sleutel op de volgende bestaande indexpagina. Voor de beste kans op minimale logboekregistratie zorg er in deze omstandigheden voor dat de ingevoegde rijen de bestaande rijen niet zo ver mogelijk overlappen.
DMLRequestSort-voorwaarden
Onthoud dat FastLoadContext kan alleen worden geactiveerd als DMLRequestSort is ingesteld op waar voor de corresponderende Index Insert operator in het uitvoeringsplan.
Er zijn twee hoofdcodepaden die DMLRequestSort . kunnen instellen tot waar voor index-inserts. Beide pad retourneren waar is voldoende.
1. FOptimizeInsert
De sqllang!CUpdUtil::FOptimizeInsert code vereist:
- Meer dan 250 rijen geschat in te voegen; en
- Meer dan 2 pagina's geschat gegevensgrootte invoegen; en
- De doelindex moet minder dan 3 bladpagina's hebben .
Deze voorwaarden zijn hetzelfde als RowsetBulk op een lege geclusterde index, met een aanvullende vereiste voor niet meer dan twee pagina's op indexbladniveau. Let goed op dat dit verwijst naar de grootte van de bestaande index voor de invoeging, niet de geschatte grootte van de toe te voegen gegevens.
Het onderstaande script is een aanpassing van de demo die in eerdere delen van deze serie is gebruikt. Het toont minimale logboekregistratie wanneer minder dan drie indexpagina's voor . zijn ingevuld de test INSERT...SELECT loopt. Het testtabelschema is zodanig dat 130 rijen op een enkele 8KB-pagina passen wanneer rijversiebeheer voor de database is uitgeschakeld. De vermenigvuldiger in de eerste TOP clausule kan worden gewijzigd om het aantal bestaande indexpagina's te bepalen voor de test INSERT...SELECT wordt uitgevoerd:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (3 * 130) -- Change the 3 here
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
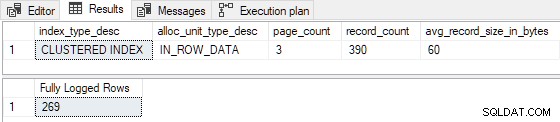
GO Wanneer de geclusterde index vooraf is geladen met 3 pagina's , de testbijlage is volledig geregistreerd (transactielogdetailrecords weggelaten voor de beknoptheid):
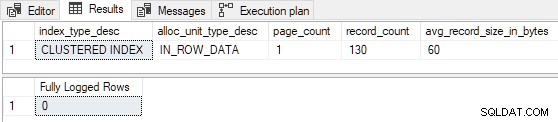
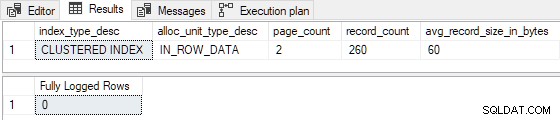
Wanneer de tabel vooraf is geladen met slechts 1 of 2 pagina's , de testbijlage is minimaal gelogd :
Wanneer de tabel niet vooraf geladen is met alle pagina's is de test gelijk aan het uitvoeren van de lege geclusterde tabeldemo uit deel twee, maar zonder de TABLOCK hint:
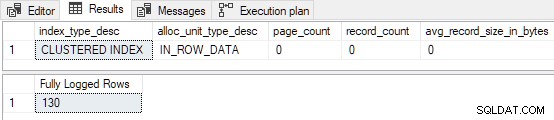
De eerste 130 rijen zijn volledig ingelogd . Dit komt omdat de index leeg was voordat we begonnen en er 130 rijen op de eerste pagina passen. Onthoud dat de eerste pagina altijd volledig is geregistreerd wanneer FastLoadContext wordt gebruikt en de index was vooraf leeg. De overige 139 rijen worden ingevoegd met minimale logboekregistratie .
Als een TABLOCK hint is toegevoegd aan de invoeging, alle pagina's worden minimaal gelogd (inclusief de eerste), aangezien de lege geclusterde indexlading nu in aanmerking komt voor de RowsetBulk mechanisme (ten koste van het nemen van een Sch-M slot).
