
Gastauteur:Andy Mallon (@AMtwo)
Nee, serieus. Wat is een DTU?
Wanneer u een toepassing implementeert, is een van de eerste vragen die opkomt:"Wat gaat dit kosten?" De meesten van ons hebben ooit dit soort oefening gedaan om een SQL Server-installatie te dimensioneren, maar wat als u naar de cloud implementeert? Met Azure IaaS-implementaties is er niet veel veranderd:u bouwt nog steeds een server op basis van het aantal CPU's, een bepaalde hoeveelheid geheugen en configureert opslag om u voldoende IOPS te geven voor uw werkbelasting. Wanneer u echter de sprong naar PaaS maakt, heeft Azure SQL Database verschillende servicelagen, waarbij de prestaties worden gemeten in DTU's. Wat is in vredesnaam een DTU?
Ik weet wat een BTU is. Misschien staat DTU voor Database Thermal Unit? Is het de hoeveelheid rekenkracht die nodig is om de temperatuur van het datacenter met één graad te verhogen? Laten we, in plaats van te gissen, de documentatie bekijken en kijken wat Microsoft te zeggen heeft:
Een [Database Transaction Unit] is een gecombineerde meting van CPU, geheugen en data-I/O en transactielogboek-I/O in een verhouding die wordt bepaald door een OLTP-benchmark-workload die is ontworpen om typisch te zijn voor OLTP-workloads in de echte wereld. Het verdubbelen van de DTU's door het prestatieniveau van een database te verhogen, komt neer op een verdubbeling van de set resources die beschikbaar is voor die database.OK, dat was mijn tweede gok, maar wat is de "gemengde maat"? Hoe kan ik wat ik weet over de grootte van een server vertalen naar de grootte van een Azure SQL-database? Helaas is er geen eenvoudige manier om '2 CPU-cores en 4 GB geheugen' om te zetten in een DTU-meting.
Is er geen DTU-calculator?
Ja! Microsoft geeft ons wel een DTU-calculator om te schatten de juiste servicelaag van Azure SQL Database. Om het te gebruiken, downloadt en voert u een PowerShell-script (sql-perfmon.ps1) uit op de server terwijl u een werkbelasting uitvoert in SQL Server. Het script voert een CSV uit die vier prestatietellers bevat:(1) totaal % processortijd, (2) totaal aantal leesbewerkingen per seconde, (3) totaal aantal schrijfbewerkingen per seconde en (4) totaal aantal gewiste logbytes/seconde. Deze CSV-uitvoer wordt vervolgens geüpload naar de DTU-calculator, die schat welke servicelaag het beste aan uw behoeften voldoet. De enige gegevens die de DTU-calculator naast de CSV gebruikt, zijn het aantal CPU-kernen op de server die het bestand heeft gegenereerd. De DTU-calculator is nog steeds een beetje een zwarte doos - het is niet eenvoudig om wat we weten uit onze on-premises databases in Azure in kaart te brengen.
Ik wil erop wijzen dat de definitie van een DTU is dat het "een gemengde maatstaf is van CPU, geheugen , en data I/O en transactielog I/O..." Geen van de prestatietellers die door de DTU Calculator worden gebruikt, houdt rekening met geheugen, maar het wordt duidelijk vermeld in de definitie als onderdeel van de berekening. Dit is niet noodzakelijk een probleem, maar het is het bewijs dat de DTU-calculator niet perfect zal zijn.
Ik zal wat synthetische lading uploaden naar de DTU Calculator, en kijken of ik erachter kan komen hoe die zwarte doos werkt. In feite zal ik de CSV's volledig fabriceren, zodat ik de prestatienummers die we in de DTU-calculator laden, volledig kan controleren. Laten we één statistiek tegelijk doorlopen. Voor elke statistiek uploaden we 25 minuten (1500 seconden – ik hou van ronde getallen) aan gefabriceerde gegevens en kijken we hoe die prestatiegegevens worden geconverteerd naar DTU's.
CPU
Ik ga een CSV maken die een 16-core server simuleert, waarbij het CPU-gebruik langzaam wordt opgevoerd totdat het vastzit op 100%. Aangezien ik de ramp-up op een 16-core server ga simuleren, zal ik mijn CSV maken om 1/16e tegelijk op te voeren - in wezen simuleren dat één core maximaal wordt, dan een tweede maximaal, dan de derde, enz. Al die tijd toont de CSV nul lees-, schrijf- en log-flushes. Een server zou eigenlijk nooit zo'n workload genereren, maar dat is het punt. Ik isoleer het CPU-gebruik volledig zodat ik kan zien hoe CPU DTU's beïnvloedt.
Ik maak een CSV-bestand met één rij per seconde en elke 94 seconden verhoog ik de teller van het totale % processortijd met ~6%. De andere drie tellers zullen in alle gevallen nul zijn. Nu upload ik dit bestand naar de DTU Calculator (en vertel de DTU Calculator om 16 cores te overwegen), en hier is de output:
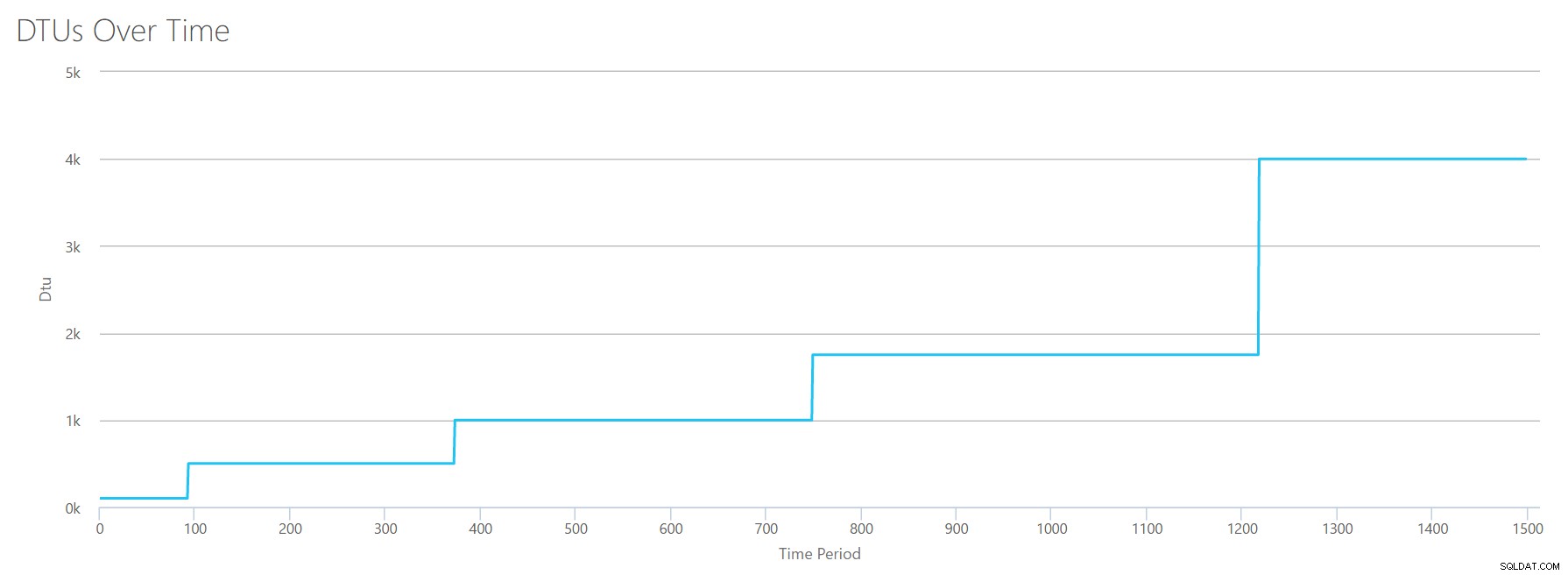
Wacht? Heb ik het CPU-gebruik niet in 16 even stappen opgevoerd? Deze DTU-grafiek toont slechts vijf stappen. Ik moet het verprutst hebben. Nee, mijn CSV had 16 even stappen, maar dat vertaalt zich (blijkbaar) niet gelijkmatig in DTU's. Althans niet volgens de DTU Calculator. Op basis van onze maximale CPU-test zou onze CPU-naar-DTU-naar-service Tier-toewijzing er als volgt uitzien:
| Nummerkernen | DTU's | Servicelaag |
|---|---|---|
| 1 | 100 | Standaard – S3 |
| 2-4 | 500 | Premium – P4 |
| 5-8 | 1000 | Premium – P6 |
| 13-9 | 1750 | Premium – P11 |
| 14-16 | 4000 | Premium – P15 |
Als we naar deze gegevens kijken, leren we een paar dingen:
- Eén CPU-kern, 100% gebruikt, is gelijk aan 100 DTU's.