2. FDemandRowsSortedForPerformance
Als de FOptimizeInsert tests mislukken, DMLRequestSort kan nog steeds zijn ingesteld op true door een tweede reeks tests in de sqllang!CUpdUtil::FDemandRowsSortedForPerformance code. Deze voorwaarden zijn iets ingewikkelder, dus het is handig om enkele parameters te definiëren:
P– aantal bestaande pagina's op bladniveau in de doelindex .I– geschat aantal rijen om in te voegen.R=P/I(doelpagina's per ingevoegde rij).T– aantal doelpartities (1 voor niet-gepartitioneerd).
De logica om de waarde van DMLRequestSort te bepalen is dan:
- Als
P <= 16return false , anders :- Als
R < 8:- Als
P > 524retourneer true , anders onwaar .
- Als
- If
R >= 8:- Als
T > 1enI > 250retourneer true , anders onwaar .
- Als
- Als
De bovenstaande tests worden geëvalueerd door de queryprocessor tijdens het samenstellen van het plan. Er is een laatste voorwaarde geëvalueerd door storage engine code (IndexDataSetSession::WakeUpInternal ) bij uitvoeringstijd:
DMLRequestSortis momenteel waar; enI >= 100.
We zullen al deze logica nu opsplitsen in hanteerbare stukjes.
Meer dan 16 bestaande doelpagina's
De eerste test P <= 16 betekent dat indexen met minder dan 17 bestaande leaf-pagina's niet in aanmerking komen voor FastLoadContext via dit codepad. Om op dit punt absoluut duidelijk te zijn:P is het aantal pagina's op leaf-niveau in de doelindex voor de INSERT...SELECT wordt uitgevoerd.
Om dit deel van de logica te demonstreren, laden we de geclusterde testtabel vooraf met 16 pagina's Van de gegevens. Dit heeft twee belangrijke effecten (onthoud dat beide codepaden false moeten retourneren om te eindigen met een false waarde voor DMLRequestSort ):
- Het zorgt ervoor dat de vorige
FOptimizeInserttest mislukt , omdat niet aan de derde voorwaarde is voldaan (P < 3). - De
P <= 16voorwaarde inFDemandRowsSortedForPerformancezal ook niet worden voldaan.
We verwachten daarom FastLoadContext niet te worden ingeschakeld. Het aangepaste demoscript is:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (16 * 130) -- 16 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; Alle 269 rijen zijn volledig ingelogd zoals voorspeld:
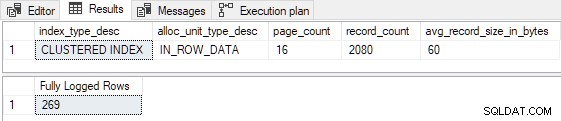
Merk op dat het niet uitmaakt hoe hoog we het aantal nieuwe rijen instellen dat moet worden ingevoegd, het bovenstaande script zal nooit produceer minimale logboekregistratie vanwege de P <= 16 test (en P < 3 test in FOptimizeInsert ).
Als u ervoor kiest om de demo zelf uit te voeren met een groter aantal rijen, plaats dan commentaar op de sectie die individuele transactielogboekrecords toont, anders wacht u erg lang en kan SSMS crashen. (Om eerlijk te zijn, zou het dat toch kunnen doen, maar waarom zou je het risico vergroten.)
Ratio pagina's per ingevoegde rij
Als er 17 of meer . zijn bladerpagina's in de bestaande index, de vorige P <= 16 test zal niet mislukken. Het volgende deel van de logica behandelt de verhouding van bestaande pagina's naar nieuw ingevoegde rijen . Dit moet ook slagen om minimale logboekregistratie te bereiken . Ter herinnering, de relevante voorwaarden zijn:
- Verhouding
R=P/I. - Als
R < 8:- Als
P > 524retourneer true , anders onwaar .
- Als
We moeten ook de laatste opslagengine-test voor ten minste 100 rijen onthouden:
I >= 100.