- DTU's nemen een beetje toe lineair naarmate de CPU toeneemt, maar schijnbaar met horten en stoten.
- De servicelagen Basic en Standard zijn gelijk aan minder dan een enkele CPU-kern.
- Elke Multi-core server zou zich vertalen naar een bepaalde grootte binnen de Premium-servicelaag.
Leest
Deze keer ga ik dezelfde methode gebruiken. Ik zal een CSV genereren met oplopende getallen voor de lees/seconde-teller, met de andere perfmon-tellers op nul. Ik zal het aantal in de loop van de tijd langzaam opvoeren. Laten we deze keer in blokken van 2000 stappen, elke 100 seconden, totdat we 30000 bereiken. Dit geeft ons dezelfde totale tijd van 25 minuten, maar deze keer heb ik 15 stappen in plaats van 16. (Ik hou van ronde getallen.)
Wanneer we dit CSV uploaden naar de DTU-calculator, geeft het ons deze DTU-grafiek:
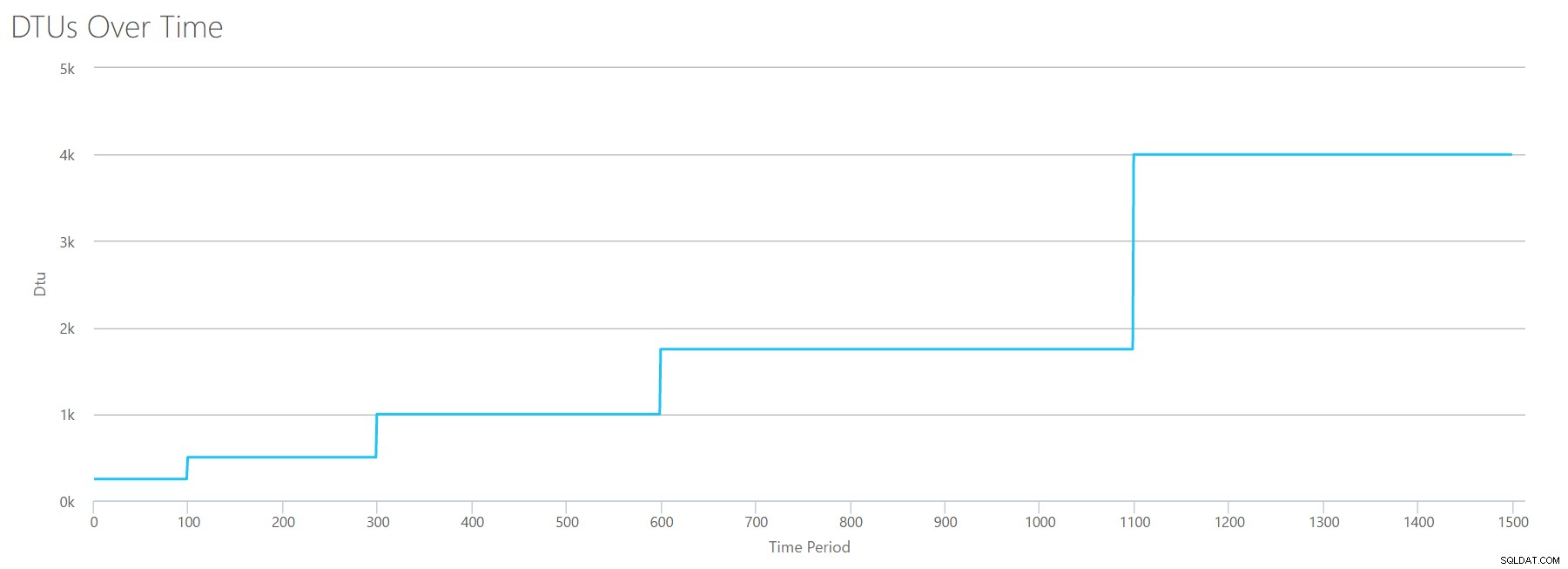
Wacht even ... dat lijkt erg op de eerste grafiek. Nogmaals, het gaat in 5 ongelijke stappen omhoog, ook al had ik 15 even stappen in mijn bestand. Laten we het in tabelvorm bekijken:
| Lees/sec | DTU's | Servicelaag |
|---|---|---|
| 2000 | 250 | Premium – P2 |
| 4000-6000 | 500 | Premium – P4 |
| 8000-12000 | 1000 | Premium – P6 |
| 14000-22000 | 1750 | Premium – P11 |
| 24000-30000 | 4000 | Premium – P15 |
Nogmaals, we zien dat de Basic- en Standard-lagen vrij snel worden gesprongen (minder dan 2000 reads/sec), maar dan is de Premium-tier behoorlijk breed, met een bereik van 2000 tot 30000 reads per seconde. In de bovenstaande tabel kan de "Lees/sec" waarschijnlijk worden gezien als "IOPS" ... Of, technisch gezien, gewoon "OPS", aangezien er geen schrijfbewerkingen zijn om het "invoer"-gedeelte van IOPS te vormen.
Schrijft
Als we een CSV maken met dezelfde formule die we hebben gebruikt voor Reads, en dat CSV uploaden naar de DTU Calculator, krijgen we een grafiek die identiek is aan de grafiek voor Reads:
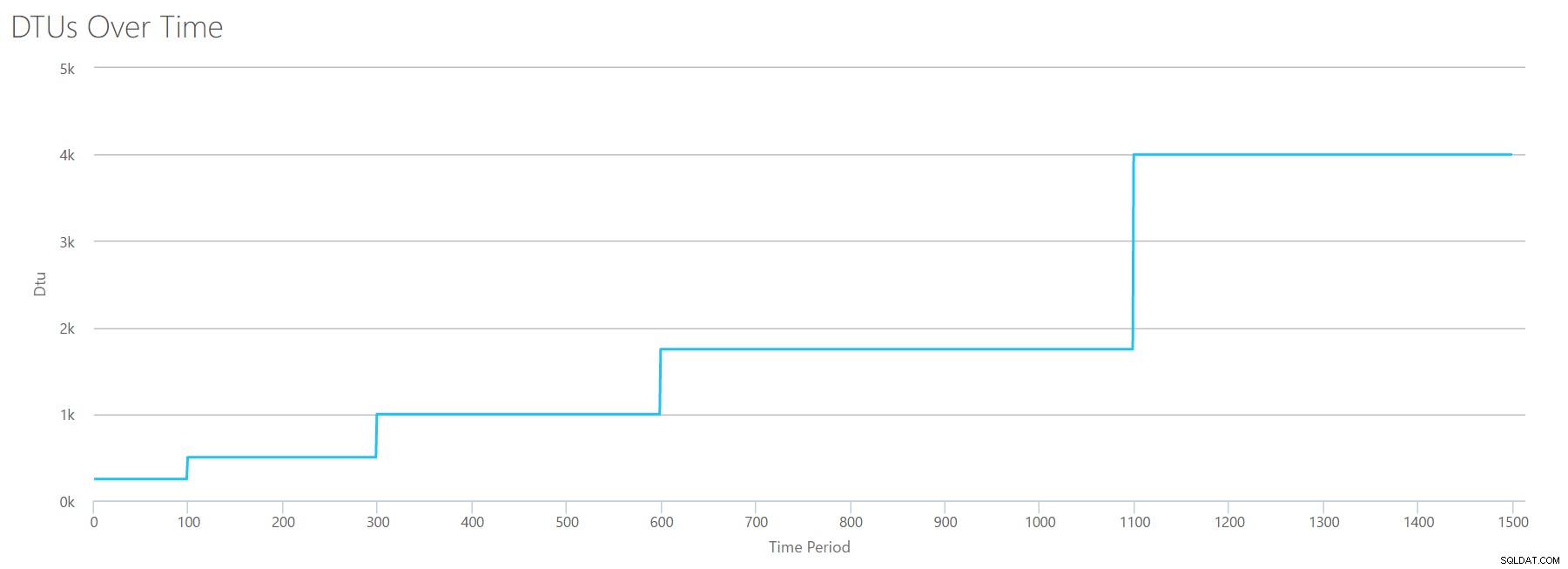
IOPS is IOPS, dus of het nu lezen of schrijven is, het lijkt erop dat de DTU-berekening er evenzeer rekening mee houdt. Alles wat we weten (of denken te weten) over lezen, lijkt evenzeer van toepassing op schrijven.