Die voorwaarden een beetje reorganiseren, allemaal van het volgende moet waar zijn:
P > 524(bestaande indexpagina's)I >= 100(geschatte ingevoegde rijen)P / I < 8(verhoudingR)
Er zijn meerdere manieren om tegelijkertijd aan die drie voorwaarden te voldoen. Laten we de minimaal mogelijke waarden kiezen voor P (525) en I (100) een R . geven waarde van (525 / 100) =5,25. Dit voldoet aan de (R < 8 test), dus we verwachten dat deze combinatie resulteert in minimale logging :
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (525 * 130) -- 525 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (100)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
De 100-rij INSERT...SELECT is inderdaad minimaal ingelogd :
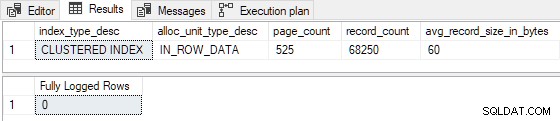
Het verminderen van de geschatte rijen ingevoegd tot 99 (brekend I >= 100 ), en/of het aantal bestaande indexpagina's verminderen tot 524 (waardoor P > 524 wordt verbroken ) resulteert in volledige logboekregistratie . We kunnen ook wijzigingen aanbrengen zodat R is niet meer dan 8 om volledige logboekregistratie te produceren . Bijvoorbeeld:P = 1000 . instellen en I = 125 geeft R = 8 , met de volgende resultaten:
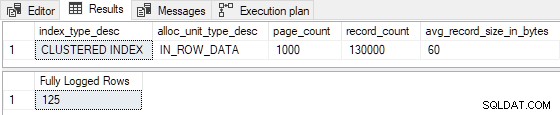
De 125 ingevoegde rijen waren volledig geregistreerd zoals verwacht. (Dit is niet te wijten aan het loggen van de eerste pagina, aangezien de index vooraf niet leeg was.)
Paginaverhouding voor gepartitioneerde indexen
Als alle voorgaande tests mislukken, vereist de enige resterende test R >= 8 en kan alleen tevreden zijn als het aantal partities (T ) groter is dan 1 en er zijn meer dan 250 geschatte ingevoegde rijen (I ). Terugroepen:
- If
R >= 8:- Als
T > 1enI > 250retourneer true , anders onwaar .
- Als
Eén subtiliteit:voor gepartitioneerd indexen, geldt de regel die zegt dat alle rijen op de eerste pagina volledig zijn geregistreerd (voor een aanvankelijk lege index) per partitie . Voor een object met 15.000 partities betekent dat 15.000 volledig gelogde 'eerste' pagina's.
Samenvatting en laatste gedachten
De formules en de volgorde van evaluatie die in de hoofdtekst worden beschreven, zijn gebaseerd op code-inspectie met behulp van een debugger. Ze werden gepresenteerd in een vorm die nauw aansluit bij de timing en volgorde die in de echte code worden gebruikt.
Het is mogelijk om die voorwaarden een beetje te herschikken en te vereenvoudigen, om een beknopter overzicht te krijgen van de praktische vereisten voor minimale logging bij het invoegen in een b-tree met INSERT...SELECT . De verfijnde uitdrukkingen hieronder gebruiken de volgende drie parameters:
P=aantal bestaande index pagina's op bladniveau.I=geschat aantal rijen om in te voegen.S=geschat gegevensgrootte in 8KB pagina's invoegen.
Bulklading Rowset
- Gebruikt
sqlmin!RowsetBulk. - Vereist een lege geclusterd indexdoel met
TABLOCK(of gelijkwaardig). - Vereist
DMLRequestSort = trueop de Geclusterde Index Insert operator. DMLRequestSortis ingesteld optruealsI > 250enS > 2.- Alle ingevoegde rijen zijn minimaal gelogd .
- Een
Sch-Mlock voorkomt gelijktijdige toegang tot de tafel.
Snel laadcontext
- Gebruikt
sqlmin!FastLoadContext. - Schakel minimaal gelogd in voegt toe aan b-tree indexen:
- Geclusterd of niet-geclusterd.
- Met of zonder tafelvergrendeling.
- Doelindex leeg of niet.
- Vereist
DMLRequestSort = trueop de bijbehorende Indexbijlage planoperator. - Alleen rijen geschreven naar gloednieuwe nieuwe pagina's worden in bulk geladen en minimaal geregistreerd .
- De eerste pagina van een eerder lege index partitie is altijd volledig ingelogd .
- Absoluut minimum van
I >= 100. - Vereist traceervlag 610 voor SQL Server 2016.
- Standaard beschikbaar vanaf SQL Server 2016 (tracevlag 692 is uitgeschakeld).