Logbytes gewist
We zijn toe aan de laatste perfmon-teller:logbytes die per seconde worden gewist. Dit is een andere maatstaf van IO, maar specifiek voor het SQL Server-transactielogboek. Voor het geval je het nu nog niet doorhebt, maak ik deze CSV's zodat de hoge waarden worden berekend als een P15 Azure DB, en verdeel de waarde vervolgens eenvoudig in even stappen. Deze keer gaan we van 5 miljoen naar 75 miljoen, in stappen van 5 miljoen. Zoals we bij alle eerdere tests hebben gedaan, zijn de andere prestatietellers nul. Aangezien deze prestatieteller in bytes per seconde is, en we meten in miljoenen, kunnen we dit bedenken in de eenheid waar we meer vertrouwd mee zijn:Megabytes per seconde.
We uploaden deze CSV naar de DTU-calculator en we krijgen de volgende grafiek:
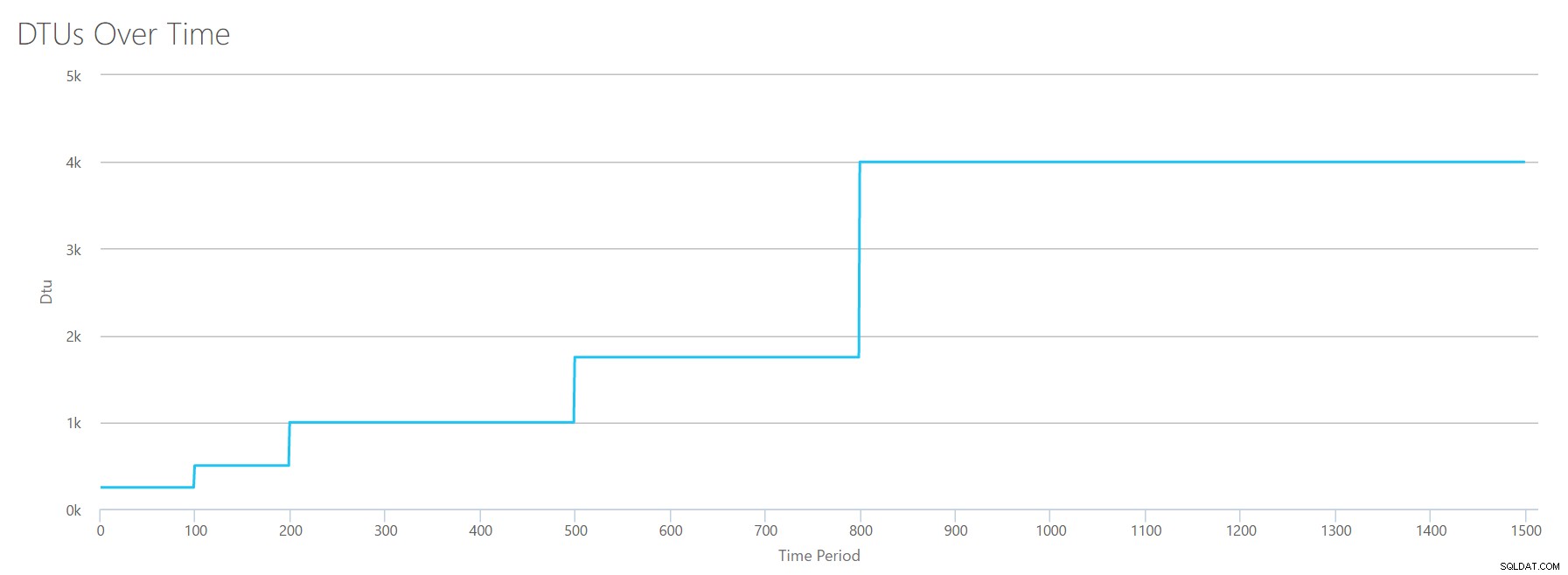
| Log megabytes gewist/sec | DTU's | Servicelaag |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15-25 | 1000 | Premium – P6 |
| 30-40 | 1750 | Premium – P11 |
| 45-75 | 4000 | Premium – P15 |
De vorm van deze grafiek wordt behoorlijk voorspelbaar. Behalve deze keer gaan we een beetje sneller door de lagen en bereiken P15 na slechts 8 stappen (vergeleken met 11 voor IO en 12 voor CPU). Dit kan ertoe leiden dat je denkt:"Dit wordt mijn smalste bottleneck!" maar daar zou ik niet zo zeker van zijn. Hoe vaak genereert u 75 MB log in een seconde ? Dat is 4,5 GB per minuut . Dat is veel database-activiteit. Mijn synthetische werklast is niet per se een realistische werklast.
Alles combineren
OK, nu we hebben gezien waar sommige van de bovengrenzen geïsoleerd zijn, ga ik de gegevens combineren en kijken hoe ze zich verhouden wanneer CPU, I/O en transactielog-IO allemaal tegelijk plaatsvinden - tenslotte , is dat niet hoe de dingen eigenlijk gebeuren?
Om deze CSV te maken, heb ik gewoon de bestaande waarden genomen die we voor elke afzonderlijke test hierboven hebben gebruikt, en die waarden gecombineerd in een enkele CSV, wat deze mooie grafiek oplevert:
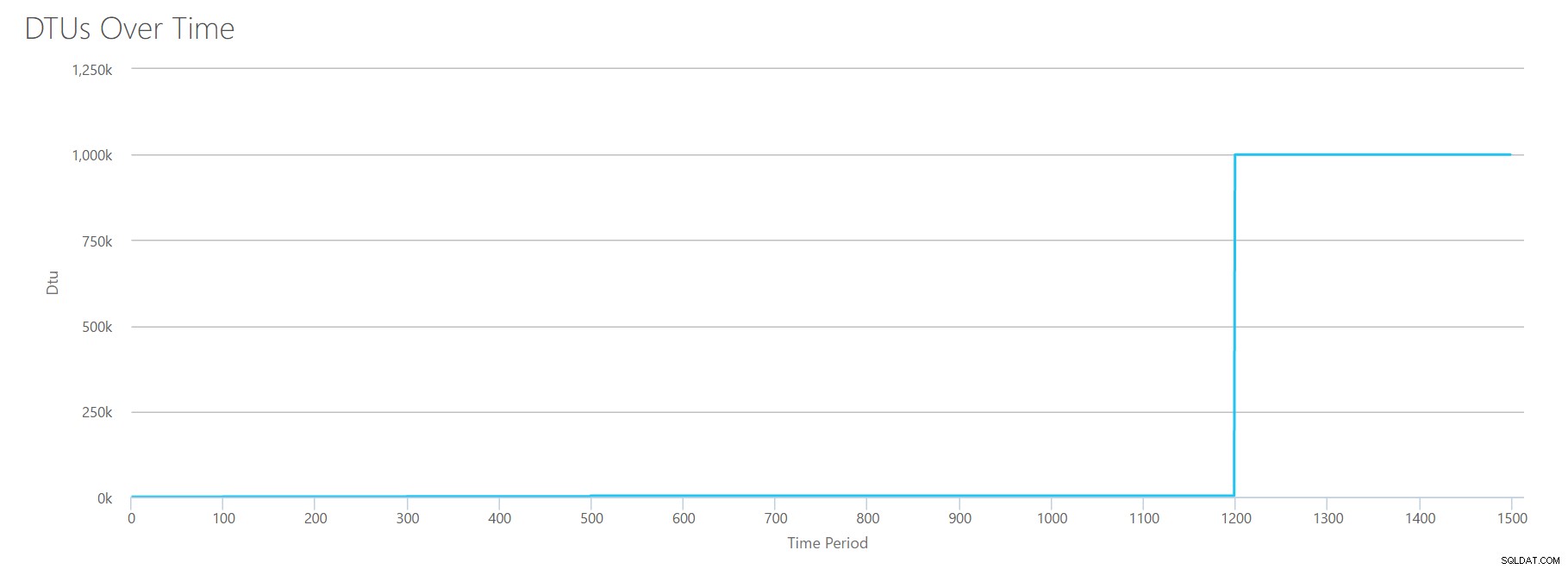
Het levert ook het bericht op:
Op basis van uw databasegebruik is uw SQL Server-werkbelasting Buiten bereik . Op dit moment is er geen serviceniveau/prestatieniveau dat uw gebruik dekt.Als u naar de Y-as kijkt, ziet u dat we de "1.000k" (dwz 1 miljoen) DTU's bij 1200 seconden bereiken. Dat lijkt...uhh...fout? Als we naar de bovenstaande tests kijken, was het 1200 seconden-teken toen alle 4 individuele statistieken het doel bereikten voor 4000 DTU, P15-laag. Het is logisch dat we buiten bereik zouden zijn, maar de vorm van de grafiek klopt niet helemaal voor mij - ik denk dat de DTU-rekenmachine gewoon zijn handen in de lucht heeft gegooid en zei:"Wat dan ook, Andy. Het is veel. veel. Het zijn een miljard DTU's. Deze workload past niet voor Azure SQL Database."