DMLRequestSort is ingesteld op true voor:
- Elke index (gepartitioneerd of niet) als:
I > 250enP < 3enS > 2; ofI >= 100enP > 524enP < I * 8
Alleen voor gepartitioneerde indexen (met> 1 partitie), DMLRequestSort is ook ingesteld op true als:
I > 250enP > 16enP >= I * 8
Er zijn een paar interessante gevallen die voortkomen uit die FastLoadContext voorwaarden:
- Alle wordt ingevoegd in een niet-gepartitioneerd index met tussen 3 en 524 (inclusief) bestaande leaf-pagina's worden volledig gelogd ongeacht het aantal en de totale grootte van de toegevoegde rijen. Dit is vooral van invloed op grote inzetstukken tot kleine (maar niet lege) tafels.
- Alle wordt ingevoegd in een gepartitioneerd index met tussen 3 en 16 bestaande pagina's worden volledig ingelogd .
- Grote inzetstukken te groot niet-gepartitioneerd indexen mogen niet minimaal worden gelogd vanwege de ongelijkheid
P < I * 8. WanneerPis groot, een overeenkomstig grote geschatte aantal ingevoegde rijen (I) Is benodigd. Een index met 8 miljoen pagina's kan bijvoorbeeld geen ondersteuning bieden voor minimale logging bij het invoegen van 1 miljoen rijen of minder.
Niet-geclusterde indexen
Dezelfde overwegingen en berekeningen die worden toegepast op geclusterde indexen in de demo's zijn van toepassing op niet-geclusterde b-tree indexen ook, zolang de index wordt onderhouden door een dedicated plan operator (een brede , of per-index plan). Niet-geclusterde indexen die worden onderhouden door een basistabeloperator (bijv. Geclusterde index invoegen ) komen niet in aanmerking voor FastLoadContext .
Merk op dat de formuleparameters opnieuw moeten worden geëvalueerd voor elke niet-geclusterde indexoperator — berekende rijgrootte, aantal bestaande indexpagina's en schatting van kardinaliteit.
Algemene opmerkingen
Pas op voor lage kardinaliteitsschattingen bij de Indexbijlage operator, aangezien deze van invloed zijn op de I en S parameters. Als een drempel niet wordt bereikt vanwege een kardinaliteitsschattingsfout, wordt de invoeging volledig geregistreerd .
Onthoud dat DMLRequestSort is gecacht met het abonnement — het wordt niet geëvalueerd bij elke uitvoering van een hergebruikt plan. Dit kan een vorm van het bekende parametergevoeligheidsprobleem introduceren (ook bekend als "parameter sniffing").
De waarde van P (indexbladpagina's) is niet vernieuwd aan het begin van elke uitspraak. De huidige implementatie slaat de waarde op voor de hele batch . Dit kan onverwachte bijwerkingen hebben. Bijvoorbeeld een TRUNCATE TABLE in dezelfde batch als een INSERT...SELECT zal P niet resetten op nul zetten voor de berekeningen die in dit artikel worden beschreven — ze zullen de pre-truncate-waarde blijven gebruiken en een hercompilatie zal niet helpen. Een tijdelijke oplossing is om grote wijzigingen in afzonderlijke batches in te dienen.
Traceervlaggen
Het is mogelijk om FDemandRowsSortedForPerformance . te forceren om true terug te geven door ongedocumenteerd en niet-ondersteund . in te stellen traceringsvlag 2332, zoals ik schreef in T-SQL-query's optimaliseren die gegevens wijzigen. Wanneer TF 2332 actief is, het aantal geschatte rijen om in te voegen moet nog steeds minstens 100 zijn . TF 2332 beïnvloedt de minimale logging beslissing voor FastLoadContext alleen (het is effectief voor gepartitioneerde heaps voor zover DMLRequestSort is bezorgd, maar heeft geen effect op de heap zelf, aangezien FastLoadContext geldt alleen voor indexen).
Een brede/per-index planvorm voor niet-geclusterd indexonderhoud kan worden geforceerd voor rowstore-tabellen met behulp van traceringsvlag 8790 (niet officieel gedocumenteerd, maar vermeld in een Knowledge Base-artikel en in mijn artikel zoals gelinkt voor TF2332 net hierboven).
Gerelateerde literatuur
Allemaal door Sunil Agarwal van het SQL Server-team:
- Wat zijn de optimalisaties voor bulkimport?
- Bulkimportoptimalisaties (minimale logboekregistratie)
- Minimale wijzigingen in de logboekregistratie in SQL Server 2008
- Minimale wijzigingen in de logboekregistratie in SQL Server 2008 (deel 2)
- Minimale wijzigingen in de logboekregistratie in SQL Server 2008 (deel 3)