OK, dus wat gebeurt er voor de 1200 seconden? Laten we de CSV verkleinen en opnieuw indienen bij de rekenmachine met alleen de eerste 1200 seconden. De maximale waarden voor elke kolom zijn:81% CPU (of apx 13 cores bij 100%), 24000 reads/sec, 24000 writes/sec en 60 MB log flushed/sec.
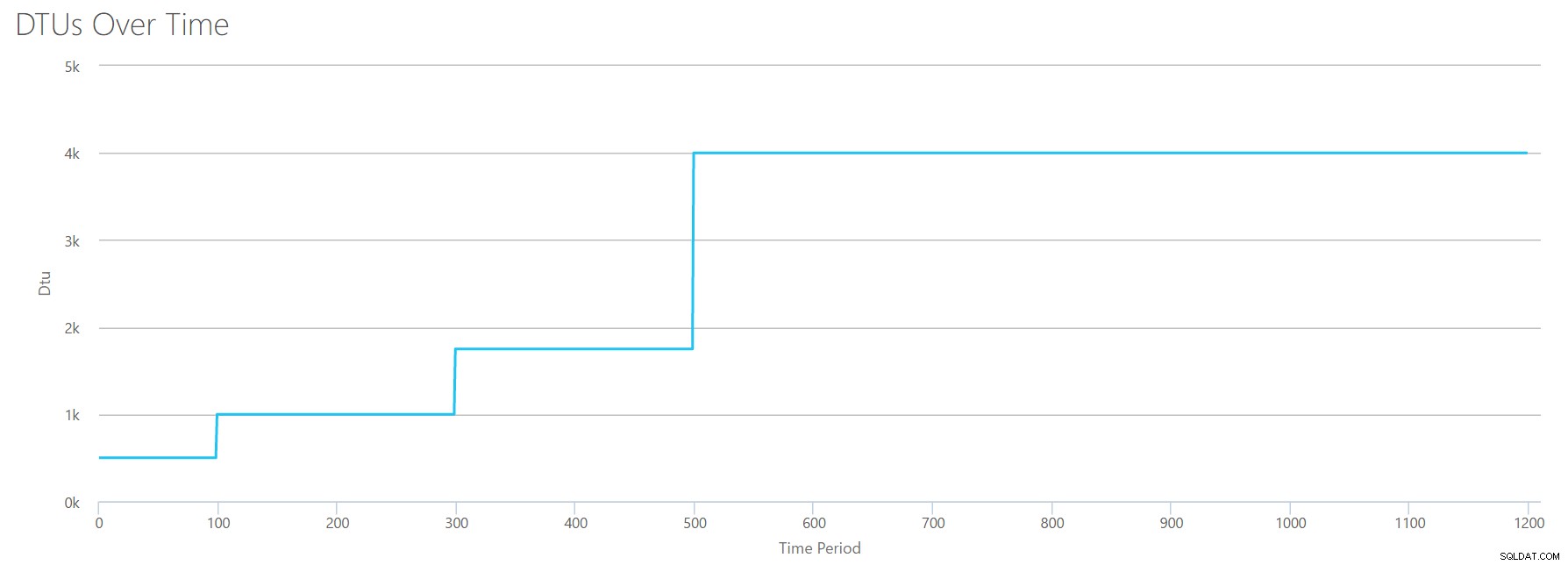
Hallo, oude vriend... Die vertrouwde vorm is weer terug. Hier is een samenvatting van de gegevens van de CSV en wat de DTU-calculator schat voor het totale DTU-gebruik en de servicelaag.
| Nummerkernen | Lees/sec | Schrijft/sec | Log megabytes gewist/sec | DTU's | Servicelaag |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Premium – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Premium – P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | Premium – P15 |
Laten we nu eens kijken hoe de individuele DTU-berekeningen (wanneer we ze afzonderlijk hebben geëvalueerd) zich verhouden tot de DTU-berekeningen van deze meest recente controle:
| CPU DTU's | Lees DTU's | Schrijf DTU's | Log flush DTU's | Totaal totaal aantal DTU's | DTU Calculator schatting | Servicelaag |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Premium – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Premium – P15 |
U zult merken dat de DTU-berekening niet zo eenvoudig is als het optellen van uw afzonderlijke DTU's. Zoals de definitie die ik aan het begin heb geciteerd, aangeeft, is het een "gemengde maatstaf" van die afzonderlijke statistieken. De formule die wordt gebruikt voor "mengen" is ingewikkeld en we hebben die formule niet echt. Wat we kunnen zien is dat de schattingen van de DTU Calculator lager . zijn dan de som van de afzonderlijke DTU-berekeningen.
DTU's toewijzen aan traditionele hardware
Laten we de gegevens van de DTU-calculator nemen en proberen te raden hoe traditionele hardware kan worden toegewezen aan sommige Azure SQL Database-lagen.
Laten we eerst aannemen dat "reads/sec" en "writes/sec" rechtstreeks naar IOPS worden vertaald, zonder dat vertaling nodig is. Ten tweede, laten we aannemen dat het toevoegen van deze twee tellers ons onze totale IOPS geeft. Ten derde, laten we toegeven dat we geen idee hebben wat geheugengebruik is, en dat we geen enkele manier hebben om daarover conclusies te trekken.
Terwijl ik hardwarespecificaties schat, kies ik ook een mogelijke Azure VM-grootte die bij elke hardwareconfiguratie past. Er zijn veel vergelijkbare Azure VM-grootten, elk geoptimaliseerd voor verschillende prestatiestatistieken, maar ik ben doorgegaan en heb mijn keuzes beperkt tot de A-serie en DSv2-serie.
| Nummerkernen | IOPS | Geheugen | DTU's | Servicelaag | Vergelijkbare Azure VM-grootte |
|---|---|---|---|---|---|
| 1 kern, 5% gebruik | 10 | ??? | 5 | Basis | Standard_A0, nauwelijks gebruikt |
| <1 kern | 150 | ??? | 100 | Standaard S0-S3 | Standard_A0, niet volledig benut |
| 1 kern | tot 4000 | ??? | 500 | Premium – P4 | Standard_DS1_v2 |
| 2-3 kernen | tot 12000 | ??? | 1000 | Premium – P6 | Standard_DS3_v2 |
| 4-5 kernen | tot 20000 | ??? | 1750 | Premium – P11 | Standard_DS4_v2 |
| 6-13 | tot 48000 | ??? | 4000 | Premium – P15 | Standard_DS5_v2 |
De Basic-laag is ongelooflijk beperkt. Het is goed voor incidenteel/casual gebruik en het is een goedkope manier om uw database te "parkeren" wanneer u deze niet gebruikt. Maar als u een echte toepassing gebruikt, zal de Basic-laag niet voor u werken.
De Standard Tier is ook vrij beperkt, maar voor kleine toepassingen kan hij aan uw behoeften voldoen. Als u een 2-coreserver hebt waarop een handvol databases wordt uitgevoerd, passen die databases afzonderlijk mogelijk in de Standard-laag. Evenzo, als u een server hebt met slechts één database, waarop 1 CPU-core draait op 100% (of 2 cores op 50%), is het waarschijnlijk net genoeg pk's om de schaal in de Premium-P1-servicelaag te laten vallen.
Als u een multi-core server in een on-premises (of IaaS) zou gebruiken, dan zou u binnen de Premium-servicelaag op Azure SQL Database kijken. Het is gewoon een kwestie van bepalen hoeveel CPU &I/O pk je nodig hebt voor je workload. Uw 2-core, 4GB-server brengt u waarschijnlijk ergens rond een P6 Azure SQL DB. In een pure CPU-workload (met nul I/O) kan een P15-database 16 cores aan verwerking aan, maar zodra u IO aan de mix toevoegt, past alles dat groter is dan ~12 cores niet in Azure SQL Database.
De volgende keer zal ik een aantal daadwerkelijke workloads nemen en de prestaties van verschillende servicelagen vergelijken. Zullen de schattingen van de DTU-calculator nauwkeurig zijn? We zullen het ontdekken.
Over de auteur
 Andy Mallon is een SQL Server DBA en Microsoft Data Platform MVP die databases heeft beheerd in de gezondheidszorg, financiën, e -handels- en non-profitsectoren. Sinds 2003 ondersteunt Andy OLTP-omgevingen met hoge volumes en hoge beschikbaarheid met veeleisende prestatie-eisen. Andy is de oprichter van BostonSQL, mede-organisator van SQLSaturday Boston en blogt op am2.co.
Andy Mallon is een SQL Server DBA en Microsoft Data Platform MVP die databases heeft beheerd in de gezondheidszorg, financiën, e -handels- en non-profitsectoren. Sinds 2003 ondersteunt Andy OLTP-omgevingen met hoge volumes en hoge beschikbaarheid met veeleisende prestatie-eisen. Andy is de oprichter van BostonSQL, mede-organisator van SQLSaturday Boston en blogt op am2.co.